AI开发者指南丨如何正确理解神经网络和深度学习?
Posted TSINGSEE
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AI开发者指南丨如何正确理解神经网络和深度学习?相关的知识,希望对你有一定的参考价值。
神经网络定义
神经网络是一组算法,可以模仿人脑,旨在识别其模式。它们通过一种机器感知、标记或聚类原始输入来解释感官数据。他们识别的模式是包含在向量中的数字,无论是图像、声音、文本还是时间序列,都必须转换成向量。
神经网络帮助我们进行聚类和分类。你可以将它们视为存储和管理的数据之上的聚类和分类层。它们有助于根据示例输入之间的相似性对未标记的数据进行分组,并在有要训练的标记数据集时对数据进行分类。(神经网络还可以提取特征,这些特征会被提供给其他算法进行聚类和分类;因此,你可以将深度神经网络视为涉及强化学习、分类和回归算法的大型机器学习的组件。)

一些具体的例子
深度学习将输入映射到输出。 它找到相关性。 它被称为“通用逼近器”,因为它可以学习在任何输入 x 和任何输出 y 之间逼近未知函数 f(x) = y,假设它们完全相关(例如通过相关性或因果关系)。 在学习过程中,神经网络会找到正确的 f,或者将 x 转换为 y 的正确方式,无论是 f(x) = 3x + 12 还是 f(x) = 9x - 0.1。 以下是深度学习可以做什么的几个例子。
1)分类
所有分类任务都依赖于标记数据集;也就是说,人类必须将他们的知识转移到数据集,以便神经网络学习标签和数据之间的相关性。 这被称为监督学习。
- 检测人脸,识别图像中的人物,识别面部表情(生气、高兴)
- 识别图像中的物体(停车标志、行人、车道标记……)
- 识别视频中的手势
- 检测语音、识别说话者、将语音转录为文本、识别语音中的情绪
- 将文本分类为垃圾邮件(在电子邮件中)或欺诈性(在保险索赔中); 识别文本中的情绪(客户反馈)

2)聚类
聚类或分组是对相似性的检测。深度学习不需要标签来检测相似性。没有标签的学习称为无监督学习。机器学习的一条定律是:算法可以训练的数据越多,它就越准确。因此,无监督学习有可能产生高度准确的模型。
- 搜索:比较文档、图像或声音以显示相似的项目。
