详解python三大器——迭代器生成器装饰器
Posted 网民余某人
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了详解python三大器——迭代器生成器装饰器相关的知识,希望对你有一定的参考价值。
- 迭代器
聊迭代器前我们要先清楚迭代的概念:通常来讲从一个对象中依次取出数据,这个过程叫做遍历,这个手段称为迭代(重复执行某一段代码块,并将每一次迭代得到的结果作为下一次迭代的初始值)。-
可迭代对象(iterable):是指该对象可以被用于for…in…循环,例如:集合,列表,元祖,字典,字符串,迭代器等。
- 在python中如果一个对象实现了 __iter__方法,我们就称之为可迭代对象,可以查看set\\list\\tuple…等源码内部均实现了__iter__方法
- 如果一个对象未实现__iter__方法,但是对其使用for…in则会抛出TypeError: ‘xxx’ object is not iterable
- 可以通过isinstance(obj,Iterable)来判断对象是否为可迭代对象。如:
-
from collections.abc import Iterable
a: int = 1
print(isinstance(a, Iterable)) # False
b: str = "lalalalala"
print(isinstance(b, Iterable)) # True
c: set = set([1, 2])
print(isinstance(c, Iterable)) # True
我们也可以自己实现__iter__来将一个类实例对象变为可迭代对象:
class MyIterable:
def __iter__(self):
pass
print(isinstance(MyIterable(), Iterable)) # True
-
迭代器:对可迭代对象进行迭代的方式或容器,并且需要记录当前迭代进行到的位置。
- 在python中如果一个对象同时实现了__iter__和__next__(获取下一个值)方法,那么它就是一个迭代器对象。
- 可以通过内置函数next(iterator),来获取当前迭代的值
- 迭代器一定是可迭代对象,可迭代对象不一定是迭代器。
- 如果可迭代对象遍历完后继续调用next(),则会抛出:StopIteration异常。
自己实现一个迭代器对象:
from collections.abc import Iterator, Iterable
class MyIterator:
def __init__(self, array_list):
self.array_list = array_list
self.index = 0
def __iter__(self):
return self
def __next__(self):
if self.index < len(self.array_list):
val = self.array_list[self.index]
self.index += 1
return val
else:
raise StopIteration
# 父类如果是迭代器,子类也将是迭代器
class MySubIterator(MyIterator):
def __init__(self):
pass
myIterator = MyIterator([1, 2, 3, 4])
# 判断是否为可迭代对象
print(isinstance(myIterator, Iterable)) # True
# 判断是否为迭代器
print(isinstance(myIterator, Iterator)) # True
# 子类实例化
mySubIterator = MySubIterator()
print(isinstance(mySubIterator, Iterator)) # True
# 进行迭代
print(next(myIterator)) # 1
print(next(myIterator)) # 2
print(next(myIterator)) # 3
print(next(myIterator)) # 4
print(next(myIterator)) # raise StopIteration
迭代器优缺点:
- 优点:迭代器对象表示的是一个数据流,可以在需要时才去调用next来获取一个值;因而本身在内存中始终只保留一个值,对于内存占用小可以存放无限数据流。优于其他容器需要一次将所有元素都存放进内存,如:列表、集合、字典...等
- 缺点:1.无法获取存放的元素长度,除非取完计数。2.只能向后取值,next()永远返回的是下一个值。取值不灵活,无法取出指定值(无法像字典的key,或列表的下标),而且迭代器的生命周期是一次性的元素被迭代完则生命周期结束
- 生成器
定义:在Python中,一边循环一边计算的机制,称为生成器:generator;同时生成器对象也是迭代器对象,所以他有迭代器的特性;例如支持for循环、next()方法…等
作用:对象中的元素是按照某种算法推算出来的,在循环的过程中不断推算出后续的元素,这样就不必创建完整的list,从而节省大量的空间。- 简单生成器:通过将列表生成式[]改成()即可得到一个生成器对象
# 列表生成式
_list = [i for i in range(10)]
print(type(_list)) # <class 'list'>
print(_list) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# 生成器
_generator = (i for i in range(10))
