YoloYolo v1
Posted _睿智_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了YoloYolo v1相关的知识,希望对你有一定的参考价值。
目录
一、基础理论
步骤1:生成备选框。
步骤2:从备选框中找出物体边框。
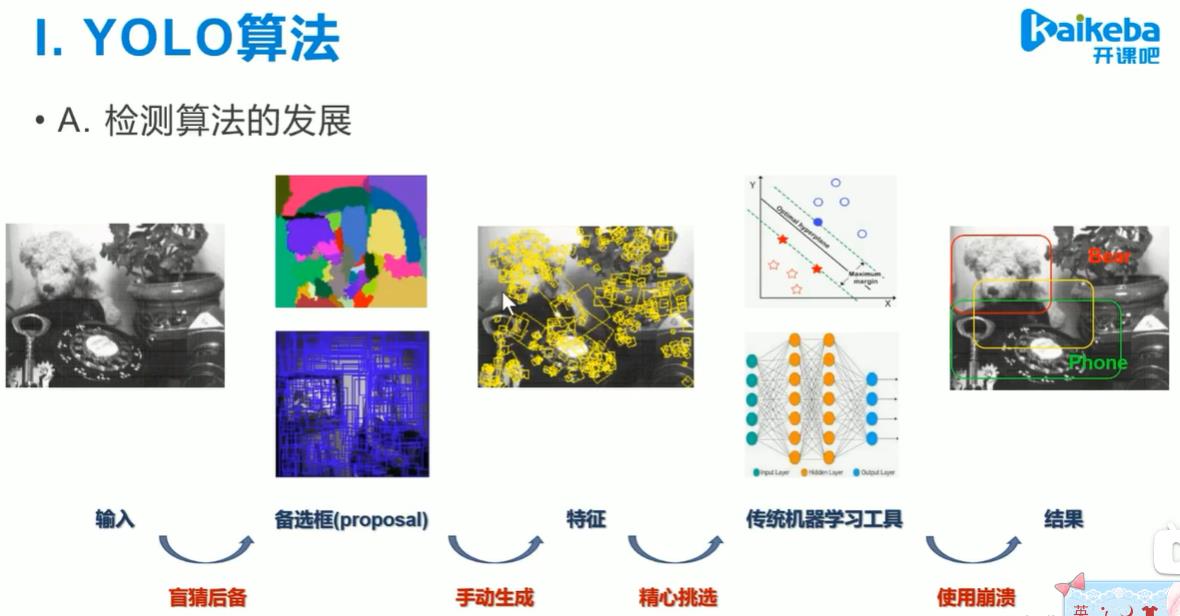
根据像素的突变,进行图像分割,分出不同物体,画出不同颜色的区域,得到备选框(proposal)。我们需要寻找的物体也在备选框中,我们需要把它从备选框中找出来。
优缺点

二、过程
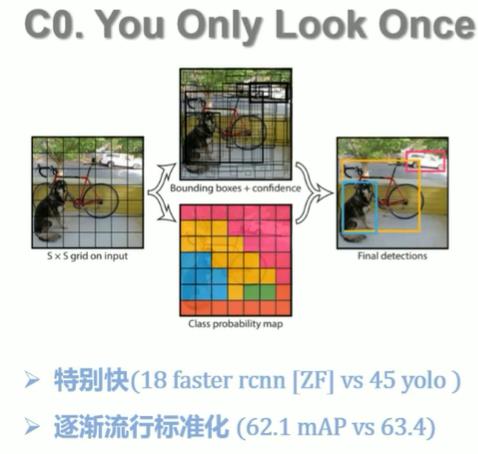
1、对每张图像打格
图像打格过程中,物体中心落在哪个格子,那个格子就负责预测哪个物体。



:预测框。(Yolo v1预测2个边框,多预测几个边框,留下最好的那个)
:置信度(判断是否靠谱)(考虑两方面:(1)是某物体的概率;(2)重合的比例))
:是某物体的概率。 (最后结果在0~1之间)
:交并比(重合部分越高,交并比越大)
得到的Bounding Box五维数据:x、y、w、h、confidence。(横、纵坐标、宽、高、置信度)
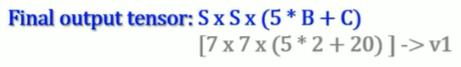 (B不一定得是2)
(B不一定得是2)
以上的五个数据分别为:width * height * (5维 * Box数量B + Confidence)
2、损失函数
由于上面有3个物体,所以获取3个中心:

2-1、损失函数介绍
损失函数:坐标损失(Coordinate loss)、置信度损失(Confidence loss)、分类损失(Classification loss)。
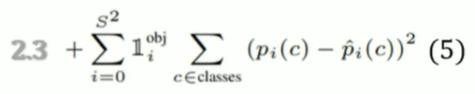
上述4个式子分别计算:坐标、 大小、物体、背景、分类概率的loss。
(这里)误差 = 预测 - 真实
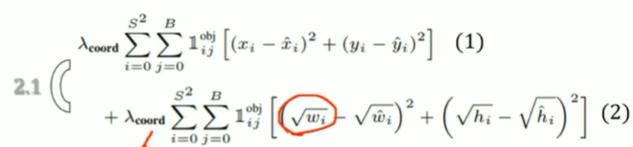

2-2、参数介绍


 (IoU:交并比)
(IoU:交并比)
object:学习物体: 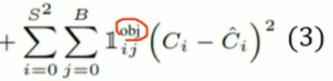
no object:学习背景: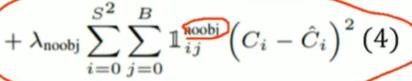
2-3、注意事项
注:
1、(2)式用根号压缩物体的原因:
小物体和大物体的差距过大,尽可能压缩减小差距。(不压缩的话,loss会被大物体严重影响)
2、(4)式noobject(背景)原因:
增强泛化能力。除了要学习物体的信息,我们还需要学习背景信息(有时候背景中可能有和原物体比较像的物体,但不是原物体,为了加以区分)(学习非物体的东西,提高泛化能力)。
3、(4)式加
的原因:
为了减小背景的权重,因为背景通常更大,实际物体更小,所以背景会产生更多的损失。这样会导致网络去学习产生大loss的因素,即侧重于学习背景,而忽略掉学习物体的特征,这不是我们想要的。
以上是关于YoloYolo v1的主要内容,如果未能解决你的问题,请参考以下文章