计算机专业:老师也许会跳过的 C 语言基础知识,赶紧补上一课!
Posted 一起学编程
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了计算机专业:老师也许会跳过的 C 语言基础知识,赶紧补上一课!相关的知识,希望对你有一定的参考价值。
对于理工科的大一新生来说,C 语言是个绕不开的坎。由于在进入大学前,许多人都完全没有接触过编程相关的内容,导致对于这门课的接受能力普遍偏低,学起来也非常费劲。这里就总结一些可能在课堂上老师不会详细讲解,但是对于理解 C 语言个人感觉比较重要的一些内容,供大家参考讨论。

首先我们来讨论一些基础的内容。由于学校教学时长是有限的,每节课的时间也比较短,因此在进入具体教学前的绪论环节,并不会花费过多的笔墨。很多时候,甚至只会告诉同学如何安装 IDE、如何新建文件、保存、编译并运行,但不会告诉同学们为什么要这么做,每一步背后到底都干了些什么。要搞清楚这些问题,首先需要知道一些编程语言的基本知识,我们从分类讲起。
编程语言怎么分类?
编程语言的分类其实有很多种分类方法,首先可以将其分为高级语言与低级语言,而高级语言之中又有着非常多的种类,这些将在下面进行介绍。
高级语言与低级语言
首先按照高级低级来区分,可以分为机器语言(汇编语言)和其他。高级语言的分类较多,这边先简单聊一聊低级语言。
机器语言仅由 0 和 1 组成,是计算机硬件能够直接理解的语言。不同的架构——如我们熟知的 ARM,x86,RISC-V 等架构——都有着不同的机器语言。机器语言能够直接操作处理器,其操作码在计算机内都有着对应的电路来完成。
汇编语言是在机器语言的基础上诞生的一种语言,每一条语句都与机器语言中的操作码一一对应,能够直接翻译到机器语言。其存在的意义就是能够方便程序员理解。
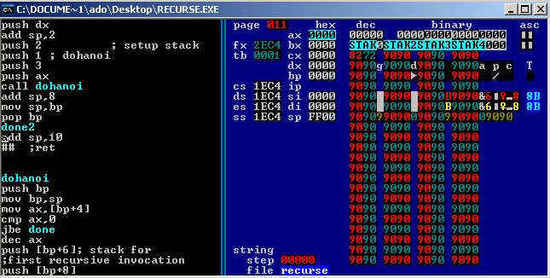
上图:汇编语言与机器语言对比
举一个简单的例子:如果想要让两个数进行加法运算,例如计算 2+3 ,那么使用机器语言可能就是 00000011 00000010 00000011 (这里为了方便加入了空格,实际的机器语言中不存在空格,只有 0 和 1 ,且该机器码为个人杜撰,仅作为例子使用,并非某一架构实际所使用的机器码),而用汇编语言写起来则是 ADD 2, 3 这样较为便于理解的方式。当然,汇编语言可不止这么简单,不过由于本文并非主要介绍汇编语言,因此就不进行深入讨论了。
尽管如此,汇编语言依然非常复杂,而且限制颇多,一旦需要写一些复杂功能,或是算法运算,很容易写完后连自己都读不懂。我在学习微机原理时,写过一个课程项目,要求是用汇编为 89C51 单片机写一段摇一摇计数的代码,剔除驱动 LCD 屏的代码,总共不过四五百行,却又写了近三百行注释以便理解。虽然其中有我对于汇编不够熟练的缘故,但其繁复程度可见一斑。
由此可见,显然不太可能用机器语言或是汇编语言来进行复杂代码的编写。这时高级语言就应运而生。下面就简单介绍一下高级语言以及其分类。
编译型、解释型与混合型
接下来介绍通过语言的翻译方式来进行的分类,以三种目前非常流行的语言为例,分别为 C 语言,Python 以及 Java。
由于所有写的代码最终都会变成机器语言才能执行,因此不同的语言最终也会殊途同归,翻译回汇编和机器语言,只是不同类型的语言翻译的方式不同而已。这边首先介绍 C 语言为代表的编译型语言。
