DataFrame的级联与合并操作
Posted 胜天半月子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DataFrame的级联与合并操作相关的知识,希望对你有一定的参考价值。
文章目录
一、级联操作
1.1 匹配级联
- pd.concat
- pd.append
pandas使用pd.concat函数,与np.concatenate函数类似,只是多了一些参数:
- objs
- axis=0
- keys
- join=‘outer’ / ‘inner’: 表示的是级联的方式;
outer会将所有的项进行级联(忽略匹配和不匹配),而inner只会将匹配的项级联到一起,不匹配的不级联- ignore_index=False
- 导入包
import numpy as np
import pandas as pd
from pandas import DataFrame,Series
- 创建数据
df1 = DataFrame(data=np.random.randint(0,100,size=(5,3)),columns=['A','B','C'])
df2 = DataFrame(data=np.random.randint(0,100,size=(5,3)),columns=['A','D','C'])
- df1

- df2

- 匹配级联
pd.concat((df1,df1),axis=0)
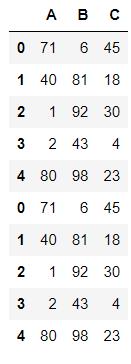
pd.concat((df1,df1),axis=1)

1.2 不匹配级联
不匹配指的是级联的维度的索引不一致。例如纵向级联时列索引不一致,横向级联时行索引不一致
有2种连接方式,join参数:
- 外连接:补NaN(默认模式)【如果想要保留数据的完整性必须使用outer(外连接)】
- 内连接:只连接匹配的项
pd.concat((df1,df2),axis=0)
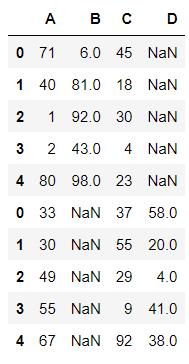
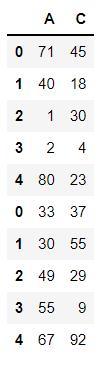
pd.concat((df1,df2),axis=0,join='inner')
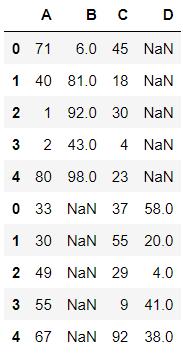
pd.concat((df1,df2),axis=0,join='outer')
append函数的使用:
只可以列和列级联
df1.append(df1)
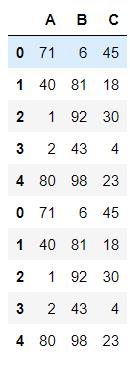
df1.append(df2)

二、合并操作
- merge与concat的区别在于:
merge需要依据某一共同列来进行合并;级联是做拼接- 使用pd.merge()合并时,会自动根据两者相同column名称的那一列,作为key来进行合并。
- 注意每一列元素的顺序不要求一致
2.1 一对一合并
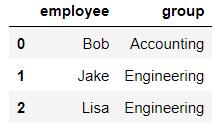
df1 = DataFrame({'employee':['Bob','Jake','Lisa'],
'group':['Accounting','Engineering','Engineering'],
})
df1
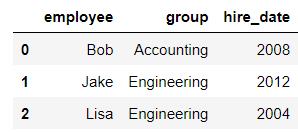
df2 = DataFrame({'employee':['Lisa','Bob','Jake'],
'hire_date':[2004,2008,2012],
})
df2

