MySql相关
Posted 买糖买板栗
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySql相关相关的知识,希望对你有一定的参考价值。
目录
3 Mysql 中 MyISAM 和 InnoDB 的区别有哪些?
1 索引数据结构:B+树
联合索引(a, b),第一个和第二个触发条件,where a=会触发嘛,where b=会嘛,为什么?
CREATE TABLE E (e1 INT, e2 VARCHAR(9), e3 INT, PRIMARY KEY(e1, e3)); 这样就建立了一个联合索引:e1,e3
触发联合索引是有条件的:偏左原理
1、使用联合索引的全部索引键,可触发索引的使用。
例如:SELECT E.* FROM E WHERE E.e1=1 AND E.e3=2
2、使用联合索引的前缀部分索引键,如“key_part_1 常量”,可触发索引的使用。
例如:SELECT E.* FROM E WHERE E.e1=1
3、使用部分索引键,但不是联合索引的前缀部分,如“key_part_2 常量”,不可触发索引的使用。
例如:SELECT E.* FROM E WHERE E.e3=1
二叉树不能作为数据库的索引数据结构,是因为其高度太高,磁盘IO次数过多导致性能降低;查找一个数据,可能需要树高度次数的IO(一次无法读取所有的索引数据,因为太大,每次只能读取一个磁盘页),而B树(B-)是多路平衡查找树,不是二叉树哦,他的每个节点最多会有K个子节点(比2更多),k被称作B树的阶,他要把原本瘦高的树结构变得矮胖。磁盘IO永远都比内存中的计算慢很多,所以尽量减少磁盘IO的操作就会加快查询速度。
2 数据库索引
1、聚集索引、非聚集索引
聚集索引:数据行的物理顺序与列值(一般是主键的那一列,primary key)的逻辑顺序相同,一个表中只能拥有一个聚集索引。聚集索引的好处了,索引的叶子节点就是对应的数据节点
非聚集索引:该索引中索引的逻辑顺序与磁盘上行的物理存储顺序不同,一个表中可以拥有多个非聚集索引。其实按照定义,除了聚集索引以外的索引都是非聚集索引,只是人们想细分一下非聚集索引,分成普通索引,唯一索引,全文索引。如何解决非聚集索引的二次查询问题:复合索引(覆盖索引),注意使用复合索引需要满足最左侧索引的原则。
3 Mysql 中 MyISAM 和 InnoDB 的区别有哪些?
区别:
1. InnoDB支持事务,MyISAM不支持,对于InnoDB每一条SQL语言都默认封装成事务,自动提交,这样会影响速度,所以最好把多条SQL语言放在begin和commit之间,组成一个事务;
2. InnoDB支持外键,而MyISAM不支持。对一个包含外键的InnoDB表转为MYISAM会失败;
3. InnoDB是聚集索引,数据文件是和索引绑在一起的,必须要有主键,通过主键索引效率很高。但是辅助索引需要两次查询,先查询到主键,然后再通过主键查询到数据。因此,主键不应该过大,因为主键太大,其他索引也都会很大。而MyISAM是非聚集索引,数据文件是分离的,索引保存的是数据文件的指针。主键索引和辅助索引是独立的。
4. InnoDB不保存表的具体行数,执行select count(*) from table时需要全表扫描。而MyISAM用一个变量保存了整个表的行数,执行上述语句时只需要读出该变量即可,速度很快;
5. Innodb不支持全文索引,而MyISAM支持全文索引,查询效率上MyISAM要高;
如何选择:
1. 是否要支持事务,如果要请选择innodb,如果不需要可以考虑MyISAM;
2. 如果表中绝大多数都只是读查询,可以考虑MyISAM,如果既有读写也挺频繁,请使用InnoDB。
3. 系统奔溃后,MyISAM恢复起来更困难,能否接受;
