前言
拥抱变化接手了 Kafka 平台,遂学习 0.10.0 线上版本的设计与实现。限于篇幅,本文不会逐行解析源码,而是从逻辑流程、设计模式、并发安全等方面学习各组件,笔记仅供个人 Review
一:准备
1.1 配置项
参考文档 #producerconfigs,部分配置间会相互影响,如下:
batch.size // 单个 batch 的最大字节数
linger.ms // 控制 batch 未满时最多再等多久才发出
buffer.memory // producer 消息缓冲区内存上限
max.block.ms // 决定缓冲区满后阻发送一条消息的流程较长,涉及到的组件很多,塞等待可用内存的最长时间
retries // 发送消息出现临时性错误时的最大重试次数(默认无限重试以实现 AtLeastOnce)
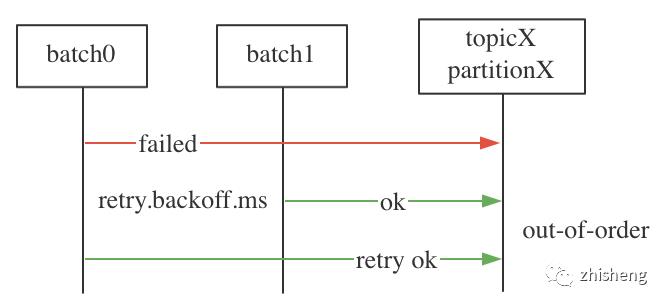
max.in.flight.requests.per.connection // 控制一条连接上能发送的在途请求数(默认 5),若不为 1 则在重试时可能导致消息乱序
|
乱序情况:
metadata.max.age.ms // 集群元信息的有效时长,超过则强制刷新
connections.max.idle.ms // 连接的最长闲置时间,超过则主动断开
max.block.ms // 应用层 send(), partitionFor() 的超时时间
request.timeout.ms // 网络层任何请求等待响应的超时时间
retry.backoff.ms, reconnect.backoff.ms // 重发消息、重连 broker 的定时规避周期
|
实现
producer 有 20+ 配置项,配置模块需对用户给定的Map<String, Object>, Properties等键值对象,进行配置值的类型检查、有效性检查、默认值填充等处理,得到有效配置。配置模块:
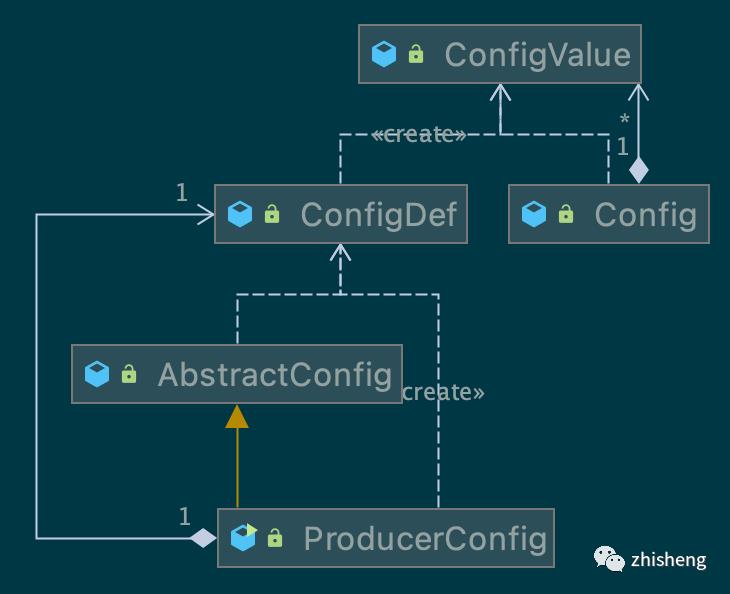
ConfigDef:记录用户原始配置、解析后的配置,并提供 util 方法按类型读取配置值,特别地,define 系列方法都返回 this 以实现链式调用,类似于 Builder 模式
ProducerConfig.CONFIG单例:静态常量,并在 static 代码块中定义,故在类加载阶段就会被初始化,是典型的单例模式应用,类似单例还有枚举实现的 protocol.ApiKeys,protocol.Errors 等等
Configurable接口规范类的反射构造行为:用户类(Partitioner, Serializer, Interceptor…)配置值都是字符串,反射实例化时构造方法可能无参或有参但类型不定,故抽象出Configurable接口,无参构造完成后接收配置值,进一步实例化
public <T> T getConfiguredInstance(String key, Class<T> t) {
Class<?> c = getClass(key);
Object o = Utils.newInstance(c); // 无参构造实例化
if (o instanceof Configurable)
((Configurable) o).configure(this.originals); // 完善构造
return t.cast(o);
}
|
1.2 预处理
如下 demo 展示了两种发送消息的方式
public class Main {
public static void main(String[] args) throws Exception {
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
ProducerRecord<String, String> record = new ProducerRecord<>("topic-01", "msg1");
Future<RecordMetadata> future = producer.send(record);
RecordMetadata meta = future.get(1, TimeUnit.SECONDS);
log.info("[invoke] send succeed, offset: {}", meta.offset());
producer.send(record, new UserCallback());
producer.flush();
}
static class UserCallback implements org.apache.kafka.clients.producer.Callback {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception == null) // 无异常,发送成功
log.info("[callback] send succeed, offset: {}", metadata.offset());
else // 发送失败
log.info("[callback] send failed, exception: {}", exception.getMessage());
}
}
}
// INFO [invoke] send succeed, offset: 12 (org.apache.kafka.clients.producer.Main:24)
// INFO [callback] send succeed, offset: 13 (org.apache.kafka.clients.producer.Main:34)
|
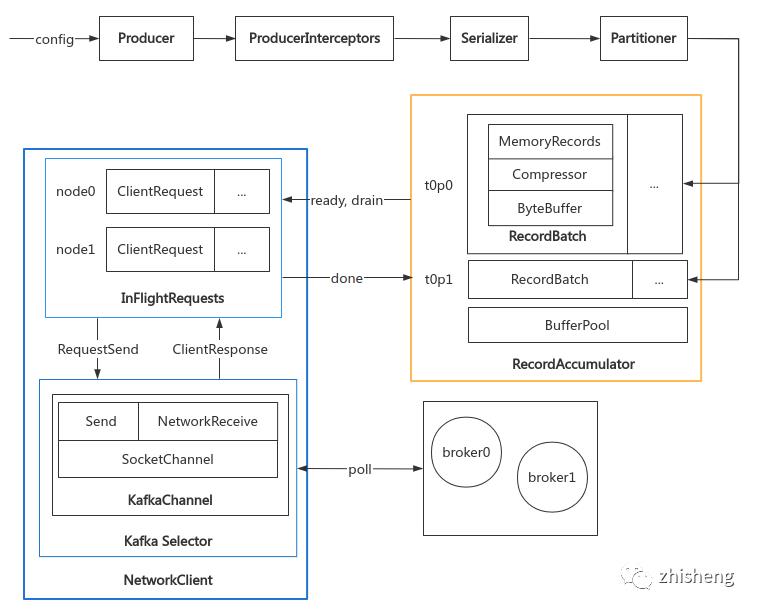
底层发送流程如下,之后章节将逐一解析各个组件:
1. ProducerInterceptors
用户类可线程安全地实现ProducerInterceptor接口(限制不能抛异常),用在
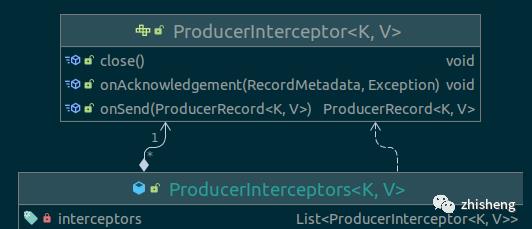
支持组合多个拦截器,批量链式调用,但不提倡,因为链式调用时若某个拦截器抛出 unchecked 异常,捕捉后仅记录日志不抛回 send 调用方,用户无法感知
public ProducerRecord<K, V> onSend(ProducerRecord<K, V> record) {
ProducerRecord<K, V> interceptRecord = record;
for (ProducerInterceptor<K, V> interceptor : this.interceptors) { // 有序遍历拦截器链,逐个拦截
try {
interceptRecord = interceptor.onSend(interceptRecord);
} catch (Exception e) {
// onSend 抛出运行时异常,只会打 warn 日志,本次拦截视为无效
// 如 A->B->C->D,若 C 拦截时抛异常,则 D 拿到的消息是 B 拦截后的,这种行为非预期
log.warn("Error executing interceptor onSend callback", e); // ...
