经典论文解读YOLOv4 目标检测
Posted 一颗小树x
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了经典论文解读YOLOv4 目标检测相关的知识,希望对你有一定的参考价值。
前言
YOLO是一种目标检测方法,它的输入是整张图片,输出是n个物体的检测信息,可以识别出图中的物体的类别和位置。YOLOv4是在YOLOv3的基础上增加了很多实用的技巧,使得速度与精度都有较大提升。v4版本设计思路如下:
输入端:在模型训练阶段,使用了Mosaic数据增强、cmBN跨小批量标准化、SAT自对抗训练;
BackBone层:也称主干网络,使用CSPDarknet53网络提取特征;同时使用Mish激活函数、Dropblock正则化;CSP 跨阶段部分连接。
Neck中间层:这是在BackBone与最后的Head输出层之间插入的一些层,Yolov4中添加了SPP模块、FPN+PAN结构;也支持“多尺度特征检测”,三种输出特征图分为19*19、38*38、76*76,对应检测大物体、中等物体、小物体。
Head输出层:输出层的锚框机制与YOLOv3相同,其中通过聚类提取先验框尺度,并约束预测边框的位置。主要改进的是训练时的损失函数CIOU_Loss,以及预测框筛选的DIOU_nms。
论文地址:YOLOv4: Optimal Speed and Accuracy of Object Detection
Pytorch-YOLOv4 开源代码:https://github.com/Tianxiaomo/pytorch-YOLOv4
Tensorflow 2-YOLOv4 开源代码:https://github.com/hunglc007/tensorflow-yolov4-tflite
目录
一、网络结构
1.1 输入输出映射
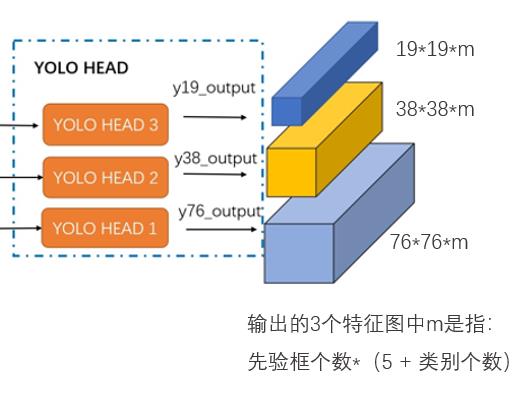
输入一张608*608的图像,CSPDarknet-53 网络后得到了 3 个分支,这些分支在经过SSP+PAN结构最终得到了三个尺寸不一的 feature map,形状分别为 [19, 19, m]、[38, 38, m] 和 [76, 76, m]。
输出的3个特征图中的m是指: 先验框个数*(5 + 类别个数)
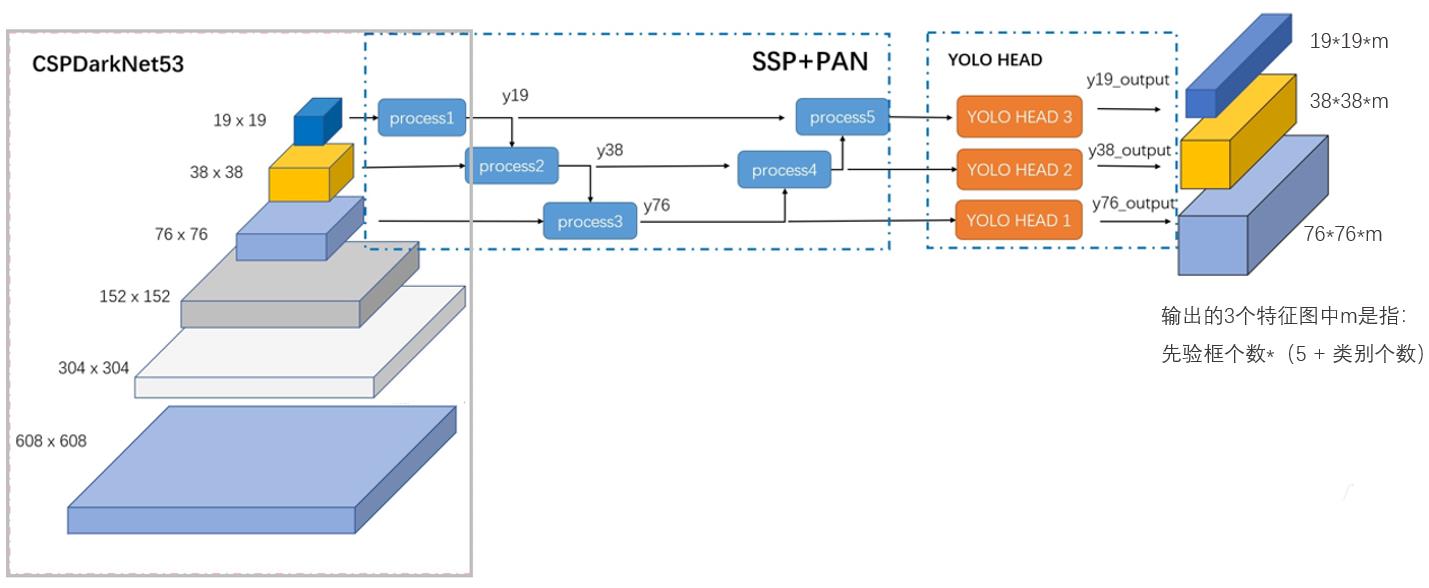
1.2整体网络结构
整体网络可以分为4部分组成,分别是输入端、BackBone主干网络、Neck连接结构、Prediction Head输出然后预测。 先看一下整体的网络结构:
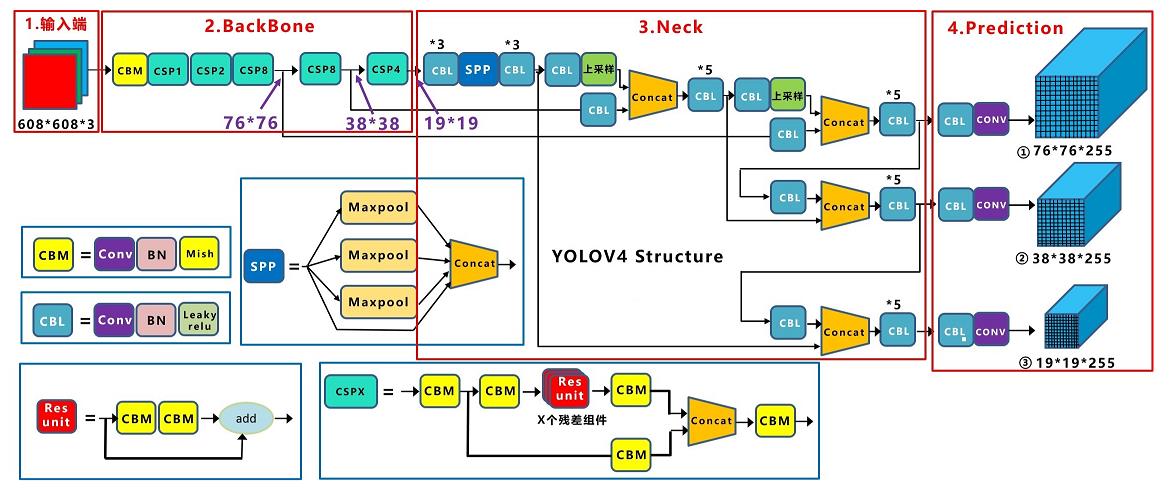
- 输入端,输入608*608的图像,进行图像预处理;其中Mosaic数据增强,提升模型的训练速度和网络的精度;cmBN及SAT自对抗训练来提升网络的泛化性能。