print(type(_generator)) # <class 'generator'>
print(_generator) # <generator object <genexpr> at 0x7fbcd92c9ba0>
# 生成器对象取值
print(_generator.__next__()) # 0
print(next(_generator)) # 1
# 注意从第三个元素开始了!
for x in _generator:
print(x) # 2,3,4,5,6,7,8,9
因为生成器对象也有迭代器的特性,所以元素迭代完后继续调用next()方法则会引发StopIteration。
- 函数对象生成器:带yield语句的函数对象的返回值则是个生成器对象。
def gen_generator():
yield 1
def generator():
return 1
print(gen_generator(), type(gen_generator()))
# <generator object gen_generator at 0x7fe68b2c8b30> <class 'generator'>
print(generator(), type(generator()))
# 1 <class 'int'>
他与普通函数返回值有所不同,普通函数运行到return语句则直接返回代码不再执行;而生成器对象会运行到yield后返回,再下次调用时从yield语句后继续执行。如:
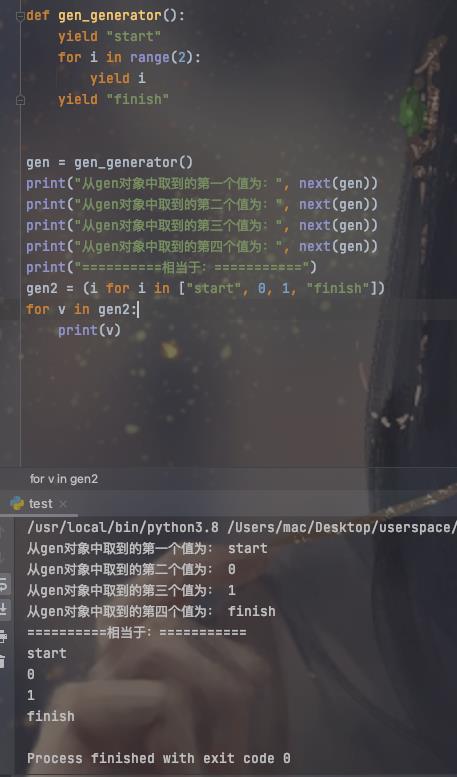
注意:yield 一次只会返回一个元素,即使返回的元素是个可迭代对象,也是一次性返回
def gen_generator2():
yield [1, 2, 3]
s = gen_generator2()
print(next(s)) # [1, 2, 3]
- yield生成器高级应用:
- send()方法,传递值给yield返回(会立即返回!);如果传None,则等同于next(generator)。
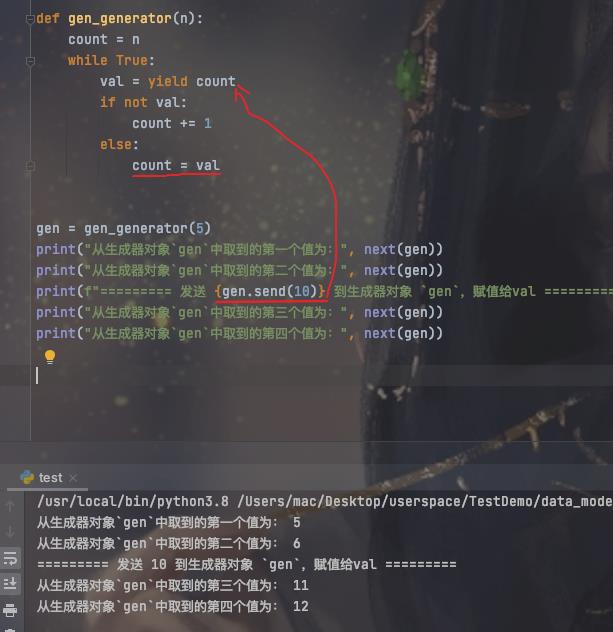
借助send我们可以实现一个简单的生产者-消费者模式如:
- send()方法,传递值给yield返回(会立即返回!);如果传None,则等同于next(generator)。
def consumer():
r = ''
while True:
n = yield r
if not n:
return
print(f'[CONSUMER] Consuming get params.. ({n})')
if n == 3:
r = '500 Error'
else:
r = '200 OK'
def produce(c):
c.send(None) # 启动生成器
n = 0
while n < 5:
n = n + 1
print(f'[PRODUCER] Producing with params.. ({n})')
r = c.send(n) # 一旦n有值,则切换到consumer执行
print(f'[PRODUCER] Consumer return : [{r}]')
if not r.startswith('200'):
print("消费者返回服务异常,则结束生产,并关闭消费者")
c.close() # 关闭生成器
break
consume = consumer()
produce(consume)
# [PRODUCER] Producing with params.. (1)
# [CONSUMER] Consuming get params.. (1)
# [PRODUCER] Consumer return : [200 OK]
# [PRODUCER] Producing with params.. (2)
# [CONSUMER] Consuming get params.. (2)
# [PRODUCER] Consumer return : [200 OK]
# [PRODUCER] Producing with params.. (3)
# [CONSUMER] Consuming get params.. (3)
# [PRODUCER] Consumer return : [500 Error]
# 消费者返回服务异常,则结束生产,并关闭消费者
- yield from iterable 语法,基本作用为:返回一个生成器对象,提供一个“数据传输的管道”,yield from iterable 是 for item in iterable: yield item的缩写;并且内部帮我们实现了很多异常处理,简化了编码复杂度。
- yield 无法获取生成器return的返回值:
def my_generator(n, end_case):
for i in range(n):
if i == end_case:
return f'当 i==`{i}`时,中断程序。'