}
}
return interceptRecord;
}
|
2. Serializer
发送消息的 Key 和 Value 统一用byte[]描述,实现二进制安全,故用户类需实现Serializer接口;serialization 模块已内置了基础数字类型、String 的序列化实现,consumer 反序列化 Deserializer 接口同理
public interface Serializer<T> extends Closeable {
public byte[] serialize(String topic, T data); /*...*/
}
|
3. Partitioner
用户实现Partitioner来决定每一条消息要发往哪个分区
public interface Partitioner extends Configurable {
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster);
}
|
默认分区器DefaultPartitioner选择分区的流程:
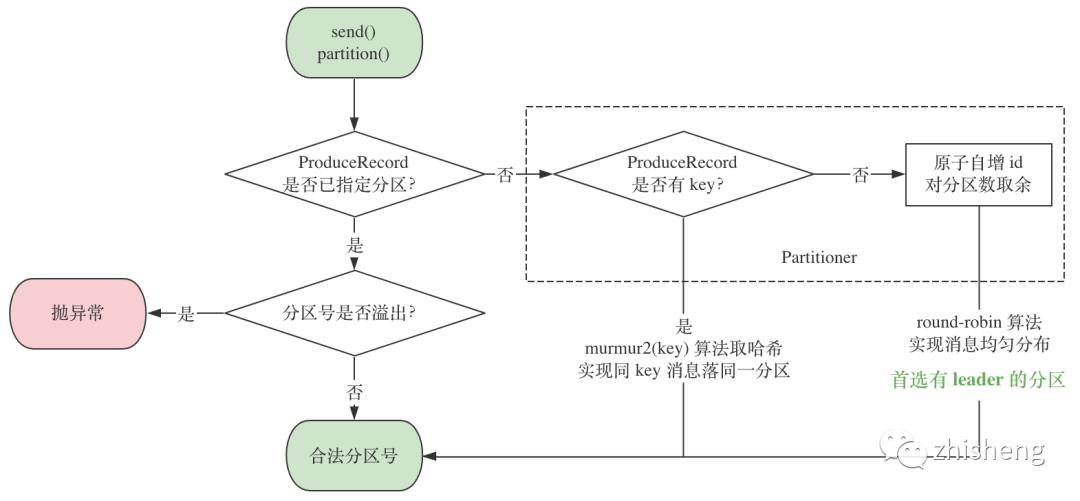
至此,分析了发送前消息的拦截修改、键值序列化、确定分区的逻辑
二:内存层
职责:内存池资源管理,消息压缩与 batch 分批,发送结果的异步计算
2.1 BufferPool
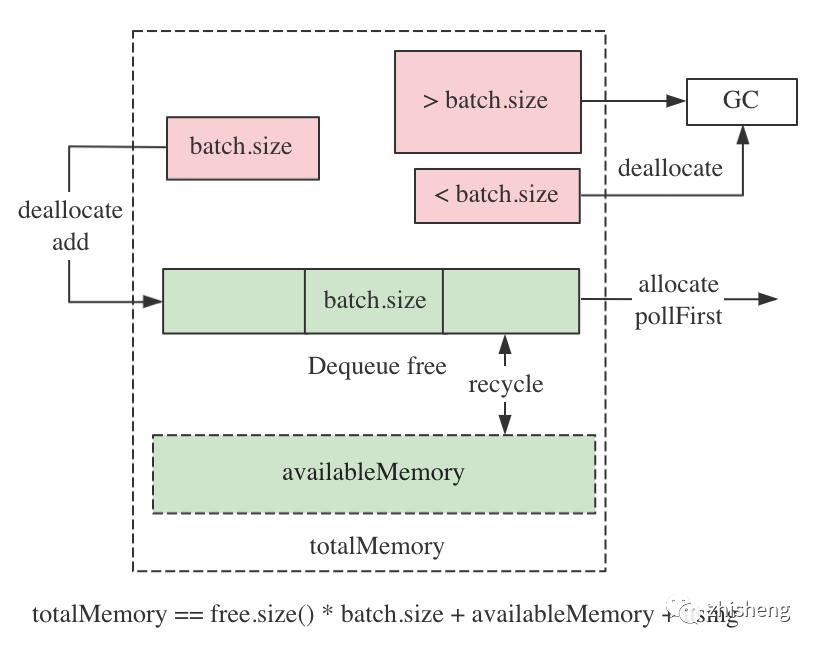
buffer.memory 配置限制了 producer 缓冲消息所能使用的最大内存,默认启用 batch 机制后,消息常以batch.size大小分批发送,故设计内存池重用 batch 内存
内存池划分为 3 个区域:
free 双端队列:元素为batch.size大小的内存块,消息发送成功后 clear 入队重用;有 2 个特性
不规整内存块:若 batch 被禁用,或发送大小在(batch.size, max.request.size]范围的大消息,会直接分配该大小的一次性 ByteBuffer,使用完毕后由 GC 回收
空闲内存:非内存块实体,只是统计值,在分配和释放不规整内存块时对应增减库存
内存不足时,调用send()的多个用户线程都会 await 阻塞在各自的条件变量上,内存池采用先到先得的策略,当有内存可用时只会 signal 唤醒入队最早、等待时间最长的线程,避免了线程饥饿或多线程低效竞争。示意图:
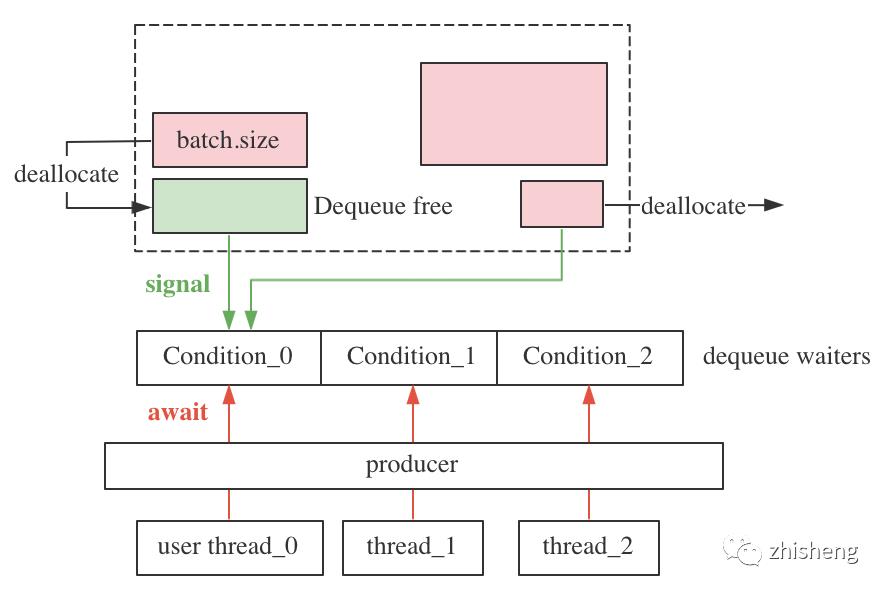
如上 thread_0 被唤醒后,会收集该可用内存,若内存已足够则恢复运行并唤醒 thread_1,否则继续等待
2.2 RecordBatch
消息批次用 RecordBatch 描述,维护消息重发、future 结果等元信息,消息实际存储在底层的 MemoryRecords 缓冲区,并使用 Compressor 进行压缩
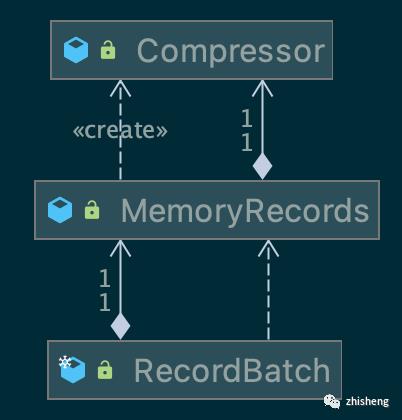
1. Compressor
1)类加载
producer 支持三种压缩方式:gzip, snappy 和 lz4,但只有 gzip 由 java.util.zip JDK 标准库实现,其他 2 种压缩类需添加 jar 包,在运行时反射加载,不使用时能减少包体积;同时为保证 producer 全局只会反射构造出一个 Constructor,用到了懒加载的 DCL 单例模式
2)封装 batch
每种算法都有预期压缩比,如 gzip 是 50%;在 MemoryRecords 视角,将 16KB batch 传给 Compressor 后,实际至多写入 32KB 数据,由于压缩比不精确,Compressor 要有动态扩容的能力,以容纳更多压缩消息;实现:
public class ByteBufferOutputStream extends OutputStream {
/*...*/
public void write(int b) {
if (buffer.remaining() < 1)
expandBuffer(buffer.capacity() + 1); // 内存不足,自动扩容
buffer.put((byte) b);
}
private void expandBuffer(int size) { // 容量增长 10%,或增长到 size 字节
int expandSize = Math.max((int) (buffer.capacity() * REALLOCATION_FACTOR), size);
ByteBuffer temp = ByteBuffer.allocate(expandSize);
temp.put(buffer.array(), buffer.arrayOffset(), buffer.position());
buffer = temp;
}
}
|
3)压缩实现
实现了两层装饰模式:为 ByteBuffer 装饰了自动扩容功能,为各种类型数据的 put 操作装饰了压缩写:
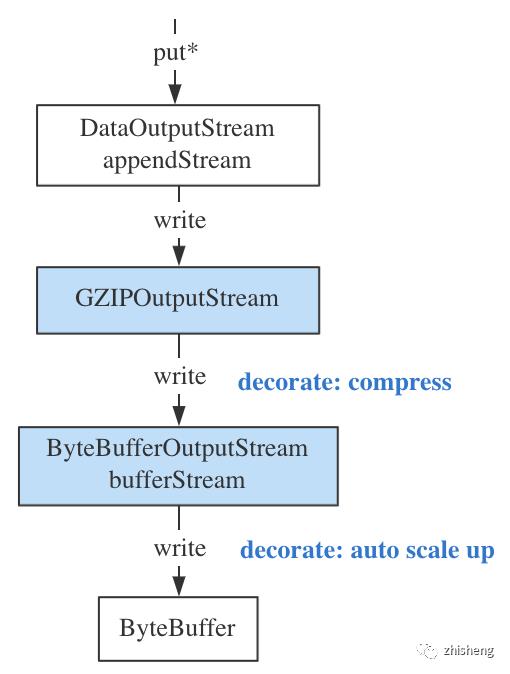
特别地,putRecord() 带压缩地写入一条消息,写入后的内存结构:

更正:magic number 为 1 时带 timestamp,为 0 则无 timestamp 字段
缓冲区写满后触发close(),Compressor 会倒回至 ByteBuffer 的初始位置,插入一条 Shadow Record 补全元数据,将其后所有压缩后的 Real Records 视为其 key 的值,内存结构:

TODO: 勘误画图,压缩后的 RealRecords 放的是 value 字段
注意,close() 方法中会动态调整压缩比,即压缩比是自适应的
4)写满判断
判断 MemoryRecords 是否已满,是通过估算 Compressor 压缩后字节数实现的,估算逻辑:
public class Compressor {
public long estimatedBytesWritten() {
if (type == CompressionType.NONE)
return bufferStream.buffer().position();
else // 有压缩,压缩后字节数 = 未压缩字节数 * 压缩比 * 误差因子
// 比如用 gzip 压缩 1MB 数据:1MB*0.5*1.05 = 537KB
return (long) (writtenUncompressed * TYPE_TO_RATE[type.id] * COMPRESSION_RATE_ESTIMATION_FACTOR);
}
}
public class MemoryRecords implements Records {
public boolean isFull() { // 估算压缩后的大小是否已超 Compressor 容量
return !this.writable || this.writeLimit <= this.compressor.estimatedBytesWritten();
}
}
|
2. MemoryRecords
负责委托 Compressor 追加写 Record,为其添加 LOG_OVERHEAD 头信息
public long append(long offset, long timestamp, byte[] key, byte[] value) {
if (!writable)
throw new IllegalStateException("Memory records is not writable");
