一文搞懂CTR建模
Posted 腾讯技术工程
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文搞懂CTR建模相关的知识,希望对你有一定的参考价值。

作者:coreyzhong,腾讯 IEG 应用研究员
本文分为三个部分:
Part1 是前菜,帮助没接触过相关内容的同学快速了解我们要做什么、为什么做;
Part2 适合刚刚接触 pCTR 建模想要完成项目的算法同学;
Part3 适合正在做 CTR 建模项目且想要进一步优化效果的算法同学。
Part1
计算广告
广告是互联网流量变现的重要手段,也是互联网产品进行推广的重要方式。互联网广告行业经历了合约广告时期、精准定向广告时期、竞价广告时期等多阶段的发展,现在行业内已经普遍采用了自动化竞价的广告投放模式。
在计算广告的投放和交易中,除了用户是被动参与其中,还有媒体和广告主两方进行交易,其中媒体希望通过广告的形式将自己的流量变现,广告主希望通过广告来付费推广自己的产品。同时整个链路中还有针对媒体方设计的供给方产品(SSP)和针对广告主设计的需求方平台(DSP)。
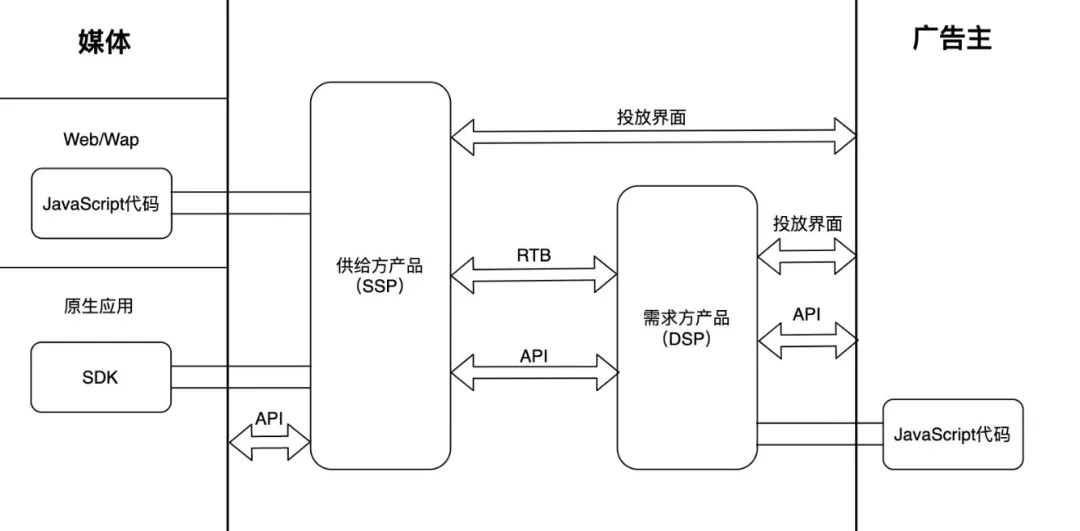
上图为行业内供需之间多种接口与产品的形式(来源于刘鹏的《计算广告》一书),而一个成熟的广告平台通常需要具备上图中的一整套功能。比如需要提供广告主建立广告的投放界面、需要具备 SSP 的与媒体 APP 对接的功能、需要提供可以给媒体 APP 集成的广告 SDK 以及需要提供 DSP 的广告竞价功能等等。其中 DSP 中的广告竞价系统是计算广告中最核心的模块之一,而 CTR 模型也将在这里发挥它的重要作用。
广告竞价系统
计算广告的核心是广告的竞价系统,也就是需要对每一次广告请求,都要在 100ms 内从广告库中选取一个最合适的广告,计算好本次曝光的价格,并返回给媒体。这个过程主要需要经历召回、粗排、精排、出价几个步骤:

召回
每个优化师都可以随时建立新的广告,通常来讲广告库中的广告数量可以达到几万、几十万、甚至几百万的量级。由于精确计算该次请求中每个广告的 pCTR、pCVR 比较耗时,如果针对广告库中所有广告都计算其 pCTR、pCVR,一方面十分浪费计算资源,而且几乎不可能在 100ms 内将结果返回给媒体。