pd.merge(df1,df2,on='employee')
- 合并:只能一次性合并两张表
- 级联:一次性可以操作多张表
2.2 一对多合并
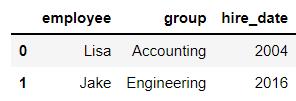
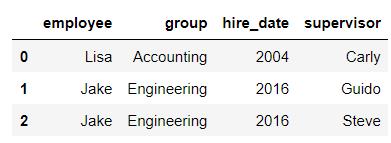
df3 = DataFrame({
'employee':['Lisa','Jake'],
'group':['Accounting','Engineering'],
'hire_date':[2004,2016]})
df3
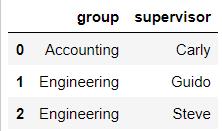
df4 = DataFrame({'group':['Accounting','Engineering','Engineering'],
'supervisor':['Carly','Guido','Steve']
})
df4
# on如果不写,默认情况下使用两表中公有的列作为合并条件
pd.merge(df3,df4)
2.3 多对多合并
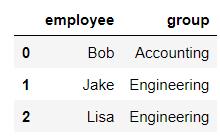
df5 = DataFrame({'employee':['Bob','Jake','Lisa'],
'group':['Accounting','Engineering','Engineering']})
df5
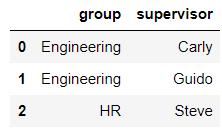
df6 = DataFrame({'group':['Engineering','Engineering','HR'],
'supervisor':['Carly','Guido','Steve']
})
df6
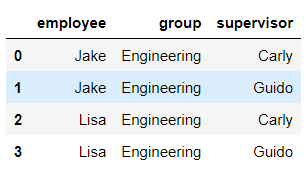
pd.merge(df5,df6)
```
```python
# how 是合并方式 默认值是 inner 只和并能合并的
# outer 能合并的不能合并的都合并
# left 保留左表的数据完整性 righ 保留右表的数据完整性
pd.merge(df5,df6,how='left')
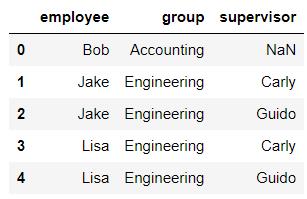
pd.merge(df5,df6,how='right')
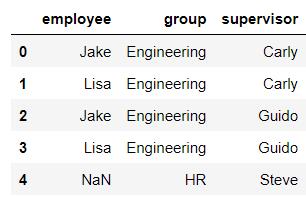
pd.merge(df5,df6,how='inner')

pd.merge(df5,df6,how='outer')

2.4 key的规范化
df7 = DataFrame({'employee':['Jack','Summer','Steve'],
'group':['Accounting','Product','Marketing'],
})
df7

df8 = DataFrame({'employee':['Jack','Bob','Jack'],
'hire_dates':[2003,2009,2012],
'group':['Accounting','sell','ceo']
})
df8
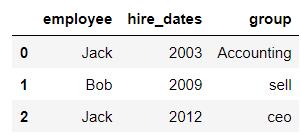
# 没有指定on则默认 表中列少的作为合并条件
# 本例:employee & group 是合并条件
pd.merge(df7,df8)

- 当两张表没有可进行连接的列时,可使用left_on和right_on手动指定merge中左右两边的哪一列列作为连接的列
两张表能不能合并不止看列名,还要看内容
df9 = DataFrame({'employee':['Bobs','Linda','Bill'],
'group':['Accounting','Product','Marketing'],
'hire_date':[1998,2017,2018]})
df9
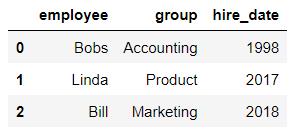
df10 = DataFrame({'name':['Lisa','Bobs','Bill'],
'hire_dates':[1998,2016,2007]})
df10
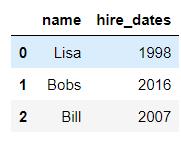
pd.merge(df9,df10,left_on='employee',right_on='name')
三、案例-股票分析
- 需求
- 使用tushare包获取某股票的历史行情数据
- 输出该股票所有收盘比开盘上涨3%以上的日期
- 输出该股票所有开盘比前日收盘跌幅超过2%日期
- 假如我从2010年1月1日开始,每月第一个交易日买入1手股票,每年最后一个交易日卖出所有股票,到今天为止,我的收益如何?【1手=100股】
import tushare as ts
import pandas as pd
from pandas import DataFrame,Series
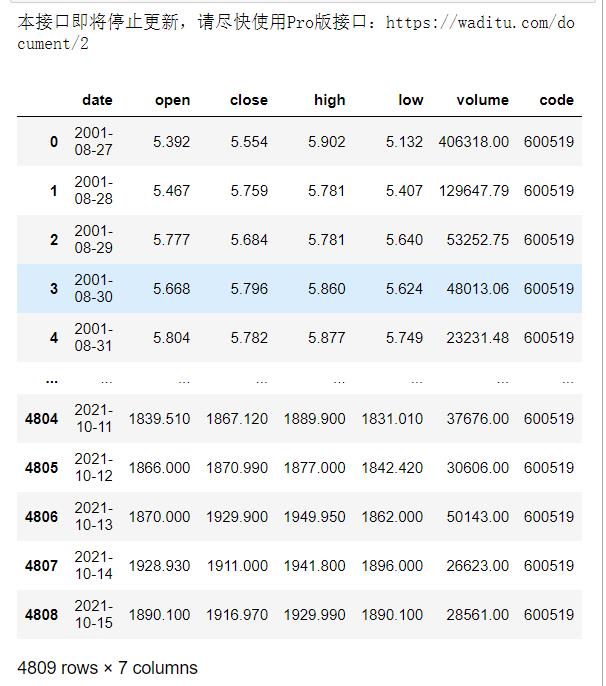
1. 使用tushare包获取某股票的历史行情数据
data = ts.get_k_data(code='600519',start='1900-01-01')
data
- 对股票的数据进行基本操作
# 1.对股票的数据进行持久化存储
data.to_csv('./maotai.csv')
# 2. 将本地加载的数据读取到df中
df = pd.read_csv('./maotai.csv')
df

