小白如何做一个Python人工智能语音助手
Posted 林-双喜
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了小白如何做一个Python人工智能语音助手相关的知识,希望对你有一定的参考价值。
小白如何做一个Python智能语音助手
真的是小白?
大家好,我是一名信息工程的大三学生,由于大一大二没怎么学习技术,所以大三准备挖粪图强。先介绍一下我的学习储备吧,断断续续学过Python,一直只是看B站,学习一些语法基础,数值类型,循环,函数…甚至连面向对象和面向过程都分不清。
不过,这样的学习基础过程太枯燥了,我太没有耐心,三天打鱼两天晒网地,所以我决定,从项目直接开始入手,遇到问题再去恶补基础知识。虽然这样的效率可能有点低,甚至你可能都不知道遇到问题该学习什么知识。
但是自顶向下的项目驱动对我来说更加有动力去学习,如果这个项目我不去做完它,我可能都会睡不着觉,所以我觉得这是最适合我的学习方法,而且现在网络这么发达,真的想要解决一个问题还能办不到吗?
这是我花了大概2天实现的第一个项目
(基本上除了吃饭睡觉都在做,还肝到了3点多)
废话不说直接上图
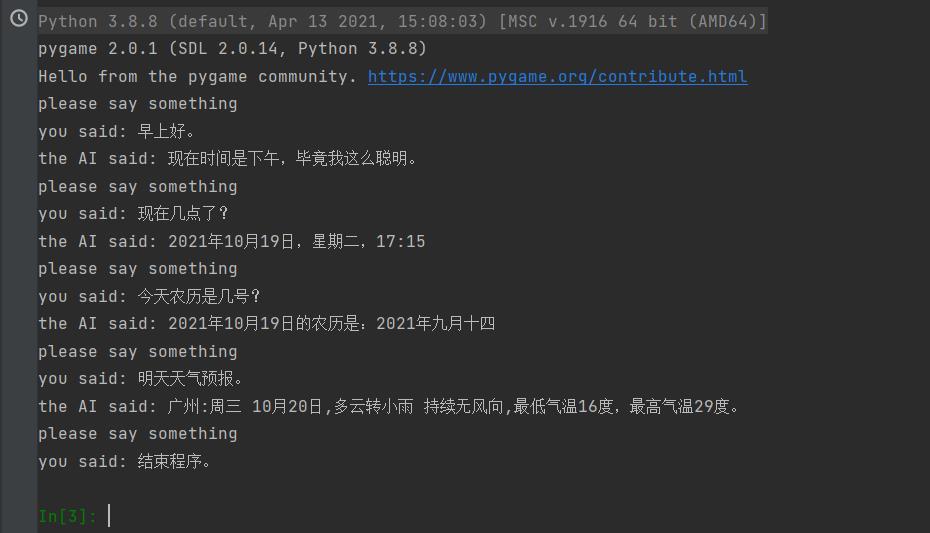
人工智能语音助手主要功能分成下面5个部分:
1、录音
2、语音识别
(将录音内容进行语音识别转成文字)
3、接入图灵机器人
(将文字发送给机器人获得回复)
4、语音合成
(将回复的文字进行语音合成)
5、播放语音
应该很好理解吧,它的核心功能其实是需要一个聊天机器人,才能实现智能回复,这里我们用的是现有的图灵机器人,调用他的接口,不是自己做一个机器人(臣妾做不到)。
同样地,语音识别和语音合成技术也是调用现有的百度语音的接口,至于怎么实现那就太复杂了。
前期准备
· 首先肯定是python的安装和编译器
这个我就不讲了,网上教程特别多
我用的是Pycharm 2021.2.2(最新版本的,也是最近重新开始学习,卸了重装的)
· 其次你要学会第三方模块的安装,这个特别重要
Python很多项目都可以直接通过第三方模块,实现大部分功能
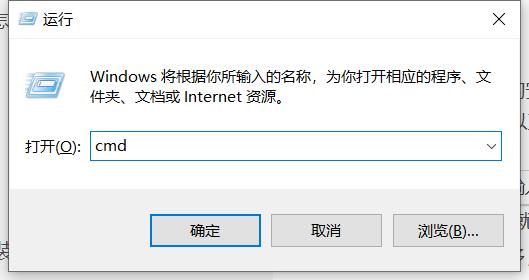
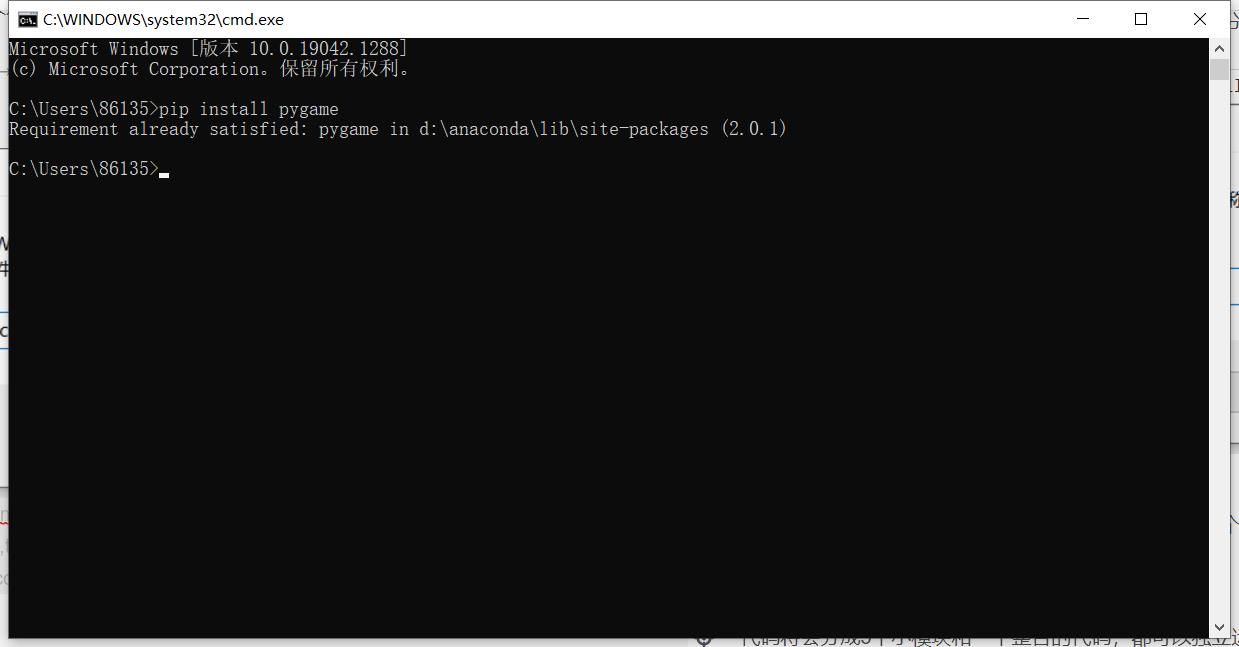
安装方法:
快捷键 Windows+R →输入‘cmd’确定→然后输入:pip install 你要安装的第三模块的名字→Enter(回车)
比如安装: pygame ,就敲入pip install pygame
我已经安装过了,要是还没安装会有下载进度(需要联网下载安装)
安装方法就是其实很多,大家可以自己搜索学习,这里举一个简单的例子
源代码
代码将会分成5个小模块和一个整合的代码,
都可以独立运行哦
1、录音
这里需要安装
pip install pyaudio
pip install SpeechRecognition
SpeechRecogintion 是 Python 的一个语音识别框架,
它可以检测语音中的停顿自动终止录音并保存,比 PyAudio 更人性化,很适合语音助手。
import speech_recognition as sr #pyaudio SpeechRecognition模块
def rec(rate=16000): #从系统麦克风拾取音频数据,采样率为 16000
r = sr.Recognizer()
with sr.Microphone(sample_rate=rate) as source:
print("please say something") #这里会打印please say something,提示你说话进行录音
audio = r.listen(source)
with open("recording.wav", "wb") as f: #把采集到的音频数据以 wav 格式保存在当前目录下的recording.wav 文件
f.write(audio.get_wav_data())
return 1
rec() #运行rec函数,录制音频
2、语音识别 (将录音内容进行语音识别转成文字)
首先要去百度AI开放平台,创建API接口应用
记得不用购买,可以先去领取免费资源

这里的App_ID、Api_Key、Secret_Key代码都会用到
这里需要安装
