2021年中国高校大数据挑战赛数据挖掘系统知识-附Matlab和Python实现代码
Posted Better Bench
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2021年中国高校大数据挑战赛数据挖掘系统知识-附Matlab和Python实现代码相关的知识,希望对你有一定的参考价值。
高清PDF、Xmind文件-Xmind源文件附知识点超链接–下载链接
目录
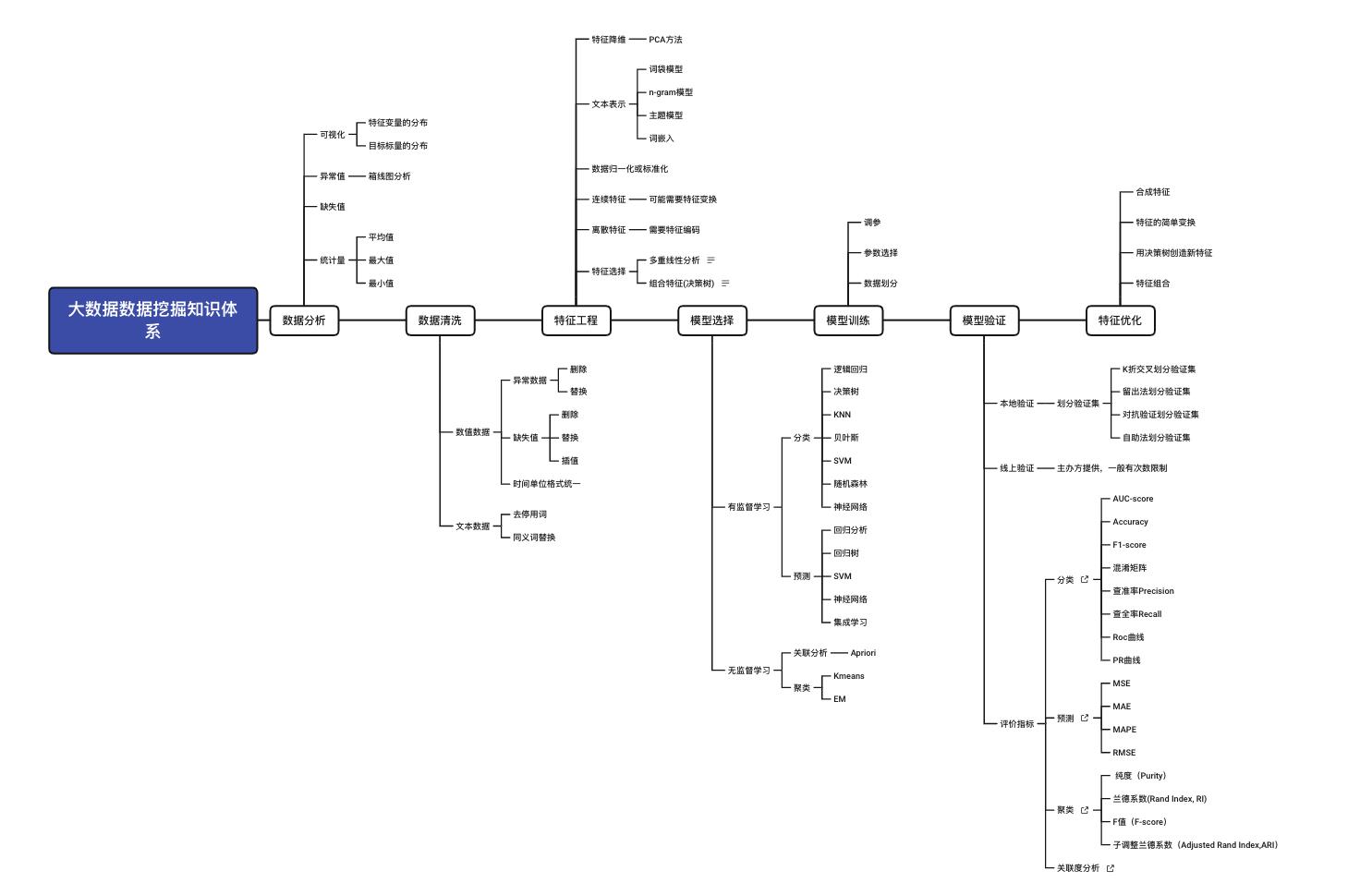
1 数据分析
1.1 基本理论
(1)拿到数据的第一件事,就是做数据分析。分析了解所有数据的分布和不合法数据的样式,为数据处理做准备。分析的内容主要包含以下几方面
-
缺失值
-
异常值
-
数据分布(可视化)
- 特征变量的分布
- 目标变量的分布
-
数据统计量
- 平均值
- 最大值
- 最小值
- 均值、方差
1.2 MATLAB实现
待完善
1.3 Python实现
import re
import numpy as np
import pandas as pd
import seaborn as sns
from pylab import rcParams
import matplotlib.pyplot as plt
import torch
# 绘图配置
%matplotlib inline
%config InlineBackend.figure_format='retina' # 主题
sns.set(style='whitegrid', palette='muted', font_scale=1.2)
HAPPY_COLORS_PALETTE = ["#01BEFE", "#FFDD00", "#FF7D00", "#FF006D", "#ADFF02", "#8F00FF"]
sns.set_palette(sns.color_palette(HAPPY_COLORS_PALETTE))
rcParams['figure.figsize'] = 25, 20
RANDOM_SEED = 42
np.random.seed(RANDOM_SEED)
torch.manual_seed(RANDOM_SEED)
# 读取数据
train = pd.read_csv('data/train.csv', sep='\\t')
# 查看表中矩阵的统计信息(最大值、最小值、平均值、行数、列数)
train.info()
# 查看前5行数据
train.head(5)
# 查看是否有缺失值
train.isnull().sum()
# 打印有缺失值的属性列
print("train null nums")
print(train.shape[0]-train.count())
# 类别变量的统计
train['categories'].value_counts()
# 类别变量的统计绘图
sns.countplot(train.categories)
plt.xlabel('categories count')
2 数据清洗
2.1 基本理论
数据清洗就是去除“脏”数据。可能包括以下问题
-
html标签:有可能数据集是爬虫得到的,内含有许多不合法的字符
-
异常数据:不合法数据或者离散点数据
-
缺失值:空值
-
单位格式统一:一般是时间格式
2.2 MATLAB实现
待完善
2.3 Python实现
(1)离散数据缺失值的处理-删除
train.dropna(axis=0, how='any', inplace=True)
(2)离散数据缺失值的处理-填充
当数据存在缺失值,用Pandas读取后均为NaN。用impute库的SimpleImputer类对这个数据集进行缺失值计算
from numpy import vstack,array,nan
from sklearn.impute import SimpleImputer
SimpleImputer().fit_transform(vstack(array([nan,nan,nan,nan]),train.values))
(3)时间序列缺失值的插值处理–线性插值
# 线性插值
# 将np.nan的数据全部插值
from scipy import interpolate
for indexs in train.columns:
if indexs =='time':
continue
train['rownum'] = np.arange(train.shape[0])
df_nona = train.dropna(subset = [indexs])
f = interpolate.interp1d(df_nona['rownum'], df_nona[indexs])