int size = Record.recordSize(key, value);
compressor.putLong(offset); // 此 record 在 batch 中的相对偏移量
compressor.putInt(size); // 压缩前此 record 的大小
long crc = compressor.putRecord(timestamp, key, value);
compressor.recordWritten(size + Records.LOG_OVERHEAD);
return crc;
}
|
当缓冲区满后会切换为只读模式,等待 drain 选中发出
public void close() {
if (writable) {
compressor.close(); // 回填压缩元数据
this.buffer = compressor.buffer(); // compressor 持有的 ByteBuffer,可能已扩容,更新指向
this.buffer.flip(); // 切为读模式
writable = false;
}
}
|
基于以上 2 个组件,RecordBatch 实现了三个机制:
1)委托 MemoryRecords 追加写 Record,并将各 Record 的元数据 future 与 batch 写结果相关联
public FutureRecordMetadata tryAppend(long timestamp, byte[] key, byte[] value, Callback callback, long now) {
/*...*/
// 递增 offsetCounter,即递增 record 的 relative offset,追加写到 batch 中
long checksum = this.records.append(offsetCounter++, timestamp, key, value);
FutureRecordMetadata future = new FutureRecordMetadata(this.produceFuture, this.recordCount,
timestamp, checksum,
key == null ? -1 : key.length,
value == null ? -1 : value.length);
if (callback != null)
thunks.add(new Thunk(callback, future)); // 用户 callback 组合 record future 记为 thunk
return future;
}
|
2)batch 发送结束后,发送结果 baseOffset 和 exception 会被填充到 ProduceRequestResult,通知各 Record 的 FutureRecordMetadata,唤醒阻塞在 get() 调用上的用户线程:
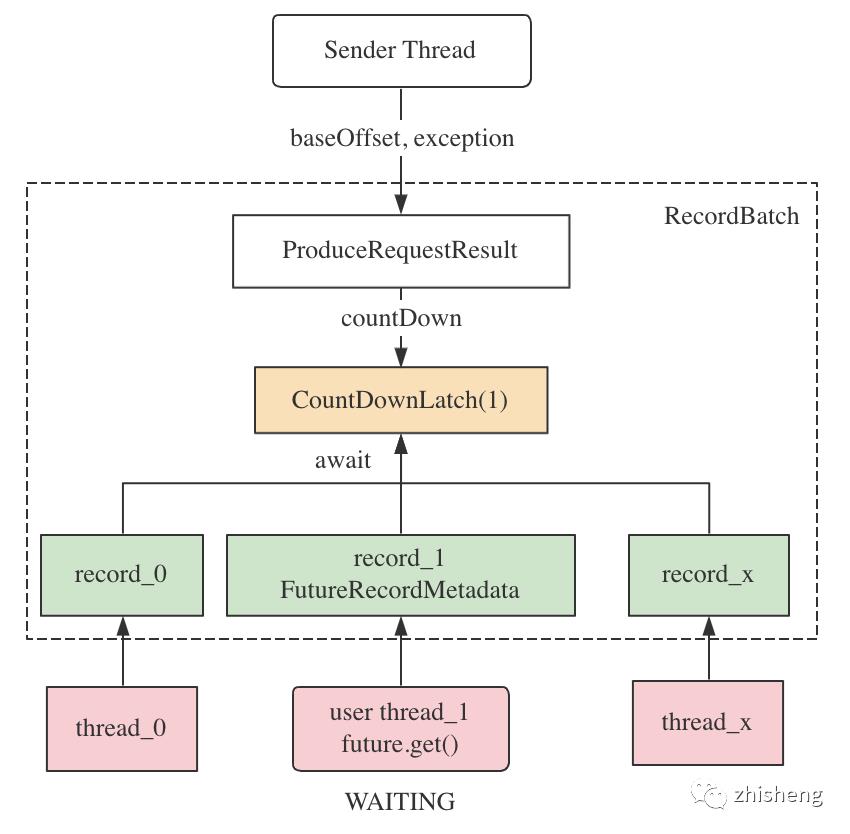
此处多线程需等待单线程执行结果,用 CountDownLatch 模拟实现了 Future 接口:
public final class ProduceRequestResult {
private final CountDownLatch latch = new CountDownLatch(1); // 模拟 future 异步通知与等待
public void done(TopicPartition topicPartition, long baseOffset, RuntimeException error) {
this.topicPartition = topicPartition;
this.baseOffset = baseOffset;
this.error = error;
this.latch.countDown(); // 发送完毕
}
public void await() throws InterruptedException {
latch.await();
}
}
public final class FutureRecordMetadata implements Future<RecordMetadata> {
private final ProduceRequestResult result; // 二者是组合关系
private final long relativeOffset;
@Override
public RecordMetadata get() throws InterruptedException, ExecutionException {
this.result.await(); // 阻塞等待 batch 发送完毕,会在 Sender.handleProduceResponse 中调用 done
// baseOffset + relativeOffset 即此消息在分区中的绝对 offset
return new RecordMetadata(result.topicPartition(), this.result.baseOffset(), this.relativeOffset, /*...*/);
}
}
|
3)维护 batch 的重发状态
2.3 RecordAccumulator
accumulator 维护各 topic partition(tp)的 batch 队列,结构如下:
public final class RecordAccumulator {
private final BufferPool free; // 内存池
private final ConcurrentMap<TopicPartition, Deque<RecordBatch>> batches; // 每个 topic 分区持有一个 RecordBatch 双端队列
}
|
producer 的 send 操作只将消息放入对应的 RecordBatch 中即返回:
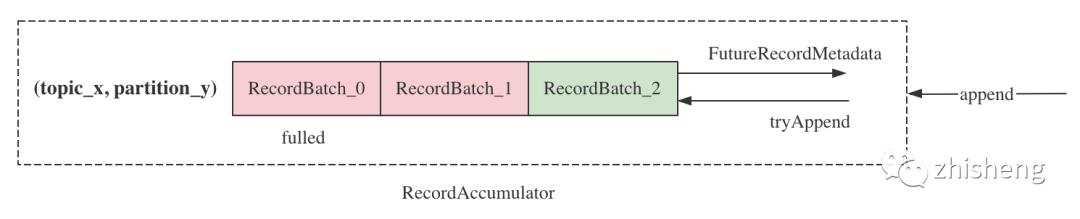
accumulator 还负责对各 tp 的 batch 队列进行 rollover,在实现上有两个优化亮点:
(1)细粒度锁,提高可用性:创建新 batch 时需阻塞申请内存,会主动放弃 dq 互斥锁。示意图:
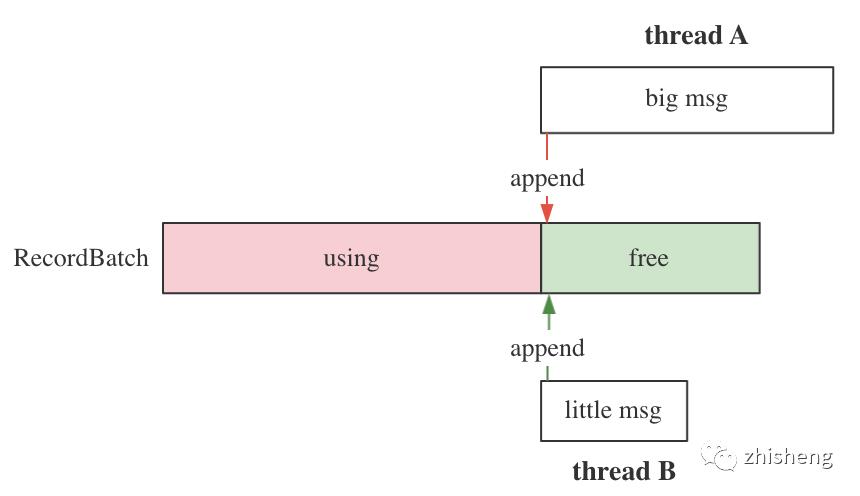
(2)解决并发 rollover 的内存碎片问题:细粒度锁的副作用是引入了新的并发竞争
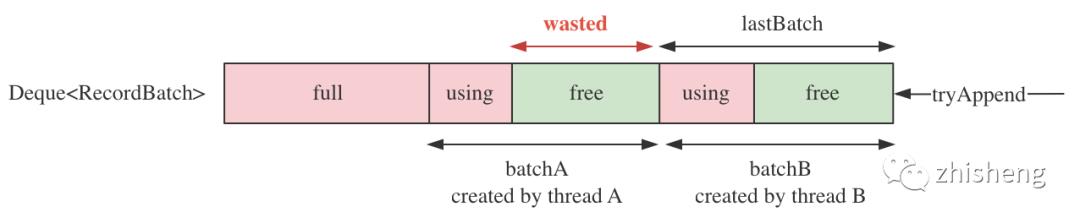
问题:A,B 同时发送大消息,都创建新 batch 后都入队,先入队的 batch 不再被使用,剩余内存将被浪费
解决:创建完新 batch 后不着急使用,先尝试写入 last batch,若写入成功则释放新 batch
缓存消息的实现:
public RecordAppendResult append(TopicPartition tp, long timestamp, byte[] key, byte[] value, Callback callback, long maxTimeToBlock) {
// 1. 获取 tp 的可用 batch
Deque<RecordBatch> dq = getOrCreateDeque(tp); // 获取或创建此 tp 的 batch 队列
synchronized (dq) { // batch deque 并非线程安全,整个队列加锁
