消息中间件之RabbitMQ
Posted ,zdc
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了消息中间件之RabbitMQ相关的知识,希望对你有一定的参考价值。
何为中间件
中间件是将具体业务和底层逻辑解耦的软件,分为:MOM(消息中间件)、RPC(远程过程调用中间件)、UDA(数据访问中间件)、TPM(交易中间件)等。
消息中间件,又称为消息队列、消息队列中间件,分为RabbitMQ、ActiveMQ、Kafka等。
原理
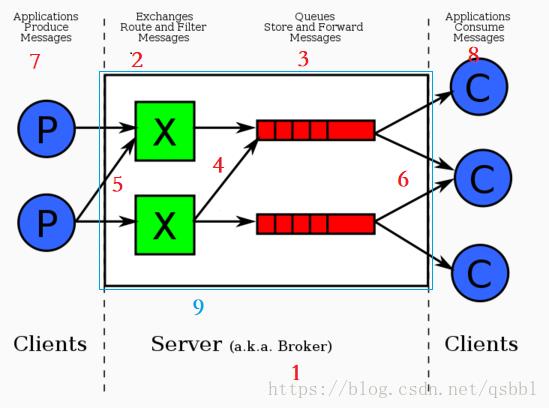
各部分的名字和作用?
1.Brocker:消息队列服务器实体,Rabbitmq可以作为一个选择。
2.Exchange:消息交换机,用于接收、分配消息。指定消息按什么规则,路由到哪个队列。
3.Queue:消息队列,用于存储生产者的消息。每个消息都会被投入到一个或者多个队列里。
4.Binding Key:绑定关键字,用于把交换器的消息绑定到队列中,它的作用是把exchange和queue按照路由规则binding起来。
5.Routing Key:路由关键字,用于把生产者的数据分配到交换器上。exchange根据这个关键字进行消息投递。
6.Vhost:虚拟主机,一个broker里可以开设多个vhost,用作不用用户的权限分离。
7.Producer:消息生产者,就是投递消息的程序。
8.Consumer:消息消费者,就是接受消息的程序。
9.Channel:信道,消息推送使用的通道。可建立多个channel,每个channel代表一个会话任务。
使用流程
使用流程?
1.消息接收客户端连接到消息队列服务器,打开一个channel。
2.客户端声明一个exchange,并设置相关属性。
3.客户端声明一个queue,并设置相关属性。
4.客户端使用routing key,在exchange和queue之间建立好绑定关系。
5.消息发布客户端投递消息到exchange。
6.exchange接收到消息后,就根据消息的key和已经设置的binding,进行消息路由,将消息投递到一个或多个队列里。
总结起来就是:生产者发送一条消息给交换机——交换机根据关键字匹配到对应的队列——将消息存入队列——消费者从队列中取出消息使用。
队列模式
在官网中有明确的说明:http://www.rabbitmq.com/getstarted.html
1.简单队列模式:一个生产者对应一个消费者。

2.工作队列模式:一个生产者产生的消息可以供多个消费者消费,但是一个消息只能被其中一个消费者消费。
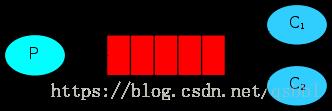
3.发布/订阅模式:多了一个交换机,生产者将消息发送到交换机上,交换机发送消息给各个队列,此时,一个消息可以被多个消费者获取。
值得一提的是,这又叫广播模式,是最常用的模式了,在ITOO中使用的就是这种模式。

4.路由模式:又多了一个routing key,生产者发送消息带有routingkey,消费者选择自己需要的消息进行消费,也配置一个routing key。

5.主题模式:又多了一个通配符,这样消费端如果需要好几种消息的时候,不用一个一个的设置,直接用通配符可以接收自己想要的各种消息。

6.RPC(远程调用):c对s说“我这有个任务需要你的帮助”,s处理完后,将结果返回给c。

为什么选择rabbitMQ
1.除了Qpid,RabbitMQ是唯一一个实现了AMQP标准的消息服务器;
2.可靠性,RabbitMQ的持久化支持,保证了消息的稳定性;
3.高并发,RabbitMQ使用了Erlang开发语言,Erlang是为电话交换机开发的语言,具备高并发和高可用特性;
4.集群部署简单,正是因为Erlang使得RabbitMQ集群部署变的超级简单;
5.社区活跃度高,根据网上资料来看,RabbitMQ也是首选;
应用场景
RabbitMQ以至于MQ的应用场景有4个:异步处理、应用解耦、流量削峰、日志处理。
异步处理
案例:用户下单后,订单系统完成持久化处理后,将消息写入消息队列,返回用户订单下单成功。
库存系统订阅下单信息(消息队列),采用拉/推的方式,获取下单信息后,进行库存操作。
流量削峰
在秒杀活动中,极短的时间内,有大量的请求涌入,如果都从数据库层面操作,就会让数据库瘫痪。
解决办法就是加入消息队列,这样就将请求“积压”在了消息队列中,数据库能尽可能多地调用就调,调用不了的可以先存着。
当然,消息队列也有满的时候,如果超过了容量,它就会直接抛弃用户请求或跳转到错误页面。
日志处理
日志处理和流量削峰的过程大致一样,解决的是大量日志传输的问题。Rabbitmq也能进行日志处理,但是我们一般使用Kafka进行日志处理。
kafka和RabbitMQ的区别
1.应用场景方面
RabbitMQ:用于实时的,对可靠性要求较高的消息传递上。
kafka:用于处于活跃的流式数据,大数据量的数据处理上。
2.语言方面
RabbitMQ是由内在高并发的erlanng语言开发,用在实时的对可靠性要求比较高的消息传递上。
kafka是采用Scala语言开发,它主要用于处理活跃的流式数据,大数据量的数据处理上
3.吞吐量方面
RabbitMQ:支持消息的可靠的传递,支持事务,不支持批量操作,基于存储的可靠性的要求存储可以采用内存或硬盘,吞吐量小。
kafka:内部采用消息的批量处理,数据的存储和获取是本地磁盘顺序批量操作,消息处理的效率高,吞吐量高。
4.Brokerr与Consume交互方式不同
RabbitMQ 采用push的方式
kafka采用pull的方式
5.集群负载均衡方面
RabbitMQ:本身不支持负载均衡,需要loadbalancer的支持
kafka:采用zookeeper对集群中的broker,consumer进行管理,可以注册topic到zookeeper上,通过zookeeper的协调机制,producer保存对应的topic的broker信息,可以随机或者轮询发送到broker上,producer可以基于语义指定分片,消息发送到broker的某个分片上。
相关知识
AMQP理论
即Advanced Message Queuing Protocol,一个提供统一消息服务的应用层标准高级消息队列协议,RabbitMQ遵循此协议。
ACK机制
每次消费者取出消息时会通知队列,我拿到了,当队列接收到这条消息,就会把消息删除,这是默认的ACK机制。如果在接收消息之后,消费者挂掉,或者任何情况没有返回ack,队列中这条消息将不会删除,可以一直存着,等待其他消费者来取。
Erlang
我们知道,安装Rabbitmq时,需要先下载安装Erlang。因为Rabbitmq是由Erlang语言编写的。
参考:
以上是关于消息中间件之RabbitMQ的主要内容,如果未能解决你的问题,请参考以下文章