你是不是已经成为爸爸程序员了?用Python给自己的宝下载200+绘本动画吧,协程第3遍学习
Posted 梦想橡皮擦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了你是不是已经成为爸爸程序员了?用Python给自己的宝下载200+绘本动画吧,协程第3遍学习相关的知识,希望对你有一定的参考价值。
在 python 爬虫中使用协程,能大幅度提高对目标站点的采集效率,所以我们要反复学习本概念,并将其用在爬虫案例中。
协程的定义
有了两篇文章的铺垫,现在定义一个协程应该是非常简单的了,在一个函数前面增加 async 关键字,函数就变成了协程,你可以直接通过 isinstance 函数,验证其类型。
from collections.abc import Coroutine
async def func():
print("我是协程函数")
if __name__ == '__main__':
# 创建协程对象,注意协程对象不会运行函数内代码,即不会输出任何信息
coroutine = func()
# 类型判断
print(isinstance(coroutine, Coroutine))
代码输入如下内容:
True
sys:1: RuntimeWarning: coroutine 'func' was never awaited
通过类型判断,得到添加 async 关键字的函数是协程类型,下面的警告暂时忽略,原始是该协程没有被注册到事件循环中并得到调用。
使用协程
本次依旧采用一个爬虫案例学习协程,目标站点为 http://banan.huiben.61read.com/,该站点为中少绘本网站,它是中国少年儿童新闻出版总社旗下的绘本网站,网站有大量儿童绘本动画,并且无广告,动画都是 MP4 格式,便于下载。
import asyncio
import requests
# 协程函数
async def get_html():
res = requests.get("http://banan.huiben.61read.com/Video/List/1d4a3be3-0a72-4260-979b-743d9db8ad85")
if res is not None:
return res.status_code
else:
return None
# 声明协程对象
coroutine = get_html()
# 事件循环对象
loop = asyncio.get_event_loop()
# 将协程转换为任务
task = loop.create_task(coroutine)
# task = asyncio.ensure_future(coroutine) # 使用该方法,也可以将协程转换为任务
# 将 task 任务放入事件循环中并调用
loop.run_until_complete(task)
# 输出结果
print("结果输出",task.result())
也可以对上述代码进行改造,python3.7 之后,可以使用 asyncio.run() 方法来运行最高层级的入口函数。
import asyncio
import requests
# 协程函数
async def get_html():
res = requests.get("http://banan.huiben.61read.com/Video/List/1d4a3be3-0a72-4260-979b-743d9db8ad85")
if res is not None:
print(res.status_code)
else:
return None
async def main():
await get_html()
# 声明协程对象
coroutine = get_html()
asyncio.run(main())
接下来参考上述代码,实现对两个 MP4 视频的下载。
# http://static.61read.com/flipbooks/huiben/huazhuangwuhui/web/1.mp4
# http://static.61read.com/flipbooks/huiben/jingubanghexiaofengche/web/1.mp4
import asyncio
import time
import requests
async def requests_get(url):
headers = {
"Referer": "http://banan.huiben.61read.com/",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.54 Safari/537.36"
}
try:
res = requests.get(url, headers=headers)
return res
except Exception as e:
print(e)
return None
async def get_video(url):
res = await requests_get(url)
if res is not None:
with open(f'./mp4/{time.time()}.mp4', "wb") as f:
f.write(res.content)
async def main():
start_time = time.perf_counter()
# http://static.61read.com/flipbooks/huiben/huazhuangwuhui/web/1.mp4
# http://static.61read.com/flipbooks/huiben/jingubanghexiaofengche/web/1.mp4
await get_video("http://static.61read.com/flipbooks/huiben/huazhuangwuhui/web/1.mp4")
await get_video("http://static.61read.com/flipbooks/huiben/jingubanghexiaofengche/web/1.mp4")
print("代码运行时间:", time.perf_counter() - start_time)
if __name__ == '__main__':
asyncio.run(main())
测试在上述代码下,下载两个视频耗时 44S(不同电脑与网速时间不同)。
使用 asyncio.create_task() 函数用来并发运行多个协程
继续修改代码,优化执行时间。
import asyncio
import time
import requests
async def requests_get(url):
headers = {
"Referer": "http://banan.huiben.61read.com/",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.54 Safari/537.36"
}
try:
res = requests.get(url, headers=headers)
return res
except Exception as e:
print(e)
return None
async def get_video(url):
res = await requests_get(url)
if res is not None:
with open(f'./mp4/{time.time()}.mp4', "wb") as f:
f.write(res.content)
async def main():
start_time = time.perf_counter()
# http://static.61read.com/flipbooks/huiben/huazhuangwuhui/web/1.mp4
# http://static.61read.com/flipbooks/huiben/jingubanghexiaofengche/web/1.mp4
task1 = asyncio.create_task(
get_video("http://static.61read.com/flipbooks/huiben/huazhuangwuhui/web/1.mp4"))
task2 = asyncio.create_task(
get_video("http://static.61read.com/flipbooks/huiben/jingubanghexiaofengche/web/1.mp4"))
await task1
await task2
print("代码运行时间:", time.perf_counter() - start_time)
if __name__ == '__main__':
asyncio.run(main())
代码运行时间为 27S,可以看到效率得到了提升。
在正式分析上述代码前,先学习一个 可等待对象 概念
可等待对象
可以在 await 语句中使用的对象,就是可等待对象,可等待对象有三种主要类型:协程,任务,Future
协程在 python 中一定要区分好,协程函数与协程对象,后者是前者所返回的对象。
创建任务
asyncio.create_task(coro, *, name=None) 为创建任务对象并调度其执行,参数1为协程对象,参数2为任务名称,该函数是 python3.7 之后加入的,如果使用之前的版本,请使用 asyncio.ensure_future() 函数。
并发运行任务
函数原型如下所示:
asyncio.gather(*aws, loop=None, return_exceptions=False) -> awaitable
