详解优化sql的过程(看完可以跟面试官正面对线)
Posted 一个还没入门的程序员
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了详解优化sql的过程(看完可以跟面试官正面对线)相关的知识,希望对你有一定的参考价值。
详解优化sql的过程
在我们平时的面试中,如果面试官问起数据库的问题时,一般都逃不开数据库引擎的区别和如何优化sql的问题,关于数据库引擎的区别,我上一篇文章就很详细的写了有兴趣的可以去学习学习(Mysql引擎之间的区别),下面我们就一起来学习学习如何在面试中关于Sql优化问题与面试官进行对线。
1.很多人面试中,当面试官问起你在实际开发中,你是怎么处理一些sql执行很慢的,很多面试者可能想都不想就说直接加索引,这虽然很笼统的说出了如何优化sql 的一种方式,但是这样的答案,在面试官看来是不合格的,不出众的,因为这种回答加索引的,在面试中太多人是这样回答的,这样不能让面试官觉得你是正在懂优化sql 的,因此接下来我们讲讲怎么样的回答能够使得面试官认为你是真正学习过sql优化或者真正在实际开发中使用过msql优化的。
2.sql执行慢总体上有两种优化方式:一种是软件层面的优化、另一种是硬件层面的优化
2.1 硬件层面的优化
首先我们先来说说硬件层面优化:
- 配置运行速度更快的CUP
- 把机械硬盘更换成固态硬盘
- 加大运行内存
硬件层面优化最主要是上面这几种方式。
2.2 软件层面的优化(基于mysql 8.0及以上)
关于软件层面的优化,也是本文章的最主要的核心内容,接下来我们将结合我实际开发中用到的案例进行详细的讲解。
2.2.1 我们要抛弃在面试中,面试官一问到如何优化一些慢查询的时,就不假思索地回答加索引的“陋习”。
当我们实际开发中,我们在执行sql语句需要很长的时间时,我们需要对该语句进行分析,首先是使用explain命令对sql进行分析。接下来我们以案例进行讲解:
即将用到的表结构:

创表语句:
CREATE TABLEinnodb_table(idint DEFAULT NULL,namevarchar(45) DEFAULT NULL,sexvarchar(45) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
我创建了以上简单的数据表。
如何我们执行了一个sql语句

假如执行的时间花了很久,那么我们就要对该语句进行分析,分析过程如下:

 然后发现type为all,说明进行了全表扫描,并且在possible_keys和key中都是为null,说明没有用到索引,其实我们一开始就没有建立索引,因此我们对该sql的优化是对该表进行加个索引,操作如下:
然后发现type为all,说明进行了全表扫描,并且在possible_keys和key中都是为null,说明没有用到索引,其实我们一开始就没有建立索引,因此我们对该sql的优化是对该表进行加个索引,操作如下:
ALTER TABLE `shop`.`innodb_table`
CHANGE COLUMN `id` `id` INT NOT NULL ,
ADD PRIMARY KEY (`id`);
即假如了字段id的索引,然后我们再次执行explain命令
 发现sql查询语句用到了索引,这样就能加快了sql的执行的速度。
发现sql查询语句用到了索引,这样就能加快了sql的执行的速度。
2.2.2 如果上面的查询语句不再是 select * from innodb_table where id =101;,而是变成了select * from innodb_table where name=?时,我们应该怎么优化呢?