- 异常检测:检测相似性的另一方面是检测异常或异常行为。 在许多情况下,异常行为与您想要检测和预防的事情高度相关。
3)预测分析:回归
通过分类,深度学习能够建立图像中的像素与人名之间的相关性。你可以将其称为静态预测。同样的道理,如果有足够多的正确数据,深度学习能够在当前事件和未来事件之间建立关联。它可以在过去和未来之间运行回归。未来事件在某种意义上就像标签。深度学习不一定在意时间,也不一定在意尚未发生的事情。给定一个时间序列,深度学习可能会读取一串数字并预测接下来最有可能出现的数字。
- 硬件故障(数据中心、制造、运输)
- 健康问题(基于重要统计数据和可穿戴设备数据的中风、心脏病发作)
- 用户流失(根据网络活动和元数据预测用户流失的可能性)
我们预测得越好,我们就能越好地预防和预防。借助神经网络,我们也正在迈向一个更智能的世界,将神经网络与其他算法(如强化学习)相结合以实现更多的目标。
通过对深度学习用例的简要概述,让我们看看神经网络是由什么组成的。
神经网络元素
深度学习是我们用于“堆叠神经网络”的名称;即由多层组成的网络。
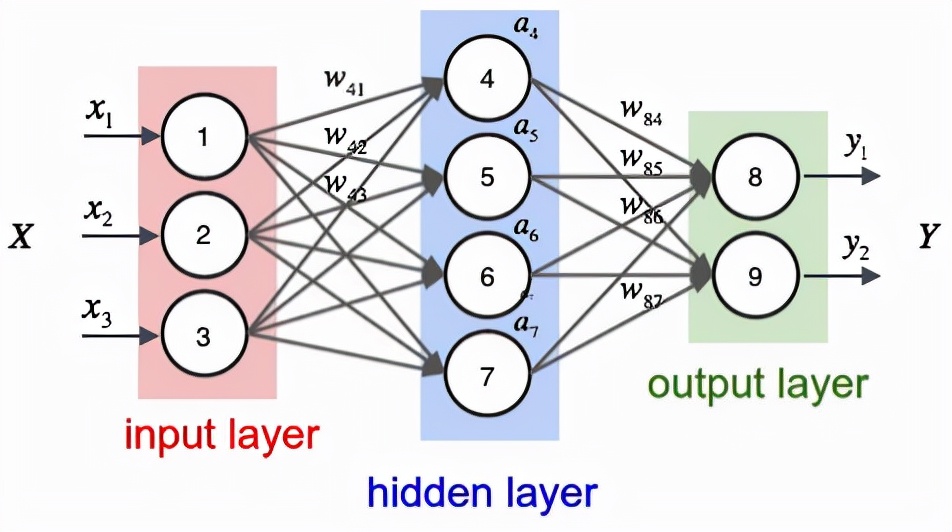
层由节点组成节点只是计算发生的地方,类似人脑中的神经元,当它遇到足够的刺激时就会激活。一个节点将来自数据的输入与一组系数或权重相结合,这些系数或权重可以放大或抑制该输入,从而为算法尝试学习的任务赋予输入重要性。这些输入权重乘积被求和,然后总和通过一个节点的所谓激活函数,以确定该信号是否以及在多大程度上应该通过网络进一步传播以影响最终结果,例如分类行为。如果信号通过,则神经元已被“激活”。
大致流程如下图所示:
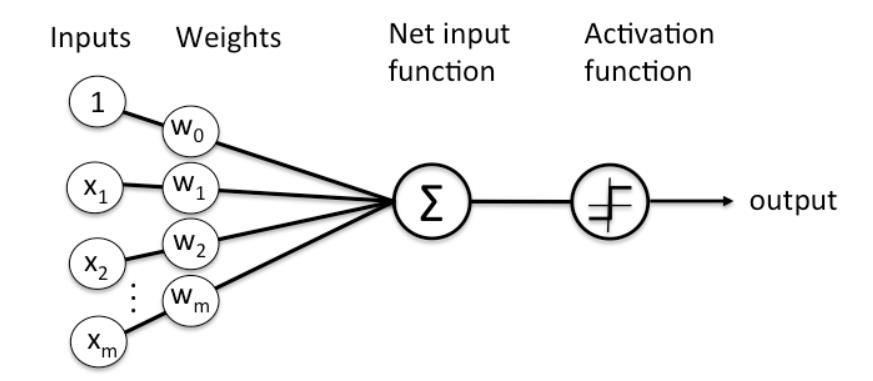
节点层是一排类似神经元的开关,当输入通过网络馈送时,这些开关会打开或关闭。每个层的输出同时是后续层的输入,从接收数据的初始输入层开始。
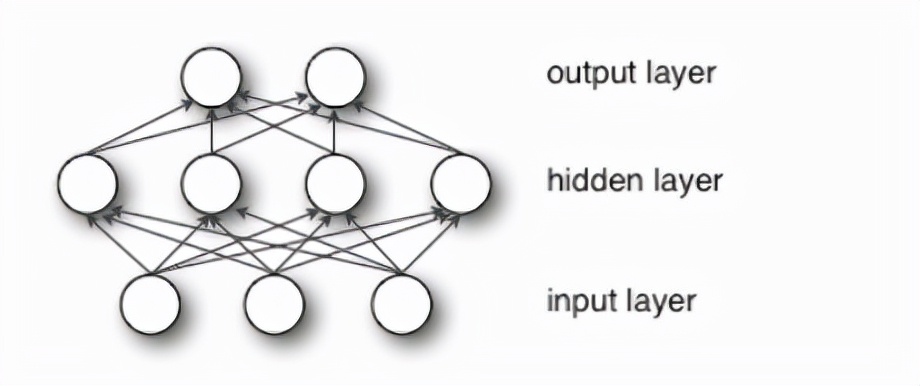
将模型的可调整权重与输入特征配对是我们如何根据神经网络如何对输入进行分类和聚类来为这些特征分配权重。
深度神经网络的关键概念
深度学习网络与更常见的单隐藏层神经网络的区别在于它们的深度;也就是说,在模式识别的多步骤过程中,数据必须通过的节点层数。