else:
yield i
g = my_generator(5, 2) # 调用
for _i in g: # for循环不会显式触发异常,故而无法获取到return的值
print(_i)
# 输出:
# 0
# 1
从上面的例子可以看出,for迭代语句不会显式触发异常,故而无法获取到return的值,迭代到2的时候遇到return语句,隐式的触发了StopIteration异常,就终止迭代了,但是在程序中不会显示出来。
可以通过next()显示的触发StopIteration异常来获取返回值:
def my_generator2(n, end_case):
for i in range(n):
if i == end_case:
return f'当 i==`{i}`时,中断程序。'
else:
yield i
g = my_generator2(5, 2) # 调用
try:
print(next(g)) # 0
print(next(g)) # 1
print(next(g)) # 此处要触发end_case了
except StopIteration as exc:
print(exc.value) # 当 i==`2`时,中断程序。
使用yield from 可以简化成:
def my_generator3(n, end_case):
for i in range(n):
if i == end_case:
return f'当 i==`{i}`时,中断程序。'
else:
yield i
def wrap_my_generator(generator): # 将my_generator的返回值包装成一个生成器
result = yield from generator
yield result
g = my_generator3(5, 2) # 调用
for _ in wrap_my_generator(g):
print(_)
# 输出:
# 0
# 1
# 当 i==`2`时,中断程序。
yield from 有以下几个概念名词:
1、调用方:调用委派生成器的客户端(调用方)代码(上文中的wrap_my_generator(g))
2、委托生成器:包含yield from表达式的生成器函数(包装),作用就是提供一个数据传输的管道(上文中的wrap_my_generator)
3、子生成器:yield from后面加的生成器函数(上文中的my_generator)
调用方是通过这个 “包装函数” 来与生成器进行交互的,即“调用方——>委托生成器——>生成器函数”
下面有个例子帮助大家理解(该🌰参考于博客):
# 子生成器
def average_gen():
total = 0
count = 0
average = 0
while True:
new_num = yield average
if new_num is None:
break
count += 1
total += new_num
average = total / count
# 每一次return,都意味着当前协程结束。
return total, count, average
# 委托生成器
def proxy_gen():
while True:
# 只有子生成器要结束(return)了,yield from左边的变量才会被赋值,后面的代码才会执行。
total, count, average = yield from average_gen()
print("总共传入 {} 个数值, 总和:{},平均数:{}".format(count, total, average))
# 调用方
def main():
calc_average = proxy_gen()
next(calc_average) # 激活协程
calc_average.send(10) # 传入:10
calc_average.send(None) # 结束协程 send(None)等于next(calc_acerage),也就是会走到average_gen里面的return语句
print("================== 重开协程 ===================")
calc_average.send(20) # 传入:20
calc_average.send(30) # 传入:30
calc_average.send(None) # 结束协程
if __name__ == '__main__':
main()
# 输出:
# 总共传入 1 个数值, 总和:10,平均数:10.0
# ================== 重开协程 ===================
# 总共传入 2 个数值, 总和:50,平均数:25.0
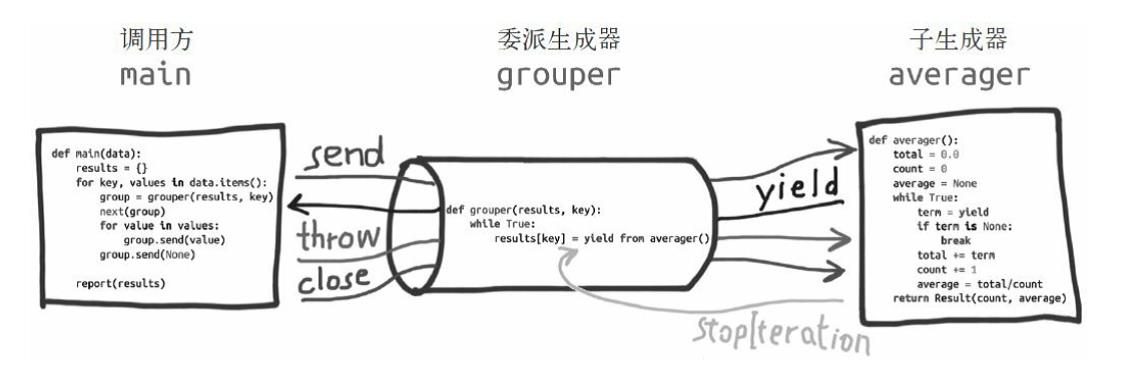
有兴趣的同学可以结合图和下方一起理解:
- 迭代器(即可指子生成器)产生的值直接返还给调用者