- BackBone主干网络,用于提取图像特征;v4版本使用CSPDarknet53作为主干网络。使用Mish激活函数代替原始的RELU激活函数;增加了Dropblock正则化来进一步提升模型的泛化能力,降低过拟合风险 。
- Neck连接结构,用于连接BackBone主干网络 和 Head输出层,通过设计“Neck连接结构”可以提升特征的多样性及鲁棒性。使用SPP结构,融合不同尺度大小的特征图,解决不同尺寸的特征图如何进入全连接层,对任意尺寸的特征图直接进行固定尺寸的池化,来得到固定数量的特征。使用PAN结构,代替FPN进行参数聚合以适用于不同level的目标检测。
- Head输出层,用来完成目标检测结果的输出。用CIOU_Loss来代替Smooth L1 Loss函数,并利用DIOU_nms来代替传统的NMS操作,从而进一步提升算法的检测精度。
基础组件,包括CBM、CBL、Res unit、CSPX、SPP。
1.3 基础组件CBM
CBM,由Conv+BN+Mish激活函数组成。
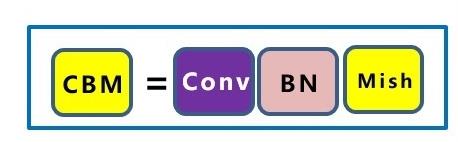
Conv 是卷积层,用来提取特征;
BN,batch normalization 批归一化:
网络中的位置:在“该层网络输出后”和“激活函数之前”增加一个BN层。
批归一化的处理:对该层网络输出的特征量分别进行归一化处理,分别使每个特征的数据分布变换为均值0,方差1。特征值数范围控制在[0,1]之间。
批归一化的效果:有助于解决反向传播过程中的梯度消失和梯度爆炸问题,降低对一些超参数(比如学习率、网络参数的大小范围、激活函数的选择)的敏感性,并且每个batch分别进行归一化的时候,起到了一定的正则化效果,从而能够获得更好的收敛速度和收敛效果。
Mish,是一种激活函数。Mish与ReLU、Swish非常相似,但Mish可以在不同数据集的许多深度网络中胜过它们,Mish公式:
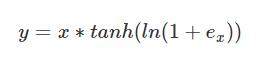
Mish是一个平滑的曲线,平滑的激活函数允许更好的信息深入神经网络,从而得到更好的准确性和泛化;在负值的时候并不是完全截断,允许比较小的负梯度流入。
看看Mish、ReLU、SoftPlus 和 Swish 激活函数的图:
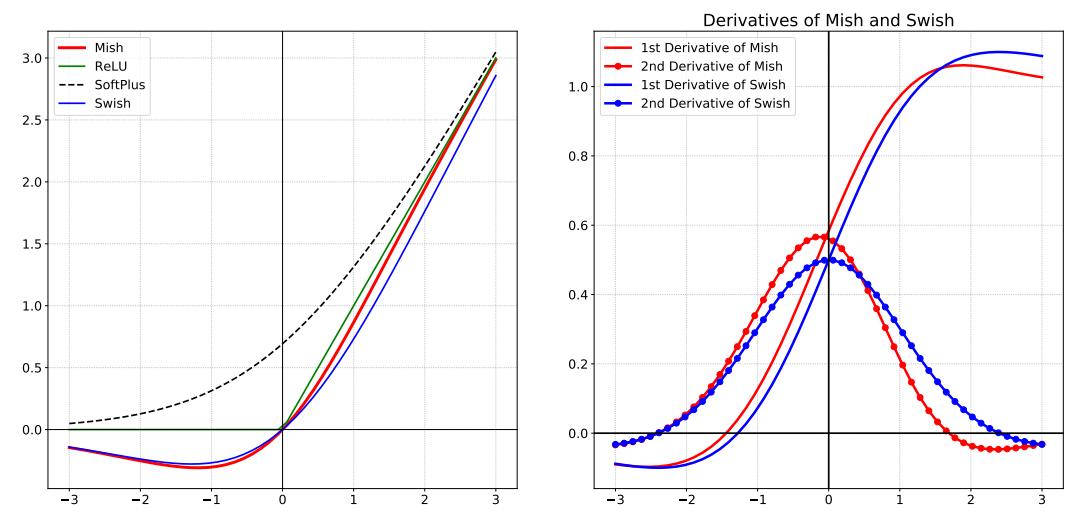
Mish论文地址: https://arxiv.org/pdf/1908.08681.pdf
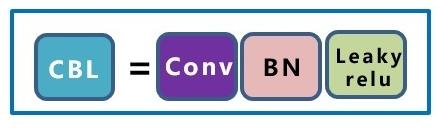
1.4 基础组件CBL
CBL,由Conv+BN+Leaky_relu激活函数组成。
Conv、BN 上面介绍过了,这里主要介绍Leaky_relu激活函数。 公式:
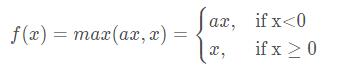
其中a通常会设为0.01。
Leaky_relu与ReLU很相似,仅在输入小于0的部分有差别,ReLU输入小于0的部分值都为0,而Leaky_relu输入小于0的部分,值为负,且有微小的梯度。看看ReLU、Leaky_relu激活函数的图:
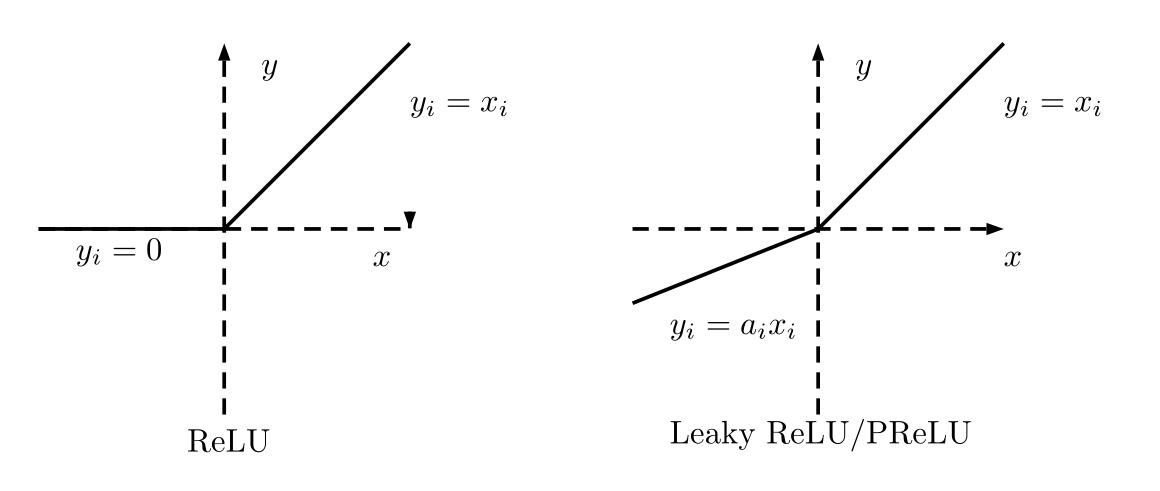
Leaky_relu 优点:在反向传播过程中,其输入小于零的部分,也可以计算得到梯度(而不是像ReLU一样值为0),这样就避免了上述梯度方向锯齿问题。
1.5 基础组件Res unit
Res unit,借鉴ResNet网络中的残差结构,用来构建深层网络,CBM是残差模块中的子模块。
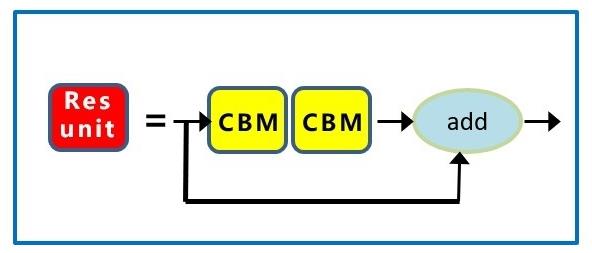
这里主要介绍一下残差结构。
ResNets残差结构解决深度神经网络的“退化”问题。其中退化”指的是,给网络叠加更多的层后,网络深度在增加,性能却快速下降的情况。随着网络深度增加,会出现梯度消失或 梯度爆炸。梯度消失会导致梯度变为 0 ;梯度爆炸会导致梯度太大。
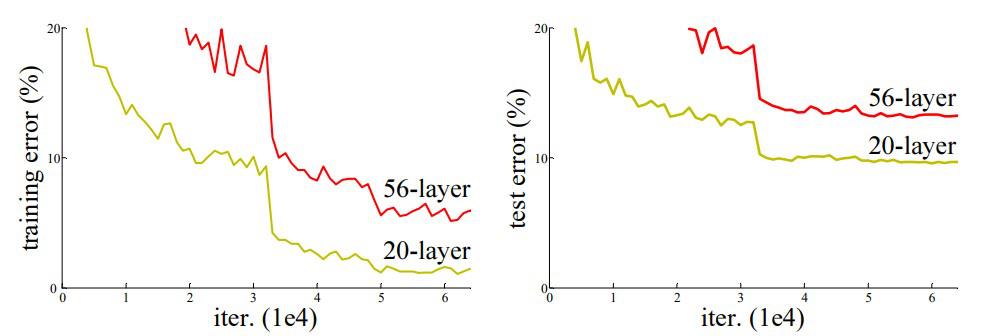
在上图中,我们可以观察到 56 层 CNN 在训练和测试数据集上的错误率都高于 20 层 CNN 架构,如果这是过度拟合的结果,那么56层CNN应该中具有更低的“训练错误”,但它也有更高的训练误差。在对错误率进行更多分析后,ResNet作者得出结论,这是由梯度消失/爆炸引起的。
微软研究院的研究人员于 2015 年提出的 ResNet 引入了一种名为 Residual Network 的新架构。
残差块:
为了解决梯度消失/爆炸的问题,该架构引入了残差网络的概念。在这个网络中,我们使用一种称为跳过连接的技术。跳过连接,从几层跳过训练,并直接连接到输出。
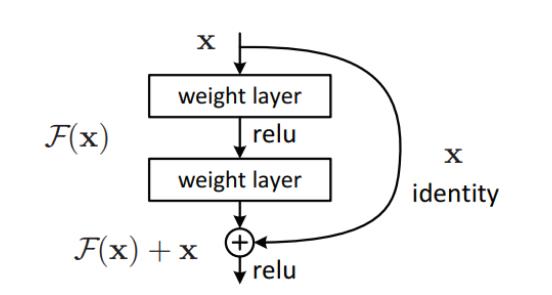
添加这种类型的跳过连接的好处是,如果任何层损害了架构的性能,那么它将被正则化跳过。因此,这导致训练非常深的神经网络,而不会出现梯度消失/爆炸引起的问题。
其中输出H(x),H(x) = F(x) + x。x是输入信息。F(x)是输入信息经过一些层的特征提取得出的结果。
该结构是让网络拟合残差映射,F(x) = H(x) – x。
1.6 基础组件CSPX
CSPX,借鉴CSPNet网络结构,由卷积层和X个Res unint模块Concate组成而成。
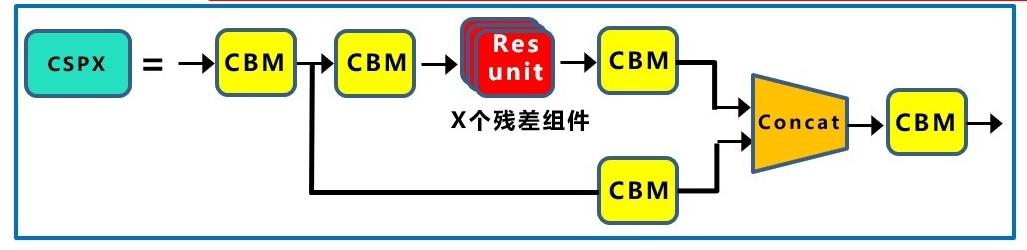
首先介绍一下Concate 结构,然后介绍CSPNet网络结构。
Concate,用于将特征联合;是通道数的合并,也就是说描述图像本身的特征增加了,而每一特征下的信息是没有增加。
1.7 基础组件 SPP
SPP,采用1×1、5×5、9×9和13×13的最大池化方式,进行多尺度特征融合。
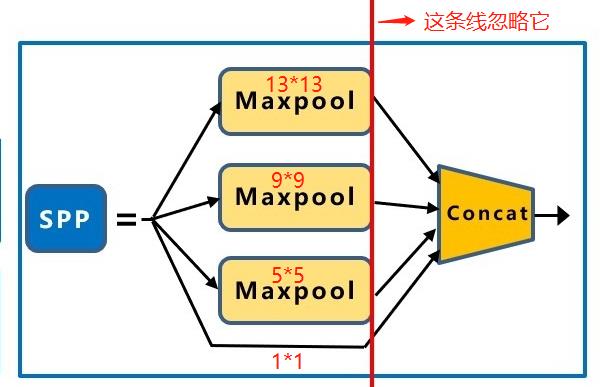
SPP结构,能融合不同尺度大小的特征图;用来解决不同尺寸的特征图如何进入全连接层,对任意尺寸的特征图直接进行固定尺寸的池化,来得到固定数量的特征。
