Java书籍送送送MapReduce的安装和基础编程
Posted 小生凡一
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java书籍送送送MapReduce的安装和基础编程相关的知识,希望对你有一定的参考价值。
- 🎉粉丝福利送书:《 Java多线程与大数据处理实战》
- 🎉点赞 👍 收藏 ⭐留言 📝 即可参与抽奖送书
- 🎉下周二(10月26日)晚上20:00将会在【点赞区和评论区】抽一位粉丝送这本北京大学出版社的书~🙉
- 🎉详情请看第六点的介绍嗷~✨
目录
1.词频统计任务要求
本地编辑txt文件

填入文字
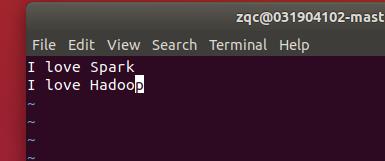
编写文档入其中
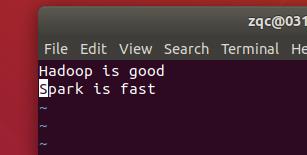
1.1 MapReduce程序编写方法
导入包
- mapreduce下所有jar
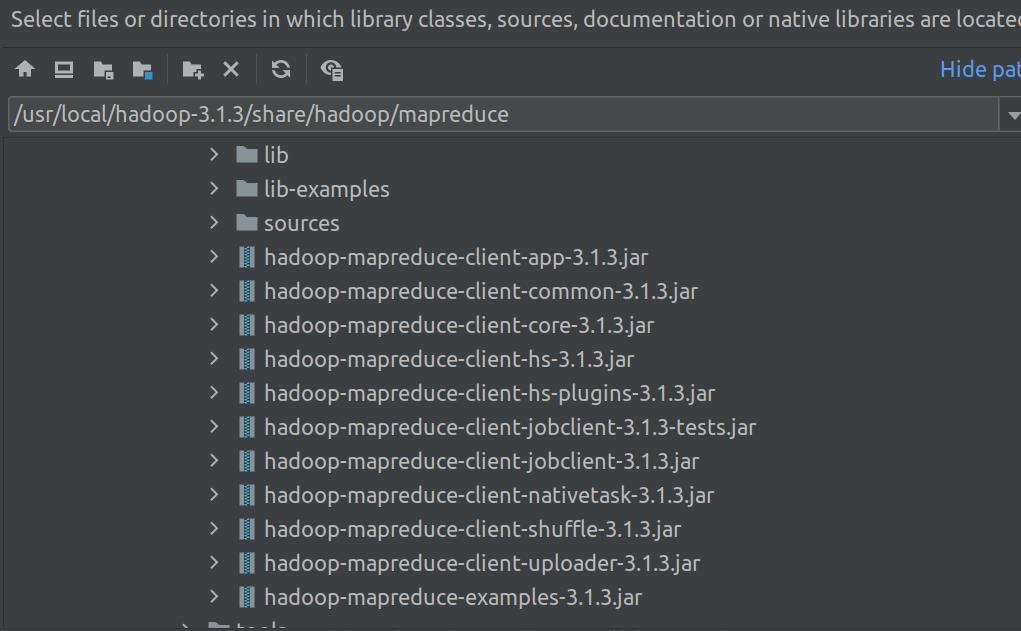
-
common下所有jar
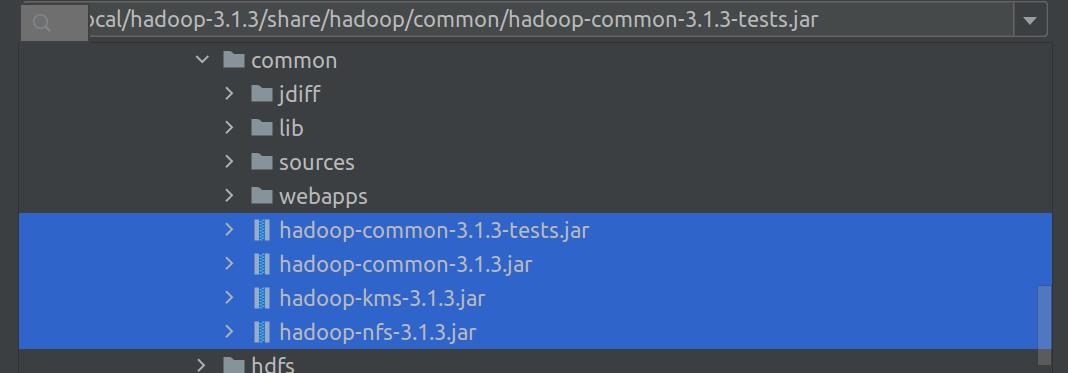
-
common/lib下所有jar
-
yarn下所有包
- hdfs下所有包
在hdfs上创建input,output文件夹。

查看是否创建

上传刚刚新建立的wordfile1.txt和wordfile2.txt到hdfs文件中!