RecordBatch last = dq.peekLast(); // 之前 batch 都已满,取最后一个 batch
if (last != null) {
FutureRecordMetadata future = last.tryAppend(timestamp, key, value, callback, time.milliseconds());
if (future != null) { // 写成功直接返回
return new RecordAppendResult(future, dq.size() > 1 || last.records.isFull(), false);
}
}
} // 放弃 dq 锁
// 2. tp 的 batch 队列为空,或现有 batch 都已满,阻塞申请内存创建新 batch
int size = Math.max(this.batchSize, Records.LOG_OVERHEAD + Record.recordSize(key, value));
ByteBuffer buffer = free.allocate(size, maxTimeToBlock);
synchronized (dq) { // 重新加锁
RecordBatch last = dq.peekLast(); // 重新尝试入队 last
if (last != null) {
FutureRecordMetadata future = last.tryAppend(timestamp, key, value, callback, time.milliseconds());
if (future != null) {
free.deallocate(buffer); // 使用 batchA,释放 batchB
return new RecordAppendResult(future, dq.size() > 1 || last.records.isFull(), false);
}
}
// 3. 构建新 batch 重新入队,肯定能写成功
MemoryRecords records = MemoryRecords.emptyRecords(buffer, compression, this.batchSize);
RecordBatch batch = new RecordBatch(tp, records, time.milliseconds());
FutureRecordMetadata future = Utils.notNull(batch.tryAppend(timestamp, key, value, callback, time.milliseconds()));
dq.addLast(batch); // 新 batch 入队
return new RecordAppendResult(future, dq.size() > 1 || batch.records.isFull(), true);
}
}
|
至此,分析了消息的内存分配、压缩写入、batch 读写模式切换、batch rollover 等机制
三:网络层
职责:维护连接状态,执行四种网络 IO 并收集结果
producer 网络层使用了 NIO Selector 机制,内部各组件关系如下,逐个分析
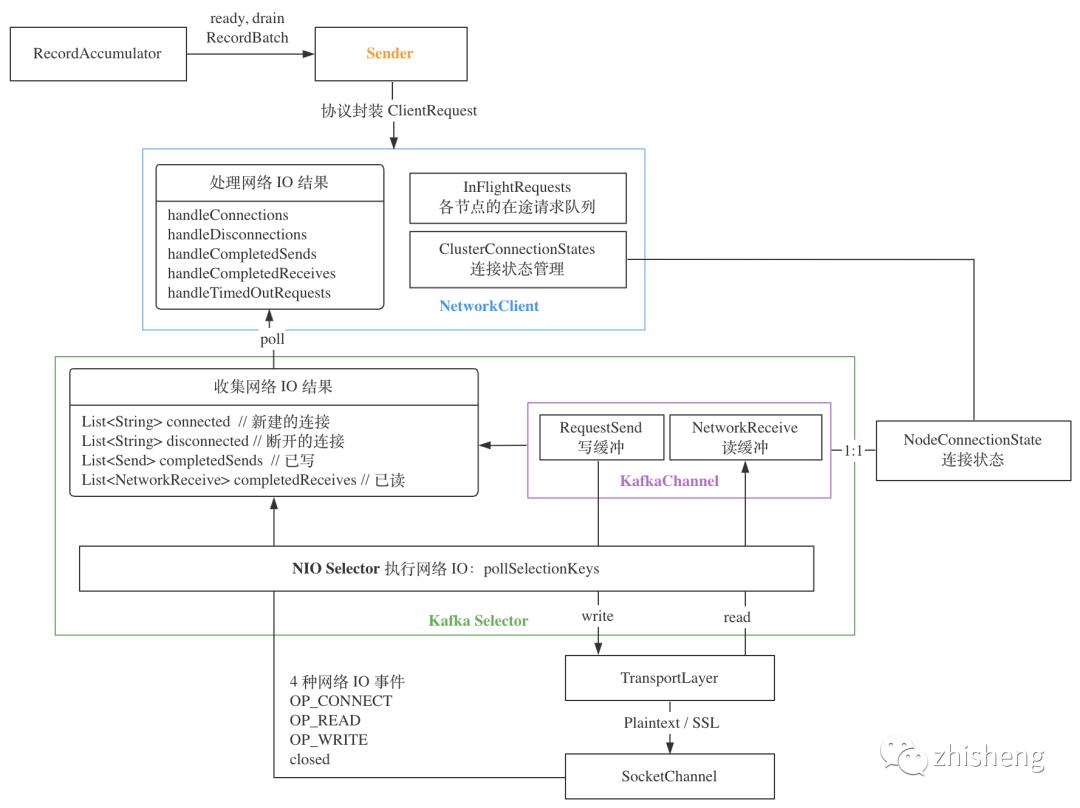
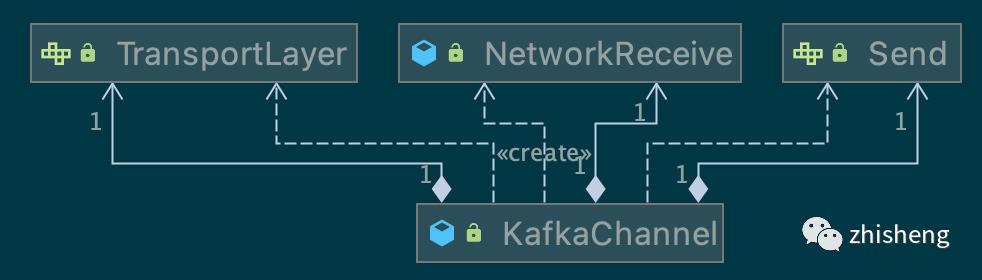
3.1 KafkaChannel
1. TransportLayer
封装 SocketChannel 的读写,提供注册事件的快捷方法
// 实现分割、聚合读写 ByteBuffer 的 Channel
interface TransportLayer extends ScatteringByteChannel, GatheringByteChannel{ /*...*/ }
public class PlaintextTransportLayer implements TransportLayer { // 明文传输层
private final SelectionKey key;
private final SocketChannel socketChannel;
@Override
public boolean finishConnect() throws IOException {
boolean connected = socketChannel.finishConnect(); // 等待连接建立,并自动注册 OP_READ 事件
if (connected)
key.interestOps(key.interestOps() & ~SelectionKey.OP_CONNECT | SelectionKey.OP_READ);
return connected;
}
@Override
public int read(ByteBuffer dst) throws IOException {
return socketChannel.read(dst); // 读写操作都被直接委托给了底层的 SocketChannel
}
public int write(ByteBuffer src) throws IOException {
return socketChannel.write(src);
}
@Override
public void addInterestOps(int ops) {
key.interestOps(key.interestOps() | ops); // 注册新事件
}
/*...*/
} /* TODO: SslTransportLayer */
|
2. 读写缓冲区
KafkaChannel 只维护一个读缓冲、一个写缓冲,并提供对应的read, write方法读写 TransportLayer
3.2 KafkaSelector
在 NIO Selector 上封装了网络 IO 的单次执行 4 种结果,对应了 4 种 IO 事件:
List<String> connected; // OP_CONNECT // 新建连接的 broker id 列表
List<String> disconnected; // closed, error // 断开连接的 broker id 列表
List<NetworkReceive> completedReceives; // OP_READ // 读取到的响应数据
List<Send> completedSends; // OP_WRITE // 已写出的请求数据
|
执行网络 IO:
public void poll(long timeout) throws IOException {
clear(); // 清理上次 poll 的结果
int readyKeys = select(timeout); // 等待网络 IO
if (readyKeys > 0)
pollSelectionKeys(this.nioselector.selectedKeys(), false);
addToCompletedReceives();
}
private void pollSelectionKeys(Iterable<SelectionKey> selectionKeys, boolean isImmediatelyConnected) {
Iterator<SelectionKey> iterator = selectionKeys.iterator();
