Redis支撑50ws请求原理解析
Posted 踩踩踩从踩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis支撑50ws请求原理解析相关的知识,希望对你有一定的参考价值。
前言
本篇文章会从限制性能的几个因素包括 io cpu 内存,常见的几个性能瓶颈解析;然后从redis中协议看高性能原因;以及pipeline机制是如何支撑50w每秒的 ;redis中的多线程异步处理机制;
限制Redis性能的核心因素
概述
这里影响的redis性能的核心因素,主要三个点 io cpu 内存,这个和netty中的应对百万级连接优化很像,Netty IoT百万长连接优化主要都是对我们部署的linux进行优化,很多时候我们在想也能想象的到其实限制性能并不是框架本身,要达到百万级别或者更高,其实很多时候是我们自己系统硬件的限制,一台机器本身只有内存有个16个g或者更高32个g,或者在高一点,但主要是固定的。一般的公司在考虑时,在这台机器上不单单只执行一个一个任务,有时候为了保证计算机的高可用在晚上会运行多个任务,一旦任务巨多时,会将机器性能榨干;这是一种我在公司中遇到的。这说的有点远,继续回来;
例如同时有一千万个人要去访问我们的应用,不单单是一个接口哈,多个接口同时访问量达到一千万,这恐怕就得在网关层就进行分流了(这里先不讨论这个因素),然后下来继续,说到计算机得性能,这是非常影响 得,这在netty那里就进行讨论过,这里也不讨论,然后继续下来,到达缓存这里有50ws请求过来,然后redis怎么能接受, 虽然我们redis一般和应用是部署在不同得计算机上,但是还是受不了,先不说框架。框架其实兼容性是非常好得,计算机如果够大,我们弄个千万个线程去处理,有何不可啦,怎么不能接受啦,肯定能接受。因此开始这里说一下 计算机级别上得处理
Redis的速度
redis在不同平台得测试速度,
Redis 自带了一个叫 redis-benchmark 的工具来模拟 N 个客户端同时发出 M 个请求。 (类似于 Apache ab 程序)。你可以使用 redis-benchmark -h 来查看基准参数。这里在官方文档中展示得速度
REDIS benchmarks -- Redis中文资料站 -- Redis中国用户组(CRUG)
使用 pipelining
默认情况下,每个客户端都是在一个请求完成之后才发送下一个请求 (benchmark 会模拟 50 个客户端除非使用 -c 指定特别的数量), 这意味着服务器几乎是按顺序读取每个客户端的命令。Also RTT is payed as well.
真实世界会更复杂,Redis 支持 /topics/pipelining,使得可以一次性执行多条命令成为可能。 Redis pipelining 可以提高服务器的 TPS。 下面这个案例是在 Macbook air 11” 上使用 pipelining 组织 16 条命令的测试范例:

这里通过管道经过官方得测试 带有pipelining下得到得数据

不使用 pipelining
而得到得结果

测试
这里在官方文档给我们得到得结果是非常大得 ,而我们自己也可以使用命令看一下redis得效果
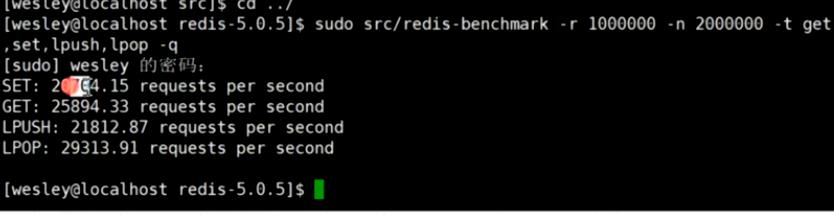
通过管道的方式

性能瓶颈
- 性能瓶颈 - 网络
- CPU型号
- 性能瓶颈 - 内存操作
- 包括 持久化时,磁盘也会影响其 性能
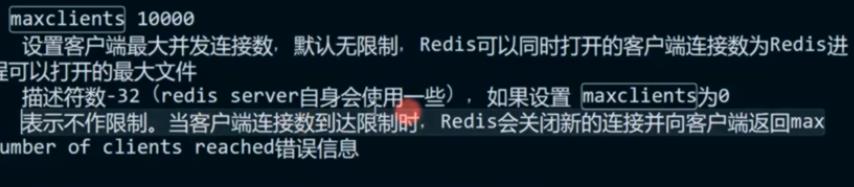
- 客户端最大连接数也会影响 这里配置就会限制
Redis协议高性能
这里和dubbo性能对比时,提出过一个好的协议影响其高性能; redis客户端通过tcp 进行 连接服务端,而这个数据包大小会影响其性能
数据包中的格式
请求数据包的格式
*<number of arguments> CR LF 参数数量
$<number of bytes of argument 1> CR LF 第一个参数长度
<argument data> CR LF 第一个参数的值
...
$<number of bytes of argument N> CR LF 第N个参数长度
<argument data> CR LF 第N个参数的值协议中的格式