pip install baidu-aip
from aip import AipSpeech
APP_ID = '25016634'
API_KEY = 'Qsj6XGf0m1ilsV0QwLTmHeiy'
SECRET_KEY = 'Mctl1jHY85Hr3wmTpizLI********' #这三个输入你自己的接口账号密钥哈,我就不放了,有需要可以找我要
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
def listen():
with open('recording.wav', 'rb') as f: #将录制好的音频文件recording.wav上传至百度语音的服务,返回识别后的文本结果并输出。
audio_data = f.read()
results = client.asr(audio_data, 'wav', 16000, {
'dev_pid': 1537, #这里的results是一个字典,文本内容在Key名字为result对应的值,这里我恶补了一点字典的知识
})
if 'result' in results:
print("you said: " + results['result'][0]) #results['result']这个是输出Key名字为result对应的值,也就是我们要的文本,至于后面[0]有什么用我还没搞明白,
return results['result'][0]
else:
print("出现错误,错误代码:" , results['err_no']) #不存在result就返回错误代码err_no
listen() #运行listen函数,将录音转成文字
语音识别放回的字典存放在results里面,是一个字典,包含了下面的内容,
result里面就是我们需要的文本了

我刚开始弄的时候一直报错 KeyErrory,我查了下是字典的Key不存在,也就是没有返回result
所以我加了一个判断,就是如果result不存在,就返回错误代码,我就可以去这个网站看出了什么错误了,当然你也可以直接返回err_msg错误信息(如果你英语很好),然后我发现返回的错误代码是:3305,就找到了对应的问题,重新申请一个或者等第二天再弄就可以了

3、接入图灵机器人(将文字发送给机器人获得回复)
首先要去图灵机器人创建一个机器人,这个认证比较麻烦,还要拍身份证啥的,人工认证需要1-2天
注册认证进入图灵机器人的控制台创建一个新的聊天机器人,记下分配到的 Apikey,后面代码要用到
这里需要安装
pip install requests
import requests
import json
TURING_KEY = "d4c739c4b5b7422ab15dc********" #这里输入你的机器人Apikey
URL = "http://openapi.tuling123.com/openapi/api/v2"
HEADERS = {'Content-Type': 'application/json;charset=UTF-8'}
def robot(text=""):
data = {
"reqType": 0,
"perception": {
"inputText": {
"text": ""
},
"selfInfo": {
"location": { #这里输入你的城市
"city": "广州",
"street": "大学城"
}
}
},
"userInfo": {
"apiKey": 'd4c739c4b5b7422ab15dc********', #这里输入你的机器人Apikey
"userId": "123"
}
}
data["perception"]["inputText"]["text"] = text
response = requests.request("post", URL, json=data, headers=HEADERS)
response_dict = json.loads(response.text)
result = response_dict["results"][0]["values"]["text"] #把机器人回复的文字储存在result里
print("the AI said: " + result)
return result