所以广告系统通常会先采用一些耗时低的方案,用精度换时间。从全量广告库中召回几百条广告进入后续模块的竞价过程,这样精排过程只需要针对几百个广告计算 pCTR、pCVR 即可,就可以实现 100ms 内完整全部广告竞价过程。
粗排
粗排的作用与召回类似,主要是进一步减少广告条数。如果广告库中广告数量特别大,比如达到百万量级,因为召回模型必须重点考虑时延问题,只能牺牲精度,如果仅通过召回模块让候选集从百万降低到几百,则不可避免的会导致精度下降过大。这种情况下会在召回和精排中间加入粗排过程,粗排模型的复杂度和精度通常介于召回模型和精排模型之间,目的是在效率和精度上进行权衡取舍。
精排
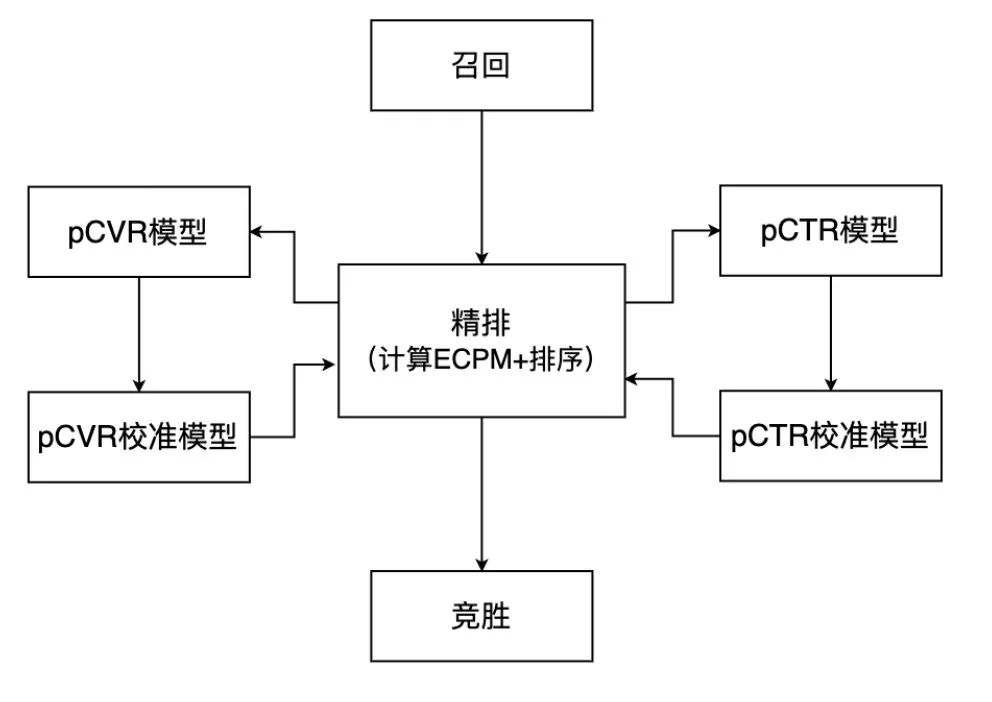
到了精排这一步,一般就只剩下几百个广告,我们只需要针对每个广告,调用 pCTR 模型和 pCVR 模型,精确计算 pCTR、pCVR 的值,计算 ECPM 并排序(这一部分下一节介绍)。
出价
通常来讲有了精排给出的 ECPM 值就可以进行曝光和结算了,但是由于精排过程中深度模型无法进行更高层面的全局考虑。通常广告平台为了成本达成、预算平滑等目的的考虑,会在精排之后对 ECPM 进行调整。这一环节中通常策略更多一些。
ECPM 与精排
在竞价系统中,每次请求究竟哪个广告胜出,通常是根据 ECPM 公式来计算。ECPM(Effective Cost Per Mille)是用来衡量一次曝光价值的指标,具体含义为假设该次曝光重复 1000 次的价格(单位为元)。比较基础的计算公式如下:
其中 price 是广告主设定的价格,比如在 oCPA 投放时,用户指定预期每个转化 40 元,那这里的 price 就等于 40;至于 pCTR 和 pCVR 就是此次曝光的点击率和转化率,分别由 pCTR 模型和 pCVR 模型进行估计。
不同的业务会根据自己的业务需求对 ECPM 公式进行修改,比如如果要进行 ROI 的优化,可能会考虑用户 LTV 的影响:
以及例如我们之前与 AMS 的合作项目中,广告主来估计用户的价值分级,回传给广告平台后,广告平台会直接在 ECPM 上乘一个系数;有时广告主需要平滑预算,会将 ECPM 进行进一步修正平滑作为最终出价。但是不论对 ECPM 进行哪些修改,都不影响其含义本质,都是衡量曝光的价值,以及作为双方进行经济结算的重要依据。
