阿里云RDS深度定制-XA Crash Safe
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阿里云RDS深度定制-XA Crash Safe相关的知识,希望对你有一定的参考价值。
简介: 近几年,随着分布式数据库系统的兴起,特别是基于mysql分布式数据库系统,会用到XA来保证全局事务的一致性。众所周知,MySQL对XA事务的支持是比较弱的,存在很多问题。为了满足分布式数据库系统对XA事务的要求,阿里做了大量的工作。 本篇内容将从两部分介绍,第一部分介绍在AliSQL分支上做的一些实用功能;第二部分介绍XA Crash Safe问题的根源和在5.7和8.0版本上的实现原理。
一、阿里云RDS MySQL(AliSQL)
AliSQL是MySQL的分支,阿里在这个分支上做了很多深度的定制,以充分挖掘MySQL的潜力。AliSQL支撑了阿里集团电商业务十余年,其稳定性、安全性和高性能是经过了极其严苛实践检验的。除此之外,AliSQL做了很多实用性的功能,以提高MySQL的易用性和使用效率。下图是AliSQL上重要的功能的列表。
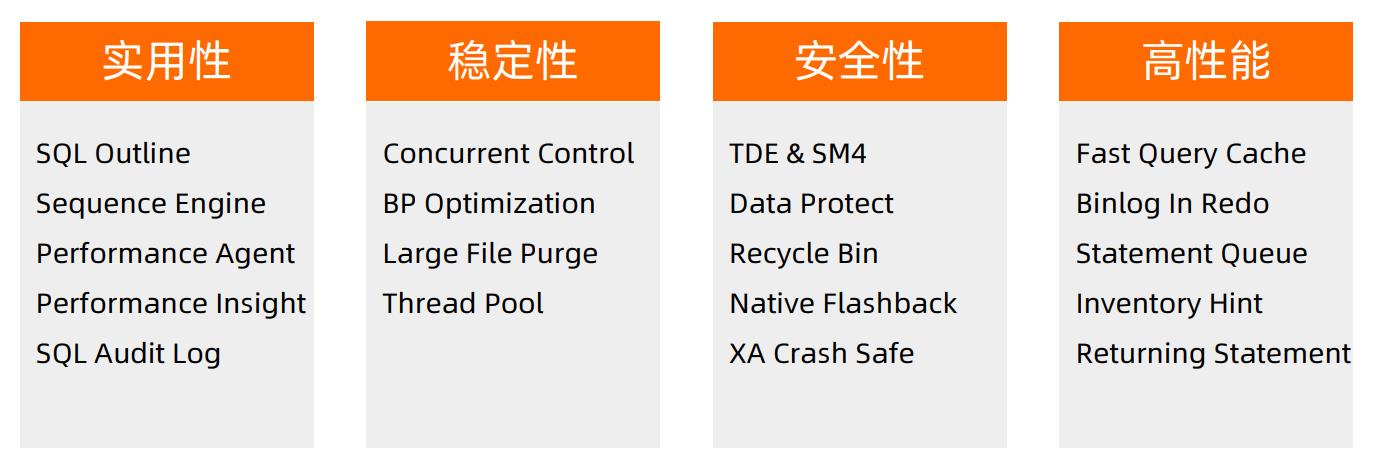
二、RDS定制化功能介绍
1. 实用性:SQL Outline 在线固化SQL执行计划
我们使用MySQL的时候时常会碰到一种情况,即业务跑着的时候有个SQL执行会变慢,分析之后发现是这个SQL执行计划发生了变化。这种变化有很多原因,比如bug或是版本升级了等等。
MySQL就提供了hint功能,它可以使我们在SQL语句里增加一些提示,以保证SQL在生成执行计划的时候是按照提示来工作的。但这只是比较理想化的状态,实际情况中这样是很不方便的,因为业务已经在线上运行了,这个时候即使能够改变业务的SQL,也需要一个很漫长的时间和过程。
