4分钟插入1000万条数据到mysql数据库表
Posted fastjson_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了4分钟插入1000万条数据到mysql数据库表相关的知识,希望对你有一定的参考价值。
准备工作
我用到的数据库为,mysql数据库8.0版本的,使用的InnoDB存储引
创建测试表
CREATE TABLE `product` (
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(100) DEFAULT NULL COMMENT '商品名',
`price` decimal(8,2) DEFAULT NULL COMMENT '价格',
PRIMARY KEY (`id`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='商品表';
一、使用java代码插入
1、编写程序
public class InsertTest {
public static void main(String[] args) throws ClassNotFoundException, SQLException {
final String url = "jdbc:mysql://localhost:3306/blog?characterEncoding=UTF-8&serverTimezone=UTC";
final String name = "com.mysql.cj.jdbc.Driver";
final String user = "root";
final String password = "root";
Connection conn = null;
Class.forName(name);//指定连接类型
conn = DriverManager.getConnection(url, user, password);//获取连接
if (conn!=null) {
System.out.println("获取连接成功");
insert(conn);
}else {
System.out.println("获取连接失败");
}
}
public static void insert(Connection conn) {
// 开始时间
Long begin = System.currentTimeMillis();
// sql前缀
String prefix = "INSERT INTO product(`name`,`price`) VALUES";
try {
// 保存sql后缀
StringBuffer suffix = new StringBuffer();
// 设置事务为非自动提交
conn.setAutoCommit(false);
// 比起st,pst会更好些
PreparedStatement pst = conn.prepareStatement(" ");//准备执行语句
// 外层循环,总提交事务次数
for (int i = 1; i <= 100; i++) {
suffix = new StringBuffer();
// 第j次提交步长
for (int j = 1; j <= 100000; j++) {
// 构建SQL后缀
suffix.append("(");
suffix.append("'"+"小米"+i*j+"',");
suffix.append(""+ ran(100) +"");
suffix.append("),");
}
// 构建完整SQL
String sql = prefix + suffix.substring(0, suffix.length() - 1);
// 添加执行SQL
pst.addBatch(sql);
// 执行操作
pst.executeBatch();
// 提交事务
conn.commit();
// 清空上一次添加的数据
suffix = new StringBuffer();
}
// 头等连接
pst.close();
conn.close();
} catch (SQLException e) {
e.printStackTrace();
}
// 结束时间
Long end = System.currentTimeMillis();
// 耗时
System.out.println("1000万条数据插入花费时间 : " + (end - begin) / 1000 + " s");
System.out.println("插入完成");
}
//创建一个范围内的随机数
public static int ran(int x)
{
java.util.Random random=new java.util.Random();
// 返回0 to x的一个随机数但不会取到x,即返回[0,x)闭开区间的值。
int rn=random.nextInt(x);
return rn;
}
}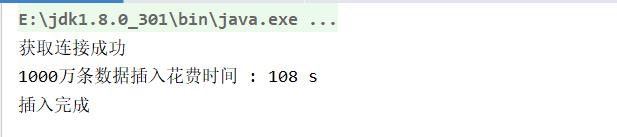
1000万条数据108完成,是不是感觉超级牛逼,
我每次插入10万条数据就提交一次事务,如果是一条一条差的话估计要好几个小时
2、总结
1、选择合适的存储引擎,这个会影响插入速度
2、索引不要创建太多,因为插入数据的时候会保存一份索引的数据
3、使用insert批量插入,每次插入10万条数据就提交一次事务,节省了大量时间
3、设置max_allowed_packet
其实我在插入1000万条数据的时候遇到了一些问题,现在先来解决他们,一开始我插入100万条数据时候报错,控制台的信息如下:
com.mysql.jdbc.PacketTooBigException: Packet for query is too large (4232009 > 4194304). You can change this value on the server by setting the max_allowed_packet’ variable.
出现上面的错误是因为数据库表的 max_allowed_packet这个配置没配置足够大,因为默认的为4M的,后来我调为100M就没报错了
set global max_allowed_packet = 100*1024*1024* 记住,设置好后重新登录数据库才能看的设置后的值show VARIABLES like '%max_allowed_packet%'
二、使用存储过程插入
CREATE DEFINER=`root`@`localhost` PROCEDURE `blog`.`test_insert`()
BEGIN
-- 设置局部变量
DECLARE product_name VARCHAR(20);
DECLARE product_price int(20);
DECLARE n int DEFAULT 1;
start transaction;
-- 开始执行循环体
WHILE n<=10000000 do
SET product_name = CONCAT('小米', n);
SET product_price = FLOOR(RAND()*100);
-- 开始插入数据
INSERT INTO `product`(`name`,`price`) VALUES (product_name,product_price);
SET n=n+1;
END WHILE;
COMMIT;
END在循环开始之前启动一次事务,循环结束后提交,这样每次 insert 就不会重新启动一个事务再提交了:
下面我们优化一下,使用批量插入,拼接sql
-- 调用存储过程,插入10000000条数据
CALL test_insert2(10000000);-- 一个简单的存储过程,通过拼接sql批量向数据库插入数据
-- row_num要插入数据的行数
create procedure blog.test_insert2(in row_num int)
begin
declare name varchar(32);
-- 计数器
declare counter int default 0;
-- 插入语句的前半部分
set @pre_sql = "INSERT INTO `product`(`name`,`price`) VALUES ";
set @exec_sql = @pre_sql;
-- 循环语句
repeat
-- 循环拼接每一行数据
set @exec_sql = concat(@exec_sql,
"('" , concat('小米',FLOOR(RAND()*100)) , "'," , FLOOR(RAND()*100) , "),"
);
set counter=counter+1;
-- 每拼接1000行数据或者技数器达到上限插入一次
if counter mod 10000 = 0 then
-- 出除sql最后一个逗号
set @exec_sql = substring(@exec_sql, 1, char_length(@exec_sql)-1);
-- 预处理需要执行的动态SQL,其中stmt是一个变量
prepare stmt from @exec_sql;
## 执行SQL语句
execute stmt;
## 释放掉预处理段
deallocate prepare stmt;
set @exec_sql = @pre_sql;
end if;
-- 直到计数器大于等于插入行数,退出循环
until counter >= row_num
end repeat;
end总共耗时7分钟
综合上面的测试数据,建议还是使用java代码进行批量插入比较快
以上是关于4分钟插入1000万条数据到mysql数据库表的主要内容,如果未能解决你的问题,请参考以下文章