在精排中,就是要将召回回来的<=300 条广告,分别计算 pCTR 和 pCVR(在这里我们本文的主角即将登场),并根据约定好的 ECPM 公式计算 ECPM,最终进行排序,价高者胜,二价计费。
Part2
前文介绍到整个广告系统的核心任务,就是对每一个曝光机会,从广告库里选择一个最合适的“广告”进行展示(并将广告的一些信息返回给媒体,一般是包括素材 URL、文案、ECPM 等内容)。而什么是所谓“合适”的广告,是根据 ECPM 来衡量的,各方面因素的影响(广告主的意愿、用户的特点等等)都会在 ECPM 公式中得以体现。而本文的主角——pCTR 模型的任务,就是尽可能精准的预估 ECPM 公式中的 pCTR 值。
模型训练 Pipeline
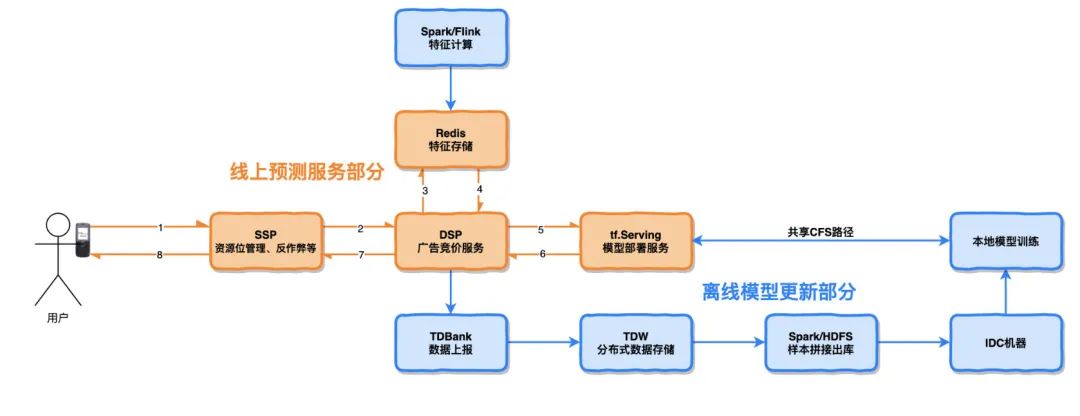
上图是一个离线模型训练流程的示意图。橙色部分为线上服务部分,蓝色部分为模型离线更新部分
线上预测服务部分
用户刷手机时,广告 SDK 将广告请求发送到 SSP 系统
SSP 系统根据资源位、反作弊等策略进行请求过滤。并将通过过滤的广告请求发送给 DSP
DSP 接收到广告请求后,先从 redis 中获取特征,并一并发送给 tf.Serving 服务,获取模型预估结果
DSP 根据模型预估结果计算最终 ECPM,并将结果经由 SSP 转发给广告 SDK,最终完成广告展示
离线模型更新部分
特征计算:运用 Spark/Flink 例行化计算离线/实时特征,保存到 redis 中以供线上服务读取,同时保存到 TDW 表中备份
样本拼接:DSP 将线上服务中每个请求的特征上报到 TDBank,并落库 TDW。并每天根据曝光、点击上报日志,以 request_id 为 key 拼接样本,并将样本出库到 HDFS
模型训练:每天定时开始检查 HDFS 上的数据,数据成功出库后触发模型训练,训练完成后以 timestamp 作为“版本号”保存到指定路径中