# 3. 删除df中指定的列数据
df.drop(labels='Unnamed: 0',axis=1,inplace=True)
- drop系列函数中
axis=0表示行,1表示列- inplace表示是否作用在原数据
# 4.df中每一列的类型可以不一致
# 每一列是一个Series
df.info()

# 5.将date作为原数据的行索引
# 首先将date列的数据由字符串转换为时间序列
pd.to_datetime(df['date'])
# print(pd.to_datetime(df['date']).dtype) :datetime64[ns]
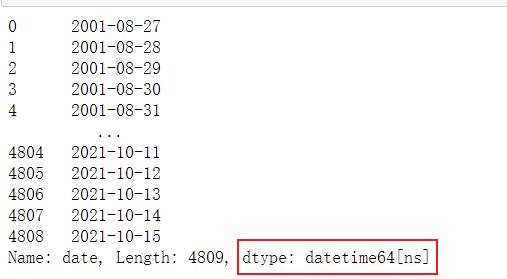
df['date'] = pd.to_datetime(df['date'])
df.info()
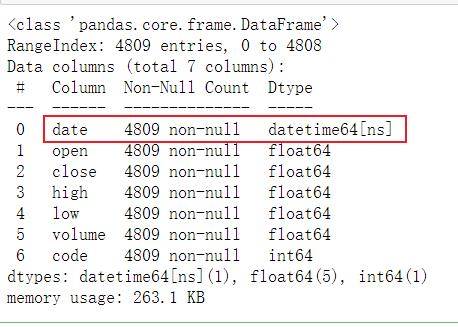
# 6. 将date这一列作为原数据的行索引
df.set_index('date',inplace=True)
df
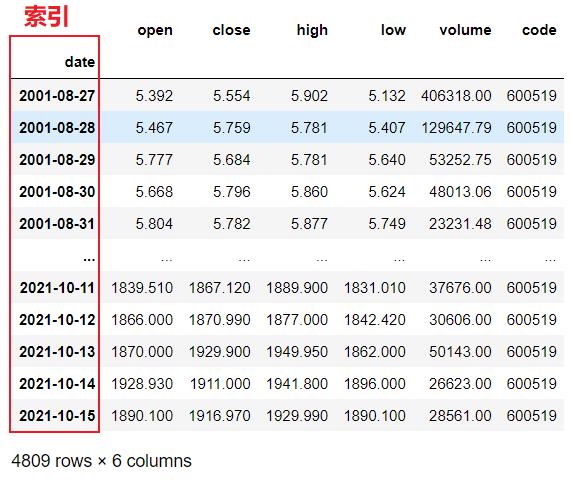
2. 输出该股票所有收盘比开盘上涨3%以上的日期
# 1.(收盘-开盘)/开盘 > 0.03
(df['close']-df['open'])/df['open'] > 0.03