train[indexs] = f(train['rownum'])
train = train.drop(columns=['rownum'])
(4)时间序列缺失值的插值处理–K最邻近平均插值
# K最邻近插值
k = 8#K 值自定义
def knn_mean(ts, n):
out = np.copy(ts)
for i, val in enumerate(ts):
if np.isnan(val):
n_by_2 = np.ceil(n/2)
lower = np.max([0, int(i-n_by_2)])
upper = np.min([len(ts)+1, int(i+n_by_2)])
ts_near = np.concatenate([ts[lower:i], ts[i:upper]])
out[i] = np.nanmean(ts_near)
return out
train[indexs] = knn_mean(train[indexs].values,k)
3 特征工程
3.1 基本理论
特征工程是利用数据领域的相关知识来创建能够使机器学习算法达到最佳性能的特征的过程。 换句话说,特征工程就是一个把原始数据转变成特征的过程,这些特征可以很好的描述这些数据,并且利用它们建立的模型在未知数据上的表现性能达到更佳。俗话说“garbage in garbage out”。特征工程极大程度的决定了模型的输出效果。在整个模型的优化阶段,会回头去做特征工程来提升模型输出效果。
(1)特征的选择
一般表有很多列,并不是每一列都对于模型又增益。存在特征冗余。特征选择是最常用的特征降维手段,其比较简单粗暴,即映射函数直接将不重要的特征删除。由于数据分析以抓住主要影响因子为主,变量越少越有利于分析,如基因序列建模。特征选择目标有两种
- 特征是否发散:如果一个特征不发散,如方差接近于0,就说明这个特征基本没有差异,这个特征对于样本的区分没有任何作用。
- 特征与目标的相关性:与目标相关性高的特征应当优先选择。
特征选择的方法有过滤法、包装法、嵌入法
-
过滤法:按照发散性或者相关性对各个特征进行评分,通过设定阈值或待待选择值的个数来选择特征
-
包装法:根据目前函数(通过是预测效果评分)每次选择若干特征,或者排除若干特征
-
嵌入法:使用机器学习的某些算法那和模型进行训练,得到各个特征的权值,并根据系数从大到小进行选择特征。
(2)数据转换
主要针对一些长尾分布的特征,需要进行幂变换或者对数变换,使得模型(LR或者DNN)能更好的优化。需要注意的是,Random Forest 和 GBDT 等模型对单调的函数变换不敏感。其原因在于树模型在求解分裂点的时候,只考虑排序分位点。常见的数据转换有基于多项式的、指数函数的和对数函数的转换方法。
针对类别的离散特征,特征编码方式有如下,一般采用Onehot编码或者LabelEncoding 自然数编码
自然数编码、独热编码、哈希编码、统计编码、目标编码、嵌入编码、缺失值编码、多项式编码、布尔编码
针对数值特征可能涉及以下的变换
取整、分箱、放缩
(3)特征降维
多重线性分析的原则是特征组之间的相关系数较大,每个特征变量与其他特征变量之间的相关性高,故可能存在较大的共线性影响,这会导致模型估计不准确,因此后续,需要使用PCA对数据进行处理,去除多重共线性。
线性降维常用的方法又主成分分析法PCA ,线性判别分析法LDA。
- PCA:主要原理是通过某种线性投影,将高维的数据映射到低维的空间中表示,其期望在所投影的维度上数据的方差最大,以此达到较小的数据维度来保留较多的原数据点特性
- LDA:是一种有监督的线性降维算法,目标是使得降维后的数据尽可能容易被区分,其利用了标签的信息。
2.2 MATLAB实现
待完善
2.3 Python实现
(1)特征选择
# 过滤法的方差选择法
from sklearn.feature_selection import VarianceThreshold
VarianceThreshold(threshold=3).fit_transform(train.values)
# 过滤法的相关系数法
import numpy as np
from numpy import array
from sklearn.feature_selection import SelectKBest
from scipy.statx import pearsonr
SelectKBest(lambda X,Y:np.array(list(map(lambda x:pearsonr(x,X),X.T))).T[0],k=2).fit_transform(train.values,Target.values)
# 还有卡方检验和最大信息系数法
(2)数据转换
from sklearn.preprocessing import PolynomialFeatures