编译型语言,顾名思义,就是通过编译将代码翻译到机器语言,再进行执行,因此执行前会首先将代码进行编译,这一步在老师教学的时候,会告诉同学们必须要先点击编译再点击执行,或点击编译并执行,其原因就在这里。编译会调用现成的编译器对代码进行分析,优化,处理,其中的过程在这里由于篇幅原因也不过多赘述了,总之最后会将所写的 .c 代码编译为以 .exe(Windows 下)或 .out (macOS 下)结尾可执行文件。
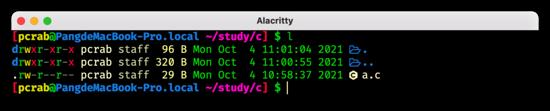
C 语言编译前
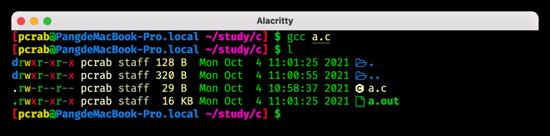
C 语言编译后
这里可以控制编译器生成汇编语言文件,可以看一下两者的差距
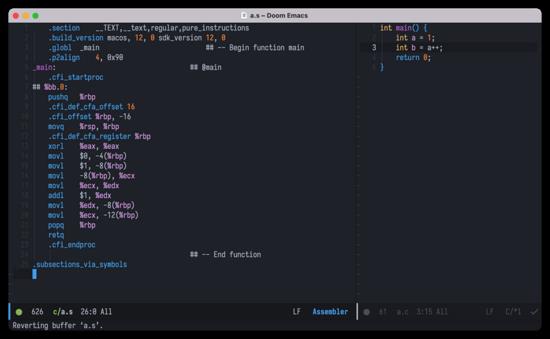
上图:C 语言与对应汇编语言
显然 C 语言的版本更容易理解。
编译型语言虽然在会在执行前进行分析优化,运行起来速度也非常快,但对于大型程序来说,编译耗时也会非常长。那么能否不进行编译而直接运行呢?答案显然是可以的,这就是解释型语言,如 Python。
对于解释型语言,将不会使用编译器进行翻译,最终生成机器语言的可执行文件,再进行执行。它会调用解释器,逐行翻译源文件,将每一行实时翻译到机器码并执行。如此一来,就不需要进行编译,执行前的准备时间大大减少。但是由于解释器并不会对代码进行优化,而且每次运行时都需要从头解释一遍,导致执行效率不如编译型语言。
编译型语言还存在另一个问题。根据前文所提到的,每种架构都有独特的机器语言,而编译的过程就是将代码翻译为机器语言的过程,这就导致每次编译生成的文件都只能在特定平台上运行。那能不能做到一次编译,就能在全平台运行呢?显然这也是可以的。这就是混合型语言,如 Java。
这类语言同样需要编译,但是编译后生成的并非机器码,而是字节码。通常这类语言在运行时会再转换成机器码执行,或直接由虚拟机解释执行。由于编译到字节码而非机器码,因而编译得到的执行文件是全平台通用的。
指定数据类型
许多同学在学习 C 语言的时候可能会疑惑,数据类型到底有什么用?要理解这个问题,我们先来看看数据是怎么存储的。
数据类型的意义
在内存中,所有数据都会被以二进制进行存储,即 01001001 等形式。这些数据仅仅只是 0 和 1 而已,所表达的意义都是人为规定的。
通常,第一位会被视为符号位,即 0 位正, 1 为负。然而,如果我希望第二位来表示符号位,也完全是符合规定的,只是所有涉及到运算的代码都要重写罢了。而数据类型就是用来规定每一位所代表的意义。
举个例子,在 32 位系统中,对于 int 类型而言,第一位表示符号,后 31 位表示具体的值。而对于 float 类型而言,尽管第一位也表示符号,但剩下的 31 位与 int 类型所表示的意义就不同了。紧接着的 8 位是指数位,剩下的是尾数,即使用科学计数法表示为 尾数 * (2 ^ 指数) 。这里是 2 的原因是计算机中所有数据都是二进制存储的,而非十进制。
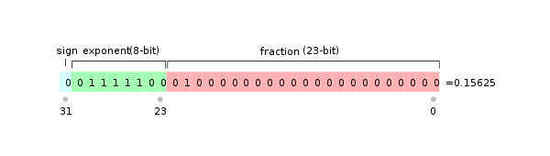
上图:float 类型存储方式
这里用 0 10000010 00010000 00000000 0000000 来展示一下 float 类型的具体计算。理解这段需要会一些简单的进制转换,如果不会建议自学一下。通过二进制计算器,可以很容易得到它对应的十进制数是 1094975488 。
对于 float 类型来说,其指数为 10000010 ,即 129 ,再根据规定减去 127 ,最终得到其指数为 2 。对于尾数而言,由于一定由 1 开头,因此最开始的这位 1 会被省略,因此其尾数实际为 10001000 00000000 00000000 ,即为 1.0001 * (2 ^ 2) ,换算成十进制为 4.25 。