模型部署:模型服务采用 Docker+tf.Serving 的模式,其中 Docker 容器和 IDC 训练机同时挂在同一个 CFS 路径。所以只需要将新模型 copy 到指定的 CFS 路径下,tf.Serving 即可自动读取版本号最大(即 timestamp 最大)的最新版本的模型进行预测服务
模型优化
特征 Embedding
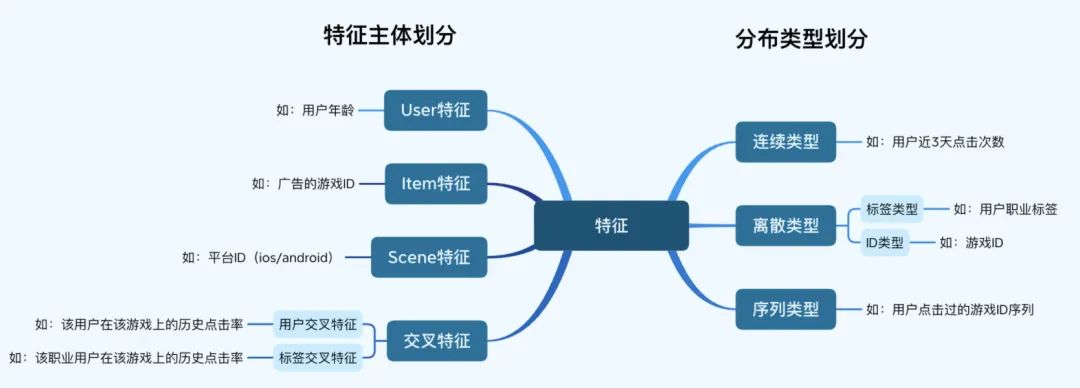
我们的 pCTR 的特征从分布类型看,分为连续类型、离散类型(包含 ID 类型)、序列类型。从特征主体划分,可以分为 User 特征、Item 特征、Scene 特征、交叉特征。
对于每一个特征,我们都会先将其 embedding 化,然后乘上该特征的 value 或 weight(对于连续特征是 value,对于离散标签特征是标签权重 weight)。最后可以将其 concat 到一起,或单独通过其他网络结构。
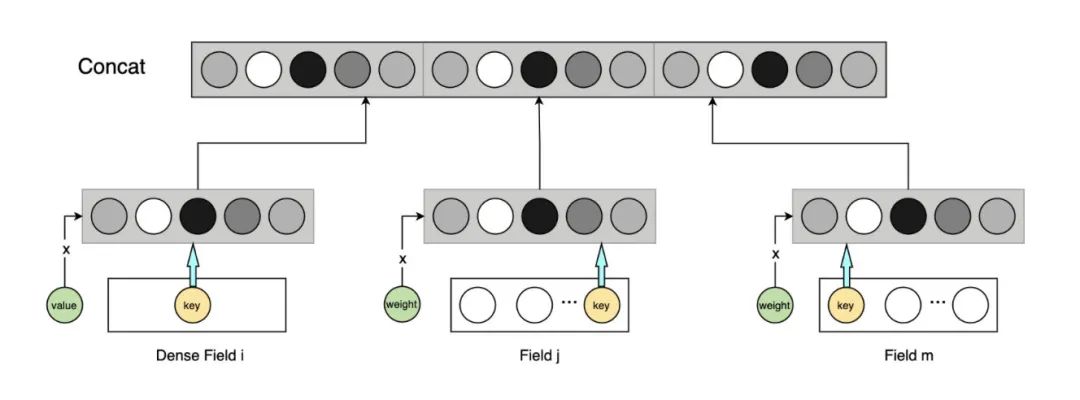
特征预处理
有些特征的特点是分布偏态十分严重,且极差极大。如“用户近 90 天游戏付费金额”,大多数用户该特征都是 0,但是极少量用户的付费金额可能达到数十万。这种情况如果直接让深度模型学习,会导致模型很难收敛,就算收敛了模型效果也大打折扣。对于这种情况需要进行特征预处理,通常业内常采用“归一化”、“标准化”、“截断”:

但这几种方法都存在一些问题:
归一化和标准化需要模型单独保留两个参数(归一化需要保存每个特征的 max 和 min,标准化需要保存每个特征的均值和方差)。但是每次模型训练的数据集中统计的这几个参数都是不同的,这样会导致每次更新模型都会有比较大的波动(比如今天没有突然有大 R 付费,那付费特征的 max 就会飙升,导致模型不稳定)。
归一化和标准化只能解决分布方差大的问题,不能解决偏态严重的问题
截断的方法损失了大量信息,损失了这部分特殊用户的区分度
为了解决这些问题,我们针对部分需要进行预处理的特征,采用如下公式进行转换:
这样做的目的是尽可能不损失区分度的情况下,对该特征进行压缩,避免模型无法收敛的情况。由于对于不同日期的数据,不论其分布如何,都统一采取同样的预处理方式,所以不会出现模型更新后,分布不稳定的情况。经过多次离线实验,采用该变换公式解决收敛性和稳定性问题的同时,并未导致 AUC 降低,真是一个好办法!
