python Chrome + selenium自动化测试与python爬虫获取网页数据
Posted 皓月盈江
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python Chrome + selenium自动化测试与python爬虫获取网页数据相关的知识,希望对你有一定的参考价值。
一、使用Python+selenium+Chrome 报错:
selenium.common.exceptions.SessionNotCreatedException: Message: session not created: This version of ChromeDriver only supports Chrome version 78
说明,这个chrom驱动支持78版本
谷歌浏览器版本
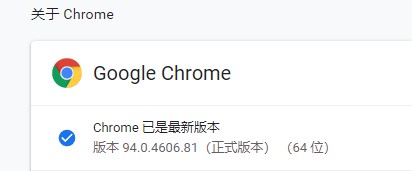
进入驱动网址:http://npm.taobao.org/mirrors/chromedriver/,下载对应版本的谷歌驱动
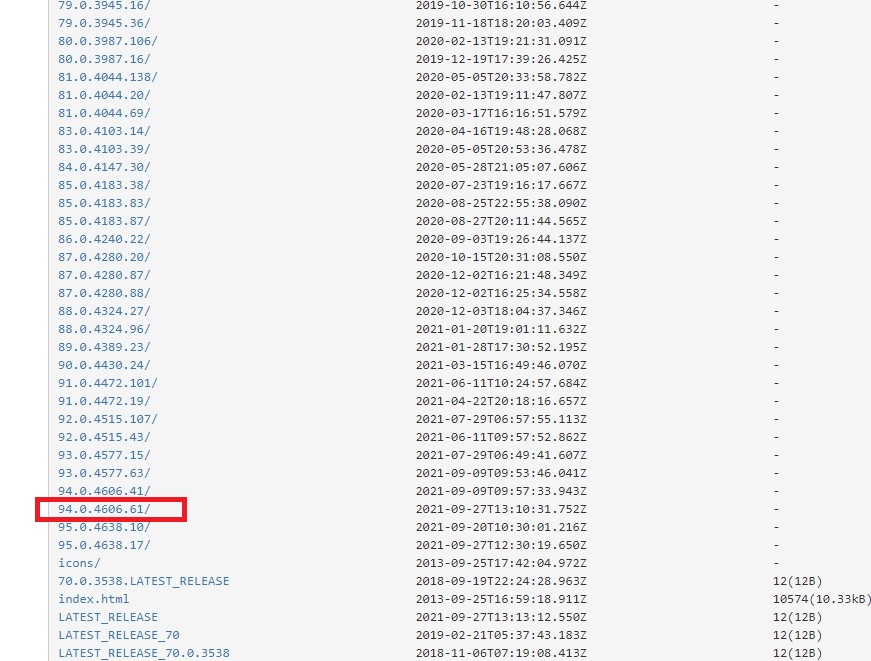
下载后放在与python解析器同一文件夹下面
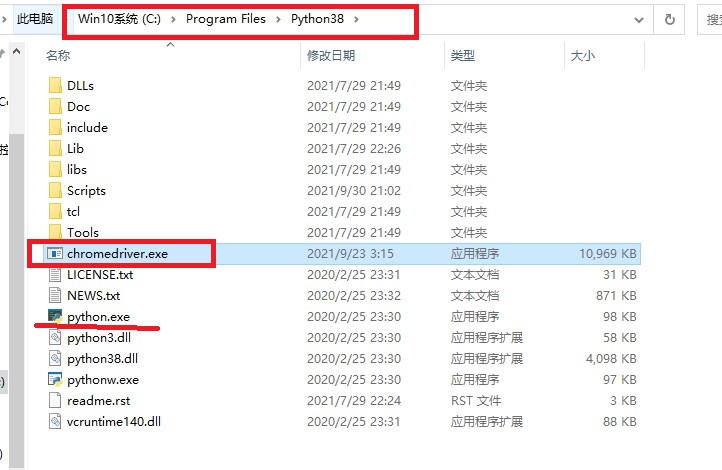
重新运行程序,运行成功!!!