# 多项式转换
PolynomialFeatures().fit_transform(train.values)
# 对数变换
from numpy import loglp
from sklean.preprocessing import FunctionTransformer
FunctionTransformer(loglp,validate=False).fit_transform(train.values)
(3)离散特征或目标变量编码
from numpy import array
from numpy import argmax
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import OneHotEncoder
# define example
data = ['cold', 'cold', 'warm', 'cold', 'hot', 'hot', 'warm', 'cold', 'warm', 'hot']
values = array(data)
# 自然数编码
label_encoder = LabelEncoder()
integer_encoded = label_encoder.fit_transform(values)
print(integer_encoded)
# 独热编码
onehot_encoder = OneHotEncoder(sparse=False)
integer_encoded = integer_encoded.reshape(len(integer_encoded), 1)
onehot_encoded = onehot_encoder.fit_transform(integer_encoded)
print(onehot_encoded)
(4)特征降维
# 主成分分析法降维
from sklearn.decomposition import PCA
PCA(n_components =2).fit_transform(iris.data)
# 线性判别分析法降维
from sklearn.disctrminant_nanlysis import LinearDiscriminantAnalysis as LDA
LDA(n_components =2).fit_transform(iris.data,iris.target)
4 模型选择
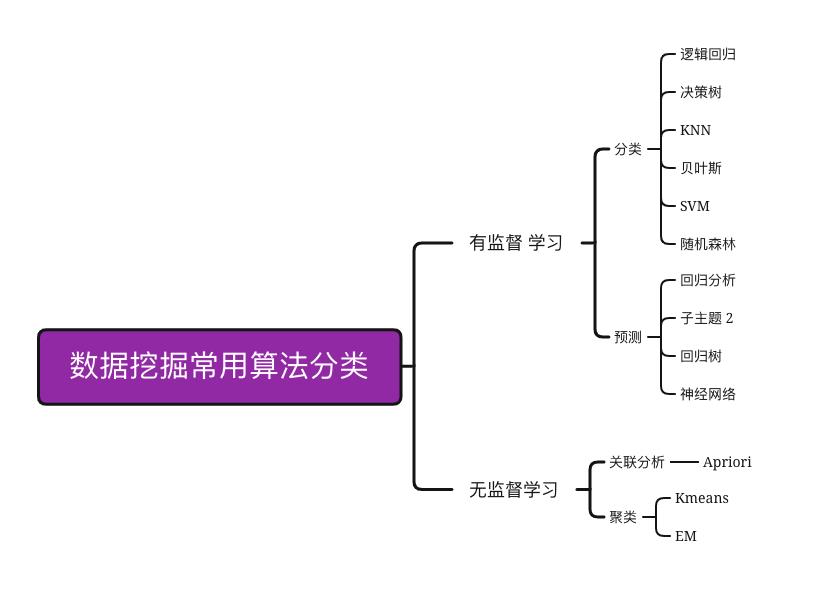
4.1 基本理论
十大算法:https://zhuanlan.zhihu.com/p/25140821
-
分类
- 逻辑回归、决策树、C4.5,朴素贝叶斯,SVM,KNN,Adaboost,CART
-
聚类
- K-Means,EM
-
关联规则
- Apriori
-
预测算法
- 回归分析、回归树、SVM、神经网络、集成学习
4.2 MATLAB实现
4.3 Python实现
(1)决策树
#1、导入需要的包
from sklearn.datasets import load_wine #导入自带的红酒数据集
from sklearn import tree
from sklearn.model_selection import train_test_split #进行训练集数据集划分
#2、获取数据
wine = load_wine()
#3、划分训练集和测试集 注意顺序不能乱分别表示 训练集,测试集,训练集标签(类别),测试集标签(类别)
Xtrain,Xtest,Ytrain,Ytest=train_test_split(wine.data,wine.target,test_size=0.3)
#4、建立模型
clf = tree.DecisionTreeClassifier() #实例化,全部选择了默认的参数
clf.fit(Xtrain,Ytrain) #拟合
score=clf.score(Xtest,Ytest) #模型评分
print(score) #输出结果
(2)KMeans聚类
# k-means 聚类
from numpy import unique
from numpy import where
from sklearn.cluster import KMeans,MiniBatchKMeans,DBSCAN,AgglomerativeClustering,Birch
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn import metrics
import pandas as pd
import numpy as np
# from mpl_toolkits.mplot3d import Axes3D
from mpl_toolkits.mplot3d import Axes3D