为了解决这个问题,就有了SQL Outline的功能。这个功能不需要改变应用的SQL语句,只需要在server端告诉RDS碰到哪种类型的特定的SQL,可以给它定制一个hint,然后按照用户指定的方式执行。
2. 实用性:Performance Agent可诊断、可度量
我们在实例的监控上也做了大量的工作,从而可以很容易的分析数据库中的一些问题。首先就是实例级别的统计信息,它包括了操作系统层面、server层和InnoDB等共计55个指标。然后把它放到一个Performance表中,每秒钟进行一次统计。通过这些统计的信息可以分析系统出现问题的原因。
3. 实用性:Performance Insight可诊断、可度量
这个是对象级别性能度量的指标,包括表和索引。这些统计可以支持业务数据模型的优化和变更。
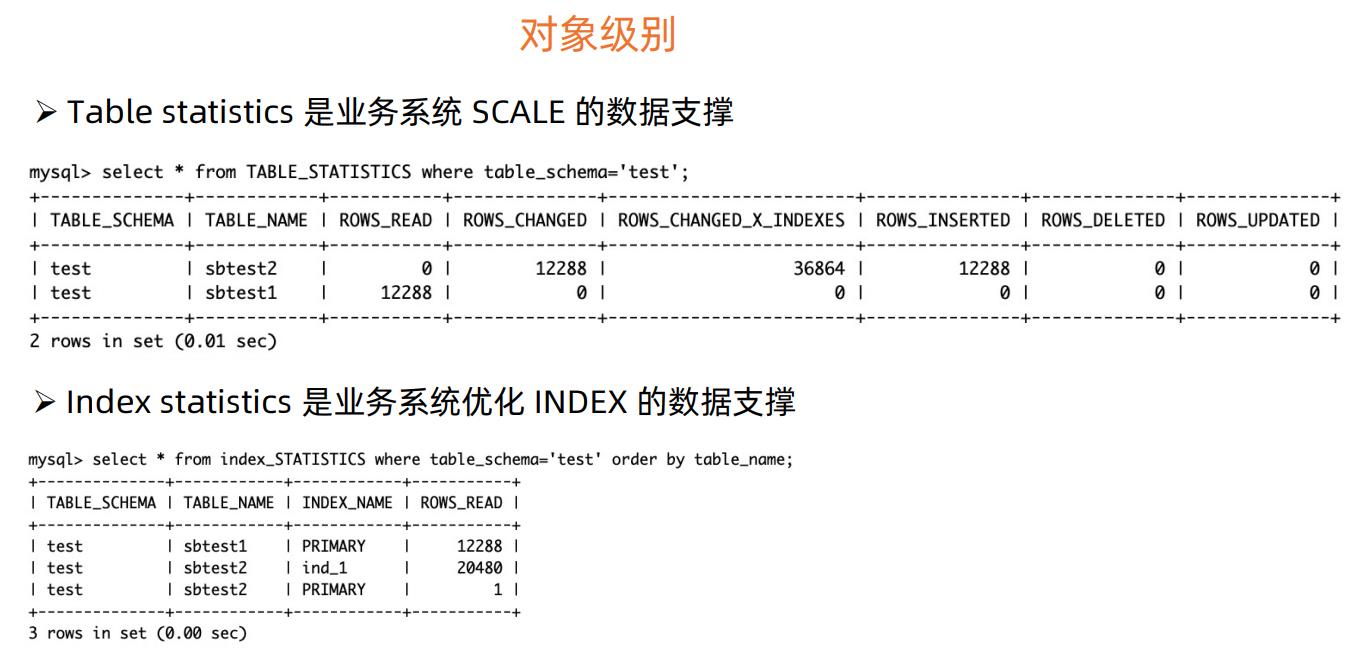
还有语句级别的统计信息。MySQL本身具有语句级别统计信息,但是它的统计信息不够丰富,因此在这个基础上我们又增加了更多实用性的统计信息,比如CPU的使用时间,加锁消耗的时间等。
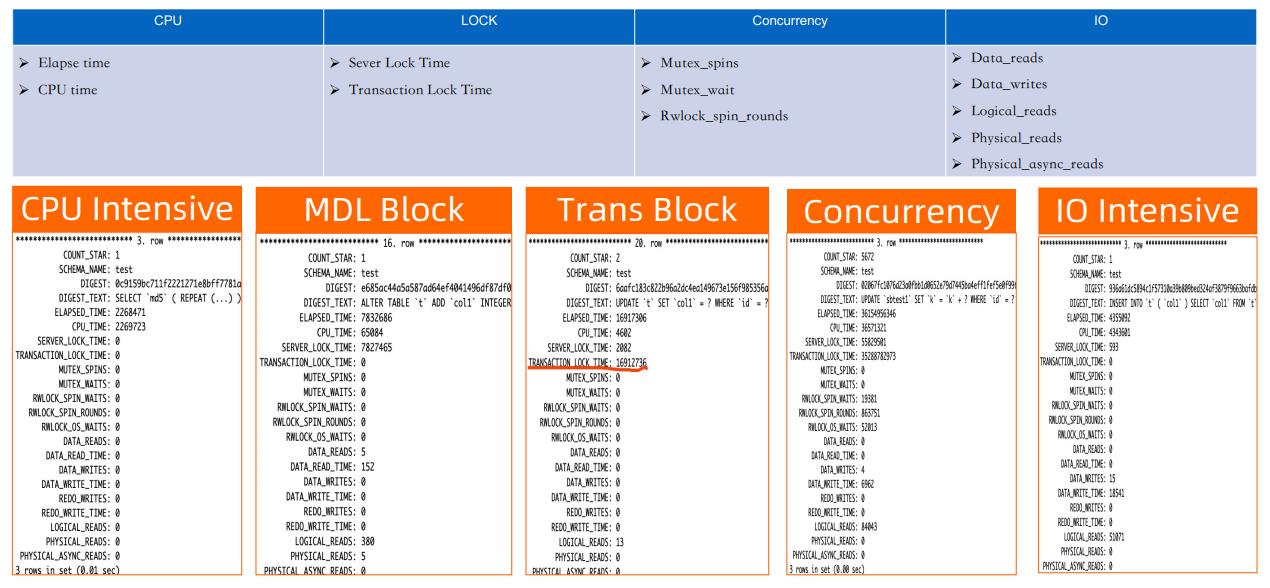
MySQL里用了大量的Mutex来保证多线程之间的数据访问,我们加了对于Mutex加锁时消耗时间的统计,方便对数据库热点的分析。
这些统计信息提供了更充分的数据依据,帮助我们做快速的问题定位。
4. 稳定性:Buffer Pool优化
在稳定性方面,我们也做了大量的工作。首先是Buffer Pool的优化。