协议格式实现 从代码中构建一个数据包,这里协议是非常简单的, 包括
- 第一部分 请求参数个数
command.append("*3").append("\\r\\n"); // 第一部分描述整个请求包含几个参数
- 第一个参数的长度 --- 命令的名称
command.append("$3").append("\\r\\n");// 第一个参数的长度 --- 命令的名称
- 第一个参数的值
command.append("SET").append("\\r\\n");// 第一个参数的值
- 第2个参数的长度
大概这样的协议最后构造出来就是一个完整的部分
Socket connection;
public RedisClient(String host, int port) throws IOException {
connection = new Socket(host, port);
// 数据发送,读取 基于连接
}
// set key value
public String set(String key, String value) throws IOException {
// 构建数据包
StringBuilder command = new StringBuilder();
command.append("*3").append("\\r\\n"); // 第一部分描述整个请求包含几个参数
command.append("$3").append("\\r\\n");// 第一个参数的长度 --- 命令的名称
command.append("SET").append("\\r\\n");// 第一个参数的值
command.append("$").append(key.getBytes().length).append("\\r\\n");// 第2个参数的长度
command.append(key).append("\\r\\n");// 第2个参数的值
command.append("$").append(value.getBytes().length).append("\\r\\n");// 第3个参数的长度
command.append(value).append("\\r\\n");// 第2个参数的值
// 发送命令请求,发给redis服务器
connection.getOutputStream().write(command.toString().getBytes());
// 读取redis服务器的响应
byte[] response = new byte[1024];
connection.getInputStream().read(response);
return new String(response);
}
// get key
public String get(String key) throws IOException {
// 构建数据包
StringBuilder command = new StringBuilder();
command.append("*2").append("\\r\\n"); // 第一部分描述整个请求包含几个参数
command.append("$3").append("\\r\\n");// 第一个参数的长度 --- 命令的名称
command.append("GET").append("\\r\\n");// 第一个参数的值
command.append("$").append(key.getBytes().length).append("\\r\\n");// 第2个参数的长度
command.append(key).append("\\r\\n");// 第2个参数的值
System.out.println(command.toString());
// 发送命令请求,发给redis服务器
connection.getOutputStream().write(command.toString().getBytes());
// 读取redis服务器的响应
byte[] response = new byte[1024];
connection.getInputStream().read(response);
return new String(response);
}REDIS protocol -- Redis中国用户组(CRUG)
官方的协议文档
Redis用不同的回复类型回复命令。它可能从服务器发送的第一个字节开始校验回复类型:
用单行回复,回复的第一个字节将是“+”
错误消息,回复的第一个字节将是“-”
整型数字,回复的第一个字节将是“:”
批量回复,回复的第一个字节将是“$”
多个批量回复,回复的第一个字节将是“*”
这个对比http协议,明显就是效率高很多
Pipeline机制支撑50w每秒
Redis大量数据插入(redis mass-insert) -- Redis中国用户组(CRUG)
些时候,Redis实例需要装载大量用户在短时间内产生的数据,数以百万计的keys需要被快速的创建。
我们称之为大量数据插入(mass insertion),本文档的目标就是提供如下信息:Redis如何尽可能快的处理数据。
使用Luke协议
使用正常模式的Redis 客户端执行大量数据插入不是一个好主意:因为一个个的插入会有大量的时间浪费在每一个命令往返时间上。使用管道(pipelining)是一种可行的办法,但是在大量插入数据的同时又需要执行其他新命令时,这时读取数据的同时需要确保请可能快的的写入数据。
只有一小部分的客户端支持非阻塞输入/输出(non-blocking I/O),并且并不是所有客户端能以最大限度的提高吞吐量的高效的方式来分析答复。

这也是官方文档中给我们提供的
生成Redis协议
它会非常简单的生成和解析Redis协议,Redis协议文档请参考Redis协议说明。 但是为了生成大量数据插入的目标,你需要了解每一个细节协议,每个命令会用如下方式表示:
*<args><cr><lf>
$<len><cr><lf>
<arg0><cr><lf>
<arg1><cr><lf>
...
<argN><cr><lf>在文件内容中出现的。 这里都提供了方式可以使用
管道协议