# 参考资料 https://zhuanlan.zhihu.com/p/126661239
def minibatchKmeans(X,k,p=False):
if p==True:
for index, kk in enumerate((3,4,5,6)):
plt.subplot(2,2,index+1)
y_pred = MiniBatchKMeans(n_clusters=kk).fit_predict(X)
score= metrics.calinski_harabasz_score(X, y_pred)
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.text(.99, .01, ('k=%d, score: %.2f' % (kk,score)),
transform=plt.gca().transAxes, size=10,
horizontalalignment='right')
plt.show()
else:
y_pred = KMeans(n_clusters=k).fit_predict(X)
clusters = unique(y_pred)
indexdict ={}
for i in clusters:
indexarr = np.where(y_pred[:]==i)
indexdict[i] = indexarr[0]
return indexdict
def P_Kmeans(X,k,p=False):
if p==True:
for index, kk in enumerate((3,4,5,6)):
plt.subplot(2,2,index+1)
y_pred = KMeans(n_clusters=kk).fit_predict(X)
score= metrics.calinski_harabasz_score(X, y_pred)
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.text(.99, .01, ('k=%d, score: %.2f' % (kk,score)),
transform=plt.gca().transAxes, size=10,
horizontalalignment='right')
plt.show()
else:
y_pred = KMeans(n_clusters=k).fit_predict(X)
clusters = unique(y_pred)
indexdict ={}
for i in clusters:
indexarr = np.where(y_pred[:]==i)
indexdict[i] = indexarr[0]
return indexdict
if __name__ =="__main__":
# 定义数据集
train = pd.read_excel('./data/train.xlsx')
train = train.values
scaler = StandardScaler()
X = scaler.fit_transform(X_out)
k = 3
indexdict = P_Kmeans(X,k,True)
(3)回归树
from sklearn import tree
from sklearn import tree
from sklearn.model_selection import train_test_split #进行训练集数据集划分
#2、获取数据
train = pd.read_csv('data.csv')
Xtrain,Xtest,Ytrain,Ytest=train_test_split(train.data,train.target,test_size=0.3)
clf = tree.DecisionTreeRegressor()
clf = clf.fit(Xtrain, Ytrain)
clf.predict(Xtest)
5 模型训练
5.1 基本理论
模型训练,需要考虑三个问题,数据集划分、参数选择、调参。数据划分将在以下的模型验证部分讲解,对于训练参数和模型参数的选择,在机器学习算法中,首先用默认参数去跑通模型,再通过调参优化模型。对于模型调参,一般采用网格搜索方法。这是一种穷举搜索的调参手段,在所有候选的参数选择中欧,循环遍历,尝试每一种可能性,表现最好的参数就是最终选择。
5.2 MATLAB实现
略
5.3 Python实现
(1)网格搜索调参举例
from sklearn.datasets import load_iris
from sklearn.svm import SVM
form sklearn.model_selection import train_test_split