早期版本的神经网络(如第一个感知器)是浅层的,由一个输入层和一个输出层组成,中间最多有一个隐藏层。超过三层(包括输入和输出)就可以称为“深度”学习。So deep 不仅仅是一个流行词,它让算法看起来像是在读萨特,听你还没有听说过的乐队。这是一个严格定义的术语,表示多个隐藏层。
在深度学习网络中,每一层节点都根据前一层的输出在一组不同的特征上进行训练。越深入神经网络,节点可以识别的特征就越复杂,因为它们聚合和重新组合来自前一层的特征。
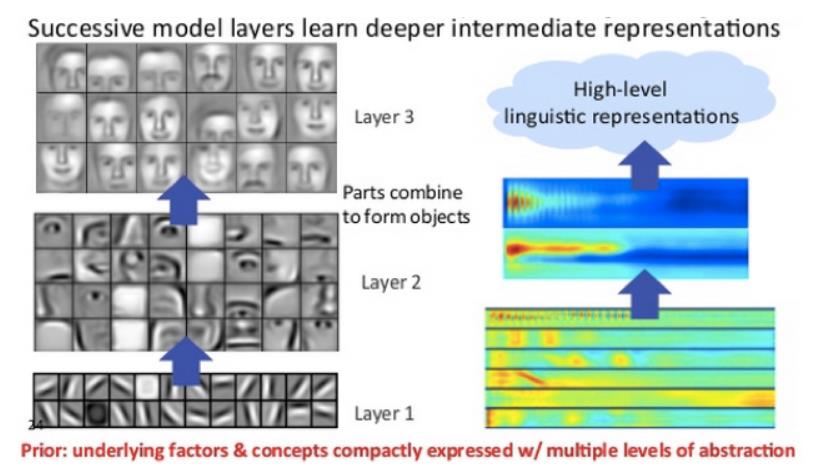
这被称为特征层次结构,它是一个复杂性和抽象性不断增加的层次结构。它使深度学习网络能够处理具有数十亿个通过非线性函数的参数的非常大的高维数据集。
最重要的是,这些神经网络能够发现未标记、非结构化数据中的潜在结构。非结构化数据的另一个词是原始媒体。即图片、文字、视频和录音。因此,深度学习最能解决的问题之一是处理和聚类世界上原始的、未标记的媒体,辨别数据中的相似之处和异常,这些数据没有人在关系数据库中组织过或从未命名过。
例如,深度学习可以拍摄一百万张图像,并根据它们的相似性对它们进行聚类:一个角落是猫,另一个角落是破冰船,还有三分之一是你祖母的所有照片。这就是所谓的智能相册的基础。
现在将相同的想法应用于其他数据类型:深度学习可能会聚类原始文本,例如电子邮件或新闻文章。充满愤怒抱怨的电子邮件可能会聚集在向量空间的一个角落,而满意的客户或垃圾邮件消息可能会聚集在其他角落。这是各种消息过滤器的基础,可用于客户关系管理 (CRM)。这同样适用于语音消息。
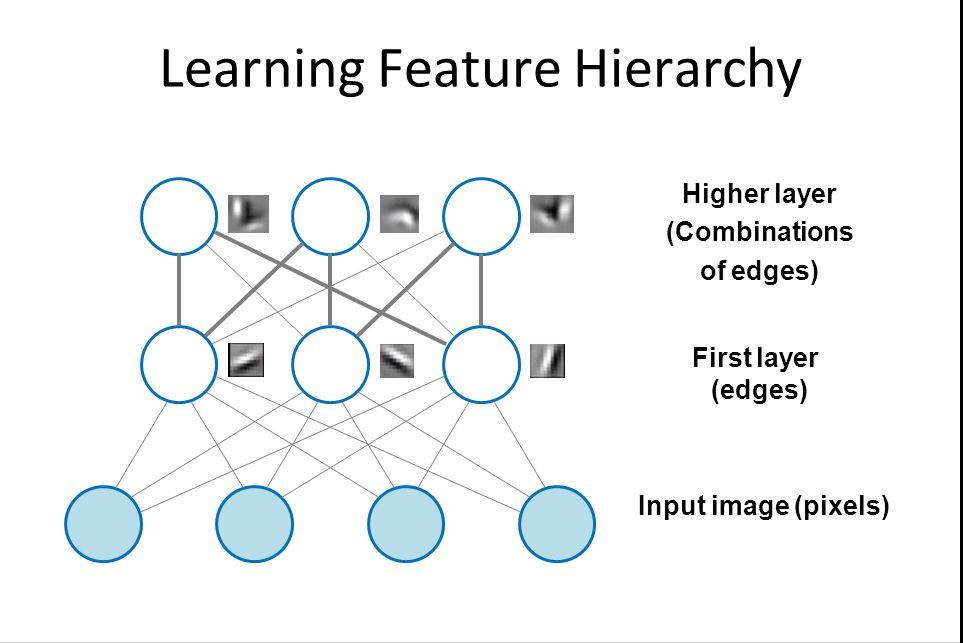
对于时间序列,数据可能会聚集在正常/健康行为和异常/危险行为的周围。如果时间序列数据是由智能手机生成的,它将提供对用户健康和习惯的洞察;如果它是由汽车零件产生的,它可能被用来防止灾难性的故障。
与大多数传统机器学习算法不同,深度学习网络无需人工干预即可执行自动特征提取。鉴于特征提取是一项需要数据科学家团队数年才能完成的任务,深度学习是一种绕过有限瓶颈的方法。
在对未标记数据进行训练时,深度网络中的每个节点层都会通过反复尝试重构从中抽取样本的输入来自动学习特征,尝试最小化网络猜测与输入数据本身的概率分布之间的差异。例如,受限玻尔兹曼机以这种方式创建所谓的重建。
