数据集成工具的使用---Flume 从理论学习到熟练使用
Posted 北慕辰
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据集成工具的使用---Flume 从理论学习到熟练使用相关的知识,希望对你有一定的参考价值。
本期与大家分享的是,小北精心整理的大数据学习笔记,数据采集工具Flume 的详细介绍,希望对大家能有帮助,喜欢就给点鼓励吧,记得三连哦!欢迎各位大佬评论区指教讨论!
💜🧡💛制作不易,各位大佬们给点鼓励!
🧡💛💚点赞👍 ➕ 收藏⭐ ➕ 关注✅
💛💚💙欢迎各位大佬指教,一键三连走起!往期好文推荐:
🔶🔷数据集成工具的使用(一)—Sqoop 从理论学习到熟练使用
🔶🔷数据集成工具的使用(二)—DataX 从理论学习到熟练使用
🔶🔷数据集成工具的使用(三)—FlinkX 从理论学习到熟练使用
🔶🔷数据集成工具的使用(五)—Kettle 从理论学习到熟练使用
一、Flume简介
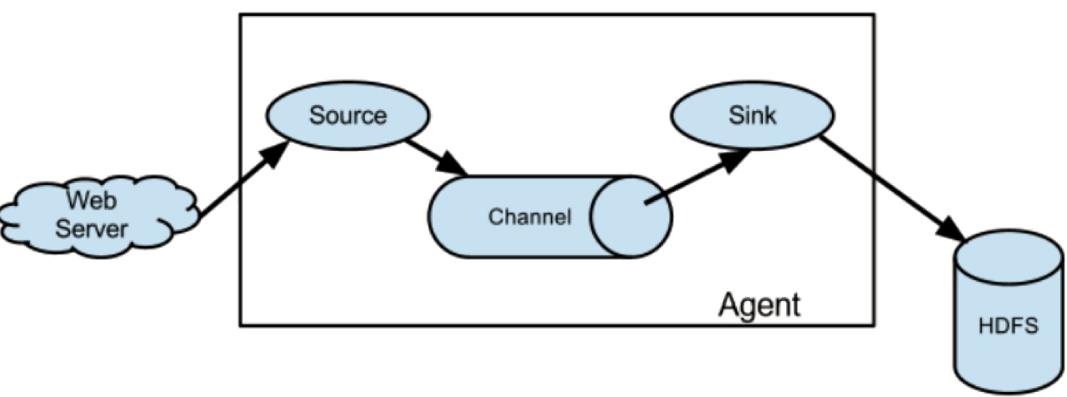
flume是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(比如文本、HDFS、Hbase等)的能力 。flume的数据流由事件(Event)贯穿始终。事件是Flume的基本数据单位,它携带日志数据(字节数组形式)并且携带有头信息,这些Event由Agent外部的Source生成,当Source捕获事件后会进行特定的格式化,然后Source会把事件推入(单个或多个)Channel中。你可以把Channel看作是一个缓冲区,它将保存事件直到Sink处理完该事件。Sink负责持久化日志或者把事件推向另一个Source。
二、Flume架构
Flume 运行的核心是 Agent。Flume以agent为最小的独立运行单位。一个agent就是一个JVM。它是一个完整的数据收集工具,含有三个核心组件,分别是
source、 channel、 sink。通过这些组件, Event 可以从一个地方流向另一个地方,如下图所示。
三、Flume组件
Client:Client生产数据,运行在一个独立的线程。
Event: 一个数据单元,消息头和消息体组成。(Events可以是日志记录、 avro 对象等。)
Flow: Event从源点到达目的点的迁移的抽象。
Agent: 一个独立的Flume进程,包含组件Source、 Channel、 Sink。(Agent使用JVM 运行Flume。每台机器运行一个agent,但是可以在一个agent中包含多个sources和sinks。)
