Python爬虫实战|爬取视频
Posted 向阳-Y.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫实战|爬取视频相关的知识,希望对你有一定的参考价值。
预备知识:快速入门Python爬虫|requests请求库|pyquery定位库
仅供技术交流,技术无罪,请勿拿来做坏事[doge]
1.发现网址url规律
分析目标网站,确定爬取的url路径,headers参数

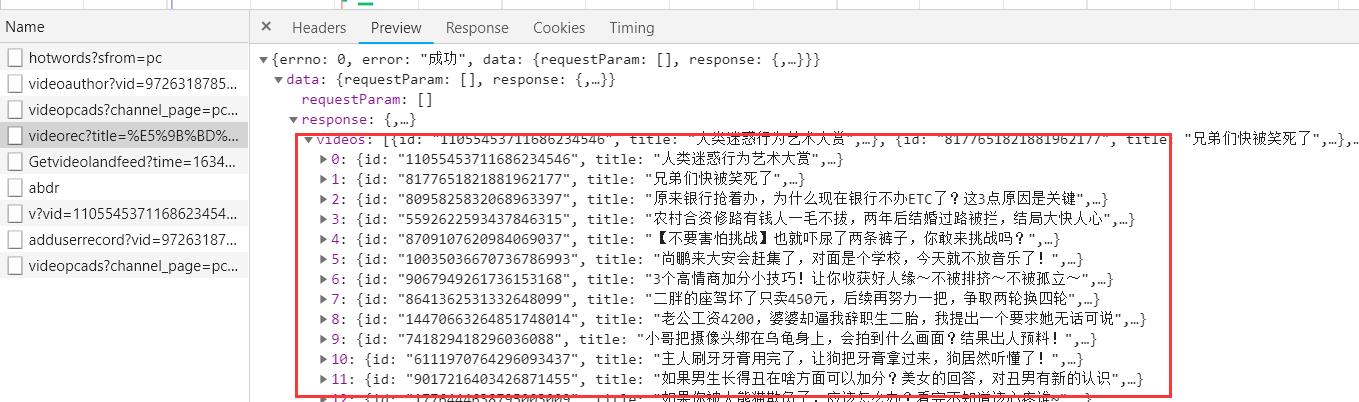
所以确定的url为下图:
url='https://haokan.baidu.com/videoui/api/videorec?title=%E5%9B%BD%E5%A4%96%E6%90%9E%E7%AC%91%E5%90%8D%E5%9C%BA%E9%9D%A2%E7%AC%91%E6%AD%BB&vid=9726318785549137226&act=pcRec&pd=pc'
headers={"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3877.400 QQBrowser/10.8.4506.400"}
2.拿到一个页面数据
resp=requests.get(url,headers=headers)
raw_json=resp.text
3.数据解析
#3.1数据转换
do=json.loads(raw_json)#转换为json数据
#3.2数据解析
data_list=do['data']['response']['videos']
for data in data_list:
#print(data)
video_title=data["title"]+".mp4"#视频文件名
video_url=data['play_url']#视频的url地址
print("视频名称为:{video_title}\\nURL地址为:{video_url}".format(video_title=video_title,video_url=video_url))
data_list=do['data']['response']['videos']上句意为,将代码一层层剥离
还可以继续剥离:data_list=do['data']['response']['videos'][0]['id'][0]

4.存储数据
将文件下载指本地位置
#再次发送请求
video_data=requests.get(video_url,headers=headers).content
with open('F:\\\\papapa\\\\video\\\\' + video_title,"wb")as f: #视频是二进制,所以需要用到wb写入方式
f.write(video_data)
.content获取二进制数据(如文件、图片、音视频)
5.大功告成
from pyquery import PyQuery
import requests
import json
#1分析目标网站,确定爬取的url路径,headers参数
url='https://haokan.baidu.com/videoui/api/videorec?title=%E5%9B%BD%E5%A4%96%E6%90%9E%E7%AC%91%E5%90%8D%E5%9C%BA%E9%9D%A2%E7%AC%91%E6%AD%BB&vid=9726318785549137226&act=pcRec&pd=pc'
headers={"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3877.400 QQBrowser/10.8.4506.400"}
#2发送请求,获取响应数据
resp=requests.get(url,headers=headers)
raw_json=resp.text
#comments=json.loads(raw_json[20:-2])['play_url']
#comments
#3解析数据
#3.1数据转换
do=json.loads(raw_json)
#3.2数据解析
data_list=do['data']['response']['videos']
for data in data_list:
#print(data)
video_title=data["title"]+".mp4"#视频文件名
video_url=data['play_url']#视频的url地址
#print("视频名称为:{video_title}\\nURL地址为:{video_url}".format(video_title=video_title,video_url=video_url))
#4保存数据
#再次发送请求
print("正在下载:",video_title)
video_data=requests.get(video_url,headers=headers)
with open('F:\\\\papapa\\\\video\\\\' + video_title,"wb")as f: #视频是二进制,所以需要用到wb写入方式
f.write(video_data.content)
print("下载完成!\\n")
保存数据的另一种写法:
a文件追加 b进制文件编写
with open(“F:\\papapa\\video\\{}.mp4”.format(video_title),“ab”)as f:
以上是关于Python爬虫实战|爬取视频的主要内容,如果未能解决你的问题,请参考以下文章