并发运行序列中的可等待对象,如果
aws中的某个可等待对象为协程,它将自动被作为一个任务调度。
return_exceptions 参数说明:
return_exceptions为 False (默认),所引发的首个异常会立即传播给等待gather()的任务。aws 序列中的其他可等待对象不会被取消并将继续运行;return_exceptions为 True,异常会和成功的结果一样处理,并聚合至结果列表。
如果 gather() 被取消,所有被提交 (尚未完成) 的可等待对象也会被取消。
简单等待
函数原型如下:
asyncio.wait(aws, *, loop=None, timeout=None, return_when=ALL_COMPLETED) -> coroutine
并发运行
aws指定的可等待对象并阻塞线程直到满足 return_when 指定的条件。
如果 aws(上述参数) 中的某个可等待对象为协程,它将自动作为任务加入日程。直接向 wait() 传入协程对象已弃用。
该函数返回两个 Task/Future 集合,一般写作 (done, pending)。
return_when 指定此函数应在何时返回。它必须为以下常数之一:
FIRST_COMPLETED:函数将在任意可等待对象结束或取消时返回;FIRST_EXCEPTION:函数将在任意可等待对象因引发异常而结束时返回。当没有引发任何异常时它就相当于 ALL_COMPLETED;ALL_COMPLETED:函数将在所有可等待对象结束或取消时返回。
与 wait() 方法类似的一个方法是 wait_for,该方法原型如下:
asyncio.wait_for(aw, timeout, *, loop=None) -> coroutine
等待 aw 可等待对象 完成,指定 timeout 秒数后超时。
这个函数可以传递协程,如果发生超时,任务取消并引发 asyncio.TimeoutError。
wait() 与 wait_for() 的区别是:wait() 在超时发生时不会取消可等待对象。
绑定回调函数
异步I/O的实现原理,就是在I/O操作的地方挂起程序,等I/O结束后,再继续执行。
编写爬虫程序,很多时候都要依赖IO的返回值,这就要用到回调了。
同步编程实现回调
直接在
await前声明变量,获取回调值
import asyncio
import time
import requests
async def requests_get(url):
headers = {
"Referer": "http://banan.huiben.61read.com/",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.54 Safari/537.36"
}
try:
res = requests.get(url, headers=headers)
return res
except Exception as e:
print(e)
return None
async def get_video(url):
res = await requests_get(url)
if res is not None:
with open(f'./mp4/{time.time()}.mp4', "wb") as f:
f.write(res.content)
return (url,"success")
else:
return None
async def main():
start_time = time.perf_counter()
# http://static.61read.com/flipbooks/huiben/huazhuangwuhui/web/1.mp4
# http://static.61read.com/flipbooks/huiben/jingubanghexiaofengche/web/1.mp4
task1 = asyncio.create_task(
get_video("http://static.61read.com/flipbooks/huiben/huazhuangwuhui/web/1.mp4"))
task2 = asyncio.create_task(
get_video("http://static.61read.com/flipbooks/huiben/jingubanghexiaofengche/web/1.mp4"))
# 同步回调方法
ret1 = await task1
ret2 = await task2
print(ret1,ret2)
print("代码运行时间:", time.perf_counter() - start_time)
if __name__ == '__main__':
asyncio.run(main())