Source: 数据收集组件。(source从Client收集数据,传递给Channel)
Channel: 中转Event的一个临时存储,保存由Source组件传递过来的Event。(Channel连接 sources 和 sinks ,这个有点像一个队列。)
Sink: 从Channel中读取并移除Event, 将Event传递到FlowPipeline中的下一个Agent(如果有的话)(Sink从Channel收集数据,运行在一个独立线程。)
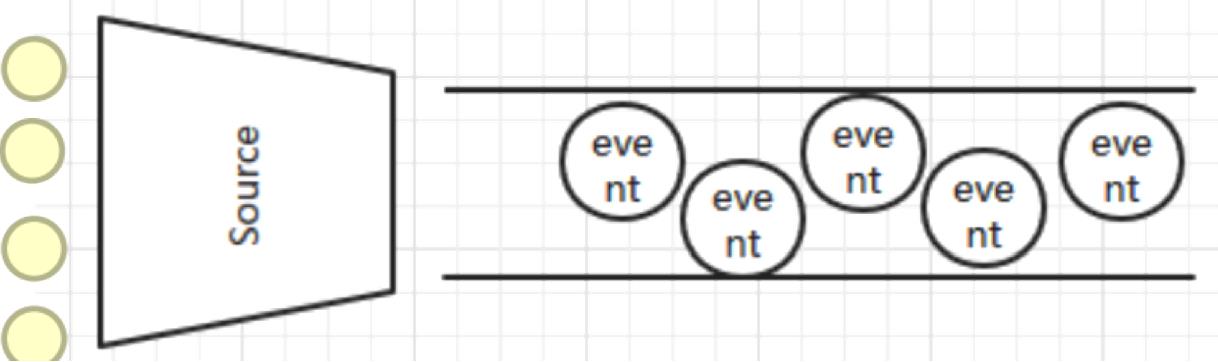
Source
- Source是数据的收集端,负责将数据捕获后进行特殊的格式化,将数据封装到事件(event) 里,然后将事件推入Channel中。 Flume提供了很多内置的Source, 支持 Avro, log4j, syslog 和 http post(body为json格式)。可以让应用程序同已有的Source直接打交道,如AvroSource
- 如果内置的Source无法满足需要, Flume还支持自定义Source。
Channel
- Channel是连接Source和Sink的组件,大家可以将它看做一个数据的缓冲区(数据队列),它可以将事件暂存到内存中也可以持久化到本地磁盘上, 直到Sink处理完该事件。介绍两个较为常用的Channel, MemoryChannel和FileChannel。

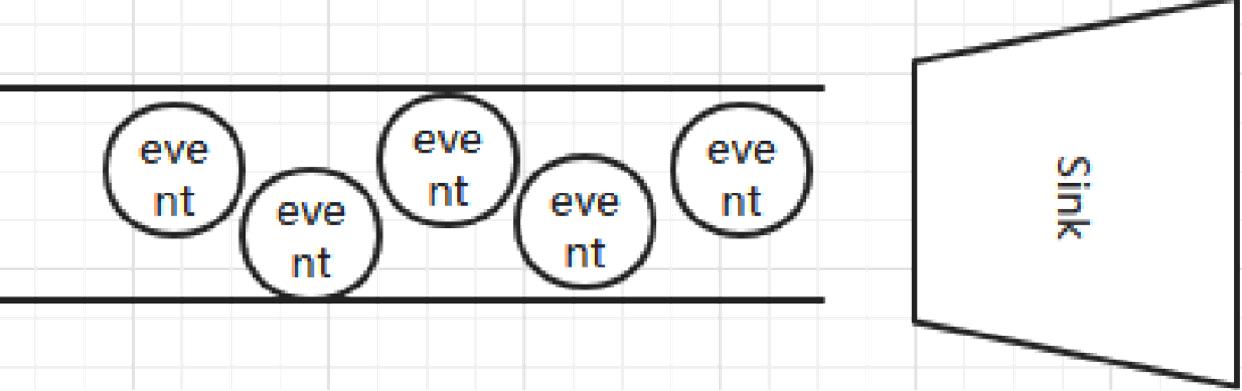
Sink
- Sink从Channel中取出事件,然后将数据发到别处,可以向文件系统、数据库、 hadoop存数据, 也可以是其他agent的Source。在日志数据较少时,可以将数据存储在文件系统中,并且设定一定的时间间隔保存数据。
四、Flume数据流
-
Flume 的核心是把数据从数据源收集过来,再送到目的地。为了保证输送一定成功,在送到目的地之前,会先缓存数据,待数据真正到达目的地后,删除自己缓存的数据
-
Flume 传输的数据的基本单位是 Event,如果是文本文件,通常是一行记录,这也是事务的基本单位。 Event 从 Source,流向 Channel,再到 Sink,本身为一个 byte 数组,并可携带 headers 信息。 Event 代表着一个数据流的最小完整单元,从外部数据源来,向外部的目的地去。
-