while (iterator.hasNext()) {
SelectionKey key = iterator.next(); // 逐个处理 selectionKey
iterator.remove();
KafkaChannel channel = channel(key); // 取出 attach 的 kafkaChannel
try {
// 1. 处理 OP_CONNECT
if (isImmediatelyConnected || key.isConnectable()) {
if (channel.finishConnect()) // 连接成功,注册 OP_READ
this.connected.add(channel.id()); // 1. 收集新连接
else
continue; // 连接未完成,后续不必再处理
}
// 2. 处理 OP_READ
if (channel.ready() && key.isReadable() && !hasStagedReceive(channel)) {
NetworkReceive networkReceive;
while ((networkReceive = channel.read()) != null)
addToStagedReceives(channel, networkReceive); // 2. 收集一个完整的 Receive 响应
}
// 3. 处理 OP_WRITE
if (channel.ready() && key.isWritable()) {
Send send = channel.write(); // 写出 send 缓冲
if (send != null)
this.completedSends.add(send); // 3. 收集写成功的 Send 请求
}
// 4. 处理 closed
if (!key.isValid()) {
close(channel);
this.disconnected.add(channel.id()); // 4. 收集不可用连接
}
} catch (Exception e) {
close(channel);
this.disconnected.add(channel.id()); // 有异常视为连接不可用
}
}
}
|
结果收集完毕后,通过 List<Send> completedSends()等多个对应方法暴露给上层的 NetworkClient
3.3 NetworkClient
负责统一网络 IO 结果并解析响应,维护发往各个节点的有序请求队列,维护与各节点单一连接的状态;持有 2 个子组件:
(1)ClusterConnectionStates:连接状态管理
client 与每个 broker 都只会保持一条 TCP 连接,而非维护一个连接池,以简化消息有序性的实现。连接有三种状态,并由NodeConnectionState维护重连信息,由ClusterConnectionStates持有整个集群的连接状态
final class ClusterConnectionStates {
private final long reconnectBackoffMs;
private final Map<String, NodeConnectionState> nodeState;
/* ... */
private static class NodeConnectionState {
ConnectionState state;
long lastConnectAttemptMs;
}
}
public enum ConnectionState {
DISCONNECTED, CONNECTING, CONNECTED
}
|
(2)InFlightRequests:各节点的有序请求队列
client 发往各节点的请求都会对应入队 InFlightRequests 暂存,以实现三个功能:
有序收发:收到响应的顺序,必须与发出请求的顺序保持一致
请求超时检测:发出的请求在request.timeout.ms时限仍未收到响应,向用户返回连接异常
请求数限制:限制单个节点(连接)并发请求数,不超过max.in.flight.requests.per.connection配置,配置设为 1 以实现消息的绝对有序性
final class InFlightRequests {
private final int maxInFlightRequestsPerConnection;
private final Map<String, Deque<ClientRequest>> requests = new HashMap<String, Deque<ClientRequest>>();
// 是否限制 node 发送新请求
public boolean canSendMore(String node) {
Deque<ClientRequest> queue = requests.get(node);
return queue == null || queue.isEmpty() || // 1. 未发出任何请求
// 2. 上一个请求必须已完成 write,否则网络可能不可用,上一个请求还在该 channel 的 send 缓冲区中,不能强行覆盖
(queue.peekFirst().request().completed()
// 3. 同时在途请求数不能超过配置
&& queue.size() < this.maxInFlightRequestsPerConnection);
}
// 筛出出有超时请求的节点列表
public List<String> getNodesWithTimedOutRequests(long now, int requestTimeout) {
List<String> nodeIds = new LinkedList<String>();
for (String nodeId : requests.keySet()) {
if (inFlightRequestCount(nodeId) > 0) {
ClientRequest request = requests.get(nodeId).peekLast(); // 最早入队的 request
long timeSinceSend = now - request.sendTimeMs();
if (timeSinceSend > requestTimeout) // 超过 request.timeout.ms 都还未处理完,视为超时
nodeIds.add(nodeId);
}
}
return nodeIds;
}
}
|
此外,还负责读取网络 IO 结果,执行协议解析并汇总成 Response pipeline,逐个调用 protocol handler:
public List<ClientResponse> poll(long timeout, long now) {
long metadataTimeout = metadataUpdater.maybeUpdate(now); // 若有必要,发起额外的 MetadataRequest 请求
this.selector.poll(Utils.min(timeout, metadataTimeout, requestTimeoutMs)); // min timeout 保证各种超时事件能被及时执行
List<ClientResponse> responses = new ArrayList<>();
// 1. 处理 acks=0 的请求:对于发送成功的 send,若 acks=0 不需要等待响应,构造空 response 并收集