iris = load_iris()
Xtrain,Xtest,Ytrain,Ytest=train_test_split(iris.data,iris.target,test_size=0.3)
best_score = 0
for g in [0.001,0.01,0.1,1,10,100]:
for c in [0.001,0.01,0.1,1,10,100]:
svm =SVM(gamma=g,C=c)
svm.fit(Xtrain,Ytrain)
score =svm.score(Xtest,Ytest)
if score>best_socre:
best_score =score
best_para = {'gamma':g,'C',c}
print('best score:{}'.format(best_socre))
print('best parameters,gamma:{},C:{}'.format(best_para['g'],best_para['c']))
6 模型验证
6.1 基本理论
(1)本地验证
模型的验证一般先通过划分训练集和测试集去线下验证,社会性的比赛,主办方会提供为标注的测试集,以该测试集的线上平台验证得分为准。划分训练集和测试集的方法就有多种
-
K折交叉验证划分
- kfold
- StratifiedKFold
-
留出法划分
- train_test_split
-
对抗验证划分
-
自助法划分
(2)评价指标
根据不同的模型模型模式选择。
-
分类:AUC、准确率Accuracy、F1-score、混淆矩阵、查准率、查全率、ROC曲线、PR曲线
-
聚类:常见的评价指标有:纯度(Purity)、兰德系数(Rand Index, RI)、F值(F-score)和调整兰德系数(Adjusted Rand Index,ARI)
-
预测:MSE、RMSE、MAE、MAPE
-
关联度分析:灰色关联分析的基本思想是,根据序列曲线几何形状的相似程度来判断其联系是否紧密。曲线越接近,相应序列之间的关联度就越大,反之就越小。
6.2 MATLAB实现
待完善
6.3 Python实现
(1)划分数据集
# K折分层划分
from sklearn.datasets import load_iris
from sklearn.model_selection import StratifiedKFold,cross_val_score,KFold,train_test_split
from sklearn.linear_model import LogisticRegression
iris = load_iris()
print('Iris labels:\\n{}'.format(iris.target))
logreg = LogisticRegression()
strKFold = StratifiedKFold(n_splits=3,shuffle=False,random_state=0)
scores = cross_val_score(logreg,iris.data,iris.target,cv=strKFold)
# K折划分
strKFold = KFold(n_splits=3,shuffle=False,random_state=0)
scores = cross_val_score(logreg,iris.data,iris.target,cv=strKFold)
# 留出法
Xtrain,Xtest,Ytrain,Ytest=train_test_split(iris.data,iris.target,test_size=0.3)
(2)评价指标
# F1-Score
from sklearn.metrics import f1_score
y_true = [0, 1, 2, 0, 1, 2]
y_pred = [0, 2, 1, 0, 0, 1]
f1_score(y_true, y_pred, average='macro')
# AUC
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_auc_score
X, y = load_breast_cancer(return_X_y=True)
clf = LogisticRegression(solver="liblinear", random_state=0).fit(X, y)
roc_auc_score(y, clf.predict_proba(X)[:, 1])
7 模型改进
7.1 特征优化
好的特征对于模型性能有着至关重
以上是关于2021年中国高校大数据挑战赛数据挖掘系统知识-附Matlab和Python实现代码的主要内容,如果未能解决你的问题,请参考以下文章