如果希望对这两个类型的数据进行简单的加法运算,而不指定数据类型,汇编中会直接进行对位相加,即对应的每一个 0 或 1 相加,并加上前一位的进位。这样计算会得到 10000010 00010000 00000000 00000000 ,显然不是我们想要的 1094975492.25 。
如果不指定数据类型,计算就会得到错误的答案。由此可见,在内存中无意义的一串二进制数,我们可以通过规定每一位的意义,来得到不一样的结果。
为什么要指定这么多数据类型
很多同学可能也有这样的疑惑,为什么光一个整数就有 short , int , lang 三种,浮点数也有 float , double 两种,甚至还有与 int 类型对应的 char 类型呢?只需要 int 和 double 不就够用了么?
由于现在的计算机内存普遍充裕,不太会遇到内存空间不足的问题,因此可以直接选用高精度的数据类型进行存储与计算。然而,在多年以前,或是在嵌入式领域,这类存储空间非常紧张的条件下,不同数据类型的差距就显现出来了。
由于在这些条件下,每一个 bit 都显得弥足珍贵,因此程序员会想方设法地优化存储空间的使用,能够用低精度的就不会用高精度。
而浮点数根据上文对存储方式的解释可以看出,精度越高,其所能表示的大小越小,因此在表示较大的,对精度要求高的数据时,就必须使用高精度的数了,反之则可以用低精度的节省空间。由于 float 所能表示的精度实在是非常低,因此建议在学校编写 C 程序时,如无特殊要求,一律使用 double 类型。
而 char 类型则较为特殊,可以与整数类型进行相互转换。在单片机等环境中,由于存储空间有限,因此更倾向于使用 char 这一只消耗一字节的数据类型,而不是 int 等更大的。另外, char 一般用来表示字符,因此如果要表示例如 'A' 这种字符型的数据时,一般用 char 类型。 char 类型在后文有关字符串的部分还会提到。
然而, short 类型不一定就比 int 类型消耗的空间少, long 也不一定就比 int 表示的精度高,一切由编译器决定(只需要遵守 2 <= short <= int <= long 就是符合规定的)。因此如果真的有需要,可以用 char 来降低消耗,而不是使用 short 。
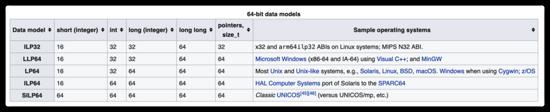
上图:数据类型在不同操作系统下的大小
由此可见,虽然常用的数据类型就这么几个,但是其他的类型也都有其存在的意义,可以不用,但不能没有。数据类型一旦确定,该变量在内存中所分配的大小,以及每一位所代表的意义,也就随之确定下来了。
数组与指针
明白数据类型,接下来就可以定义数组了。一个数组是由一定数量的,相同数据类型的变量组成的一种数据结构,也就是说,一个数组可以由一定数量的其他数组组成,而这些数组也可以由数组组成,形成套娃。
在 C 语言中,数组在定义时必须显式指定其长度与数据类型,而在一些其他语言——如 Java、 Python 中——可以不断扩展数组的长度,但 C 语言中却不能这样做。这又是为什么呢?这需要从如何在内存中生成一个数组说起。
数组的生成
我们在 C 语言中创建数组时,会指定数组的数据类型和长度,而编译器可以根据 数据类型 * sizeof(数据类型) 推算出这一数组具体需要占据多大的内存空间,进而在程序运行到这一步,需要创建数组时,为其在内存中申请符合要求的,连续的一段空间进行数组的生成。但为什么要连续的空间,而不能断断续续呢?