robot("你好吗?") #运行robot函数,与机器人聊天
4、语音合成 (将回复的文字进行语音合成)
这里用到的还是百度AI开放平台的 App_ID、Api_Key、Secret_Key
from aip import AipSpeech
APP_ID = '25016634'
API_KEY = 'Qsj6XGf0m1ilsV0QwLTmHeiy'
SECRET_KEY = 'Mctl1jHY85Hr3wmTpizLI********'
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
def speak(text=""):
result = client.synthesis(text, 'zh', 1, { #这里的参数可以调 zh表示中文
'spd': 4, #语速
'vol': 5, #音量
'per': 4, #类型
})
if not isinstance(result, dict):
with open('audio.mp3', 'wb') as f: #保存为当前目录下mp3格式的音频:audio.mp3,不建议用wav格式,wav格式后面我用的是pagame播放无法识别
f.write(result)
f.close()
speak('你好啊!') #运行speak函数,把机器人回复的文字转换成语音
机器人的语速、语调、音量、发声人都可以选择,更改对应参数数值就可以了

5、播放语音
用到的是pygame第三方库(一听就是做游戏的)
这里需要安装
pip install pagame
import pygame
def play():
pygame.mixer.init() # 初始化混音器模块(pygame库的通用做法,每一个模块在使用时都要初始化pygame.init()为初始化所有的pygame模块,可以使用它也可以单初始化这一个模块)
pygame.mixer.music.load("D:/C Language/Python/pythonProject/audio_assistant/audio.mp3") # 加载音乐 ######大坑,注意这里需要使用绝对路径(就是不是默认当前路径,我恶补一下绝对路径和相对路径)
pygame.mixer.music.set_volume(0.5)# 设置音量大小0~1的浮点数
pygame.mixer.music.play() # 播放音频
while pygame.mixer.music.get_busy(): # 在音频播放未完成之前不退出程序
pass
pygame.mixer.music.unload() #停止加载音频
play()
这个看似是最简单的一个,不过却有一个大坑,我弄了好久才搞定。
如果你直接使用 audio.mp3 相对路径,
它在播放完audio.mp3之后,这个audio.mp3就在python里面打开里,我试了好多办法都没办法关闭,
所以它就只能播放一次,后面再播放就会报错,说文件被占用,所以大家记得用绝对路径,
不然后面你跟语音助手对话就只能说一次了。
最终代码来了
import speech_recognition as sr
from aip import AipSpeech
import requests
import json
import pygame
#录音
def rec(rate=16000):
r = sr.Recognizer()
with sr.Microphone(sample_rate=rate) as source:
print("please say something")
audio = r.listen(source)
with open("recording.wav", "wb") as f:
f.write(audio.get_wav_data())
return 1
#语音识别
APP_ID = '25016634'
API_KEY = 'Qsj6XGf0m1ilsV0QwLTmHeiy'
SECRET_KEY = 'Mctl1jHY85Hr3wmT***********'
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
def listen():
with open('recording.wav', 'rb') as f:
audio_data = f.read()