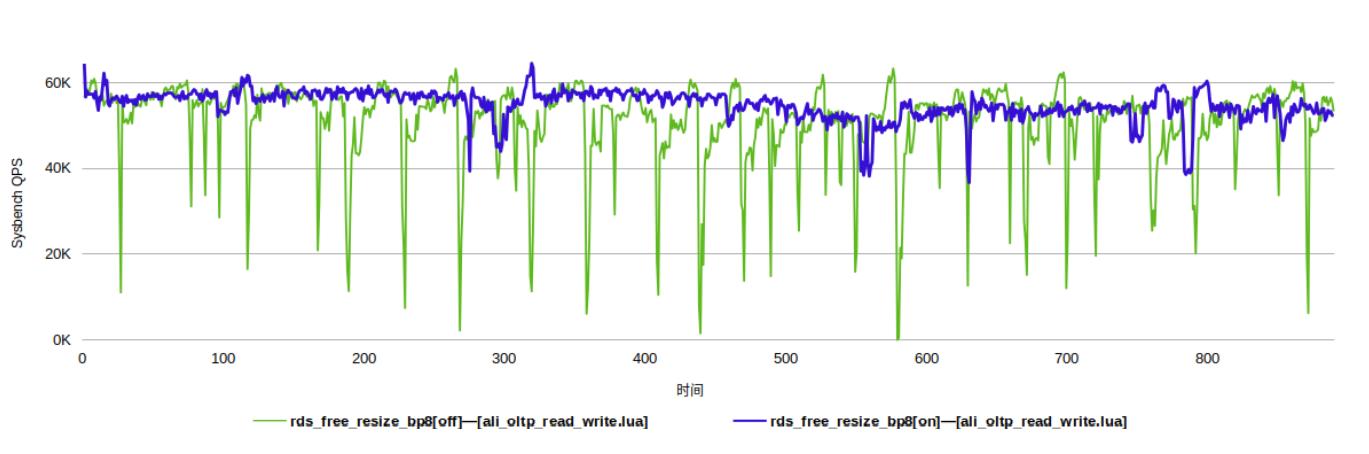
云上用户会有临时变配的需求。举个例子,在业务高峰时,若希望实例临时规格变大,过了高峰之后再把规格降下来。MySQL是支持线上的resize,但是它的稳定性不够好。在做Online resize对性能的影响还是比较大的。AliSQL针对这个做了优化后,可以看到下图蓝色线条是动态变配的波动曲线,稳定性好很多。
5. 稳定性:Concurrency Control 并发控制
用户常常会碰到几个SQL过来一下子就把实例的CPU打满的情况,或者是内存耗光等类似的情况。Concurrency Control并发控制这个功能,可以让用户根据实际使用情况,对SQL限制执行个数,以提高实例整体运行的稳定性。

6. 安全性:TDE支持国密SM4
企业级用户对于安全性的要求越来越高,对于各种各样的加密、密码强度、生命周期等要求也越来越多。AliSQL在安全这块做了更全面的支持,比如对于加密来讲,除了支持TDE这种AES的加密算法,还支持国密加密算法SM4,对于有涉密要求的用户可以用SM4的加密算法来保证数据的安全性。
7. 安全性:Recycle Bin防止误删除
当用户在做删除表或是Truncate表的时候,使用这个回收站功能,并不会把数据文件直接删除掉,而是会把这些表放到一个回收站里,这样就避免了用户在误删之后数据丢失的风险,误删除后还能通过回收站把删除的数据快速找回。
8. 安全性:Flashback Query
不仅是表级的误删除,当我们对某一些数据更新的范围错误了之后,使用Flashback机制,可以恢复到更新前的历史版本。同时,用户还可以自定义查询某个时间戳的某个数据。
