神经网络全连接层详解
Posted 17岁boy想当攻城狮
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了神经网络全连接层详解相关的知识,希望对你有一定的参考价值。
全连接层即:每一个节点都与上一层的节点相连,每个节点都视为一个特征点,当产生一个输入源后会对全连接层做卷积操作,卷积核多大取决于你的全连接层每层数据表有多大,全连接层里每一层都是一组数据,这组数据里包含了每次训练的结果,通俗易懂的说就是当输入一个数据后,对全连接层进行循环遍历的操作,每次遍历时对每层进行卷积运动若每层中有相似数据则记录为1,然后遍历完所有层后将所有记录值集合成一个值输出。
下面用一个简单的例子来看:
我们想在一个方框中识别出是否有一张猫的图片,猫的位置不是固定的,可能在方框的右上角,也可能在左下角,这对于计算机视觉来说会比较简单,但是对于机器学习不一样,机器学习不知道什么是图片,也不知道什么是方框,更不知道这个图片出现在什么地方算是正确的,所以我们需要给它一组数据,告诉它猫在哪个位置是正确的,因此我们需要准备非常多的特征,即猫在方框中的各个位置的特征,然后用机器学习去训练,并在指定位置出现猫的特征时给机器奖励,这个奖励值会被记录到当前训练的全连接层的某一层中,如果方框里没有猫则没有奖励反而还要被惩罚,利用这样的机制给定特征之后使用全连接层模型去训练,完成之后会得到一组可观的全连接层模型。
如下有两张猫咪图片在方框不同位置的图片

当我们把数据输入之后全连接层会对每层数据进行卷积:

可以看到首先将图像数据转化为了(Feature MAP)特征映射(即转化为向量),然后去我们的模型滤器(Filter)里进行卷据遍历,特征映射会与全连接层的每一层进行比较运算,最后发现每一层都有类似的特征数据然后输出的值就会越来越大最终输出一个比较大的数字,这个数字越大则代表越相似,所以我们可以通过这个数字来判断是否相似,可以自己设置阈值。
我们每次训练神经库的时候不会只训练一次可能每个角度的猫咪图片会训练上万次,所以一组数据下来每个角度的猫咪可能有几十万组数据,这里假设一个模型有二十万组数据,那么处于左上角猫咪的特征大概有五万组数据,当每一层遍历时发现这五万组里都符合遍历时累加值会越来越多,不符合的则不变,也有部分图片中猫咪在左上角附近我们也给了奖励,所以最后将所有遍历条件集合成一个值时会发现这个值非常大,则认为这个猫咪是存在图像中的,这一步仅仅是做到了图像中是否有猫咪这样的一个工作,但是还无法分类,比如猫咪的种类,猫咪的动作等等,上述的描述仅仅只能针对于特定场景的猫咪是否存在于方框中。
所以如果想要判断一幅图中是否有猫咪,可以将猫咪的每个部位都训练一次:

最后在进行全连接层遍历,红色部分则代表找到对应特征,其它层没有找到的则为输入特征不明显或模型特征太少,找不到输出的值就会越低

最后我们可以根据每个全连接层输出的值来判断一幅图中是否有猫咪,如果有猫咪的一半特征则认为有猫咪,或者有猫咪的一个特征都认为有猫咪。
当然更精准一点你可以根据猫咪的器官进行分类识别,下图是两层全连接层,两层全连接层是有两组全连接层模型组合的,可以用于解决非线性的问题,因为我们找到了猫的器官还要去比较这个器官属于猫的哪个部位,所以用两层全连接层做分类。

输入数据在全连接层1中找到对应的模型后通过全连接层的激活函数去寻找下一个全连接层2,在全连接层2中寻找对应的模型分类,然后输出
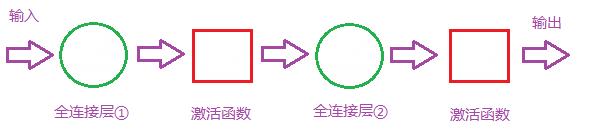
两层全连接会造成训练成本会比较高,其次因为是非线性时间周期所以在模型比对时时间成本会比较大

以上是关于神经网络全连接层详解的主要内容,如果未能解决你的问题,请参考以下文章