二、实例测试:
使用python selenium自动化测试模块结合python爬虫获取网页数据。
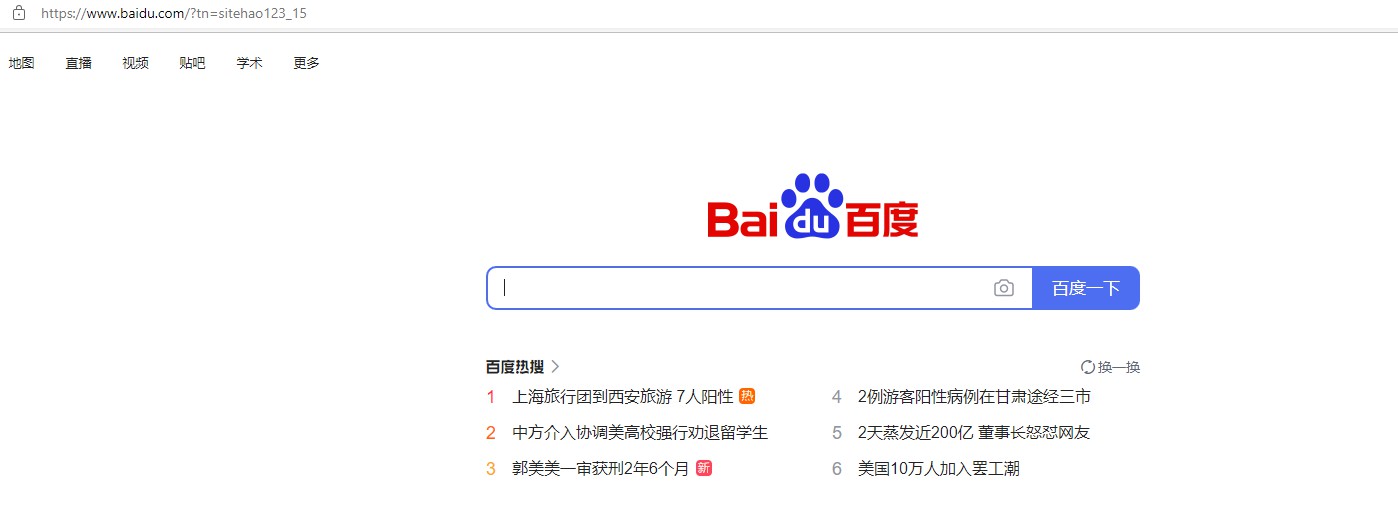
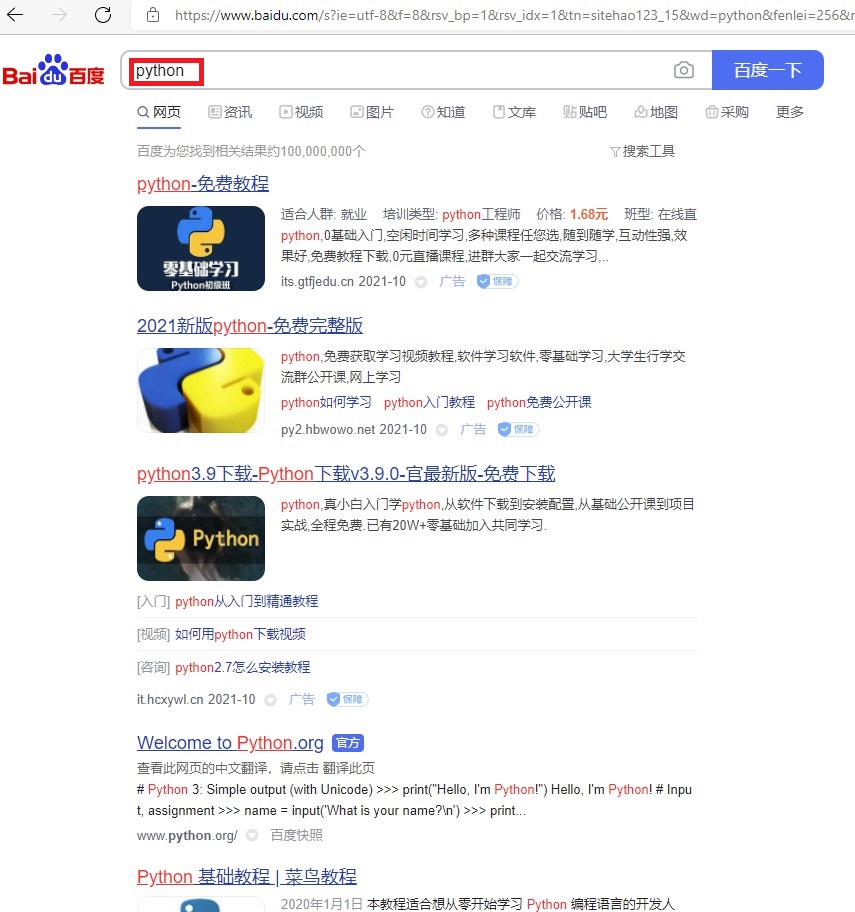
使用谷歌浏览器模拟打开https://www.hao123.com/网页,浏览器点击百度衔接,模拟输入python进行百度搜索,在关闭子网页,最后在https://www.hao123.com/网页获取精选新闻信息。
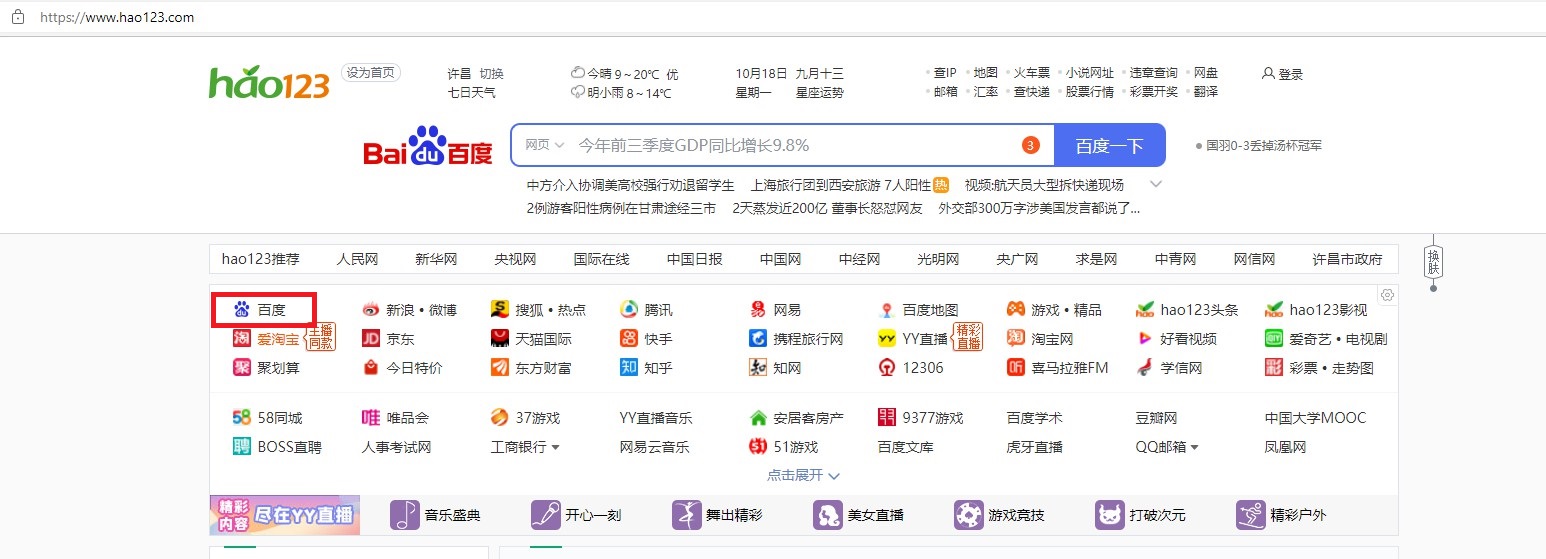
1.python控制谷歌浏览器
main.py
"""=== coding: UTF8 ==="""
from selenium.webdriver import Chrome
from selenium.webdriver.common.keys import Keys
import time
"""
========================================
主函数功能测试
========================================
"""
if __name__ == '__main__':
web = Chrome()
web.get("https://www.hao123.com/")
# 谷歌浏览器模拟人工点击“百度”衔接
web.find_element_by_xpath('//*[@id="userCommonSites"]/ul/li[1]/div/a').click()
time.sleep(1)
# 变更selenium窗口视角,切换到子窗口,-1代表在网页标签页最后一个网页
web.switch_to.window(web.window_handles[-1])
# 谷歌浏览器模拟人工输入“python”,进行百度搜索
web.find_element_by_xpath('//*[@id="kw"]').send_keys("python", Keys.ENTER)