results = client.asr(audio_data, 'wav', 16000, {
'dev_pid': 1537,
})
if 'result' in results:
print("you said: " + results['result'][0])
return results['result'][0]
else:
print("出现错误,错误代码:" , results['err_no'])
#调用图灵机器人
TURING_KEY = "1dde879fa943438e9*********"
URL = "http://openapi.tuling123.com/openapi/api/v2"
HEADERS = {'Content-Type': 'application/json;charset=UTF-8'}
def robot(text=""):
data = {
"reqType": 0,
"perception": {
"inputText": {
"text": ""
},
"selfInfo": {
"location": {
"city": "广州",
"street": "大学城"
}
}
},
"userInfo": {
"apiKey": '1dde879fa943438e9**********',
"userId": "123"
}
}
data["perception"]["inputText"]["text"] = text
response = requests.request("post", URL, json=data, headers=HEADERS)
response_dict = json.loads(response.text)
result = response_dict["results"][0]["values"]["text"]
print("the AI said: " + result)
return result
#语音合成
def speak(text=""):
result = client.synthesis(text, 'zh', 1, {
'spd': 4,
'vol': 5,
'per': 4,
})
if not isinstance(result, dict):
with open('audio.mp3', 'wb') as f:
f.write(result)
#播放音频
def play():
pygame.mixer.init()
pygame.mixer.music.load("D:/C Language/Python/pythonProject/audio_assistant/audio.mp3")
pygame.mixer.music.set_volume(0.5)
pygame.mixer.music.play()
while pygame.mixer.music.get_busy():
pass
pygame.mixer.music.unload()
if __name__ == "__main__":
while True:
rec() # 保存录音文件:recording.wav
text = listen() # 自动打开录音文件recording.wav进行识别,返回 识别的文字存到text
if '结束程序' in text: #这里我设置了一个结束语,说“结束程序”的时候就结束,你也可以改掉
break
text_1 = robot(text) # 将text中的文字发送给机器人,返回机器人的回复存到text_1
speak(text_1) # 将text_1中机器人的回复用语音输出,保存为audio.mp3文件
play() #播放audio.mp3文件
主要就是后面主函数那段代码啦,设置了一个循环可以无限对话下去,还设置了一个“结束程序”
那么我的第一个项目Python智能语音助手就告一段落了!
后面我想学一学树莓派,把这个弄到树莓派里面,再加上一个智能唤醒的功能,做一个独立的 树莓派智能语音助手。
你们有什么好的简单项目也可以推荐给我呀!大家一起做,互相请教总比一个人做效率高。
以上是关于小白如何做一个Python人工智能语音助手的主要内容,如果未能解决你的问题,请参考以下文章
爆肝一周,用Python在物联网设备上写了个智能语音助手-创建阿里云账号