在这个过程中,这些神经网络学会识别某些相关特征与最佳结果之间的相关性——它们在特征信号和这些特征代表的含义之间建立联系,无论是完全重建还是标记数据。
然后,在标记数据上训练的深度学习网络可以应用于非结构化数据,使其能够获得比机器学习网络更多的输入。这是提高性能的秘诀:网络可以训练的数据越多,它就越准确。 (在大量数据上训练的糟糕算法可以胜过在很少数据上训练的好算法。)深度学习处理和学习大量未标记数据的能力使其比以前的算法具有明显的优势。
深度学习网络在输出层结束:逻辑或 softmax 分类器,为特定结果或标签分配可能性。我们称之为预测,但它是广义的预测。给定图像形式的原始数据,深度学习网络可能会决定,例如,输入数据有 90% 的可能性代表一个人。
1)前馈网络
我们使用神经网络的目标是尽可能快地到达误差最小的点。举个例子,跑步比赛中,比赛围绕着一条赛道进行,所以我们在一个循环中反复通过相同的点。 比赛的起点是我们的权重被初始化的状态,终点是那些参数能够产生足够准确的分类和预测时的状态。
比赛本身涉及许多步骤,而这些步骤中的每一步都类似于之前和之后的步骤。 就像跑步者一样,我们会一遍又一遍地进行重复的动作以到达终点。 神经网络的每一步都涉及猜测、误差测量和权重的轻微更新,对系数的增量调整,因为它会慢慢学会关注最重要的特征。
权重的集合,无论它们处于起始状态还是结束状态,也称为模型,因为它试图对数据与真实标签的关系进行建模,以掌握数据的结构。模型通常开始时很糟糕,随着神经网络更新其参数而随着时间的推移而变化,最终会变得不那么糟糕。
这是因为神经网络是在无知中诞生的。它不知道哪些权重和偏差可以最好地转换输入以做出正确的猜测。它必须从猜测开始,然后随着它从错误中吸取教训,尝试按顺序做出更好的猜测。 (你可以把神经网络想象成一个孩子:他们生来就知之甚少,并且通过接触生活经验,他们慢慢学会解决世界上的问题。对于神经网络来说,数据是唯一的经验。)
以下是对前馈神经网络学习过程中发生的事情的简单解释,也是最简单的架构。
输入进入网络。系数或权重将输入映射到网络最后做出的一组猜测。
输入 * 权重 = 猜测加权输入导致对输入是什么的猜测。 然后神经系统将其猜测与数据的基本事实进行比较,有效地询问专家“我做对了吗?”