特征交叉
人工交叉
模型自动交叉的优点是不需要人工参与,可以自适应根据数据集来进行交叉。但这对于复杂的交叉关系需要极其大量的数据来进行训练,这是不现实的。人工交叉可以讲一些主观认为有价值的交叉特征直接提炼出来,不需要模型去学习,降低了模型学习的难度。
现阶段我们开发了 30+个“用户交叉特征”和 80+个“用户属性标签交叉特征”,用户交叉特征诸如“该用户在该游戏上的历史点击率”、“该用户在该媒体上的历史点击数”等,描述每个用户对每个广告的交叉特征;用户属性标签交叉特征诸如“该职业用户在该游戏上的历史点击率”、“该年龄段用户在该广告模板上的历史点击率”等,描述一个用户属性标签下所有用户对每个广告的交叉特征。
加入交叉特征后,模型 AUC 提升了 0.006(0.8032->0.8105),点击率相对提升了 5.6%。下图为点击率对比图,蓝色线为对照组,橙色线为加入了交叉特征后的实验组。
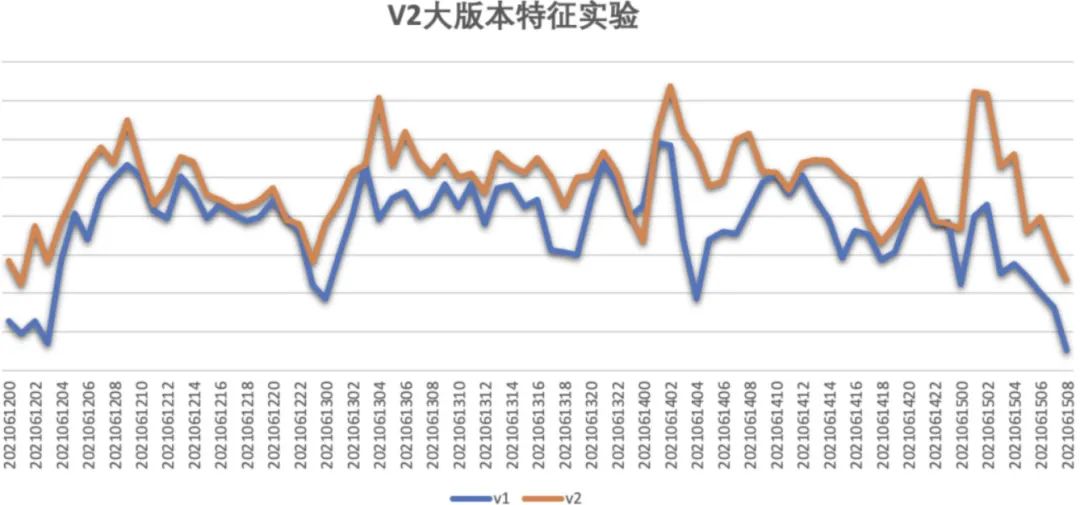
模型结构交叉
在行业内中已经有了大量关于特征自动交叉的研究成果,从 FM 到 FFM 再到 DeepFM,以及后续基于 Attention 的各种交叉变种,本文在这里就不再赘述。我们在模型结构交叉上有过几个版本的迭代:DeepFM、AutoInt 变种、DCN 变种。
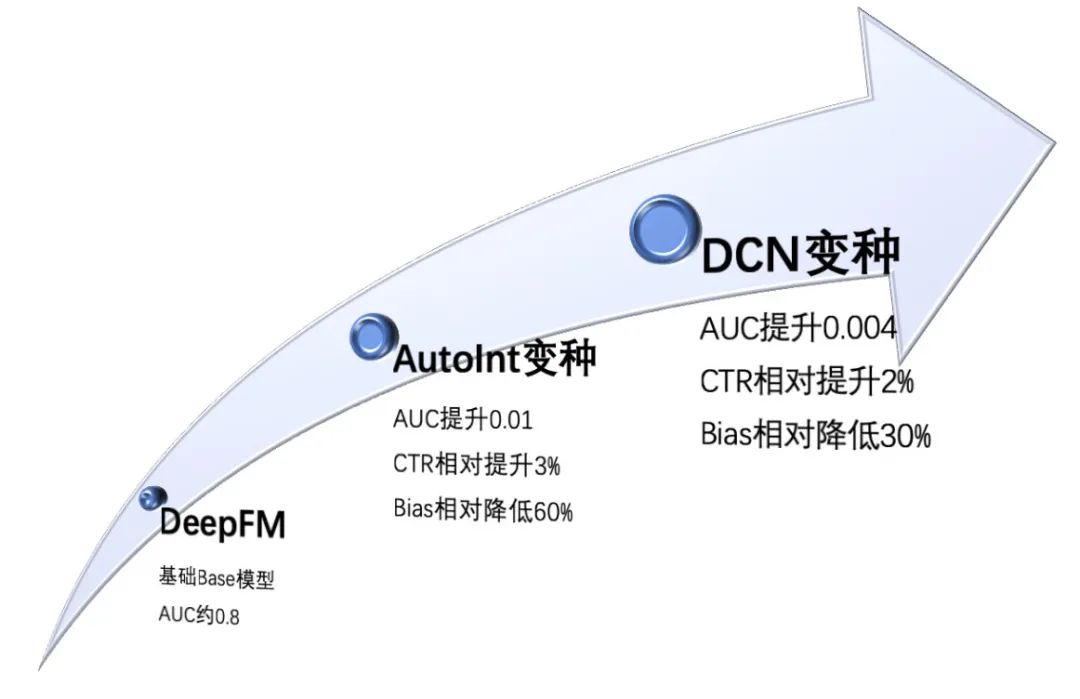
首先第一版特征交叉结构就是采用业内非常常用的 DeepFM 模型,在全量竞胜请求上可以达到 AUC=0.8 左右的效果。虽然此时的绝对 AUC 达到了比较高的值,但因为数据分布不同,不同业务之间对比 AUC 绝对值意义不大。
第二版交叉结构中,采用了 AutoInt 结构中的 Attention Layer,但是我们除此以外还进行了一些调整:
一方面继续维持了 DeepFM 中的一阶部分,删除 DeepFM 中的二阶部分,你也可以称这种结构为 Wide&AutoInt。这样做是为了提高模型的泛化性
另一方面并不是所有特征都经过 Attention Layer 进行交叉,而是剔除了一些主观认为不需要交叉的连续型统计类特征(如用户近 3 天被曝光次数),这样做是为了减小模型参数量,加快线上推导速度,同时一定程度上避免过拟合
经过以上改动,模型 AUC 显著大幅提高了 0.01,线上 CTR 相对提升了约 3%。
第三版交叉结构中,采用 DCNv2 的 Cross Layer 替换之前的 Attention Layer,同时保留之前的 Wide 部分,也同样剔除部分变量不进行 Cross Layer 交叉。这一改动使模型 AUC 显著提升了 0.004,CTR 相对提升了 2%。下图为线上点击率对比图
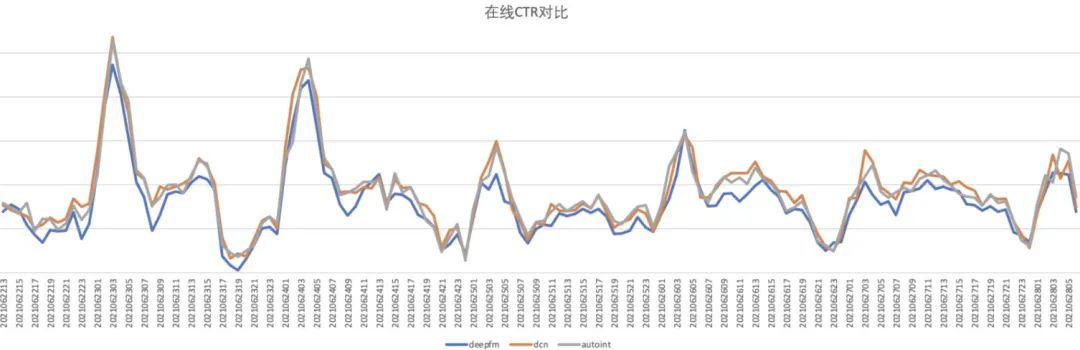
特征冗余共线
在特征中不可避免的会出现特征之间的共线性,比如“用户近 24h 的点击数”和“用户近 72h 的点击数”,又比如“用户在该媒体上的历史点击率”和“用户近 3 天历史点击率”,不可避免的会有较高的共线性。高度共线的特征会使模型很容易在局部最小值处提前收敛,而且可能会导致模型参数量增加,但没有增加有效的信息,从而出现过拟合现象。
通常处理特征共线的方法是通过大量离线实验,不断地删除可能导致共线的特征(可通过相关系数分析),并观察 AUC 的变化。从而在保证 AUC 不降低的前提下,剔除掉共线性最强的特征。但是这样做仍然存在问题:
既然剔除了特征,就不可避免的造成信息损失,降低了模型效果的天花板
加入 A、B、C 三个特征共线,那应该剔除他们三个中的哪个呢?如果仅以剔除后的 AUC 来衡量,可能会在不同天的数据集上得出不同的答案(第一天剔除 A 最好,第二天剔除 C 最高)。即共线特征的重要性,可能是变化的,直接剔除特征无法反应这种变化