所以Flashback Query对误操作删除恢复或是回档需求是很有效的方法。
9. 高性能:Binlog In Redo
对比原生MySQL,AliSQL的性能提升很多。首先介绍的是Binlog In Redo功能。众所周知,在MySQL里面,事务提交的时候需要持久化两次,因为要执行两阶段的事务提交过程。这里面做了一个改进,即可以把Binlog写到Redo里面,这样的话就只需要持久化一次Redolog,Binlog可以异步刷盘。
通过这种方式,用户事务在提交的时候就只需要一次刷盘动作,因此时延会降低,吞吐量会增大。
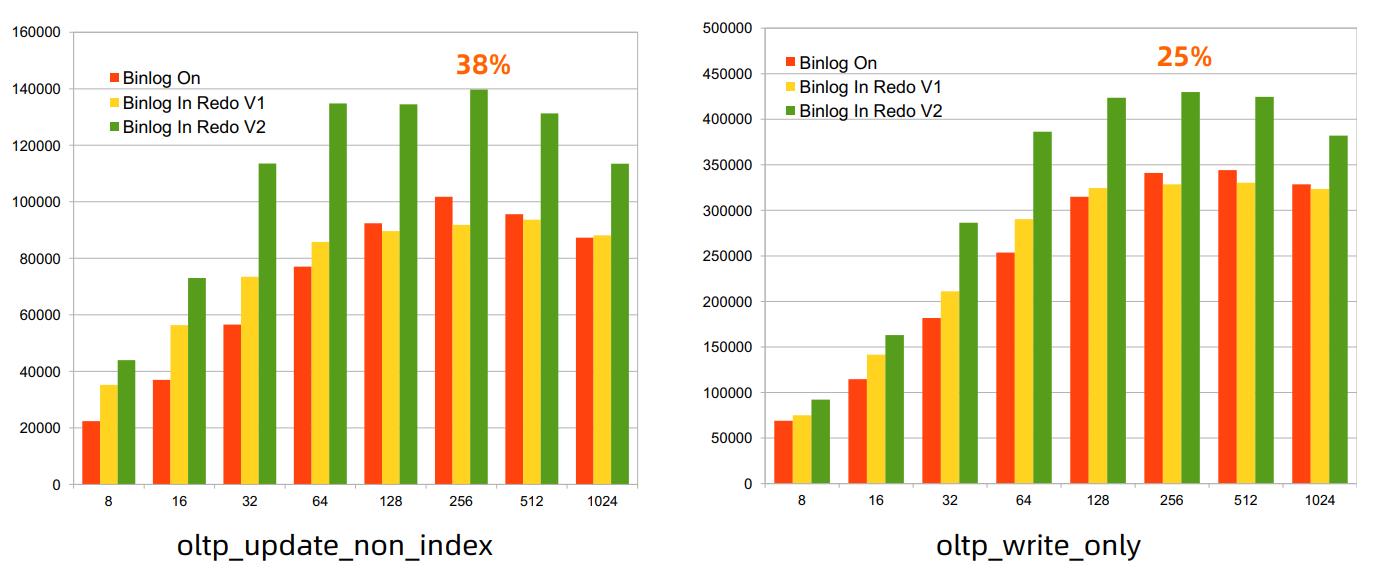
上图是基于两个Binlog in Redo版本的测试结果。通过左侧第二个版本的数据,我们发现性能会提高很多。对于Update non index来讲,可以有大概38%的性能提升。对于write only来讲,也可以达到25%的性能提升。
10. 高性能:Fast Query Cache
AliSQL针对Query Cache在并发控制、内存管理和缓存机制等等做了大量的优化。
优化之后,它的性能提升非常明显。在point select的场景下,性能提升甚至可以达到100%以上。通过测试发现,在rewrite模式命中率比较低的情况下,几乎没有任何性能损失。所以用户在读比较多的场景就可以把Query Cache打开,可以保持稳定高效的状态。
11. 高性能:DDL Optimization
围绕DDL我们做了大量优化。
用户在使用DDL的时候会发现,如果表特别大需要做rebuild或更新数据等操作的时候,效率非常低。主要是因为DDL利用Buffer Pool的模型是效率低下的模型。优化之后,对于rebuild表的这种操作效率会高很多,对于其他SQL语句的影响也会降低很多。