基本事实 - 猜测 = 错误网络的猜测和真实情况之间的区别在于它的错误。网络测量该误差,并将误差遍历其模型,根据它们对误差的贡献程度调整权重。
误差 * 权重对误差的贡献 = 调整上面的三个伪数学公式解释了神经网络的三个关键功能:对输入进行评分、计算损失和对模型应用更新——重新开始三步过程。 神经网络是一个纠正性反馈循环,奖励支持其正确猜测的权重,惩罚导致其出错的权重。
2)多元线性回归
尽管名称受生物学启发,但人工神经网络与任何其他机器学习算法一样,只不过是数学和代码。事实上,任何了解线性回归的人都可以理解神经网络的工作原理。在最简单的形式中,线性回归表示为:
Y_hat = bX + a其中 Y_hat 是估计的输出,X 是输入,b 是斜率,a 是二维图垂直轴上一条线的截距。 可以想象,每次向 X 添加一个单位时,因变量 Y_hat 都会按比例增加,无论在 X 轴上走多远。一起向上或向下移动的两个变量之间的这种简单关系是一个起点。
下一步是想象多元线性回归,其中有许多输入变量产生一个输出变量。它通常是这样表达的:
Y_hat = b_1*X_1 + b_2*X_2 + b_3*X_3 + a现在,这种形式的多元线性回归正在神经网络的每个节点上发生。对于单层的每个节点,来自前一层每个节点的输入与来自其他每个节点的输入重新组合。也就是说,输入根据它们的系数以不同的比例混合,这些系数不同,导致进入后续层的每个节点。通过这种方式,网络测试哪个输入组合在试图减少错误时是重要的。
一旦对节点输入求和以到达 Y_hat,它就会通过一个非线性函数。原因如下:如果每个节点只进行多元线性回归,Y_hat 会随着 X 的增加而无限制地线性增加,但这不符合我们的目的。
我们试图在每个节点上构建的是一个开关(如神经元……),它可以打开和关闭,这取决于它是否应该让输入信号通过以影响网络的最终决策。
当你有一个开关时,你有一个分类问题。输入的信号是否表明节点应该将其分类为足够、或不足够、开或关?二元决策可以用 1 和 0 表示,逻辑回归是一个非线性函数,它压缩输入以将其转换为 0 和 1 之间的空间。
每个节点的非线性变换通常是类似于逻辑回归的 S 形函数。它们以 sigmoid(希腊语中的“S”一词)、tanh、hard tanh 等名称命名,它们塑造了每个节点的输出。所有节点的输出,每个节点都被压缩成 0 到 1 之间的 S 形空间,然后作为输入传递到前馈神经网络中的下一层,依此类推,直到信号到达网络的最后一层,其中做出决定。
3)梯度下降
一种根据权重引起的误差调整权重的常用优化函数的名称称为“梯度下降”。
梯度是斜率的另一种说法,斜率在 xy 图上以其典型形式表示两个变量如何相互关联:随时间变化的增长、货币变化等。在这种特殊情况下,我们关心的斜率描述了网络误差和单个权重之间的关系;也就是说,随着权重的调整,误差是如何变化的。
更准确地说,哪个权重产生的误差最小?哪一个正确表示输入数据中包含的信号,并将它们转换为正确的分类?哪个可以在输入图像中听到“鼻子”,并且知道应该将其标记为人脸而不是煎锅?
随着神经网络的学习,它会慢慢调整许多权重,以便它们可以正确地将信号映射到含义。网络误差与每个权重之间的关系是一个导数 dE/dw,它衡量权重的轻微变化导致误差轻微变化的程度。
每个权重只是涉及许多变换的深度网络中的一个因素;权重的信号经过多个层的激活和求和,因此我们使用微积分的链式法则返回网络的激活和输出,最终得出所讨论的权重及其与总体误差的关系。
微积分中的链式法:
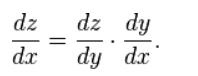
在前馈网络中,网络误差和单个权重之间的关系如下所示:

也就是说,给定两个变量 Error 和 weight,它们由第三个变量激活(权重通过该变量传递)介导,可以通过首先计算激活的变化如何影响来计算权重的变化如何影响 Error 的变化 Error 的变化,以及权重的变化如何影响激活的变化。
深度学习中学习的本质无非是:根据模型产生的误差调整模型的权重,直到无法再减少误差为止。
4)逻辑回归