time.sleep(1)
# 关闭子窗口
web.close()
# 变更selenium窗口视角,回到原来的窗口
web.switch_to.window(web.window_handles[-1])
# 提取精选新闻内容
a_list = web.find_elements_by_xpath('//*[@id="topzixun-over"]/div/div[2]/p')
for a in a_list:
print(a.find_element_by_xpath('./a[1]').text)
# 关闭窗口
web.close()
# 对于嵌入的视频窗口,切换到iframe窗口
# iframe = web.find_elements_by_xpath('......')
# web.switch_to.frame(iframe)
# 切换到原画面
# web.switch_to.default_content()
2.python使谷歌浏览器在后台运行,爬取数据(即无头浏览器)
main.py
"""=== coding: UTF8 ==="""
from selenium.webdriver import Chrome
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.options import Options
import time
"""
========================================
主函数功能测试
========================================
"""
if __name__ == '__main__':
# 准备好参数配置(使谷歌浏览器在后台运行,即无头浏览器)
opt = Options()
opt.add_argument("--headless")
opt.add_argument("--disbale-gpu")
# 把参数配置到谷歌浏览器中
web = Chrome(options=opt)
web.get("https://www.hao123.com/")
# 谷歌浏览器模拟人工点击“百度”衔接
web.find_element_by_xpath('//*[@id="userCommonSites"]/ul/li[1]/div/a').click()
time.sleep(1)
# 变更selenium窗口视角,切换到子窗口,-1代表在网页标签页最后一个网页
web.switch_to.window(web.window_handles[-1])
# 谷歌浏览器模拟人工输入“python”,进行百度搜索
web.find_element_by_xpath('//*[@id="kw"]').send_keys("python", Keys.ENTER)
time.sleep(1)
# 关闭子窗口
web.close()
# 变更selenium窗口视角,回到原来的窗口
web.switch_to.window(web.window_handles[-1])
# 提取精选新闻内容
a_list = web.find_elements_by_xpath('//*[@id="topzixun-over"]/div/div[2]/p')
for a in a_list:
print(a.find_element_by_xpath('./a[1]').text)
# 关闭窗口
web.close()
# 对于嵌入的视频窗口,切换到iframe窗口
# iframe = web.find_elements_by_xpath('......')
# web.switch_to.frame(iframe)
# 切换到原画面
# web.switch_to.default_content()
关注公众号,获取更多资料

以上是关于python Chrome + selenium自动化测试与python爬虫获取网页数据的主要内容,如果未能解决你的问题,请参考以下文章