handleCompletedSends(responses, updatedNow);
// 2. 解析响应:用对应版本的协议,去解析 receive 响应数据,填充到 Struct 后入队 responses
handleCompletedReceives(responses, updatedNow);
// 3. 处理连接断开:已断开连接节点的 in-flights 请求,构造 disconnect response
handleDisconnections(responses, updatedNow);
// 4. 处理新建连接
handleConnections();
// 5. 处理请求超时:超时节点被视为不可用,同样为 in-flights 队列重的请求,构造 disconnect response
// 连接断开是网络异常,请求超时是网络延迟,都视为节点不可用,连接都会被置为 DISCONNECTED 等待重连
handleTimedOutRequests(responses, updatedNow);
// 处理本轮 IO 结果,调用 request 的 callback handler
for (ClientResponse response : responses) {
if (response.request().hasCallback())
// 如 Produce 请求会执行 RequestCompletionHandler.handleProduceResponse
response.request().callback().onComplete(response);
}
return responses;
}
|
至此,分析了底层 SocketChannel 的读缓冲拆包、写缓冲封包,中间层 NIO Selector 四种网络 IO 事件的处理及单次结果收集,上层 NetworkClient 维护连接状态及 IO 结果处理等机制
四:数据处理层
职责:筛选出待发送的 batch,构造请求,处理发送结果,重发消息,维护集群元数据
4.1 通信协议
(1)协议描述
参考文档#The_Messages_Produce,以 Produce v0 请求为例,协议的字段分布如下:
acks => INT16
timeout_ms => INT32
[ topic_name => STRING # [] 表示数组
topic_data => [
partition_index => INT32
record_set => BYTES # 压缩后的 batch 队列数据
]
]
|
可见协议是由类型不一的字段组合嵌套而成,protocol 模块用Type类描述字段类型,Field类描述字段本身,Schema类描述协议字段集,Struct描述协议及对应数据:
public class Field {
public final String name; // 字段名
public final Type type; // 可序列化的字段类型
}
public abstract class Type {
public abstract void write(ByteBuffer buffer, Object o); // 每种数据类型都需实现的读写方法
public abstract Object read(ByteBuffer buffer); // 即完成数据的序列化、反序列化
public static final Type INT32 = new Type() {/*...*/} // 基本类型、String、ByteBuffer 对应的协议类型
public static final Type BYTES = new Type() {/*...*/}
}
public class Schema extends Type {
private final Field[] fields; // 协议的字段集
private final Map<String, Field> fieldsByName;
}
public class Struct {
private final Schema schema;
private final Object[] values; // 协议对应的数据
}
|
由上可知 Produce v0 请求可被描述为:
public static final Schema TOPIC_PRODUCE_DATA_V0
= new Schema(new Field("topic", STRING),
new Field("data", new ArrayOf(new Schema(new Field("partition", INT32),
new Field("record_set", BYTES)))));
public static final Schema TOPIC_PRODUCE_DATA_V0
= new Schema(new Field("acks", INT16),
new Field("timeout", INT32),
new Field("topic_data", new ArrayOf(TOPIC_PRODUCE_DATA_V0)));
|
(2)统一协议头
client 发出的每个请求都会带上 header,标识此请求的版本、类型、自增 id,描述如下:
public static final Schema REQUEST_HEADER
= new Schema(new Field("api_key", INT16), // 请求类型,比如 Metadata 类型为 3
new Field("api_version", INT16), // 协议版本号,如 v2 版本值为 2
new Field("correlation_id", INT32), // 请求的自增唯一 id,broker 会原样返回,用于校验响应
new Field("client_id", NULLABLE_STRING));
public enum ApiKeys {
PRODUCE(0, "Produce"),
METADATA(3, "Metadata"), /* ... */
}
|
4.2 Metadata
(1)元信息
producer 需知道各 topic 的分区分布、各分区的 leader broker 地址,此类元信息由 Cluster 类描述:
public class Node { // broker 由 Node 描述
private final int id;
private final String idString;
private final String host;
private final int port;
}
public class PartitionInfo {
private final String topic; // TopicPartition: Topic, Partition
private final int partition;
private final Node leader;
}
public final class Cluster {
private final List<Node> nodes;
private final Map<Integer, Node> nodesById; // nodeId -> node
private final Map<Integer, List<PartitionInfo>> partitionsByNode; // leaderNode -> [partInfo, ...]