然后将每个池化得到的特征合起来即得到固定长度的特征个数(特征图的维度是固定的),接着就可以输入到全连接层中进行训练网络了。SPP能增加感受野。
二、输入端
输入端:在模型训练阶段,使用了Mosaic数据增强、cmBN跨小批量标准化、SAT自对抗训练;
2.1 Mosaic数据增强
Mosaic 是一种数据增强方法,将 4 张训练图像组合成1张进行训练。

作用:增强了对正常背景(context)之外的对象的检测。每个 mini-batch 包含大量的图像,使用Mosaic后:是原来 mini-batch 所包含图像数量的 4 倍,因此,减少了估计均值和方差的时需要大mini-batch的要求。
2.2 cmBN跨小批量标准化
BN是仅仅使用“当前迭代时刻的信息”进行归一化,而CBN在计算当前时刻统计量时候会考虑“前k个时刻”统计量,从而实现扩大batch size操作。同时作者指出CBN操作不会引入比较大的内存开销,训练速度不会影响很多,但是训练时候会慢一些。
CmBN是CBN的改进版本,其把大batch内部的4个mini batch当做一个整体,对外隔离。CBN在第t时刻,也会考虑前3个时刻的统计量进行汇合,而CmBN操作不会,不再滑动cross,其仅仅在mini batch内部进行汇合操作,保持BN一个batch更新一次可训练参数。
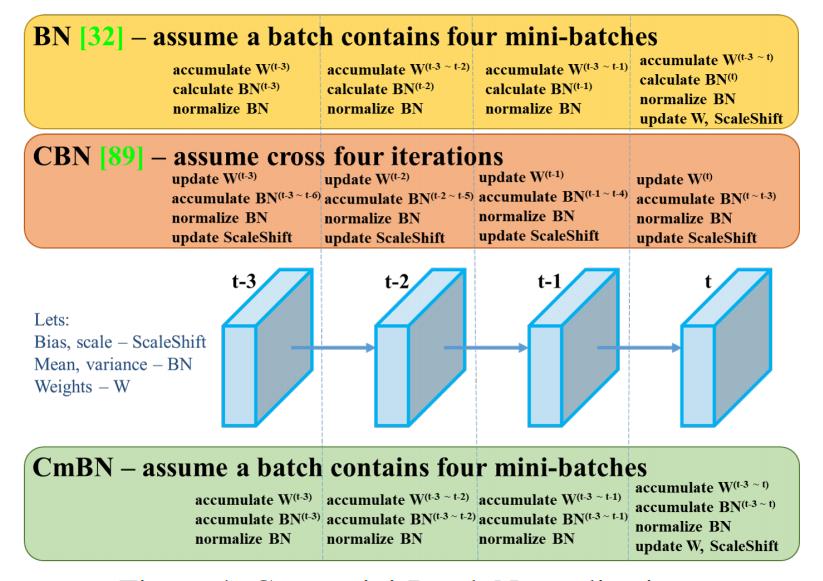
BN:无论每个batch被分割为多少个mini batch,其算法就是在每个mini batch前向传播后统计当前的BN数据(即每个神经元的期望和方差)并进行归一化,BN数据与其他mini batch的数据无关。
CBN:每次迭代中的BN数据是其之前n次数据与当前数据的和(对非当前batch统计的数据进行了补偿再参与计算),用该累加值对当前的batch进行归一化。好处在于每个batch可以设置较小的size。
CmBN:只在每个Batch内部使用CBN的方法,个人理解如果每个Batch被分割为一个mini batch,则其效果与BN一致;若分割为多个mini batch,则与CBN类似,只是把mini batch当作batch进行计算,其区别在于权重更新时间点不同,同一个batch内权重参数一样,因此计算不需要进行补偿。
2.3 SAT自对抗训练
SAT,全称Self-Adversarial Training,可以理解为自对抗训练;为一种新型数据增强方式。在第一阶段,神经网络改变原始图像而不是网络权值。通过这种方式,神经网络对其自身进行一种对抗式的攻击,改变原始图像,制造图像上没有目标的假象。在第二阶段,训练神经网络对修改后的图像进行正常的目标检测。
SAT论文:https://export.arxiv.org/pdf/1703.08603
使用对抗生成可以改善学习的决策边界中的薄弱环节,提高模型的鲁棒性。因此这种数据增强方式被越来越多的对象检测框架运用。
三、BackBone层
BackBone层也称主干网络,使用CSPDarknet53网络提取特征;同时使用Mish激活函数、Dropblock正则化;CSP 跨阶段部分连接。