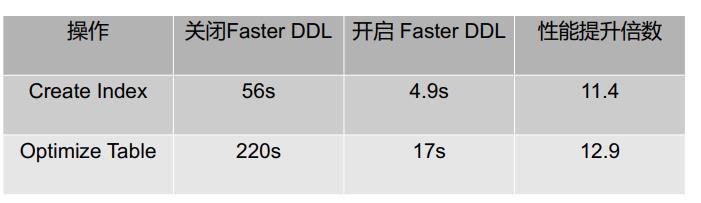
下图是针对Create Index和Optimize Table的测试,可以看到优化之后,操作都会有10倍以上的性能提升。
三、XA Crash Safe 介绍
1. XA Crash Safe背景
抛开XA Crash Safe本身,MySQL本身也有Crash Safe机制。为什么会需要这样的机制呢,因为在MySQL里,同时包括Binlog和数据两个部分,可以理解为存了两份一模一样的数据。为了保证这两份数据的一致性,MySQL Crash Safe实现了两阶段提交机制。为了保证Binlog和数据的一致性,任何用户的事务都会被转化成为两阶段的事务,首先就是进行prepare,然后再写Binlog并持久化,最后做事务的提交。所以在这两个阶段的提交过程中,Prepare、刷Redo、写Binlog和刷Binlog的执行顺序是保持不变的。
如何保证Crash Safe呢?这要看它恢复的处理过程。在实际的事务执行过程中,只要是Binlog有这个事务,一定是Prepare的状态。那么利用这个原则,在MySQL Crash重启的时候,它会取出所有已经prepare的事务,把它们的XID取出来,扫描最后一个Binlog文件,然后确认XID所对应的事务是否已经存储到Binlog里了。如果已经存储过了,就直接提交即可;如果还没有存储,就回滚掉。通过这个Crash Recovery机制后,Binlog里的数据就和引擎里面的数据保持一致了。
对于普通用户事务可以用两阶段来保证Crash Safe,那么对于用户的XA事务怎么处理呢?
