了解CV和RoboMaster视觉组比赛中的CV算法(中)目标检测的常见概念和术语
Posted NeoZng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了了解CV和RoboMaster视觉组比赛中的CV算法(中)目标检测的常见概念和术语相关的知识,希望对你有一定的参考价值。
--NeoZng[neozng1@hnu.edu.cn]
5.2.3.目标检测
利用CNN我们已经可以完成对图像的识别和分类。但是这样是远远不够的,为了能准确定位图像中的物体,我们需要对图像中所有目标进行定位(找出框住目标的bounding box外接矩形框,即[cx,cy,w,h]四个参数,分别表示目标中心在图像中的坐标和bbox的长宽)。此部分会介绍几个经典的目标检测网络实现的原理和方法。
有同学可能会想,那我直接让网络在全连接层后输出一个向量而不是标量(分类),即多输出四个坐标也就是8个值,分别代表图像中目标的四个角点不就行了吗?确实,对于只有一个目标的图像我们可以这么做,可惜倘若图像中有多个目标的话,网络的输出就变成不确定的了(需要一次性输出不确定长度,分别表示每个目标框中心、长宽和其对应的分类),我们是无法训练一个没有确定输出的网络的。
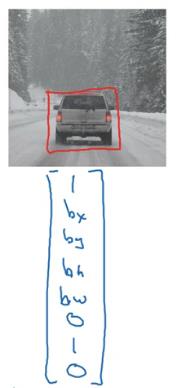
目标定位方法,得到一个WxH到1x9向量的映射
1代表有目标在图像中,随后四个数代表中心坐标和目标框的长宽,最后四个数表示目标分类
因为图像分类是对整张图像进行的,是一个WxH维到一个确定的标量或向量(如上面说的同时进行分类和回归)的映射,标准的CNN方法显然无法完成一张图片中多个对象的分类和定位操作。不过机智的你应该已经想到,我们可以把图片拆成很多的部分,然后将这些子图分别投入CNN从而得到它们对应的分类,不就把里面的对象定位出来了么。
没错,这就是密集采样的定位思想,也是最早的目标检测方法。使用滑动窗口来检测目标位置的方法和模板匹配有些类似。还有一种方法是将图像用不同的长度划分格点,在每个格点中进行图像分类(这其实是一种特殊的滑动窗口方法,即设定滑动步长大小使其与窗口的大小相同)。

采用不同大小的滑动窗口,裁取图像的一部分投入CNN得到分类(图中只使用了一种大小)
显然,这种方法的缺点也非常明显:超高的计算开销。步长设置的过大可能会发生漏检,而为了检测大小不同的目标,我们又需要采用各种大小的窗口来运行CNN,同时还可能需要使用不同长宽比的窗口来应对物体长宽比不同的情况(例如汽车在侧面看是细长的矩形,正面又比较接近正方形,如果仅使用一种类型的窗口,则可能会出现定位不精确的问题,得到的定位框包含了大量的背景)。

使用滑动窗口方法可能出现的问题,没有一个滑窗能够和汽车整体匹配
仔细观察,我们就会发现,在目标检测问题中,我们面临的最大困难就是候选区域太多且目标大小的尺度不一,问题的搜索空间过于庞大,我们难以用暴力搜索穷举全部解。于是two-stage方法的代表作R-CNN(region proposal-CNN)横空出世。不过,再介绍R-CNN之前,先让我们看看目标检测中常用的术语和概念吧。
-
常用术语和概念
-
GT(ground truth)
GT可以理解为真实值、有效值、正确的答案、正确的标注信息。对于目标检测来说,标记的坐标点和标记分类就被称作ground truth。
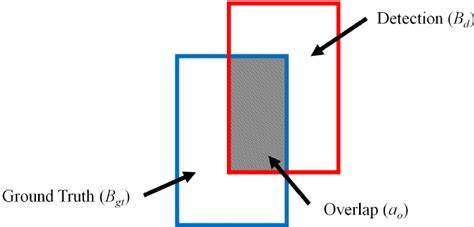
训练标记的bbox区域(蓝色区域)就是ground truth
在目标检测网络的推理过程中,如何为预测框分配标签(训练的label即GT的属于的分类)会极大地影响训练的效率和推理的准确度,这也是当前目标检测研究的热点和难点。
-
IOU(intersection of Union)
字面意思。两个bbox的交集和并集的比例,详见上方GT的插图,灰色区域为交集面积,除以两个bbox的并集就得到交并比。交并比是衡量检测生成bbox的准确性的一个指标。现在也出现了一些其他用于衡量预测框质量的指标。
-
正/负样本(positive/negative sample)
在目标检测中,包含了目标的bbox就是正样本,而没有包含目标即bbox内是背景的将被作为负样本。当然一些网络会对正负样本进行特殊定义。特别注意,我们是根据训练标注来生成正负样本的,并不是说训练标注中地GT就是正样本,其他区域都是负样本。我们会依据某种准则如与GT的IOU或置信度进而由得到正负样本。