查看是否上传成功!

1.1.1 编写Map处理逻辑
在Map阶段,文件wordfile1.txt和文件wordfile2.txt中的文本数据被读入,以<key , value>的形式提交给Map函数进行处理,其中key是当前读取到的行的地址偏移量,value是当前读取到的行的内容。<key , value>提交给Map函数以后,就可以运行自定义的Map处理逻辑,对value进行处理,然后以特定的键值对的形式进行输出,这个输出将作为中间结果,继续提供给Reduce阶段作为输入数据。
public static class TokenizerMapper extends Mapper<Object, Text, Text,
IntWritable> {
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
public TokenizerMapper() {
}
public void map(Object key, Text value, Mapper<Object, Text, Text,
IntWritable>.Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
this.word.set(itr.nextToken());
context.write(this.word, one);
}
}
}
1.1.2 编写Reduce处理逻辑
Map阶段得到的中间结果,经过Shuffle阶段(分区、排序、合并)以后,分发给对应的Reduce任务去处理。对于该阶段而言,输入是<key , value-list>形式,例如,<’Hadoop’, <1,1>>。Reduce函数就是对输入中的value-list进行求和,得到词频统计结果。
public static class IntSumReducer extends Reducer<Text, IntWritable,
Text, IntWritable> {
private IntWritable result = new IntWritable();
public IntSumReducer() {
}
public void reduce(Text key, Iterable<IntWritable> values,
Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws
IOException, InterruptedException {
int sum = 0;
IntWritable val;
for (Iterator i$ = values.iterator(); i$.hasNext(); sum += val.get()) {
val = (IntWritable) i$.next();
}
this.result.set(sum);
context.write(key, this.result);
}
}
1.1.3 编写main方法
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();// 加载hadoop配置
conf.set("fs.defaultFS", "hdfs://localhost:9000");
String[] otherArgs = new String[]{"/input/wordfile1.txt","/input/wordfile2.txt","/output/output"};
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCount.TokenizerMapper.class);
job.setCombinerClass(WordCount.IntSumReducer.class);
job.setReducerClass(WordCount.IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
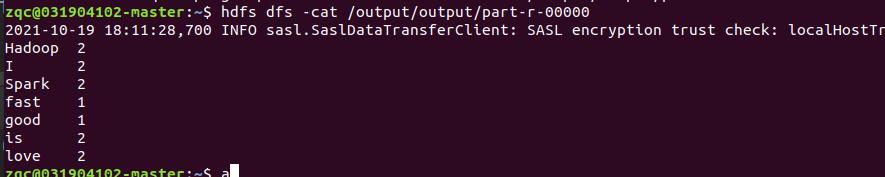
2 完整的词频统计程序
3. 编译打包程序
3.1 使用命令行编译打包词频统计程序
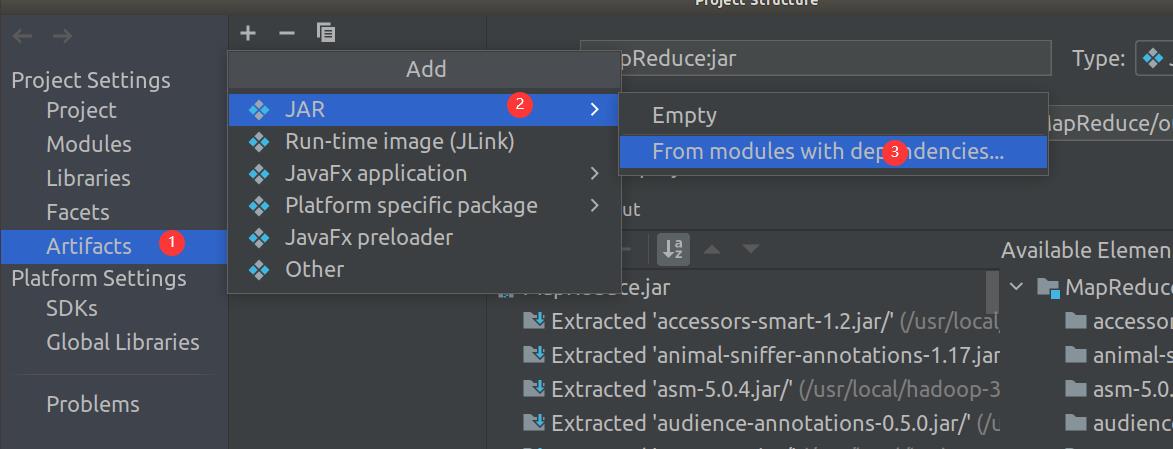