数组在访问时,会首先找到其内存地址。数组在创建时的变量名,实际也是一个指向数组第一项的一个指针(后面会讲到)。随后,根据具体访问哪一项,如第 n 项,就会将这一地址加上 n * sizeof(数据类型) ,就能直接找到这一项的内存地址。因此数组在生成时需要申请连续的内存地址,否则就无法做到这么高效的访问速度。
C 语言中的数组与其他语言的数组
那么问题来了:为什么别的语言能做到扩展数组长度,通过变量来初始化数组,而不是通过常数来指定呢?
事实上,在最底层的实现中,它们也是会指定一个具体的值来生成数组,其原理与 C 语言完全相同。但是在需要更长的数组时,会申请一段更长的连续内存空间来存放新数组,并将原来的旧数组完全复制一份过去。当然,各种语言会存在一定的优化,申请的空间会比所需的空间略大一些,防止重复不断的复制降低运行效率。
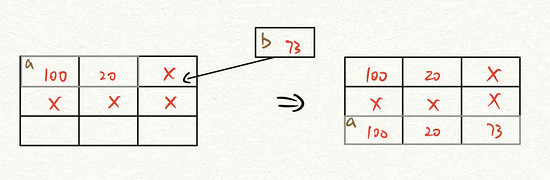
上图:数组动态扩容
由于 C 语言的数组是最原始的数组,语言本身不会自行进行申请新地址,复制旧数组等操作,因此需要在初始化时就指定好长度。
指针的作用
另外一个初学时难以理解的概念就是指针了。 先来看下指针到底是什么。指针是一个存放内存地址的变量,也就是说可以直接访问并操作内存。
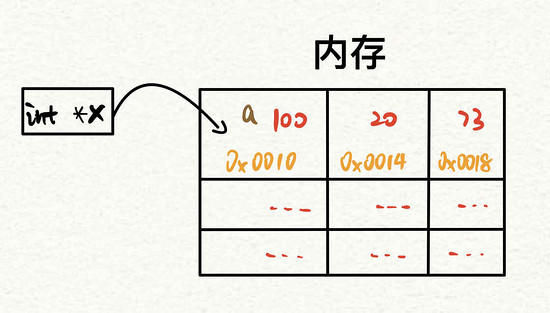
上图:指针示意图
图中 a 表示一个整数类型的变量,值为 100,在内存中存放在 0x0010 这一地址中。因此可以定义一个指针 x 指向这一地址。可以理解为 x 中存放了 0x0010 这一地址,访问这一指针就相当于访问这一地址。这就引出了一个问题:既然指针存放的是地址,访问的也是地址,那么为什么还要定义一个类型呢?