4. mysql5.5版本开始Innodb已经成为Mysql的默认引擎(之前是MyISAM),说明其优势是有目共睹的,如果你不知道用什么,那就用InnoDB,至少不会差。
注意:mysql5.7的innodb已支持全文索引
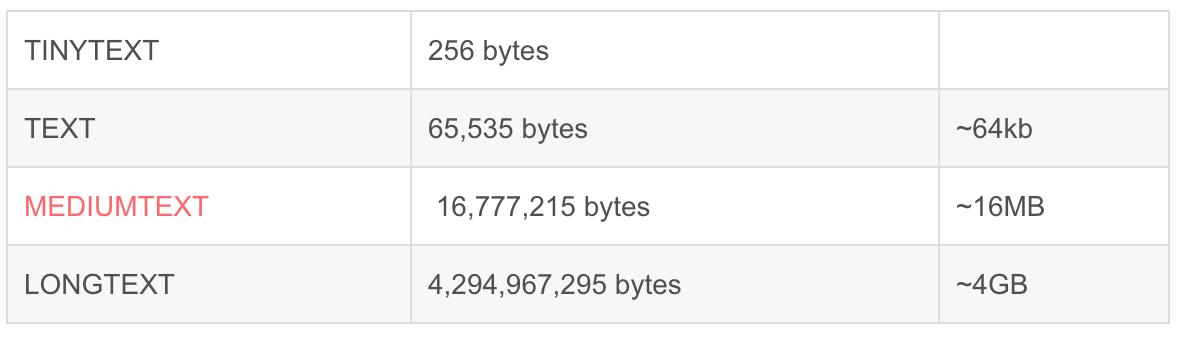
- text类型最大多少长度
- mysql事务的隔离级别:
脏读 事务A读取了事务B更新的数据,然后B回滚操作,那么A读取到的数据是脏数据 不可重复读 事务 A 多次读取同一数据,事务 B 在事务A多次读取的过程中,对数据作了更新并提交,导致事务A多次读取同一数据时,结果 不一致 幻读 系统管理员A将数据库中所有学生的成绩从具体分数改为ABCDE等级,但是系统管理员B就在这个时候插入了一条具体分数的记录,当系统管理员A改结束后发现还有一条记录没有改过来,就好像发生了幻觉一样,这就叫幻读。
小结:不可重复读的和幻读很容易混淆,不可重复读侧重于修改,幻读侧重于新增或删除。解决不可重复读的问题只需锁住满足条件的行,解决幻读需要锁表
| 事务隔离级别 | 脏读 | 不可重复读 | 幻读 |
| 读未提交(read-uncommitted) | 是 | 是 | 是 |
| 不可重复读(read-committed) | 否 | 是 | 是 |
| 可重复读(repeatable-read) | 否 | 否 | 是 |
| 串行化(serializable) | 否 | 否 | 否 |
mysql默认的事务隔离级别为可重复读(repeatable-read)
4 MySQL 执行计划
explain select * from t_base_user where name="zhengchao"
执行计划输出结果每一列解释:执行计划-含义
-
id:表示查询中select操作表的顺序,按顺序从大到依次执行
-
select_type:该表示选择的类型,可选值有: SIMPLE(简单的),
-
type:该属性表示访问类型,有很多种访问类型。最常见的其中包括以下几种: ALL(全表扫描), index(索引扫描),range(范围扫描),ref (非唯一索引扫描),eq_ref(唯一索引扫描,),(const)常数引用, 访问速度依次由慢到快。其中 : range(范围)常见与 between and …, 大于 and 小于这种情况。提示 : 慢SQL是否走索引,走了什么索引,也就可以通过该属性查看了。
-
table:表示该语句查询的表
-
possible_keys:顾名思义,该属性给出了,该查询语句,可能走的索引,(如某些字段上索引的名字)这里提供的只是参考,而不是实际走的索引,也就导致会有possible_Keys不为null,key为空的现象。
-
key:显示MySQL实际使用的索引,其中就包括主键索引(PRIMARY),或者自建索引的名字。
-
key_len:表示索引所使用的字节数,
-
ref:连接匹配条件,如果走主键索引的话,该值为: const, 全表扫描的话,为null值
-
rows:扫描行数,也就是说,需要扫描多少行,采能获取目标行数,一般情况下会大于返回行数。通常情况下,rows越小,效率越高, 也就有大部分SQL优化,都是在减少这个值的大小。注意: 理想情况下扫描的行数与实际返回行数理论上是一致的,但这种情况及其少,如关联查询,扫描的行数就会比返回行数大大增加)
-
Extra:这个属性非常重要,该属性中包括执行SQL时的真实情况信息,如上面所属,使用到的是”using where”,表示使用where筛选得到的值,常用的有:“Using temporary”: 使用临时表 “using filesort”: 使用文件排序
以上是关于MySql相关的主要内容,如果未能解决你的问题,请参考以下文章