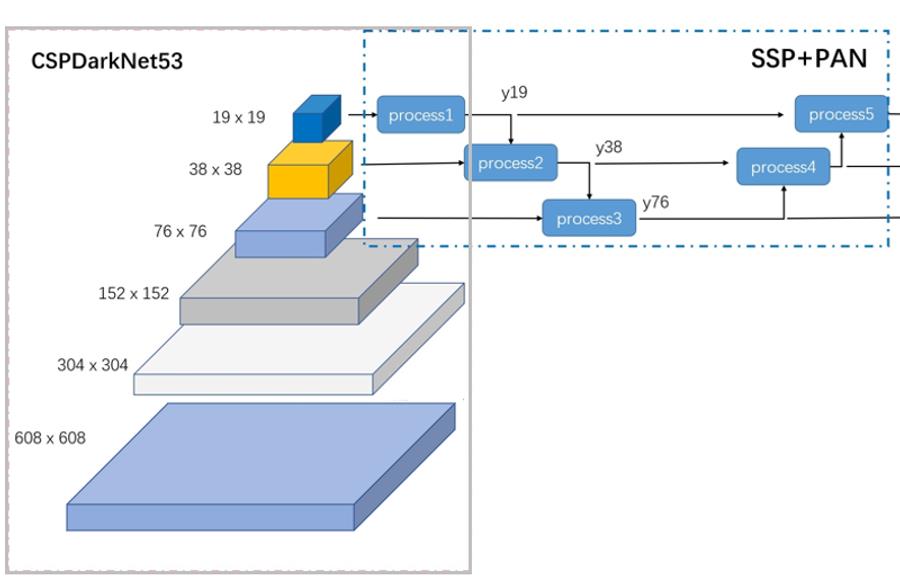
3.1 CSPDarknet53
CSPDarknet53是基于Darknet53,借鉴CSPNet,进行了一些改进,使得模型既保证了推理速度和准确率,又减小了模型尺寸。
首先介绍一下CSPNet,全称是Cross Stage Partial Networks,也就是“跨阶段局部网络”。
CSPNet解决了一些大型卷积神经网络框架Backbone中网络优化的“梯度信息重复问题”。它是将梯度的变化从头到尾地集成到特征图中,因此减少了模型的参数量。
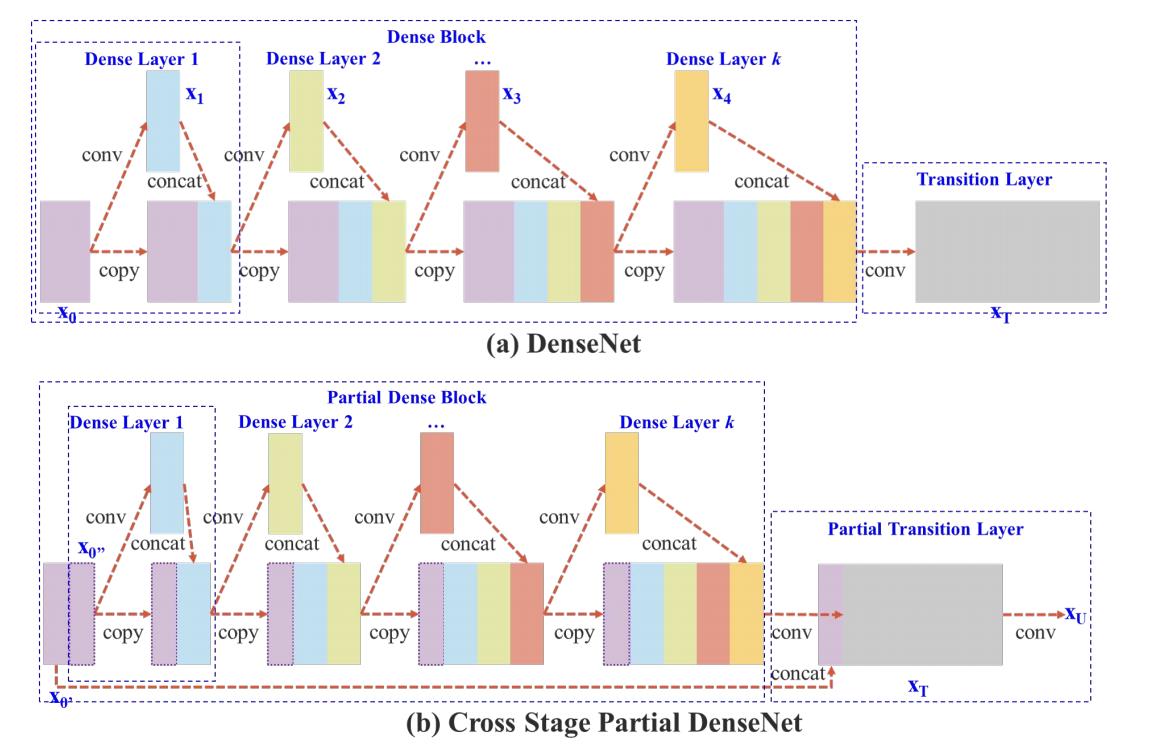
CSPNet实际上是基于Densnet的思想,“复制基础层的特征映射图”,通过dense block发送副本到下一个阶段,从而将基础层的特征映射图分离出来。这样可以有效缓解梯度消失问题(通过非常深的网络很难去反推丢失信号) ,支持特征传播,鼓励网络重用特征,从而减少网络参数数量。
CSPNet 主要从网络结构设计的角度解决推理中“计算量大”的问题。CSPNet 的作者认为推理计算过高的问题是由于“网络优化中的梯度信息重复”导致的。 因此采用CSP先将基础层的特征映射划分为两部分,然后通过“跨阶段层次结构”将它们合并,在减少了计算量的同时可以保证准确率。CSP 连接如下图所示:
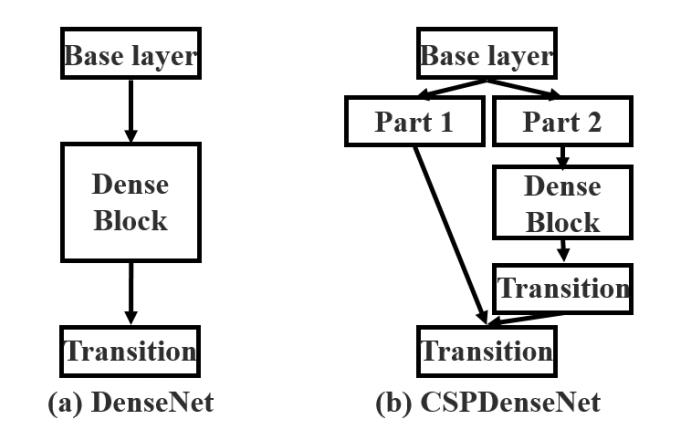
不同类型的特征融合策略: (a) 单路径 DenseNet;(b) 提出的 CSPDenseNet:转换 → 串联 → 转换。
CSPNet论文地址:CSPNet: A New Backbone that can Enhance Learning Capability of CNN
检测效果好需要以下几点:
- 更大的网络输入分辨率——用于检测小目标
- 更深的网络层——能够覆盖更大面积的感受野
- 更多的参数——更好的检测同一图像内不同size的目标
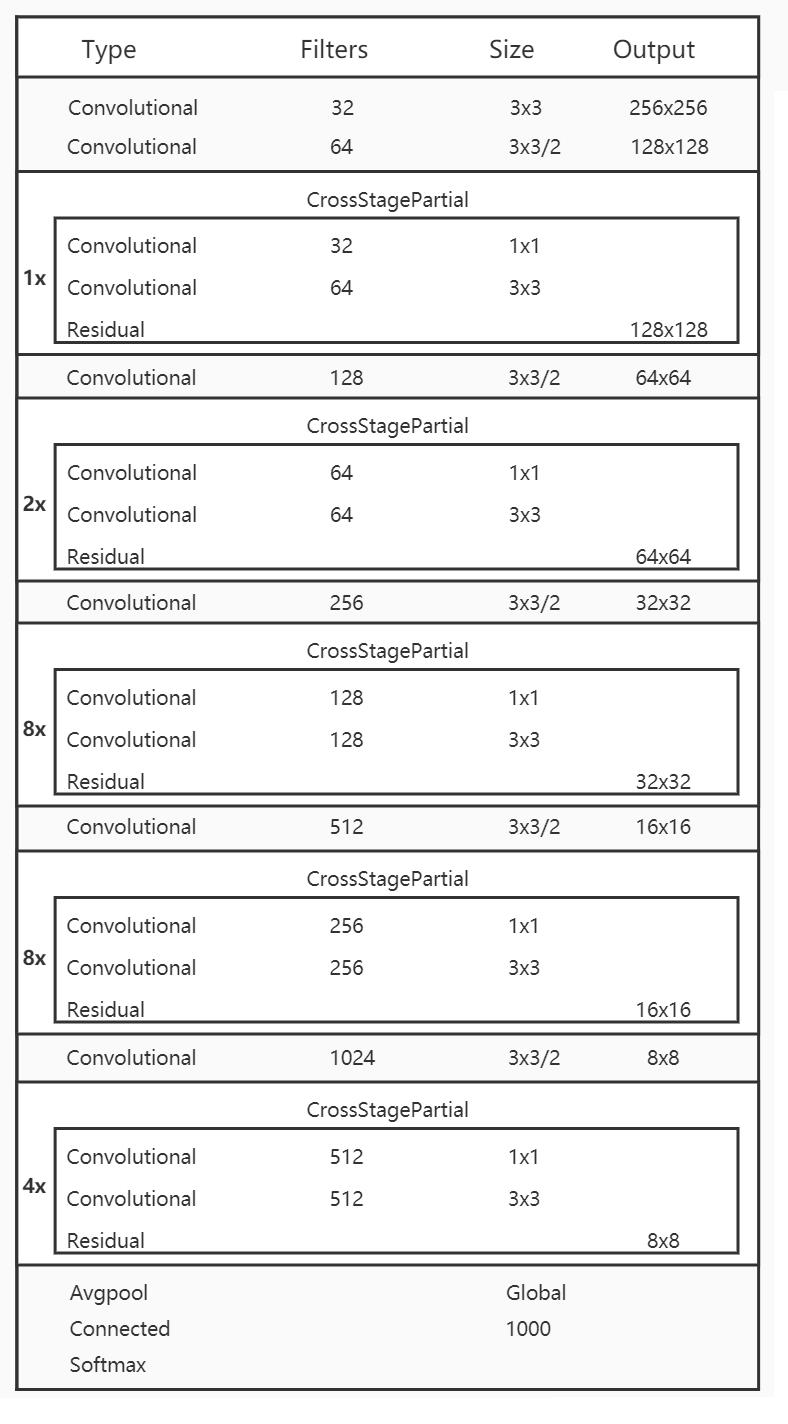
YOLOv4中,选择了具有CSP的darknet53,而是没有选择在imagenet 图像分类上跑分更高的CSPResNext50;因为在目标检测领域的精度来说,CSPDarknet53是要强于 CSPResNext50。
CSPDarknet53 结构就如下图:
3.2 Mish激活函数
Mish,是一种激活函数。Mish与ReLU、Swish非常相似,但Mish可以在不同数据集的许多深度网络中胜过它们,Mish公式:
Mish是一个平滑的曲线,平滑的激活函数允许更好的信息深入神经网络,从而得到更好的准确性和泛化;在负值的时候并不是完全截断,允许比较小的负梯度流入。
看看Mish、ReLU、SoftPlus 和 Swish 激活函数的图:
Mish论文地址: https://arxiv.org/pdf/1908.08681.pdf