执行分析结果很显然的使用了全表扫描,这是读到这里的读者,很清楚的知道要怎么加索引了,对,就是加一个字段为name 的索引;
alter table `innodb_table` add index name_index(name);
在这里我们能看到两条命令的分析结果中possible_keys都是name_index,但是第一条的key却为null,而第二条key却为name_key,从结果看出,第一条查询没有使用到了索引,第二条的索引使用到了索引,这是为什么呢?关于这个的原因,我再文章的后面会进行讲解,这里我们还是先探究加索引方式。
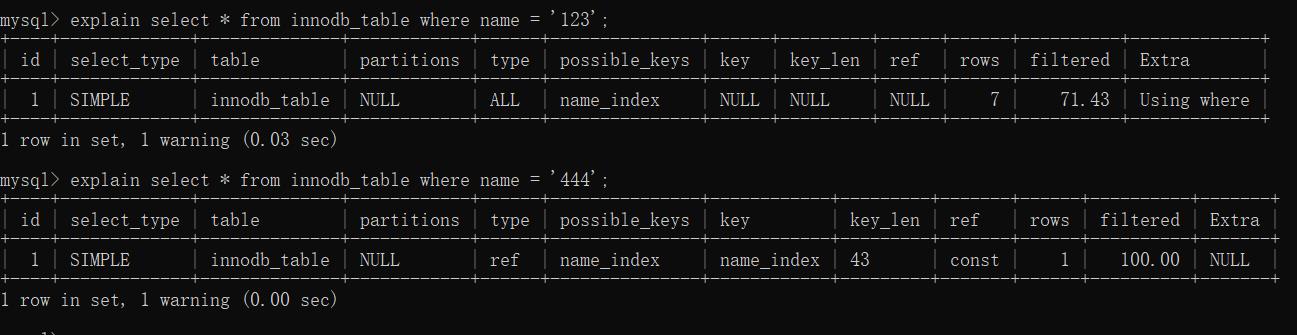 从第二跳的命令中,我们能够分析出我们加了name字段索引后,查询语句使用到了我创建的索引了,因此这就是我们对该语句的优化方式。
从第二跳的命令中,我们能够分析出我们加了name字段索引后,查询语句使用到了我创建的索引了,因此这就是我们对该语句的优化方式。
2.2.3 此时我们的需求又发生了变化,变成了 select name,sex from innodb_table where name =‘444’;那我们要怎么优化呢?首先我们先要分析一下该语句,结果如下:
 name索引,很多人就会觉得这句sql已经很完美了,不能再优化了,其实不是这样的。在innodb引擎中,我们建立的普通索引的树的叶子节点存的是该数据对应的主键的值,而不是存了我们需要查的数据,也就是说,当我们使用了普通的索引后,只是查到该数据的主键值,然后需要再次回表到主键索引的树中,才能读取出我们想要的数据,其实我们可以使用联合索引的覆盖索引的特性去优化该查询的语句的,这样就可以减少回表的次数:
name索引,很多人就会觉得这句sql已经很完美了,不能再优化了,其实不是这样的。在innodb引擎中,我们建立的普通索引的树的叶子节点存的是该数据对应的主键的值,而不是存了我们需要查的数据,也就是说,当我们使用了普通的索引后,只是查到该数据的主键值,然后需要再次回表到主键索引的树中,才能读取出我们想要的数据,其实我们可以使用联合索引的覆盖索引的特性去优化该查询的语句的,这样就可以减少回表的次数:
非主键索引树的结构:

联合索引树的结构:
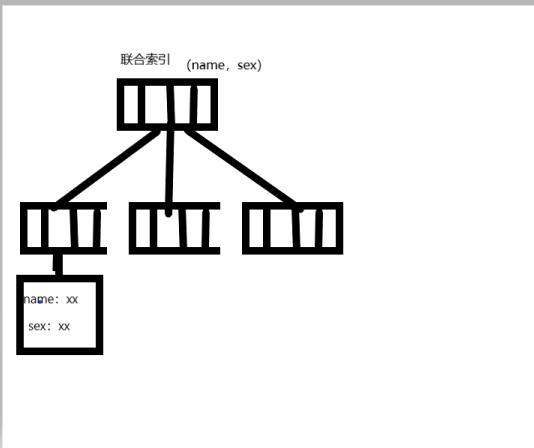
因此从上面的索引树结构中,我们发现如果我们创建(name,sex)联合索引,那么就可以省去回表的步骤,这也能加快sql执行速度。
alter table `innodb_table` add index name_sex_index(name,sex);
执行结果:
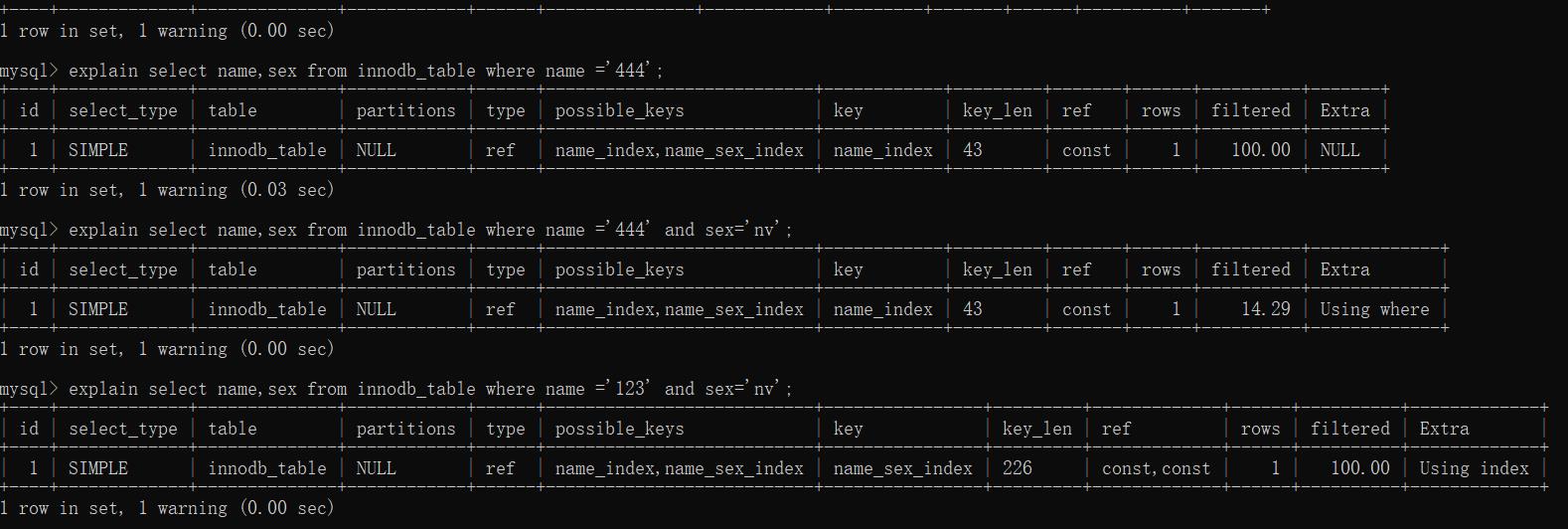