在Binlog里会把这个事务分为独立的两部分,当用户执行XA Prepare的时候,会写Binlog文件,然后把这个Prepare状态执行到引擎里,这是完全独立的。用户在XA Commit里,可以在任何时间执行,当用户在执行XA Commit之后会被再记录一次Binlog,所以这两者是完全脱离的。
对于普通的用户事务,执行过程只记录一次Binlog,而且整个事务是一个基本的单元存在Binlog中的;对于XA事务,这就是分开的。而且它整个过程是先写Binlog,然后才去把状态持久化到引擎中,做引擎的prepare。对于MySQL来讲,不能保证外部XA事务数据和Binlog的一致性。
也就是说当写完Binlog,还没有在引擎中执行prepare和commit,这个时候就Crash了,那么它起来之后就变成,Binlog里有事务记录,而在引擎里却丢失了,也许只以prepare的状态停留在那里,这就没有被提交。
2. XA Crash Safe:基于MySQL 5.7的修复
1)调整执行顺序
为了更好的支持分布式数据库系统,在MySQL 5.7的时候,阿里就做过对于XA Crash Safe的修复。这个修复是把执行顺序做了颠倒,即先执行引擎的Prepare,再写Binlog,这样它就跟普通事务的过程一样了。在Prepare之后做Crash,如果用户的XA事务做了Prepare之后没有记Binlog,那么数据就会被回滚掉。但是由于XA事务跟普通事务不太一样,需要更多处理来支持回滚,而且它也不是一个完善的方案。因为用户具有多样性,比如用户执行了一个事务但是并没有记Binlog,这个时候就没法区分是否记录了Binlog。另外,XA事务的Prepare和Commit是分开的,当用户将Prepare事务记录到很久以前的Binlog里了,也不能区分用户是否记录了Binlog。
这种情况下就需要一个解决方案,即在做Binlog rotation时候,要把所有Prepare事务的XID记录到Binlog中。这样我们就可以通过最后一个Binlog去了解所有Prepare状态的XID,然后就可以通过Rollback的方式保持Binlog和数据的一致性。
2)调整Recovery逻辑
Commit执行了另外一种逻辑,即先执行Binlog,在执行后发现事务是Prepare状态,且在Binlog中记录了Commit或Rollback,那么执行Commit或Rollback。
这就是MySQL 5.7上XA Crash Safe的修复的过程。
3. XA Crash Safe:MySQL 8.0 Gtid和事务的一致性