- 任何使用send()方法发给委派生产器(即外部生产器)的值被直接传递给迭代器。如果send值是None,则调用迭代器next()方法;如果不为None,则调用迭代器的send()方法。如果对迭代器的调用产生StopIteration异常,委派生产器恢复继续执行yield from后面的语句;若迭代器产生其他任何异常,则都传递给委派生产器。
- 子生成器可能只是一个迭代器,并不是一个作为协程的生成器,所以它不支持.throw()和.close()方法,即可能会产生AttributeError 异常。
- 除了GeneratorExit 异常外的其他抛给委派生产器的异常,将会被传递到迭代器的throw()方法。如果迭代器throw()调用产生了StopIteration异常,委派生产器恢复并继续执行,其他异常则传递给委派生产器。
- 如果GeneratorExit异常被抛给委派生产器,或者委派生产器的close()方法被调用,如果迭代器有close()的话也将被调用。如果close()调用产生异常,异常将传递给委派生产器。否则,委派生产器将抛出GeneratorExit 异常。
- 当迭代器结束并抛出异常时,yield from表达式的值是其StopIteration 异常中的第一个参数。
- 一个生成器中的return expr语句将会从生成器退出并抛出 StopIteration(expr)异常。
- ⭐️装饰器(非常实用!)
讲装饰器之前要先了解两个概念:- 对象引用 :对象名仅仅只是个绑定内存地址的变量
def func(): # 函数名仅仅只是个绑定内存地址的变量
print("i`m running")
# 这是调用
func() # i`m running
# 这是对象引用,引用的是内存地址
func2 = func
print(func2 is func) # True
# 通过引用进行调用
func2() # i`m running
- 闭包:定义一个函数A,然后在该函数内部再定义一个函数B,并且B函数用到了外边A函数的变量
def out_func():
out_a = 10
def inner_func(inner_x):
return out_a + inner_x
return inner_func
out = out_func()
print(out) # <function out_func.<locals>.inner_func at 0x7ff378af5c10> out_func返回的是inner_func的内存地址
print(out(inner_x=2)) # 12
装饰器和闭包不同点在于:装饰器的入参是函数对象,闭包入参是普通数据对象
def decorator_get_function_name(func):
"""
获取正在运行函数名
:return:
"""
def wrapper(*arg):
"""
wrapper
:param arg:
:return:
"""
print(f"当前运行方法名:{func.__name__} with params: {arg}")
return func(*arg)
return wrapper
# @func_name是python的语法糖
@decorator_get_function_name
def test_func_add(x, y):
print(x + y)
def test_func_sub(x, y):
print(x - y)
test_func_add(1, 2)
# 输出:
# 当前运行方法名:test_func_add with params: (1, 2)
# 3
# 不使用语法糖的话也可以用以下方法,效果是一样的
decorator_get_function_name(test_func_sub)(3, 5)
# 还记得前文讲的引用吗?我们还可以换种写法达到跟👆一样的效果
dec_obj = decorator_get_function_name(test_func_sub) # 这里等同于wrapper对象
dec_obj(3,5) # 这里等同于wrapper(3,5)
# 输出:
# 当前运行方法名:test_func_sub with params: (3, 5)
# -2
常用于如鉴权校验,例如笔者会用于登陆校验:
def login_check(func):
def wrapper(request, *args, **kwargs):
if not request.session.get('login_status'):
return HttpResponseRedirect('/api/login/')
return func(request, *args, **kwargs)
return wrapper
@login_check
def edit_config():
pass
装饰器内部的执行逻辑:
"""
> 1. def login_check(func): ==>将login_check函数加载到内存
> ....