多个命令发送到服务器而无需等待回复,即使客户端尚未读取旧响应,服务端也能够处理新请求。
这样虽然不保证数据是否真实存储成功,但是对于缓存,并不太影响什么。
普通的互联网网络请求通信方式
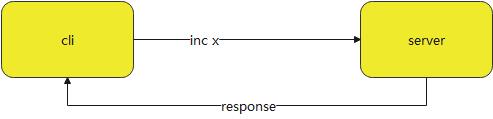
redis服务基于TCP请求 响应通信 客户端发起请求以后阻塞的方式等待服务端的相应,客户端与服务端间的请求与响应。有网络时间RTT时间。
假如RTT时间为260ms ,但是1万个请求总的RTT时间是很大的
大部分时间浪费到路上
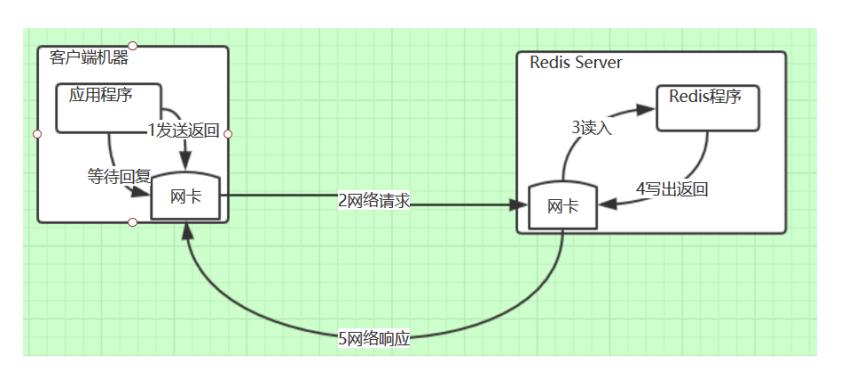 这个时间是一定存在的
这个时间是一定存在的
Redis中 管道协议
RTT是很消耗时间的,因此 redis中 pilpelline 就是合并多次请求节省往返的网络时间

开启管道方式的话,不能马上得到结果
在代码中实现
public class RedisPipeline {
@Autowired
private StringRedisTemplate stringRedisTemplate;
/**
* 使用pipeline的方式
* @param batchSize
*/
public void pipeline(int batchSize) {
List<Object> results = stringRedisTemplate.executePipelined(
new RedisCallback<Object>() {
public Object doInRedis(RedisConnection connection) throws DataAccessException {
StringRedisConnection stringRedisConn = (StringRedisConnection)connection;
for(int i=0; i< batchSize; i++) {
// set key1 value2
// set key2 value2
stringRedisConn.set("pipeline"+i, "xxx"+i);
}
return null;
}
});
System.out.println("pipeline over. results: "+results);
}
/**
* 使用简单的set命令
* @param batchSize
*/
public void setCommand(int batchSize) {
for(int i=0; i< batchSize; i++) {
stringRedisTemplate.opsForValue().set("pipeline"+i, "xxx"+i);
}
System.out.println("set command over");
}
}利用 异步的方式得到 获取异步结果的时间 利用 List<Object> results 这里会阻塞等待结果的返回数据,最后其实发现时间消耗就消耗在这里 。
代码实现
通过jedis很简单的就获取到数据
public class JedisPipeline {
public void pipeline(int batchSize) {
Jedis jedis = new Jedis("192.168.100.12", 6379);
Pipeline p = jedis.pipelined();
List<Response<?>> list = new ArrayList<Response<?>>();
long s = System.currentTimeMillis();
for (int i = 0; i < batchSize; i++) {
Response<?> r = p.get("pipeline" + i);
list.add(r);
}
p.sync();
list.forEach((e) -> {
System.out.println(e.get());
});
try {
p.close();
} catch (IOException e1) {
e1.printStackTrace();
}
jedis.close();
}
}Redis中的多线程异步处理机制
处理客户端请求数据 Redis是采用单线程去处理的,这个不是多线程处理的
Redis中的其他线程
- 持久化机制 AOF (RDB的方式属于fork子进程,非线程)
- 主从之间数据异步同步 - PSYNC
- 关闭时将内存数据刷盘到文件
- lazyfree机制(4.0+特性):
以上是关于Redis支撑50ws请求原理解析的主要内容,如果未能解决你的问题,请参考以下文章