在许多层的深度神经网络上,最后一层具有特殊的作用。在处理标记输入时,输出层对每个示例进行分类,应用最可能的标签。输出层上的每个节点代表一个标签,该节点根据它从前一层的输入和参数接收到的信号强度打开或关闭。
每个输出节点产生两种可能的结果,二进制输出值 0 或 1,因为输入变量要么值得一个标签,要么不值得。毕竟,没有一点怀孕这回事。
虽然处理标记数据的神经网络产生二进制输出,但它们接收的输入通常是连续的。也就是说,网络作为输入接收的信号将跨越一系列值并包括任意数量的指标,具体取决于它寻求解决的问题。
例如,推荐引擎必须就是否投放广告做出二元决策。但它做出决定所依据的输入可能包括用户上周在亚马逊上花费了多少,或者该用户访问该网站的频率。
因此,输出层必须将诸如花在购物上的 67.59 美元和对网站的 15 次访问等信号压缩到 0 到 1 之间的范围内;即给定输入是否应该被标记的概率。
我们用来将连续信号转换为二进制输出的机制称为逻辑回归。这个名字很不幸,因为逻辑回归用于分类而不是大多数人熟悉的线性回归。它计算一组输入与标签匹配的概率。
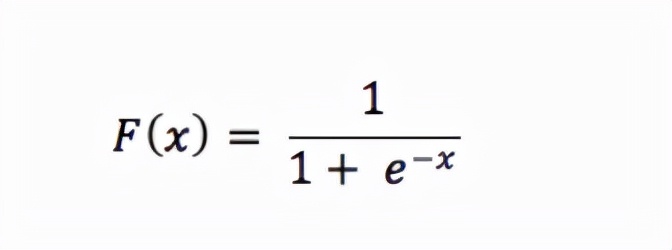
让我们研究一下这个小公式。
对于要表示为概率的连续输入,它们必须输出正结果,因为不存在负概率之类的东西。这就是为什么将输入视为分母中 e 的指数的原因——因为指数迫使我们的结果大于零。现在考虑 e 的指数与分数 1/1 的关系。一个,正如我们所知,是概率的上限,超过这个上限,我们的结果就会变得荒谬。 (我有 120% 的把握。)
随着触发标签的输入 x 的增长,x 的表达式 e 向零收缩,留下 1/1 或 100% 的分数,这意味着我们接近(但从未完全达到)标签适用的绝对确定性。与你的输出负相关的输入的值将被 e 指数上的负号翻转,并且随着负信号的增长,x 的 e 量变得更大,从而使整个分数越来越接近于零。
现在想象一下,不是将 x 作为指数,而是所有权重及其相应输入的乘积之和——通过网络的总信号。这就是你在神经网络分类器的输出层输入逻辑回归层的内容。
通过这一层,我们可以设置一个决策阈值,高于该阈值的示例标记为 1,低于该阈值则不标记。你可以根据自己的喜好设置不同的阈值——低阈值会增加误报的数量。
神经网络与人工智能
在某些圈子里,神经网络是人工智能的同义词。在另一些情况下,它们被认为是一种“蛮力”技术,其特点是缺乏智能,因为它们从一张白纸开始,然后通过敲击获得准确的模型。通过这种解释,神经网络是有效的,但其建模方法效率低下,因为它们不对输出和输入之间的功能依赖性做出假设。
值得一提的是,最重要的人工智能研究小组正在通过训练越来越大的神经网络来推动该学科的发展。蛮力有效。例如 OpenAI 对更通用 AI 的追求强调了一种蛮力的方法,这在 GPT-3 等知名模型中已被证明是有效的。

像 Hinton 的胶囊网络这样的算法需要更少的数据实例来收敛到一个准确的模型;也就是说,目前的研究有可能解决深度学习的蛮力低效问题。
虽然神经网络可用作函数逼近器,在许多感知任务中将输入映射到输出,以实现更通用的智能,但它们可以与其他 AI 方法结合来执行更复杂的任务。例如,深度强化学习将神经网络嵌入强化学习框架中,它们将动作映射到奖励以实现目标。 Deepmind 在电竞和围棋中的胜利就是很好的例子。
现实场景中的AI应用示例:
人工智能已经走进我们的生活,并应用于各个领域,它不仅给行业带来了巨大的经济效益,也为我们的生活带来了许多改变和便利。
TSINGSEE青犀视频基于多年视频领域的技术经验积累,在人工智能技术+视频领域,也不断研发,将AI检测、智能识别技术融合到各个视频应用场景中,如:安防监控、视频中的人脸检测、人流量统计、危险行为(攀高、摔倒、推搡等)检测识别等。典型的示例如EasyCVR视频融合云服务,具有AI人脸识别、车牌识别、语音对讲、云台控制、声光告警、监控视频分析与数据汇总的能力。
以上是关于AI开发者指南丨如何正确理解神经网络和深度学习?的主要内容,如果未能解决你的问题,请参考以下文章