值得注意的是,Flume提供了大量内置的Source、Channel和Sink类型。不同类型的Source,Channel和Sink可以自由组合。组合方式基于用户设置的配置文件,非常灵活。(比如:Channel可以把事件暂存在内存里,也可以持久化到本地硬盘上。Sink可以把日志写入HDFS, HBase,甚至是另外一个Source等等。Flume支持用户建立多级流,也就是说,多个agent可以协同工作)
五、Flume可靠性
- Flume 使用事务性的方式保证传送Event整个过程的可靠性。 Sink 必须在Event 已经被传达到下一站agent里,又或者,已经被存入外部数据目的地之后,才能把 Event 从 Channel 中 remove 掉。这样数据流里的 event 无论是在一个 agent 里还是多个 agent 之间流转,都能保证可靠,因为以上的事务保证了 event 会被成功存储起来。比如 Flume支持在本地保存一份channel文件作为备份,而memory channel 将event存在内存 queue 里,速度快,但丢失的话无法恢复。
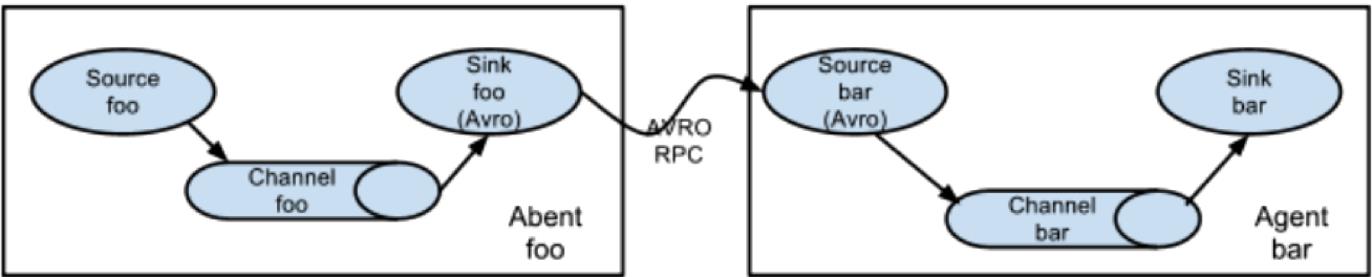
六、多个agent顺序连接
-
可以将多个Agent顺序连接起来,将最初的数据源经过收集,存储到最终的存储系统中。这是最简单的情况,一般情况下,应该控制这种顺序连接的
-
Agent 的数量,因为数据流经的路径变长了,如果不考虑failover的话,出现故障将影响整个Flow上的Agent收集服务。
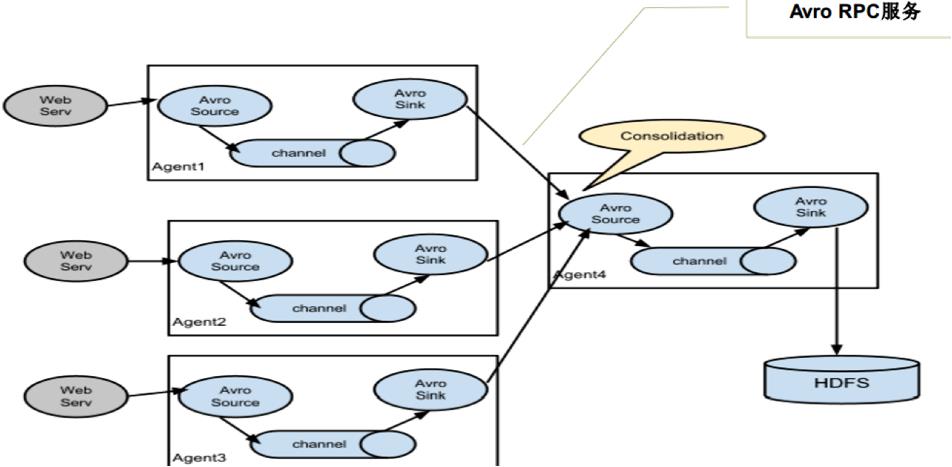
多个Agent的数据汇聚到同一个Agent
- 这种情况应用的场景比较多,比如要收集Web网站的用户行为日志, Web网站为了可用性使用的负载集群模式,每个节点都产生用户行为日志,可以为每个节点都配置一个Agent来单独收集日志数据,然后多个Agent将数据最终汇聚到一个用来存储数据存储系统,如HDFS上。
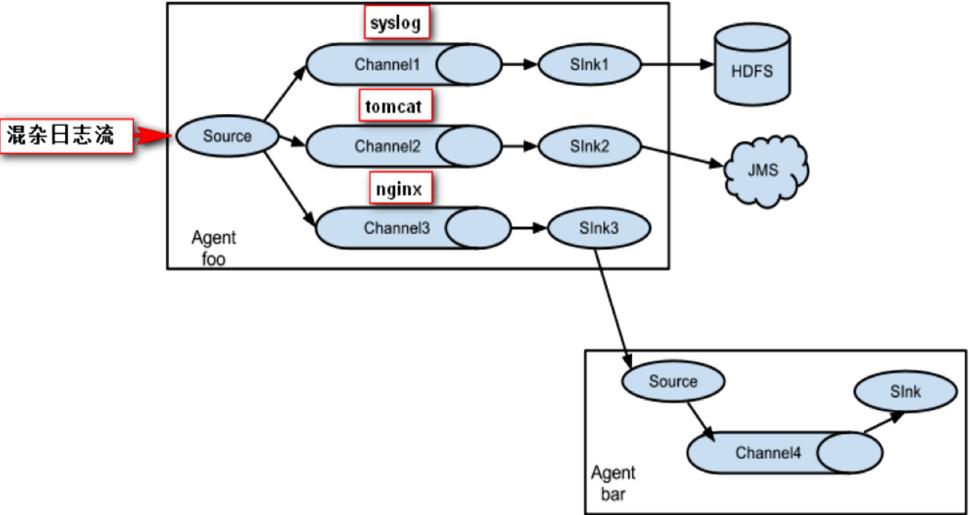
七、Flume多级流
- Flume还支持多级流,什么多级流?结合在云开发中的应用来举个例子,当syslog, java, nginx、 tomcat等混合在一起的日志流开始流入一个agent后,可以agent中将混杂的日志流分开,然后给每种日志建立一个自己的传输通道。
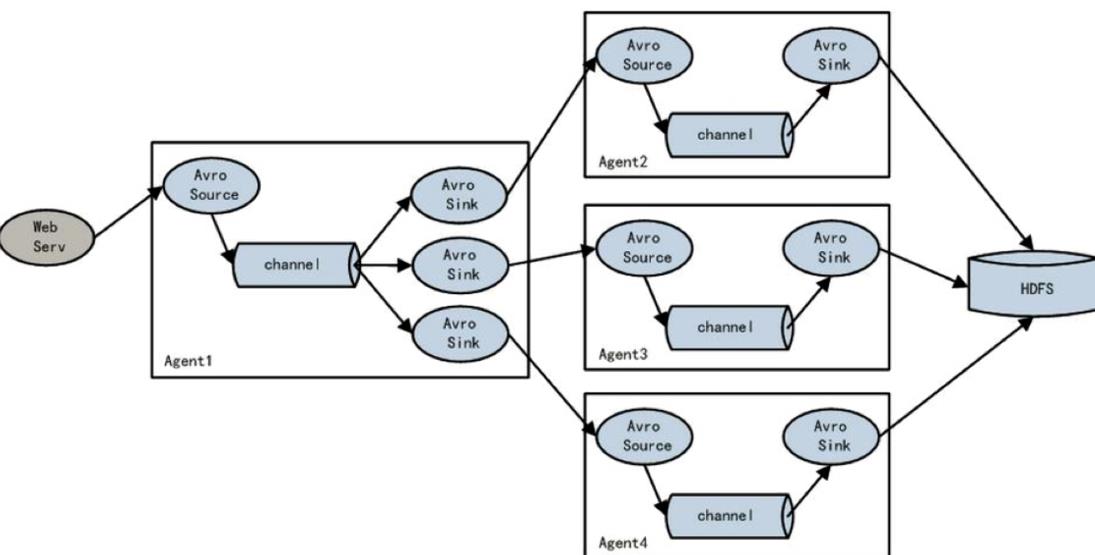
八、负载均衡功能
下图Agent1是一个路由节点,负责将Channel暂存的Event均衡到对应的多个Sink组件上,而每个Sink组件分别连接到一个独立的Agent上
九、Flume的安装
1、上传至虚拟机,并解压