3.3 Dropblock正则化
正则化技术有助于避免过拟合,对于正则化,已经提出了几种方法,如L1和L2正则化、Dropout、Early Stopping和数据增强。YOLOv4用了DropBlock正则化的方法。
DropBlock,一种解决模型过拟合的正则化方法,它的作用与Dropout基本相同。Dropout的主要思路是随机的使网络中的一些神经元失活,从而形成一个新的网络。Dropout是随机丢弃特征的,它被证明是全连接网络的有效策略,但在特征空间相关的卷积层中效果不佳。
为什么Dropout应用在全连接网络的有效,应用在卷积层中效果不佳呢?
由于卷积层通常是三层结构,即卷积+激活+池化层,池化层本身就是对相邻单元起作用,因而卷积层对于这种随机丢弃并不敏感。除此之外,即使是随机丢弃,卷积层仍然可以从相邻的激活单元学习到相同的信息。
DropBlock是“块的相邻相关区域中”丢弃特征,即:对整个局部区域进行失活(连续的几个位置)。如下图:中间的是Dropout处理效果;右边的是DropBlock处理效果。
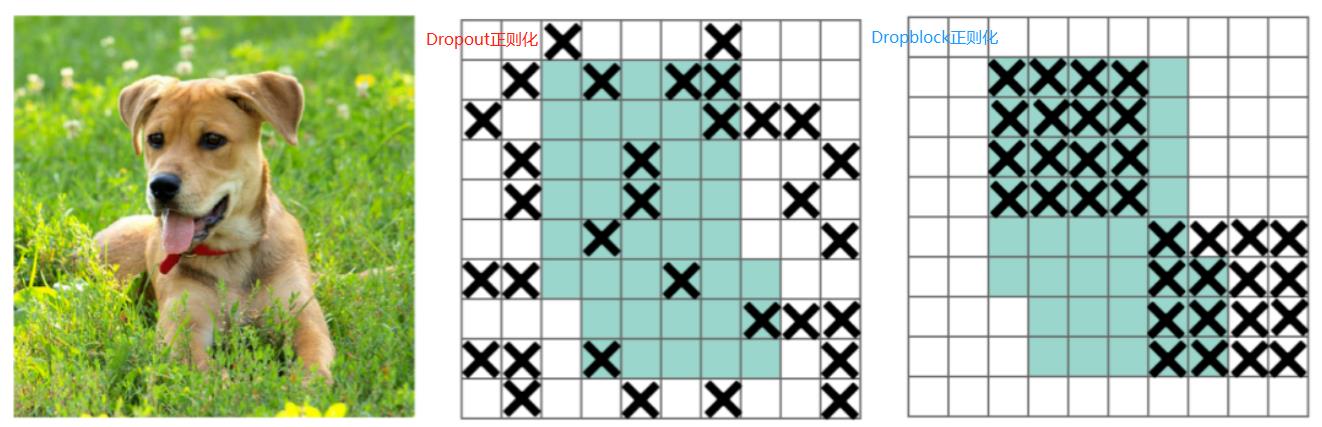
这样既可以实现生成更简单模型的目的,又可以在每次训练迭代中引入学习部分网络权值的概念,对权值矩阵进行补偿,从而减少过拟合。
DropBlock论文: https://arxiv.org/pdf/1810.12890.pdf
四、Neck中间层
Neck中间层:这是在BackBone与最后的Head输出层之间插入的一些层,Yolov4中添加了SPP模块、FPN+PAN结构。
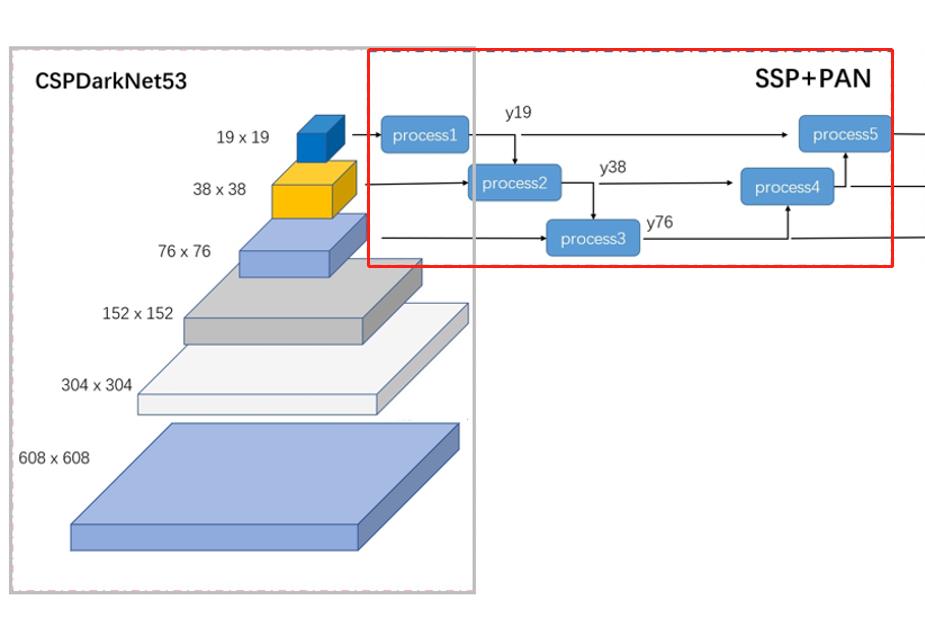
4.1 SPP模块
SPP,采用1×1、5×5、9×9和13×13的最大池化方式,进行多尺度特征融合。
SPP结构,能融合不同尺度大小的特征图;用来解决不同尺寸的特征图如何进入全连接层,对任意尺寸的特征图直接进行固定尺寸的池化,来得到固定数量的特征。
然后将每个池化得到的特征合起来即得到固定长度的特征个数(特征图的维度是固定的),接着就可以输入到全连接层中进行训练网络了。SPP能增加感受野。
4.2 PAN结构
PANet,全称Path Aggregation Network;主要用来融合不同尺寸特征图的特征信息。
下面首先介绍早期深度学习中的结构、DenseNet结构、FPN结构,最后介绍PAN结构。
在早期深度学习中,模型设计相对简单。每一层从前一层获取输入。浅层提取局部纹理和模式信息,建立后续层所需的语义信息。然而,当我们向右移动时,微调预测结果时所需的局部信息可能会丢失。
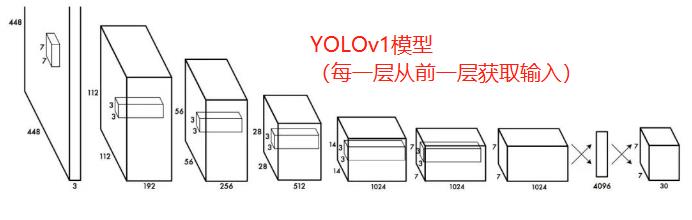
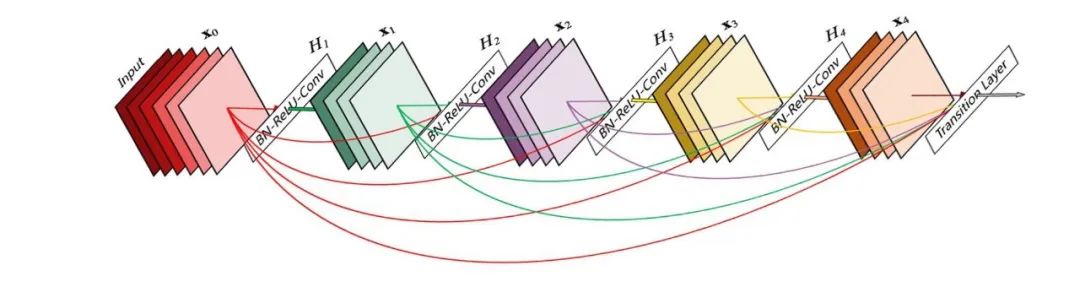
在后来的深度学习发展中,层之间的互相连接变得越来越复杂。在DenseNet,它走到了极致。每一层都与之前的所有层相连。