MySQL 8.0采用了另外一种方法。介绍这个方法之前,首先介绍下MySQL 8.0 Gtid和事务的一致性。在MySQL8.0.17的时候,引入克隆功能,这个功能可以把Gtid记到事务的undo里。记到Undo里的过程也很简单,在Prepare的时候还是先记Binlog,然后引擎里做事务Prepare的时候,去监测这个事务是否有Gtid。如果有,在修改事务状态时会连通Gtid一起写到Undo里。如果Crash之后,Prepare丢了,那么Gtid一定也是不存在的,反之亦然。在Commit的时候也同理。这样做,克隆的时候用户使用起来就会非常简单。
但是Rollback是个特例,尤其是对于XA事务来说。Rollback也会记录一个Gtid。Rollback在引擎里的做法是,把事务状态改成active之后就会自然回滚,所以在active的时候它也会记一个Gtid,所以XA Rollback会记录Binlog也会产生Gtid。整个操作也是原子的。
Gtid最终会持久化到Gtid_executed表里。之所以要做汇总是因为Undo本身需要Purge,否则会越来越大,而且检索效率也非常低。所以虽然在Prepare后会放进Undo里,但是实际上最后都会汇总到Gti_executed表中,然后会有一个单独的Gtid Flush的线程,它会周期性的把Gtid list里的Gtid写到Gtid_executd表中。写到表后,只需要持续化整个表后,undo就可以丢掉了,这样始终会有一个完整的Gtid集合。
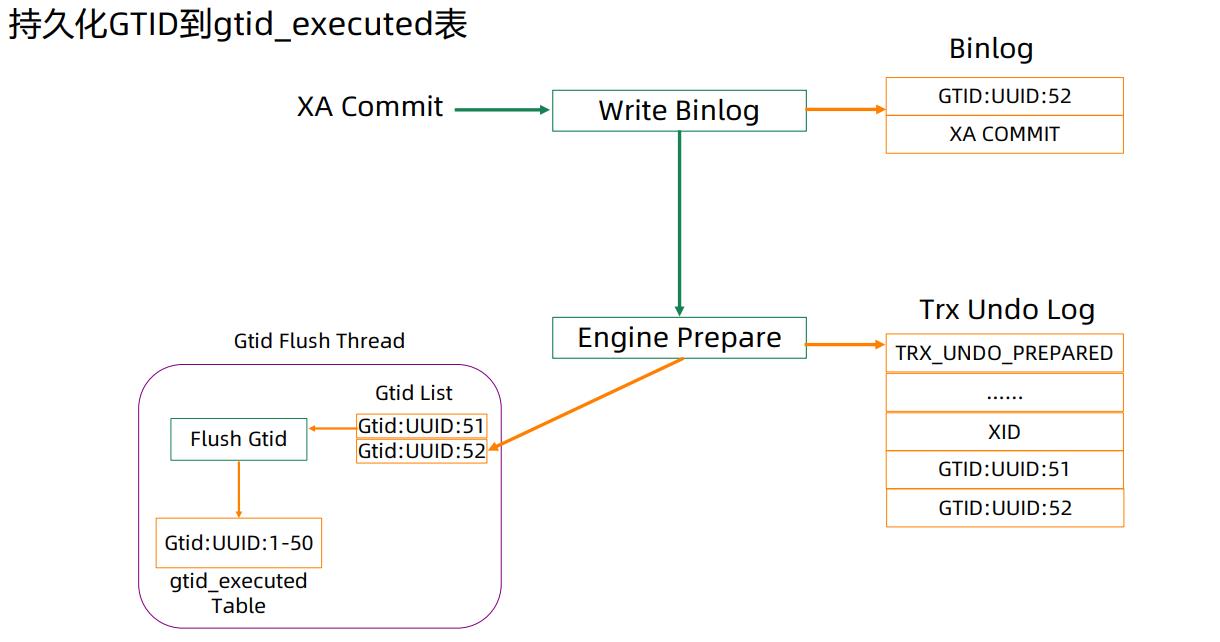
对于外部XA事务会记录两个Gtid,一个是Prepare的时候,一个是Commit的时候。最初实现这个功能的时候,只会记录一个Gtid,也就是说在commit的时候会把prepare的给覆盖了。这就要求,在Commit之前需要把Prepare的Gtid持久化到Gtid executed表里,效率非常低。后来官方优化成将两个Gtid分别存在两个位置,这就大大提高了效率。
经过以上的优化之后,我们可以看到Gtid和事务数据之间的关系,是Gtid Executed表中的Gtid代表了InnoDB中已经执行了的事务的Gtid。这两者之间是原子对应的关系。
通过这样的对应关系,我们可以在系统启动的时候做Apply Binlog这样的操作,来保证外部XA事务的Crash Safe。
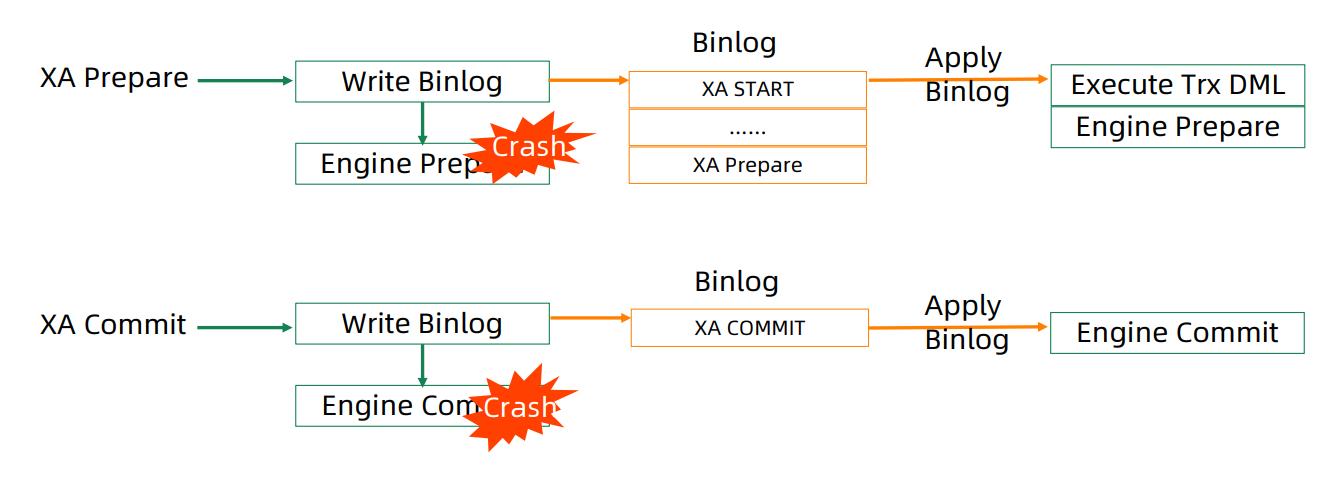
根据Gtid Executed表中的Gtid就可以知道哪些事务在引擎里存在,然后通重放Binlog里的事务将引擎里的数据补齐。通过这样的方式,不需要修改过添加Binlog Event,原来的recover过程也不需要变化。只需要在recover之后,检查Gtid Executed的表,然后对比Binlog。将缺少的事务重新Apply一下就可以了,这样就可以保证XA事务的Crash Safe。
原文链接
本文为阿里云原创内容,未经允许不得转载。
以上是关于阿里云RDS深度定制-XA Crash Safe的主要内容,如果未能解决你的问题,请参考以下文章