原因很简单,因为要取出该地址具体存放的值。前面说过,数据类型决定了该数据所占的大小,以及每一位具体所代表的内容。因此,要取出该地址具体存放的值,必须要知道其数据类型才行。这就是为什么 C 语言中定义指针时要指定数据类型,指明该内存地址存放数据的具体数据类型。
指针与数组的关系
指针与数组的关系也非常紧密。定义数组时取的名称就是指向数组第一个元素的指针,也就是说,要访问数组 a 中的 a[0] ,可以直接访问 *a 。以此类推,可以通过访问 *(a+1), *(a+2)来访问 a[1], a[2] 。这是因为在定义数组时已经指定了数据类型,因此这里的 +1 就不是简单的加法,而是在指针存储的地址的基础上,加上 sizeof(a[0]) (这里的 sizeof 用来获取某一变量在存放时使用的内存大小)。从上图可以看出,每个 int 类型如果占了 4 个字节,那么每次 +1 都会将内存地址 +4 再访问。
需要注意的是,通过这种方式访问数组会有数组越界的问题。也就是说,如果定义了一个长为 n 的数组,但是通过 *(a+n) 来访问第 n+1 位,C 语言并不会有任何的错误提示,只会返回一个存储在该内存地址的,根据定义的数据类型来计算得出的值。很多情况下无法分辨到底是否越界,因此使用这种方式访问需要小心谨慎。
另外,虽然数组名是一个指针,但是是一个常量,因此不能给其赋值。
字符与字符串
之前提到, char 类型多用于表示字符。字符串是由字符组成的,其底层是一串由 char 类型的变量组成的数组,因此可以通过 char* 或是 char[] 来生成字符串。赋值时,可以通过数组一个一个字符赋值,也可以通过双引号直接赋值。
在一些其他编程语言中,会专门有一个数据类型 String 来表示字符串,但在 C 语言中并没有。因此对字符串的处理就等价于对字符数组的处理。
在处理字符串时需要注意,数组长度是包含最后的 \\0 的,而 strlen 函数则不会。另外,如果通过数组的方式一个个添加字符,且在最后没有加上 \\0 ,那么则由于数组越界进而使得字符串中的数据出现错误。为了防止出现这一错误,最好直接通过双引号进行赋值。另外,不论字符数组有多长,第一次出现 \\0 就代表着字符串的结束。
由于 char 实际就是一个数字,因此在解决如 大小写转换 之类的问题时,可以通过 +- 32 来解决。这里的 32 来自于 ASCII 码表,每一个数字都对应着一个字符。 码表 可以在网上轻松找到。如果不记得具体的大小,可以通过格式化输出 %d 直接查看对应的数字,如果记不得大小写间差了 32,可以用 'a' - 'A' 来临时凑合使用一下。
一些要注意的语法格式
老师可能不会着重提语法格式,但是实际上良好的格式能够显著提升代码的可读性,方便理解与找错。
main 函数
首先,根据 C99 标准, main 函数应当定义为 int main(void) {...} 或是 int main(int argc, char *argv[]) {...} 。前一种在现在学习的阶段更为常用,其中的 void 一般是可以省略的。但是,最后的 return 0; 是可以被省略的,如果不写将会默认返回 0。有些老师或者书上可能会写成 void main() {...} ,或是说一定要显示地写出 return 0; 。这些都是错误的。具体标准可以参考 标准文档 。

main 函数定义

上图:main 函数返回值
缩进
缩进与换行的使用也是很重要的。 { 与 } 应当独占一行,其中所包裹的内容应当进行一次缩进。另外,尽管 if 语句或是 for 语句等,如果大括号内只包含一条语句,很多老师会去掉大括号,并写在一行内。这并不是一个好习惯,应当照样换行,加上大括号与缩进,方便阅读与之后的修改。
可以使用在线格式化,或是 astyle 等格式化软件来进行代码格式化。
其他一些小 tips
除了以上的这些老师可能会一笔带过的内容外,还有一些我在编程中所学到的一些小 tips:
Warning(敲代码是不可忽略的警告)
希望所有看到这篇文章的、需要学习 C 语言的同学们能够顺利学好这门课,取得一个好成绩。
对于准备成为一名优秀程序员的朋友,如果你想更好的提升你的编程核心能力(内功),让自己成为一个具有真材实料的厉害的程序员,不妨从现在开始!C/C++,永不过时的编程语言~
C语言C++编程学习交流圈子,QQ群:829164294【点击进入】微信公众号:C语言编程学习基地
整理分享(多年学习的源码、项目实战视频、项目笔记,基础入门教程)
欢迎转行和学习编程的伙伴,利用更多的资料学习成长比自己琢磨更快哦!
编程学习视频分享:
以上是关于计算机专业:老师也许会跳过的 C 语言基础知识,赶紧补上一课!的主要内容,如果未能解决你的问题,请参考以下文章