通过 asyncio 添加回调函数功能来实现
用到的方式是
add_done_callback,添加一个回调,该回调将在 Task 对象完成时被运行。与之对应的是移除回调函数,remove_done_callback。
import asyncio
import time
import requests
async def requests_get(url):
headers = {
"Referer": "http://banan.huiben.61read.com/",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.54 Safari/537.36"
}
try:
res = requests.get(url, headers=headers)
return res
except Exception as e:
print(e)
return None
async def get_video(url):
res = await requests_get(url)
if res is not None:
with open(f'./mp4/{time.time()}.mp4', "wb") as f:
f.write(res.content)
return (url, "success")
else:
return None
async def main():
start_time = time.perf_counter()
# http://static.61read.com/flipbooks/huiben/huazhuangwuhui/web/1.mp4
# http://static.61read.com/flipbooks/huiben/jingubanghexiaofengche/web/1.mp4
task1 = asyncio.create_task(
get_video("http://static.61read.com/flipbooks/huiben/huazhuangwuhui/web/1.mp4"))
task1.add_done_callback(callback)
task2 = asyncio.create_task(
get_video("http://static.61read.com/flipbooks/huiben/jingubanghexiaofengche/web/1.mp4"))
task2.add_done_callback(callback)
# 同步回调方法
await task1
await task2
print("代码运行时间:", time.perf_counter() - start_time)
def callback(future):
print('回调函数,返回结果是:', future.result())
if __name__ == '__main__':
asyncio.run(main())
本节课的爬虫案例
本节课爬虫由于涉及很多 MP4 视频,完整代码在 codechina 下载,主要思路整理如下。
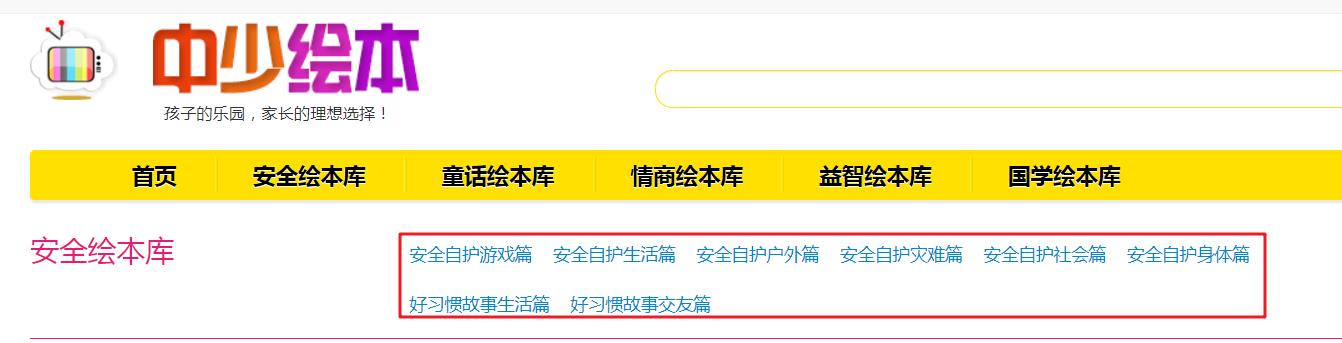
第一步:获取所有列表页的地址
具体数据位置如下所示,由于数据都在一个页面中,顾获取方式比较简单,直接解析网页即可。
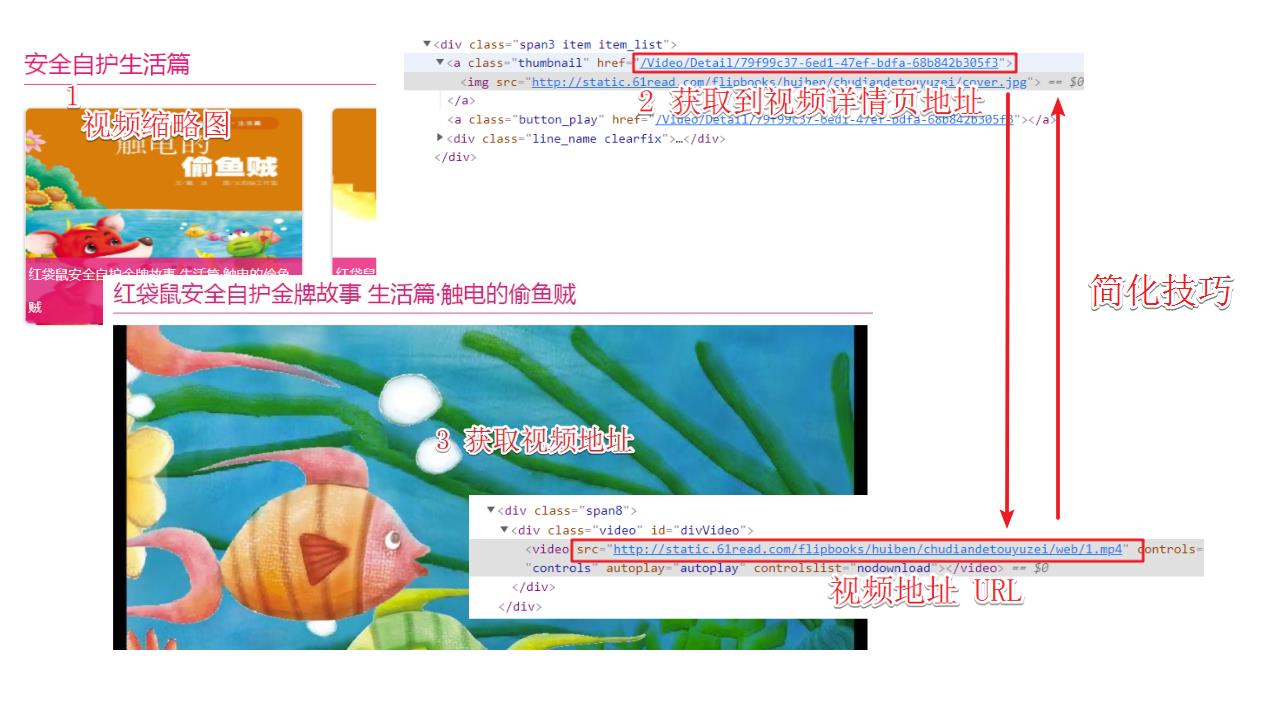
第二步:获取视频下载地址
通过下述流程获取视频地址,在查找过程中发现,视频缩略图的地址与视频播放器地址存在一定的规律,如下所示:
# 视频缩略图地址
http://static.61read.com/flipbooks/huiben/chudiandetouyuzei/cover.jpg
# 视频地址
http://static.61read.com/flipbooks/huiben/chudiandetouyuzei/web/1.mp4
即去除 cover.jpg,替换为 web/1.mp4,这样大幅度降低我们获取视频的层级了。
第三步:编写代码下载视频
import asyncio
import time
import requests
from bs4 import BeautifulSoup
import lxml
BASE_URL = "http://banan.huiben.61read.com"
async def requests_get(url):
headers = {
"Referer": "http://banan.huiben.61read.com/",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.54 Safari/537.36"
}
try:
res = requests.get(url, headers=headers)
return res