tar -zxvf apache-flume-1.9.0-bin.tar.gz -C /usr/local/soft/
在环境变量中增加如下命令,可以使用 soft 快速切换到 /usr/local/soft
alias soft=‘cd /usr/local/soft/’
2、重命名目录,并配置环境变量
#修改目录名为flume-1.9.0
mv apache-flume-1.9.0-bin/ flume-1.9.0
#配置环境变量
vim /etc/profile
#修改,添加
export FLUME_HOME=/usr/local/soft/flume-1.9.0
export PATH=$PATH:$FLUME_HOME/bin
#source 刷新配置文件
source /etc/profile
3、查看flume版本
flume-ng version

4、测试flume
监控一个目录,将数据打印出来
配置文件
# a1表示agent的名字 可以自定义
# 给sources(在一个agent里可以定义多个source)取个名字
a1.sources = r1
# 给channel个名字
a1.channels = c1
# 给channel个名字
a1.sinks = k1
# 对source进行配置
# agent的名字.sources.source的名字.参数 = 参数值
# source的类型 spoolDir(监控一个目录下的文件的变化)
a1.sources.r1.type = spooldir
# 监听哪一个目录
a1.sources.r1.spoolDir = /root/data
# 是否在event的headers中保存文件的绝对路径
a1.sources.r1.fileHeader = true
# 给拦截器取个名字 i1
a1.sources.r1.interceptors = i1
# 使用timestamp拦截器,将处理数据的时间保存到event的headers中
a1.sources.r1.interceptors.i1.type = timestamp
# 配置channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 配置sink为logger
# 直接打印到控制台
a1.sinks.k1.type = logger
# 将source、channel、sink组装成agent
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动agent