针对这种情况,我们借鉴了《GateNet:Gating-Enhanced Deep Network for Click-Through Rate Prediction》中的方案,在模型内部添加一个 Gate 层,本质上是为每个特征增加了一个“可学习的权重”。
读者可能会问:既然深度学习模型本身的学习机制就可以让无关特征的影响降低,从而起到变量筛选的作用,为什么还要单独一个 Gate Layer 来给变量赋权呢?答案就是:“假设空间太大”,一个全连接层的参数量与前后两层节点数的乘积成正比,参数量很大,不容易学习。相比之下 Gate Layer 中的参数量就少了很多,假设空间更小,更容易学习。
考虑到实际上在共线性的情况下,一个特征的权重不仅与自身有关,还与其他特征有关。所以我们采用 Bit-Wise Feature Embedding Gate 结构:
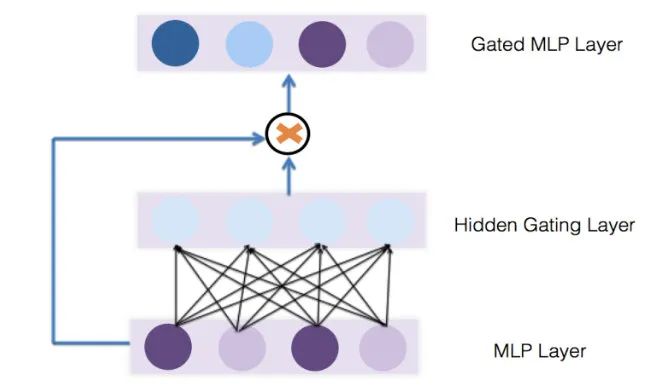
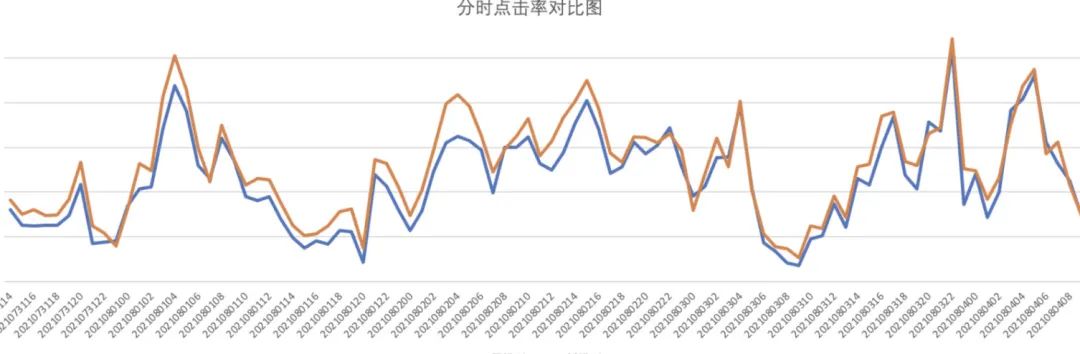
实验验证,经过改进后模型的效果更好(原文结构 AUC 提升 0.00101,改进结构 AUC 提升 0.00129)。线上 AB 实验显示,新增改进后的 Gate Layer,使得线上点击率提升约 2.37%。下图为线上点击率对比图:
序列建模
截至目前,我们在特征方面还引入了序列类型的特征:用户点击游戏序列、用户点击游戏品类序列、用户点击创意序列、用户点击广告序列、用户点击计划序列、用户点击广告类型序列这 6 个序列。针对每个序列先对其 Embedding 化,然后分别进行 Max-Poolling 和 DIN-Attention,并最终进行 concat,作为序列建模层的输出。