经验:在相关操作中如果获取了一组布尔值,下一步马上将布尔值作为源数据df的行索引
# 2. 获取True对应的索引
# 将True对应的原数据取出
df.loc[(df['close']-df['open'])/df['open'] > 0.03]

loc:显式索引iloc:隐式索引
Pandas中loc和iloc函数用法详解(源码+实例)
- 取出行索引:日期时间
df.loc[(df['close']-df['open'])/df['open'] > 0.03].index
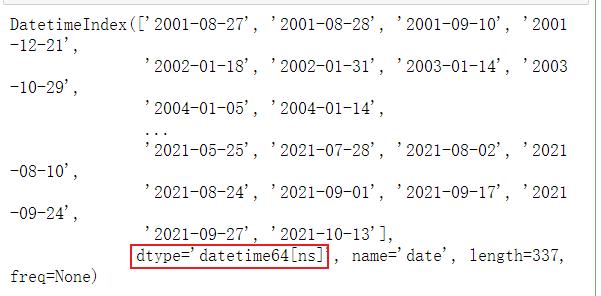
3. 输出该股票所有开盘比前日收盘跌幅超过2%日期
# 让close整体下移一行 shift
df['close'].shift(1)
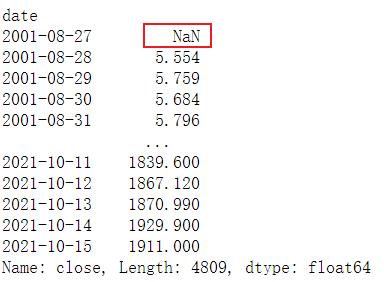
# (开盘-前日收盘)/前日收盘 < -0.02
(df['open'] - df['close'].shift(1))/ df['close'].shift(1) < -0.02
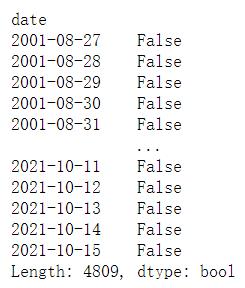
# 将布尔值作为行索引
df.loc[(df['open'] - df['close'].shift(1))/ df['close'].shift(1) < -0.02]

# 获取满足条件的日期
df.loc[(df['open'] - df['close'].shift(1))/ df['close'].shift(1) < -0.02].index

4. 假如我从2010年1月1日开始,每月第一个交易日买入1手股票,每年最后一个交易日卖出所有股票,到今天为止,我的收益如何?
分析:
- 将数据从2010切换到2021
- 买股篇:一个完整的年需要买12次股票(12手)
- 卖股票:一个完整的年,需要卖出1次股票(1200支)
- 买卖股票的单价:收盘价
- 在2021年只能买入10手股票,需要将剩余的股票价值计算到总收益中
1. 实现买入股票的操作代码
# 将数据从2010切换到2021
new_df = df['2010':'2021']
new_df
为什么可以这么切?
- 因为之前我们将行序列转换成了时间序列

找到每月第一个交易日(每月的第一行数据)的收盘价,乘以100表示买入了1手股票
df_month = new_df.resample('M').first()
df_month
# 但是该语句有显示Bug 索引是有问题的,但是数据是正确的

# 2. 以收盘价为单价买入
cost = df_month['close'].sum()*100
cost
7494947.3
2. 实现卖出股票的操作代码
# 1. 将每年的最后一个交易日的行数据取出
new_df.resample('A').last()

df_year = new_df.resample('A').last()[:-1]
df_year

# 2. 卖出股票收入多少钱
receive = df_year['close'].sum()*1200
receive
6788779.2
# 剩余股票价值计算出来
# 在2021年只能买入10手股票,需要将剩余的股票价值计算到总收益中
# 获取最近一个交易日的收盘价
last_money =1000 * new_df['close'][-1]
last_money
1916970.0
# 总收益
receive + last_money - cost
1210801.8999999994
总结
关于DataFrame的众多操作还需要巩固练习。此外,还有众多函数还未使用过,这需要不断的案例与项目进行练习才可以熟练的进行操作!
以上是关于DataFrame的级联与合并操作的主要内容,如果未能解决你的问题,请参考以下文章