flume-ng agent -n a1 -f ./spoolingtest.conf -Dflume.root.logger=DEBUG,console
新建/root/data目录
mkdir /root/data
在/root/data/目录下新建文件,输入内容,观察flume进程打印的日志
# 随意在a.txt中加入一些内容
vim /root/data/a.txt
十、Flume的简单使用
1、 spoolingToHDFS.conf
配置文件
# a表示给agent命名为a
# 给source组件命名为r1
a.sources = r1
# 给sink组件命名为k1
a.sinks = k1
# 给channel组件命名为c1
a.channels = c1
#指定spooldir的属性
a.sources.r1.type = spooldir
a.sources.r1.spoolDir = /root/data
a.sources.r1.fileHeader = true
a.sources.r1.interceptors = i1
a.sources.r1.interceptors.i1.type = timestamp
#指定sink的类型
a.sinks.k1.type = hdfs
a.sinks.k1.hdfs.path = /flume/data/dir1
# 指定文件名前缀
a.sinks.k1.hdfs.filePrefix = student
# 指定达到多少数据量写一次文件 单位:bytes
a.sinks.k1.hdfs.rollSize = 102400
# 指定多少条写一次文件
a.sinks.k1.hdfs.rollCount = 1000
# 指定文件类型为 流 来什么输出什么
a.sinks.k1.hdfs.fileType = DataStream
# 指定文件输出格式 为text
a.sinks.k1.hdfs.writeFormat = text
# 指定文件名后缀
a.sinks.k1.hdfs.fileSuffix = .txt
#指定channel
a.channels.c1.type = memory
a.channels.c1.capacity = 1000
# 表示sink每次会从channel里取多少数据
a.channels.c1.transactionCapacity = 100
# 组装
a.sources.r1.channels = c1
a.sinks.k1.channel = c1
在 /root/data/目录下准备数据
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!