except Exception as e:
print(e)
return None
async def get_video(name, url):
res = await requests_get(url)
if res is not None:
with open(f'./mp4/{name}.mp4', "wb") as f:
f.write(res.content)
return (name, url, "success")
else:
return None
async def get_list_url():
"""获取列表页地址"""
res = await requests_get("http://banan.huiben.61read.com/")
soup = BeautifulSoup(res.text, "lxml")
all_a = []
for ul in soup.find_all(attrs={'class', 'inline'}):
all_a.extend(BASE_URL + _['href'] for _ in ul.find_all('a'))
return all_a
async def get_mp4_url(url):
"""获取MP4地址"""
res = await requests_get(url)
soup = BeautifulSoup(res.text, "lxml")
mp4s = []
for div_tag in soup.find_all(attrs={'class', 'item_list'}):
# 获取图片缩略图
src = div_tag.a.img['src']
# 将缩略图地址替换为 mp4 视频地址
src = src.replace('cover.jpg', 'web/1.mp4').replace('cover.png', 'web/1.mp4')
name = div_tag.div.a.text.strip()
mp4s.append((src, name))
return mp4s
async def main():
# 获取列表页地址任务
task_list_url = asyncio.create_task(get_list_url())
all_a = await task_list_url
# 创建任务列表
tasks = [asyncio.ensure_future(get_mp4_url(url)) for url in all_a]
# 添加回调函数
# ret = map(lambda x: x.add_done_callback(callback), tasks)
# 异步执行
dones, pendings = await asyncio.wait(tasks)
all_mp4 = []
for task in dones:
all_mp4.extend(task.result())
# 获取到所有的MP4地址
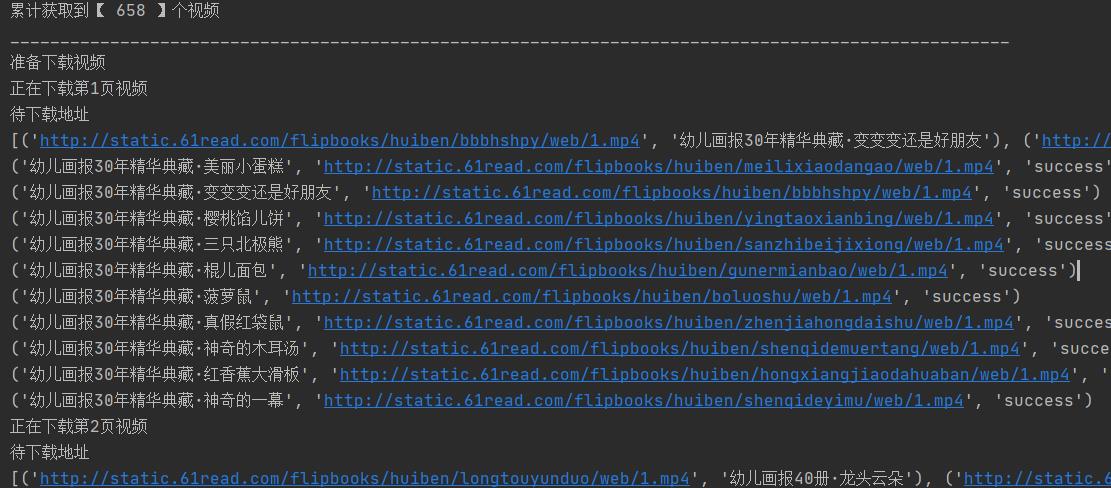
totle = len(all_mp4)
print("累计获取到【", totle, "】个视频")
print("_" * 100)
print("准备下载视频")
# 每次下载10个
totle_page = totle // 10 if totle % 10 == 0 else totle // 10 + 1
# print(totle_page)
for page in range(0, totle_page):
print("正在下载第{}页视频".format(page + 1))
start_page = 0 if page == 0 else page * 10
end_page = (page + 1) * 10
print("待下载地址")
print(all_mp4[start_page:end_page])
mp4_download_tasks = [asyncio.ensure_future(get_video(name, url)) for url, name in all_mp4[start_page:end_page]]
mp4_dones, mp4_pendings = await asyncio.wait(mp4_download_tasks)
for task in mp4_dones:
print(task.result())
if __name__ == '__main__':
asyncio.run(main())
写在后面
如需完整代码,请查看评论区置顶评论。
今天是持续写作的第 243 / 365 天。
期待 关注,点赞、评论、收藏。
更多精彩

以上是关于你是不是已经成为爸爸程序员了?用Python给自己的宝下载200+绘本动画吧,协程第3遍学习的主要内容,如果未能解决你的问题,请参考以下文章