private final Map<TopicPartition, PartitionInfo> partitionsByTopicPartition; // tp -> partInfo
private final Map<String, List<PartitionInfo>> partitionsByTopic; // topic -> [all tp]
private final Map<String, List<PartitionInfo>> availablePartitionsByTopic; // topic -> [有 leader 的 tp]
}
|
类比 String,Cluster 类及其字段都是 final 只读,被修改时返回新实例,以保证 Sender 线程写、Producer 主线程读不存在并发问题。加上版本号分辨元信息的新旧,同时维护重试状态,由 Metadata 类描述:
public final class Metadata {
private int version; // 版本号标识 Cluster 的新旧
private Cluster cluster;
private long lastRefreshMs; // 上次更新时间戳,用于重试 backoff 等待
private long lastSuccessfulRefreshMs; // 上次成功更新的时间戳
private boolean needUpdate; // 是否需要强制更新
}
/* 各种 synchronized 读写方法*/
|
(2)更新时机
NetworkClient 内部有一个持有 Metadata 的 DefaultMetadataUpdater 类,负责发起 MetadataRequest 更新请求并解析响应。client 每次执行 poll 前,都会先检查是否需要更新 Metadata,由于更新操作会阻塞主线程,故触发条件较为苛刻,有两层筛选:
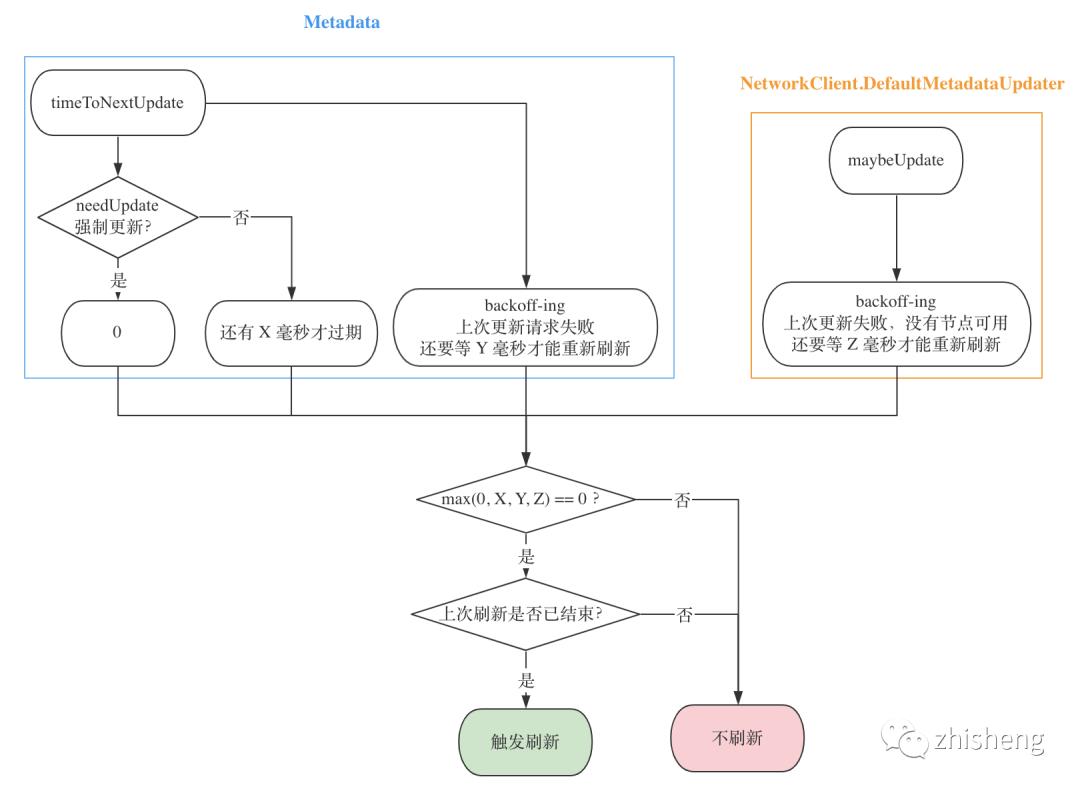
(3)更新实现
Metadata 由 Sender 线程写,而多个 Producer 线程读,是典型的线程间通信场景,故使用同一个 Sender.metadata对象的wait & notifyAll实现
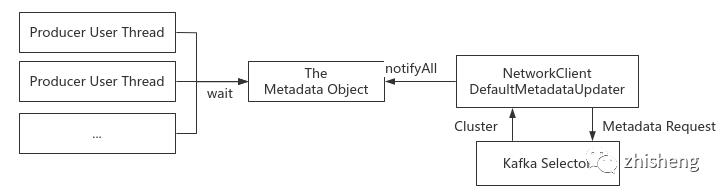
实现:
public class KafkaProducer<K, V> implements Producer<K, V> {
private long waitOnMetadata(String topic, long maxWaitMs) throws InterruptedException {
/* ... */
while (metadata.fetch().partitionsForTopic(topic) == null) { // 带超时地等待该 topic 元数据可用
int version = metadata.requestUpdate(); // 请求更新
sender.wakeup(); // 唤醒 selector,触发 NetworkClient 执行 poll
metadata.awaitUpdate(version, remainingWaitMs); // 等待 Sender 线程更新完毕调用 notifyAll
}
}
}
public final class Metadata {
public synchronized void awaitUpdate(final int lastVersion, final long maxWaitMs) throws InterruptedException {
while (this.version <= lastVersion) {
if (remainingWaitMs != 0)
wait(remainingWaitMs);
/*...*/
}
}
public synchronized void update(Cluster cluster, long now) {
this.version += 1;
this.cluster = cluster;
notifyAll();
}
}
public class NetworkClient implements KafkaClient {
class DefaultMetadataUpdater implements MetadataUpdater {
private final Metadata metadata;
/*...*/ // 找出 in-flights 请求数最少的节点,发起 Metadata 请求
private void handleResponse(RequestHeader header, Struct body, long now) {
MetadataResponse response = new MetadataResponse(body);
Cluster cluster = response.cluster(); // 解析响应读取元信息
this.metadata.update(cluster, now); // 通知 Producer 线程
}
}
}
|
4.3 Sender
(1)筛选各 node 需要发出的 batch 队列
Sender 线程在读写网络层之前,会根据 accumlator 排队时间、网络状态等条件,筛选出最紧急、最可能发送成功的 batch 集合,核心实现:
public class Sender implements Runnable {
void run(long now) {
// 1. 读取缓存的集群元信息
Cluster cluster = metadata.fetch();
// 2. accumulator: 筛选出有 topic 分区 batch 要发的节点集合
RecordAccumulator.ReadyCheckResult result = this.accumulator.ready(cluster, now);
// 3. kafkaClient: 筛掉出符合网络 IO 条件的节点集合
Iterator<Node> iter = result.readyNodes.iterator();
while (iter.hasNext())
/*...*/ // 过滤非 CONNECTED 连接
// 4. accumulator:受限于请求大小上限,为各 node 收集其负责读写的各 tp 上的等待时间最长 batch
Map<Integer, List<RecordBatch>> batches = this.accumulator.drain(cluster, result.readyNodes, this.maxRequestSize, now);
// 5. 检测已超时的 batch
this.accumulator.abortExpiredBatches(this.requestTimeout, now);
// 6. 将 batch 队列对于封装为 ClientRequest 队列
List<ClientRequest> requests = createProduceRequests(batches, now);
for (ClientRequest request : requests)
client.send(request, now); // 发送
// 7. 发送请求,读取响应
this.client.poll(pollTimeout, now); // pollTimeout 计算取了节点重连,lingerMs 到期等时间最小值
}
}
|
如上有两个核心筛选条件
ready():根据各 tp 的 batch 队列缓存情况,筛选出有 batch 要发送的 node 集合
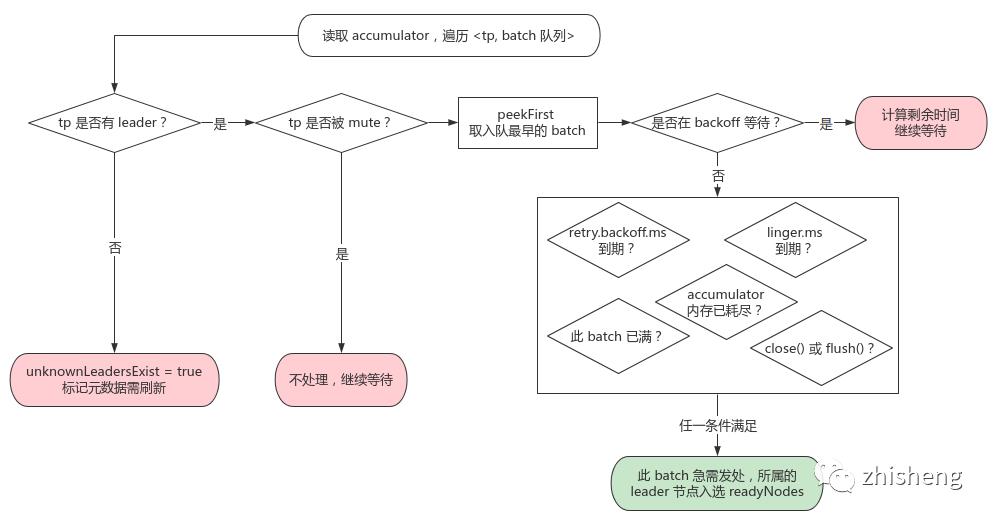
drain():每个 node 需发送多个 tp batch 队列中的最老 batch,但由于单个请求大小有max.request.size上限,为避免分区饥饿(有的分区迟迟不被选中导致 batch 超时),会从随机的 tp 开始收集 batch;若 max.request.size 较大,还会继续收集各个 tp 等待时间第二长的 batch,设计十分巧妙!