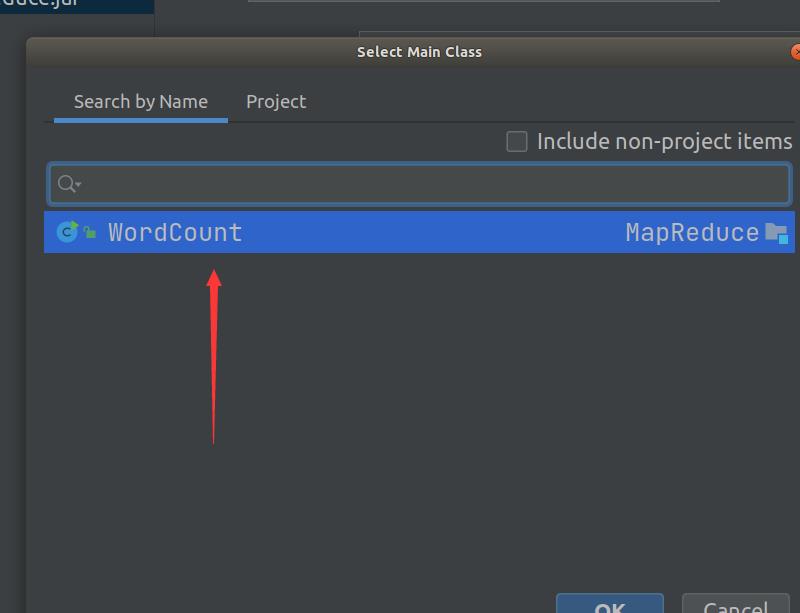
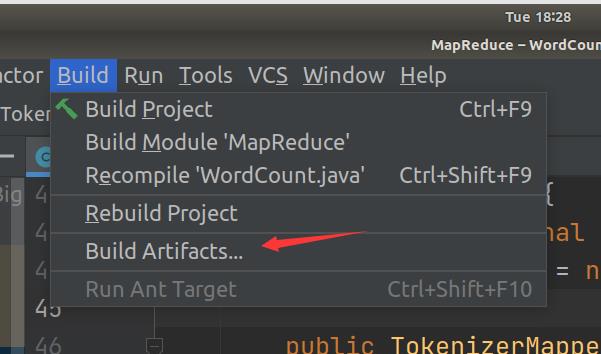
3.2 使用IDEA编译打包词频统计程序
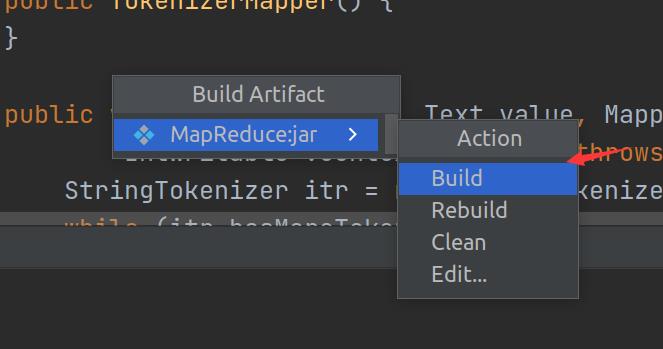
4. 运行程序
如果要再次运行WordCount.jar,需要先删除HDFS中的output目录,否则会报错。
5. 编程题
5.1 根据附件的数据文件flow_data.dat , 编程完成下面需求:
统计每个手机号的上行流量总和,下行流量总和,上行总流量之和,下行总流量之和
( Hint:以手机号码作为key值,上行流量,下行流量,上行总流量,下行总流量四个字段作为value值,然后以这个key,和value作为map阶段的输出,reduce阶段的输入。)
- 定义一个结构
public static class FlowBean implements Writable {
private long upflow;
private long downflow;
private long sumflow;
public FlowBean() {
}
public long getUpflow() {
return upflow;
}
public void setUpflow(long upflow) {
this.upflow = upflow;
}
public long getDownflow() {
return downflow;
}
public void setDownflow(long downflow) {
this.downflow = downflow;
}
public long getSumflow() {
return sumflow;
}
public void setSumflow(long sumflow) {
this.sumflow = sumflow;
}
public FlowBean(long upflow, long downflow) {
this.upflow = upflow;
this.downflow = downflow;
this.sumflow = upflow + downflow;
}
public void write(DataOutput output) throws IOException {
output.writeLong(this.upflow);
output.writeLong(this.downflow);
output.writeLong(this.sumflow);
}
public void readFields(DataInput Input) throws IOException {
this.upflow = Input.readLong();
this.downflow = Input.readLong();
this.sumflow = Input.readLong();
}
@Override
public String toString() {
return this.upflow + "\\t" + this.downflow + "\\t" + this.sumflow;
}
}
- 主函数
import java.io.IOException;
import java.util.Objects;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
public class PhoneCount {
public PhoneCount() {
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();// 加载hadoop配置
conf.set("fs.defaultFS", "hdfs://localhost:9000");
String[] otherArgs = new String[]{"/phone/input/flow_data.dat","/phone/output4"};
Job job = Job.getInstance(conf);
job.setJarByClass(PhoneCount.class);