后面发展到FPN,其全名是Feature Pyramid Networks,中文称为特征金字塔网络;FPN的预测是在不同特征层独立进行的,即:同时利用低层特征高分辨率和高层特征的高语义信息,通过融合这些不同层的特征达到预测的效果。
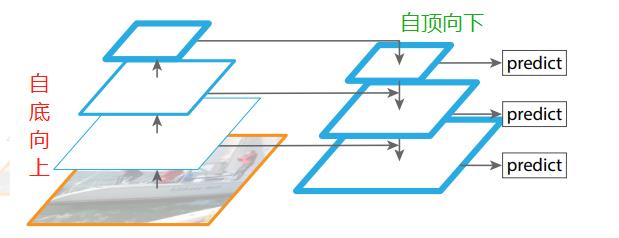
作者认为足够低层高分辨的特征对于检测小物体是很有帮助的。
自底向上的过程也称为下采样,feature map尺寸在逐渐减小,同时提取到的特征语义信息逐渐丰富。在下采样过程中,feature map的大小在经过某些层后会改变,而在经过其他一些层的时候不会改变,作者将不改变feature map大小的层归为一个stage,因此每次抽取的特征都是每个stage的最后一个层输出,这样就能构成特征金字塔。
自顶向下的过程也称为上采样(upsampling)进行,而横向连接则是将上采样的结果和自底向上生成的相同大小的feature map进行融合(merge)。其中,1*1的卷积核减少卷积核的个数,也就是减少feature map的个数,并不改变feature map的尺寸大小。
可以看看这篇文章:FPN 用于目标检测的特征金字塔网络
接着发展到了PAN,其全称Path Aggregation Network;主要用来融合不同尺寸特征图的特征信息。先看看下图:FPN是(a)中网络结构,在此基础上增加了自底向上的路径(b),使低层信息更容易传播到顶层。
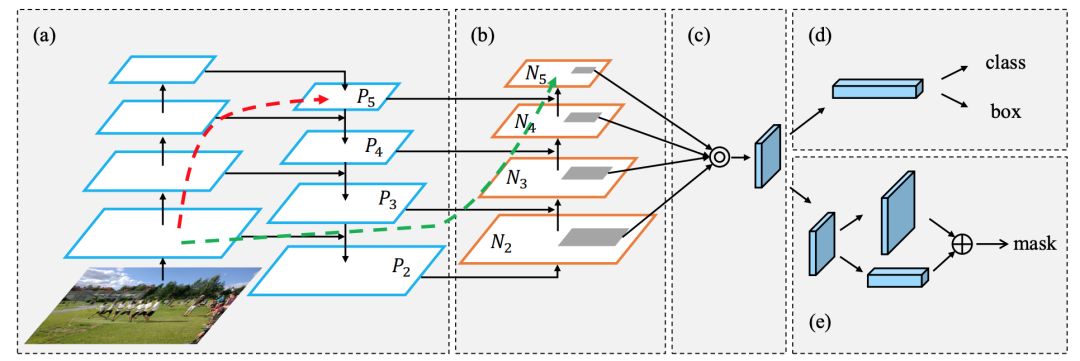
在FPN中,局部空间信息在红色箭头处向上传递。虽然图中没有清楚地显示,但红色的路径经过了大约100多个层。PAN引入了 short-cut 路径(绿色通道),只需要大约10层去顶部的N₅层。这种short-circuit 的概念使得最上层可以获得精确的局部信息。
PANet论文中融合的时候使用的方法是Addition,YOLOv4算法将融合的方法由加法改为Concatenation,即features maps是连接在一起的。如下图:
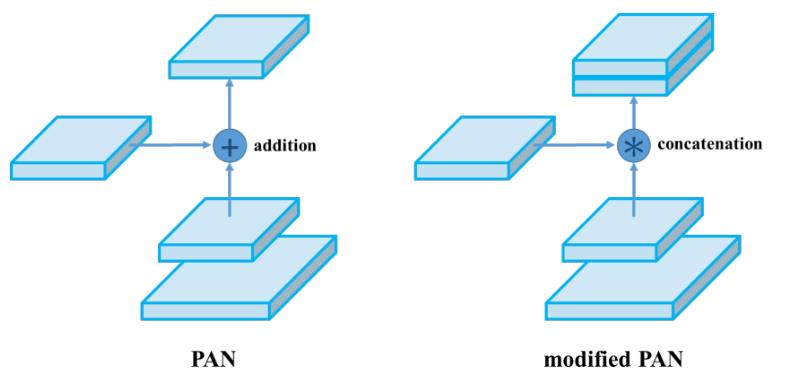
Neck连接结构小结:
5、Head输出层
Head输出层:输出层的锚框机制与YOLOv3相同,其中通过聚类提取先验框尺度,并约束预测边框的位置。主要改进的是训练时的损失函数CIOU_Loss,以及预测框筛选的DIOU_nms。
5.1 多尺度特征检测
模型输出3种尺度的张量,19*19*255、38*38*255、72*72*255,这里体现了多尺度特征检测的特点。为什么要输出3种尺度的张量呢?
低层高分辨的特征 对于检测小物体是很有帮助的,低层高分辨的特征 对应76*76;(相对于输出608*608图像,做了8倍下采样,感受野较小)
高层抽象的特征 适合检测大物体,高层抽象的特征 对应19*19;(相对于输出608*608图像,做了32倍下采样,感受野较大)
38*38 适合检测一般大小的物体,感受野中等大小。
5.2 输出维度含义