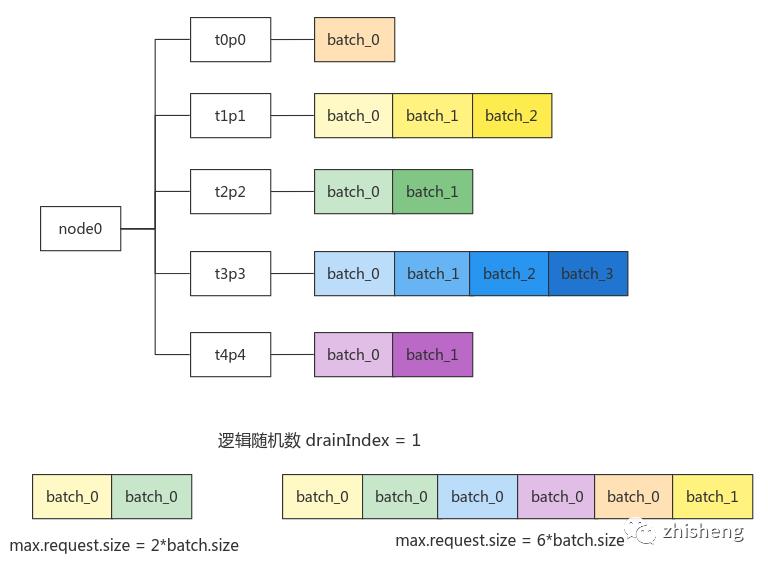
(2)协议封装
第一步为各 node 都筛选出了要发送的 batch 队列,还需进一步封装为 ClientRequest:
// 为各 node 构建 ClientRequest 网络请求
private ClientRequest produceRequest(long now, int destination, short acks, int timeout, List<RecordBatch> batches) {
Map<TopicPartition, ByteBuffer> produceRecordsByPartition = new HashMap<TopicPartition, ByteBuffer>(batches.size());
final Map<TopicPartition, RecordBatch> recordsByPartition = new HashMap<TopicPartition, RecordBatch>(batches.size());
for (RecordBatch batch : batches) {
TopicPartition tp = batch.topicPartition;
produceRecordsByPartition.put(tp, batch.records.buffer()); // tp -> 压缩后的 byteBuffer
recordsByPartition.put(tp, batch); // tp -> 维护重试信息的 RecordBatch
}
// ProduceRequest 协议及数据 --> RequestSend 写缓冲
ProduceRequest request = new ProduceRequest(acks, timeout, produceRecordsByPartition);
RequestSend send = new RequestSend(Integer.toString(destination),
this.client.nextRequestHeader(ApiKeys.PRODUCE), // 单调递增 correlation id
request.toStruct());
// 当 NetworkClient 收到此请求的响应时,将调用此 callback 处理响应结果
RequestCompletionHandler callback = new RequestCompletionHandler() {
public void onComplete(ClientResponse response) {
handleProduceResponse(response, recordsByPartition, time.milliseconds()); // 捕捉了各 tp 的 batch 信息
}
};
// RequestSend --callback handler--> ClientRequest
return new ClientRequest(now, acks != 0, send, callback);
}
|
(3)处理发送结果
在 NetworkClient 收到响应后,会执行先解析出响应的 Struct,协议如下:
public static final Schema PRODUCE_RESPONSE_V2
= new Schema(new Field("responses",
new ArrayOf(new Schema(new Field("topic", STRING),
new Field("partition_responses",
new ArrayOf(new Schema(new Field("partition", INT32),
new Field("error_code", INT16),
new Field("base_offset", INT64),
new Field("timestamp", INT64))))))),
new Field("throttle_time_ms", INT32));
|
返回结果中指明了各 tp 的 base_offset 与 error_code,若有错误则检查是否可重试,无错误则 batch 发送成功
private void completeBatch(RecordBatch batch, Errors error, long baseOffset, long timestamp, long correlationId, long now) {
if (error != Errors.NONE && canRetry(batch, error)) {
this.accumulator.reenqueue(batch, now); // 1. 发生可重试错误,重新入队到队头,尽快重发
} else {
// 2. 致命错误 or 重试次数已耗尽 or 无错误
RuntimeException exception;
if (error == Errors.TOPIC_AUTHORIZATION_FAILED)
exception = new TopicAuthorizationException(batch.topicPartition.topic());
else
exception = error.exception(); // 各种异常单例
batch.done(baseOffset, timestamp, exception); // 回调用户 callback,构造 future 结果结束等待
this.accumulator.deallocate(batch); // 向 accumulator 归还 batch 内存块
}
if (error.exception() instanceof InvalidMetadataException)
metadata.requestUpdate(); // 元数据过期,请求强制更新
if (guaranteeMessageOrder)
this.accumulator.unmutePartition(batch.topicPartition); // 解除 tp 屏蔽
}
|
至此,分析了协议描述,Metadata 更新机制,accumulator 筛选 batch 的两层过滤机制,以及 Sender 包装请求和处理发送结果的过程
总结
本文将 Kafka Producer 分为了三层
内存层:Compressor 实现消息压缩;MemoryRecords 实现 batch 写入并分批;RecordBatch 实现 batch 中各条消息元数据的异步计算,维护消息重发元数据;RecordAccumulator 则负责内存分配与协调
网络层:KafkaChannel 在 SocketChannel 上封装了拆包的读缓冲、封包的写缓冲;KafkaSelector 负责执行网络 IO 并收集结果;NetworkClient 负责维护连接状态,解析 IO 结果
数据处理层:Sender 线程从内存层筛选 batch,构造 Produce 请求下发给网络层,并处理发送结果
Producer 的亮点很多,个人认为有三点
朴素的并发设计:用 Condition 队列实现公平的内存分配、用 CountdownLatch 简化实现 Future 异步通知机制、用 metadata 对象的 wait & notifyAll 实现多线程同步等待更新,用 DCL 思想反射实例化 Compressor Constructor 单例…
严谨的并发逻辑:RecordAccumulator 在 rollover batch 时解决了细粒度锁引入的内存碎片问题…
简洁的模块解耦:RecordAccumulator 负责消息的缓冲分批,Sender 负责筛选 batch 构造发送请求并处理发送结果,NetworkClient 负责执行网络 IO
本文分析了 send 流程涉及到的核心模块及部分代码,更细致的逻辑还需参考源码
原文地址:https://yinzige.com/2020/02/15/kafka-producer/
end
Flink 从入门到精通 系列文章
基于 Apache Flink 的实时监控告警系统
关于数据中台的深度思考与总结(干干货)
日志收集Agent,阴暗潮湿的地底世界

公众号(zhisheng)里回复 面经、ClickHouse、ES、Flink、 Spring、Java、Kafka、监控 等关键字可以查看更多关键字对应的文章。
点个赞+在看,少个 bug 👇