job.setMapperClass(MapWritable.class);
job.setReducerClass(ReduceWritable.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
job.waitForCompletion(true);
}
- map操作
public static class MapWritable extends Mapper<LongWritable, Text,Text,FlowBean> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
System.out.println("line");
System.out.println(line);
String[] fields = line.split("\\t");
if (Objects.equals(fields[fields.length - 3], "上行总和")){
} else {
long upflow = Long.parseLong(fields[fields.length - 3]);
long downflow = Long.parseLong(fields[fields.length - 2]);
context.write(new Text(fields[1]), new FlowBean(upflow, downflow));
}
}
}
- reduce 操作
public static class ReduceWritable extends Reducer<Text,FlowBean,Text,FlowBean> {
@Override
protected void reduce(Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException {
//定义两个计数器,计算每个用户的上传流量、下载流量
long sumupflow = 0;
long sumdownflow = 0;
//累加的号的流量和
for (FlowBean f: values) {
sumupflow+=f.getUpflow();
sumdownflow+=f.getDownflow();
}
//输出
context.write(key,new FlowBean(sumupflow,sumdownflow));
}
}
5.2 附加题(选做)
MapReduce 实现最短路径算法,最优路径算法是路径图中满足通路上所有顶点(除起点、终点外)各异,所有边也各异的通路。
应用在公路运输中,可以提供起点和终点之间的最短路径,节省运输成本。可以大大提高交通运输效率。
给定下述路径图 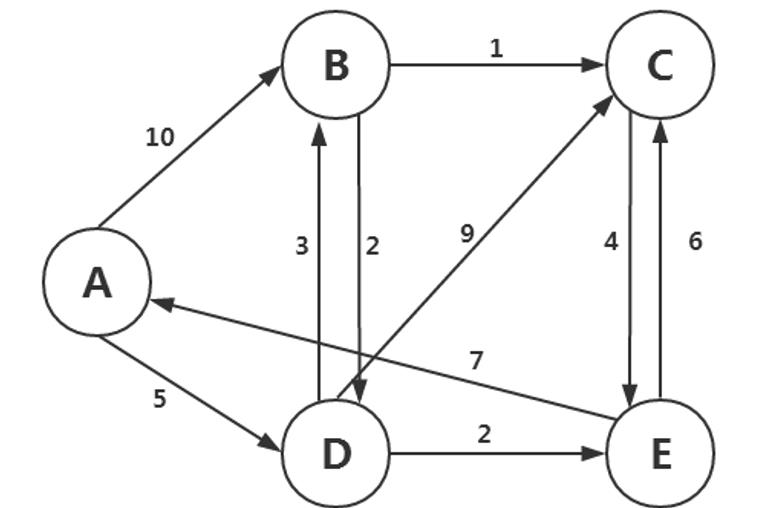
:
请编程计算出A到C之间的最短路径大小
6. 福利送书

【内容简介】
《亿级流量Java高并发与网络编程实战》 系统全面的介绍了开发人员必学的知识,如
JVM、网络编程、NIO等知识,让开发人员系统地掌握JAVA高并发与网络编程知识。
《亿级流量Java高并发与网络编程实战》分为10章,内容如下。
- 第1章,主要讲高并发相关JVM原理解析
- 第2章,主要讲 Java 网络编程
- 第3章,主要讲 Java NIO
- 第4章,主要讲并发框架Disruptor
- 第5章,主要讲微服务构建框架Spring Boot
- 第6章,主要讲微服务治理框架Spring Cloud/Dubbo
- 第7章,主要讲 Java高并发网络编程框架Netty - 实战应用
- 第8章,主要讲 Java高并发网络编程框架Netty - 深度解读
- 第9章,主要讲海量数据的高并发处理
- 第10章,主要讲基于高并发与网络编程的大型互联网项目实战。
本书主要面向面向零基础及入门级读者,Java从业人员。
【评论区】和 【点赞区】 会抽一位粉丝送出这本书籍嗷~
当然如果没有中奖的话,可以到钉钉,京东北京大学出版社的自营店进行购买。
也可以关注我!每周都会送一本出去哒~
最后
小生凡一,期待你的关注。
以上是关于Java书籍送送送MapReduce的安装和基础编程的主要内容,如果未能解决你的问题,请参考以下文章