模型输出3种尺度的张量,19*19*255、38*38*255、72*72*255。为什么都是输出255维的呢?
一个网格的维度 = 先验框数量 *( 坐标x、坐标y、宽度、高度、置信度 + 类别 )
即:255= 3 * (5 + 80)
先验框数量 在每个尺度的特征图的每个网格设置3个先验框。即:每种尺度的输出张量,都有互不相同的3个先验框Anchor Boxes;13*13 用来检测大物体,使用3个尺寸较大的先验框;52*52 用来检测小物体,使用3个尺寸较小的先验框;26*26 用来检测一般大小物体,使用3个尺寸中等的先验框。这里一共有9个不同大小的先验框。
先验框维度 先验框中心坐标x、y;框的宽、高;这4个维度用来表达先验框的位置信息;还是框的置信度,是表示框内包含物体的概率。一共5维。
类别 如果用COCO数据集训练,一共有80种物体。
5.3 DIOU_nms损失函数
IOU Loss:考虑检测框和目标框重叠面积。
GIOU Loss:在IOU的基础上,解决边界框不重合时的问题。
DIOU Loss:在IOU的基础上,考虑边界框中心距离的信息。
详细原理参考:https://blog.csdn.net/qq_37099552/article/details/104464878
https://zhuanlan.zhihu.com/p/104236411
5.4 CIOU_Loss损失函数
CIOU Loss:在DIOU的基础上,考虑边界框宽高比的尺度信息。
六、模型效果
YOLOv4与其他模型对比:
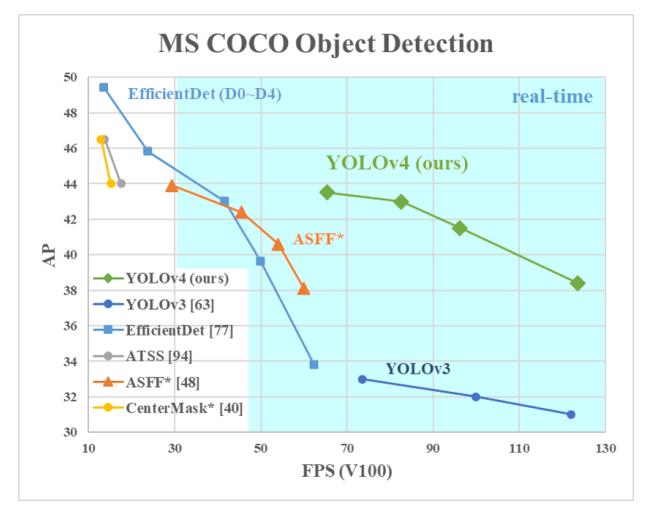
详细对比参考直接看论文:YOLOv4: Optimal Speed and Accuracy of Object Detection
七、参考文献
[1] https://cloud.tencent.com/developer/article/1748630
[2] https://zhuanlan.zhihu.com/p/161439809
[3] https://blog.csdn.net/WZZ18191171661/article/details/113765995
[4] YOLOv4: Optimal Speed and Accuracy of Object Detection
[5] Mish论文 https://arxiv.org/pdf/1908.08681.pdf
[6] DropBlock论文: https://arxiv.org/pdf/1810.12890.pdf
Pytorch-YOLOv4 开源代码:https://github.com/Tianxiaomo/pytorch-YOLOv4
Tensorflow 2-YOLOv4 开源代码:https://github.com/hunglc007/tensorflow-yolov4-tflite
本篇文章只供参考学习,谢谢。
以上是关于经典论文解读YOLOv4 目标检测的主要内容,如果未能解决你的问题,请参考以下文章