很显然三条命令中,只有第三条使用到了我们创建的索引,这和2.2.2中出现的问题,我们先不进行探究,但是这样的联合索引的优化可以提高查询的效率。
2.2.4 如果通过上面的方式,sql优化的效果还是不明显,那我们就需要考虑是不是表中的数据真的太大了,那就需要进行分库分表了,分库分表可以分为垂直分和水平分,根据自身的业务进行分。
2.2.5 接下来我们就来说说为什么我们建立了索引,而sql在最后执行的时候没有用到呢?
Mysql可以分为几个部分:连接器、分析器、优化器、执行器、引擎。
选择哪个索引的工作是优化器复制的,而优化器选择索引的目的,是找到一个最优的执行方案,并用最小的代价去执行语句。在数据库里面,扫描行数是影响执行代价的因素之一。扫描的行数越少,意味着访问磁盘数据的次数越少,消耗的CPU资源越少。
在mysql执行sql之前,优化器是不能精确的知道满足条件有多少行的,只能通过之前统计的信息来预估有多少行,因此这一步就有可能使得索引选择时与我们预想的结果不一样。
这个统计信息就是索引的“区分度”。显然,一个索引上不同的值越多,这个索引的区分度就越好。而一个索引上不同的值的个数,我们称之为“基数”。也就是说,这个基数越大,索引的区分度越好。
我们可以使用show index方法,看到一个索引的基数
(注意:Cardinality就是我们上面所说的基数)
 通过show index发现我们创建索引的区分度(基数)都不是很大,所以这就导致了优化器选择索引时就会出错。如果我们真的需要mysql按照我们预想的使用索引,我们就可以通过强制索引的方式就行优化了。
通过show index发现我们创建索引的区分度(基数)都不是很大,所以这就导致了优化器选择索引时就会出错。如果我们真的需要mysql按照我们预想的使用索引,我们就可以通过强制索引的方式就行优化了。
例如:
select name,sex from innodb_table force(name_sex_index) where name ='444' and sex='nv';
结果如下:
 不过我们在开发中一般不会使用强制索引的方式,因为优化器选错索引的情况是很少发生的,而且这样写的话,索引改名字了,sql语句就需要改;还有就是比如还数据库了,不同数据库强制索引的方式不一样,因此不建议开发中使用。
不过我们在开发中一般不会使用强制索引的方式,因为优化器选错索引的情况是很少发生的,而且这样写的话,索引改名字了,sql语句就需要改;还有就是比如还数据库了,不同数据库强制索引的方式不一样,因此不建议开发中使用。
本期就先讲到这,下期我们讲讲如何优化我们进行插入操作时比较慢的方法。
以上是关于详解优化sql的过程(看完可以跟面试官正面对线)的主要内容,如果未能解决你的问题,请参考以下文章