启动agent
flume-ng agent -n a -f ./spoolingToHDFS.conf -Dflume.root.logger=DEBUG,console
2、 hbaseLogToHDFS
配置文件
# a表示给agent命名为a
# 给source组件命名为r1
a.sources = r1
# 给sink组件命名为k1
a.sinks = k1
# 给channel组件命名为c1
a.channels = c1
#指定exec的属性
a.sources.r1.type = exec
a.sources.r1.command = tail -f /usr/local/soft/hbase-1.4.6/logs/hbase-root-master-master.log
#指定sink的类型
a.sinks.k1.type = hdfs
a.sinks.k1.hdfs.path = /flume/data/dir2
# 指定文件名前缀
a.sinks.k1.hdfs.filePrefix = hbaselog
# 指定达到多少数据量写一次文件 单位:bytes
a.sinks.k1.hdfs.rollSize = 102400
# 指定多少条写一次文件
a.sinks.k1.hdfs.rollCount = 1000
# 指定文件类型为 流 来什么输出什么
a.sinks.k1.hdfs.fileType = DataStream
# 指定文件输出格式 为text
a.sinks.k1.hdfs.writeFormat = text
# 指定文件名后缀
a.sinks.k1.hdfs.fileSuffix = .txt
#指定channel
a.channels.c1.type = memory
a.channels.c1.capacity = 1000
# 表示sink每次会从channel里取多少数据
a.channels.c1.transactionCapacity = 100
# 组装
a.sources.r1.channels = c1
a.sinks.k1.channel = c1
3、hbaselogToHBase
在hbase中创建log表
create 'log','cf1'
配置文件
# a表示给agent命名为a
# 给source组件命名为r1
a.sources = r1
# 给sink组件命名为k1
a.sinks = k1
# 给channel组件命名为c1
a.channels = c1
#指定exec的属性
a.sources.r1.type = exec
a.sources.r1.command = cat /usr/local/soft/hbase-1.4.6/logs/hbase-root-master-master.log
#指定sink的类型
a.sinks.k1.type = hbase
a.sinks.k1.table = log
a.sinks.k1.columnFamily = cf1
#指定channel
a.channels.c1.type = memory
a.channels.c1.capacity = 100000
# 表示sink每次会从channel里取多少数据
a.channels.c1.transactionCapacity = 100
# 组装
a.sources.r1.channels = c1
a.sinks.k1.channel = c1
netcatLogger
监听telnet端口
安装telnet
yum install telnet
配置文件
# a表示给agent命名为a
# 给source组件命名为r1
a.sources = r1
# 给sink组件命名为k1
a.sinks = k1
# 给channel组件命名为c1
a.channels = c1
#指定netcat的属性
a.sources.r1.type = netcat
a.sources.r1.bind = 0.0.0.0
a.sources.r1.port = 8888
#指定sink的类型
a.sinks.k1.type = logger
#指定channel
a.channels.c1.type = memory
a.channels.c1.capacity = 1000
# 表示sink每次会从channel里取多少数据
a.channels.c1.transactionCapacity = 100
# 组装
a.sources.r1.channels = c1
a.sinks.k1.channel = c1
启动
先启动agent
flume-ng agent -n a -f ./netcatToLogger.conf -Dflume.root.logger=DEBUG,console
再启动telnet
telnet master 8888
4、 httpToLogger
配置文件
# a表示给agent命名为a
# 给source组件命名为r1
a.sources = r1
# 给sink组件命名为k1
a.sinks = k1
# 给channel组件命名为c1
a.channels = c1
#指定http的属性
a.sources.r1.type = http
a.sources.r1.port = 6666
#指定sink的类型
a.sinks.k1.type = logger
#指定channel
a.channels.c1.type = memory
a.channels.c1.capacity = 1000
# 表示sink每次会从channel里取多少数据
a.channels.c1.transactionCapacity = 100
# 组装
a.sources.r1.channels = c1
a.sinks.k1.channel = c1
启动
先启动agent
flume-ng agent -n a -f ./httpToLogger.conf -Dflume.root.logger=DEBUG,console
再使用curl发起一个http请求
curl -X POST -d '[{ "headers" :{"a" : "a1","b" : "b1"},"body" : "hello~http~flume~"}]' http://master:666
以上是关于数据集成工具的使用---Flume 从理论学习到熟练使用的主要内容,如果未能解决你的问题,请参考以下文章