我们的检测目标是杯子,假设网络生成了4个检测框,认为这里面有杯子,那么根据特定的IOU阈值如0.5,我们将生成的4个检测框分别作为正负样本对待;在这里红色框是GT,紫色和蓝色框因为和GT的IOU超过50%被记为正样本,绿色框则被判定为负样本(背景)
在阅读了下一篇文章的几个经典网络后再回来看看,你应该会对正负样本有新的理解。并且目标检测中有一个很大的、亟待解决的问题就是正负样本、难易样本的失衡。(在一张图片中,没有目标存在的区域占了全图的绝大部分,负样本即背景类占了所有样本的大多数,大量负样本在训练时会淹没正样本,导致神经网络失去鉴别能力对负样本产生过拟合)
正负样本的划分策略和不平衡问题同样是目标检测的难点。
-
ConvNet和特征图
ConvNet一般值的是神经网络的backbone(骨干网络),也就是负责提取图像特征的部分,即我们在上面讲解CNN的时候由卷积层和池化层堆叠起来的block。特征图就是经过n个block之后产生的“图片”,因为原图的特征被提取到这些小”图片“上所以我们称之为特征图。简言之经过卷积或池化处理的图片或特征都可以被称作特征图,上面记录着原图的某些特征。
-
感受野(receptive field)
从这个术语的名字应该可以略知一二。receptive field是高层feature map上的一个点的信息是由原图或之前的feature map中多大的范围/面积的像素所贡献的度量。换个简单句:原图上的某个像素或低层次的feature map是否和高层中的feature map上的某个点有关联/间接连接?再或者直接看图:
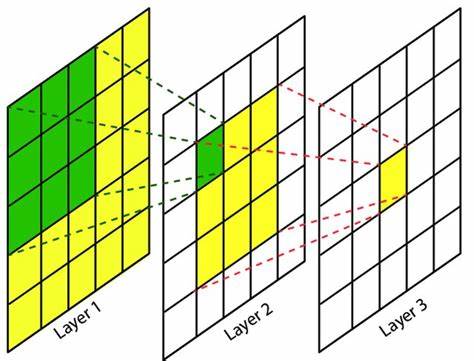
绿色区域是l2中左上角像素的感受野,而黄色区域是l3中间像素的感受野
有许多扩大感受野的方法如变步长卷积、空洞卷积、膨胀卷积、focus层等我们稍后介绍。其实这个概念应该在CNN部分就进行介绍,但是由于图像分类对此并不敏感所以将介绍移到了此处。
-
NMS(非极大值抑制)
在生成检测框的时候,可能会出现下图这种情况,这时候我们要根据框的置信度或定位精度等信息筛去一些重叠区域很大的目标框,防止出现重复检测的情况。这里给出了NMS的大致介绍和实现源码:NMS 在目标检测中的应用。

-
性能指标与mAP(mean average precision)
mAP是目标检测中最常见的测试检测器性能的指标。在次之前先让我们看看混淆矩阵,这是机器学习中所有分类器都要确定的一个参数:

混淆矩阵和对应的概念含义
由混淆矩阵中的数据,我们可以通过各种运算来得到千奇百怪的指标,常见的如正确率、真阳性率、特异度、假阴性率(漏诊率)、Youden指数等。我们则选择mAP来指示一个目标检测算法的性能,mAP的计算需要查准率(true positive rate,precision: TP/(TP+FP) )和查全率(又叫召回率recall,计算通过TPR:true positive rate,TP/(TP+FN) )两个信息。这两个指标是一对矛盾指标,当查准率高的时候,说明分类器很少把负类分为正类,只遴选那些最优把握、正类置信度高的样本,显然分类为正类的样本TP+FP将会下降(置信度上升,分类器把更少的样本分为正类),同时查全率必然跟着下降,很多正样本将会成为漏网之鱼而被分类为负样本。当降低阈值希望尽可能多地把所有的正类的查出来,那么很多置信度较高的负类同样容易被分为正类,导致查准度下降。
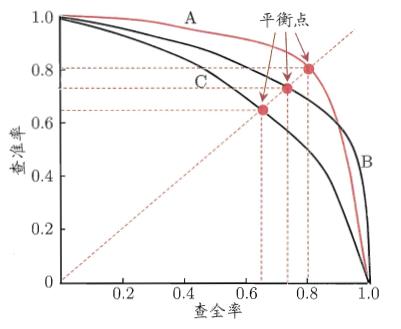
找到曲线上的平衡点,即边际效用最大的点,当继续往曲线的右侧移动,查全率上升的速度将会低于查准率下降的速度
目标检测任务中判断预测框的正负样本一般以IOU是否>0.5为准则(这里的分类是说预测框里有没有物体的置信度,而对预测框中物体的分类准确度测试则是直接通过分类置信度进行)。那么如何绘制处pr曲线?一般的测试方法是设定一个IOU阈值(如0.5则预测框和GT的IOU大于0.5会被判别为正例),在此阈值下根据不同的查全率水平计算查准率(当然如MSCOCO等更全面的数据集采用的方法是将IOU阈值设定为[0.5,0.95]步长为0.05,对这些阈值水平分别进行测试再求平均。AP就是PR曲线下方的面积(为什么用曲线下的面积,而不用平衡点处的分类器性能作为指标?),称作average precision即平均精度。而mAP是把每个类的AP曲线下的面积进行加权平均,即可算出多分类的平均精确度。
但是mAP也有一个问题,就是正负样本的数量不同的时候会导致PR曲线严重失衡(从precision和recall计算方法想想为什么),而ROC和AUC就不会出现这个问题,因此这两个指标在分类器性能测试中也很常用。
得到ROC曲线需要查全率和误诊率两个指标。查全率TPR在上面已经介绍过,这里再介绍false positive rate:它被称做假阳性率、误诊率和伪正类率,表示所有被分类器判别为正类的样本有多少实际上是负类(假正类在所有判别为负类的样本中的占比,FPR=FP/(TN+FP) ),同样会反映分类的精确程度(同样你可以思考一下为什么在正负样本比例失衡的时候ROC曲线不会变形?)。
和PR曲线的绘制相同,我们设置不同的分类置信度阈值进而在不同的查全率水平下测试得到准确率,即可获得ROC曲线。ROC曲线下方的面积AUC即area under curve同样也有一些含义。使用AUC值作为评价标准是因为很多时候ROC曲线并不能清晰的说明哪个分类器的效果更好(阈值不同且指标不同),而作为一个数值,对应AUC更大的分类器效果更好,其具体含义为:当随机挑选一个正样本和一个负样本,根据当前的分类器计算得到的score(置信度)将这个正样本排在负样本前面的概率。下图中的(b)可以帮助你更好、更直观地理解ROC曲线的含义,竖线处theta即设置的分类置信度。
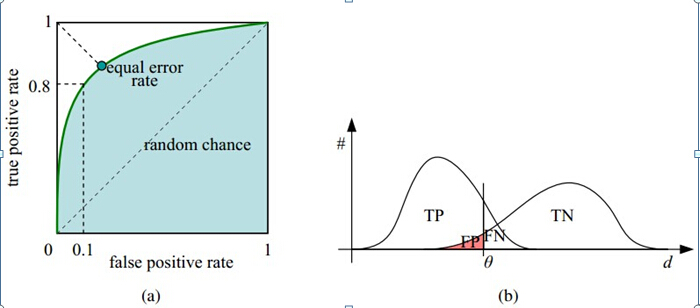
看此图理解起来没问题/有新的启发就说明你大概掌握了这些概念
如果还是没懂也没关系,就把它们当作衡量训练得到的预测器的好坏的指标即可,这个指标越大越好!
-
公开数据集
列出几个最常用的目标检测公开/比赛数据集:
-
VOC(isual object classes chanllenges)2005-2012
经典的计算机视觉竞赛,任务包括图像分类、目标检测、语义分割和动作检测。20个种类。 VOC07和VOC12最为常用。近年来被更大的数据集像ILSVRC和MS-COCO逐渐取代。
-
ImageNet 2010-2017
训练数据集包含500,000张图片,属于200类物体。由于数据集太大,训练所需计算量很大,因而很少使用。同时,由于类别数也比较多,目标检测的难度也相当大。一般不会用作检测网络的性能,二是作为训练使用。
-
MSCOCO(microsoft common objects in context)2015-now
看名字就知道是巨硬家的。最大的特点是除了bounding box 注释,还给了segmentation标注。MS-COCO也包含更多的小目标(面积小于图像大小的百分之一)和稠密的目标。这些特征使得MS-COCO更接近于现实生活。MS-COCO已经成了目标检测家族中的实际标准。
-
-
-
如果觉得笔者总结得还可以,请点一个赞,关注一下笔者吧!还可以把文章转发给对cv感兴趣的同学和其他RMer。
-
下次更新重磅内容,R-CNN!
以上是关于了解CV和RoboMaster视觉组比赛中的CV算法(中)目标检测的常见概念和术语的主要内容,如果未能解决你的问题,请参考以下文章