> @login_check ==>此处已经在内存中将login_check这个函数执行了!;并不需要等edit_config()实例化调用
> 2. 上例@login_check内部会执行以下操作:
> 2.1 执行login_check函数,并将 @login_check 下面的 函数(edit_config) 作为login_check函数的参数,即:@login_check 等价于 login_check(edit_config)
> 2.2 内部就会去执行:
def wrapper(*args):
# 校验session...
return func(request, *args, **kwargs) # func是参数,此时 func 等于 edit_config,此处相当于edit_config(request, *args, **kwargs)
return wrapper # 返回的 wrapper,wrapper代表的是函数对象,非函数实例化对象
2.3 其实就是将原来的 edit_config 函数塞进另外一个函数中,另一个函数当中可以做一些操作;再执行edit_config
2.4 将执行完的 login_check 函数返回值(也就是 wrapper对象)将此返回值再重新赋值给新 edit_config,即:
2.5 新edit_config = def wrapper:
# 校验session...
return 原来edit_config(request, *args, **kwargs)
> 3. 也就是新edit_config()=login_check(edit_config):wrapper(request, *args, **kwargs):return edit_config(request, *args, **kwargs) 有点绕,大家看步骤细细理解。
"""
同样一个函数也可以使用多个装饰器进行装饰,执行顺序从上到下
from functools import wraps
def w1(func):
@wraps(func)
def wrapper(*args, **kwargs):
print("这里是第一个校验")
return func(*args, **kwargs)
return wrapper
def w2(func):
@wraps(func)
def wrapper(*args, **kwargs):
print("这里是第二个校验")
return func(*args, **kwargs)
return wrapper
def w3(func):
def wrapper(*args, **kwargs):
print("这里是第三个校验")
return func(*args, **kwargs)
return wrapper
@w2 # 这里其实是w2(w1(f1))
@w1 # 这里是w1(f1)
def f1():
print(f"i`m f1, at {f1}")
@w3
def f2():
print(f"i`m f2, at {f2}")
# ====================== 实例化阶段 =====================
f1()
# 这里是第二个校验
# 这里是第一个校验
# i`m f1, at <function f1 at 0x7febc52f5e50>
f2()
# 这里是第三个校验
# i`m f2, at <function w3.<locals>.inner at 0x7febc52f5f70>
有同学可能要好奇 为什么f1对象打印的是“<function f1 at 0x7febc52f5e50>”,f2对象打印的是“<function w3..wrapper at 0x7febc52f5f70>”(也就是步骤2.5造成的,赋的值是wrapper对象),这就跟w1和w2 内部wrapper使用的wraps装饰器有关系了。
wraps的作用是:被修饰的函数(也就是里面的func)的一些属性值赋值给修饰器函数(wrapper)包括元信息和“函数对象”等。
同时装饰器也可以接受参数:
def decorator_get_function_duration(enable):
"""
:param enable: 是否需要统计函数执行耗时
:return:
"""
print("this is decorator_get_function_duration")
def inner(func):
print('this is inner in decorator_get_function_duration')
@wraps(func)
def wrapper(*args, **kwargs):
print('this is a wrapper in decorator_get_function_duration.inner')
if enable:
start = time.time()
print(f"函数执行前:{start}")
result = func(*args, **kwargs)
print('[%s]`s enable was %s it`s duration : %.3f s ' % (func.__name__, enable, time.time() - start))
else:
result = func(*args, **kwargs)
return result
return wrapper
return inner
def decorator_1(func):
print('this is decorator_1')
@wraps(func)
def wrapper(*args, **kwargs):
print('this is a wrapper in decorator_1')
return func(*args, **kwargs)
return wrapper
def decorator_2(func):
print('this is decorator_2')
Python基础 | 深浅拷贝生成器迭代器以及装饰器详解