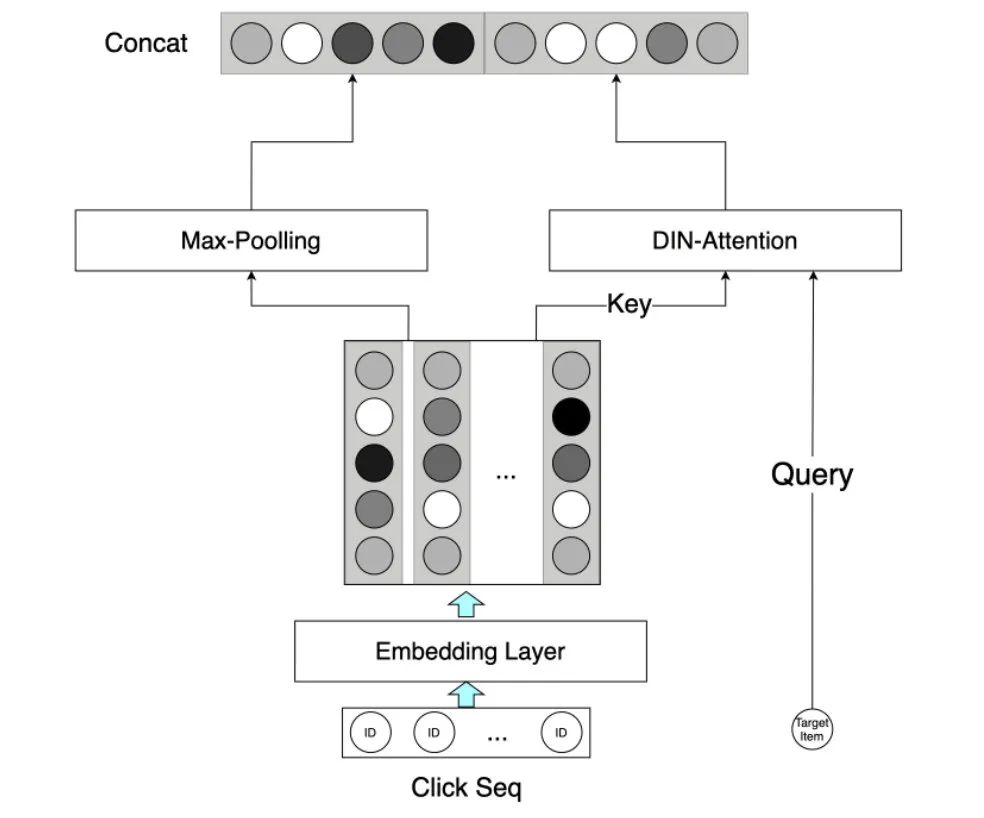
通过加入 DIN-Attention 来优化序列建模过程,模型的 AUC 稳定提升了 0.0012。
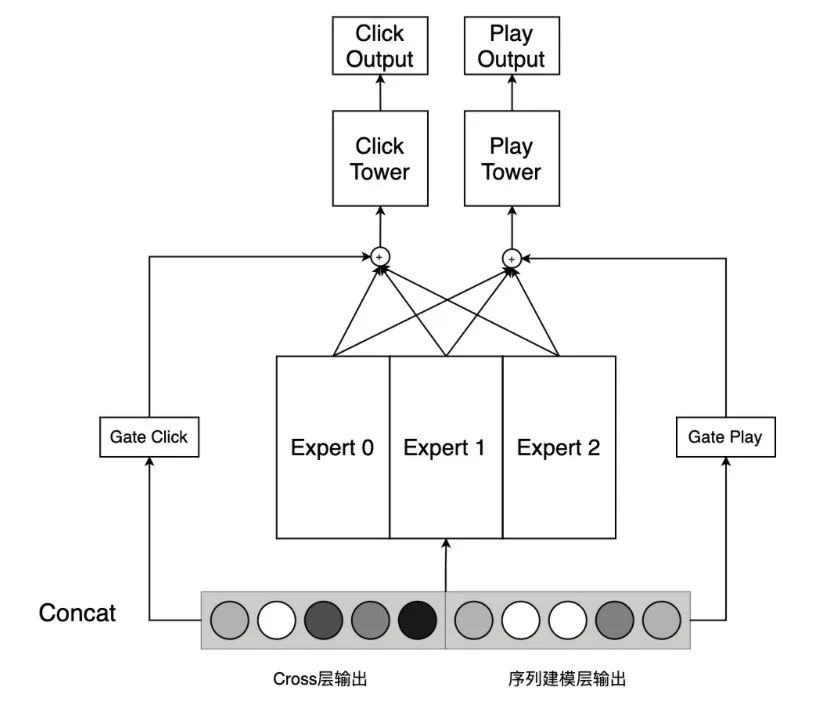
多任务建模
在不同的场景中,我们可以采用不同的辅助任务,来辅助 CTR 模型训练。如朋友圈广告中可以进行“点赞”、“评论”等交互动作。在联盟类流量的广告投放中,因为所对接的媒体类型繁杂,很难推行统一的“交互行为”。我们尝试利用预测视频播放的标签来作为辅助任务,视频播放标签分为:“未播放到 75%”、“播放至 75%到 100%之间”、“完成播放”、“其他”这四个标签,其中“其他”主要表示非视频类曝光。模型结构上,我们将 Cross 层的输出和序列建模层的输出进行 concat,然后经过一个MMoE层,后为两个任务分别接两个 FC 层形成子塔。
经过以上优化,模型离线 AUC 稳定提升了 0.0006。
素材特征
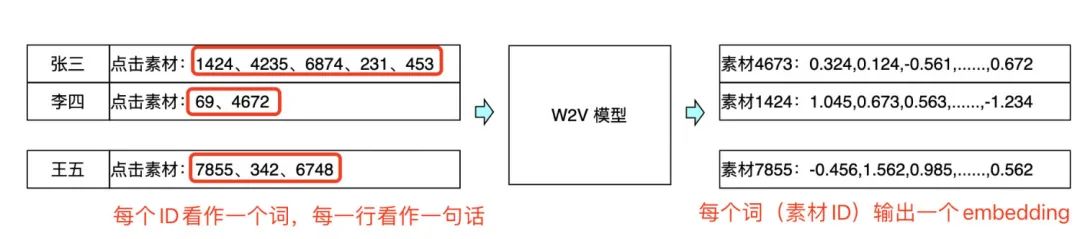
用户刷到广告后,与用户体验相关性最强的就是素材。我们也加入了一些素材的 Embedding 特征,我们尝试将单个用户近期点击过的素材 ID 看作一个集合,同处在一个集合中的素材 ID 看作是一次“共现”。这个关系与 NLP 中,一个句子中词的共现是类似的,只不过素材 ID 的共现中没有前后顺序的联系。所以我们建立了一个简单的 W2V 模型,根据素材 ID 之间的共现关系,学习每个素材 ID 的 Embedding,并将该 Embedding 加入到 pCTR 模型中,给模型的 AUC 稳定地带来了约 0.0003 的提升。
另外我们也尝试过对视频素材内容进行理解,从而提取视频素材的标签或Embedding,从而辅助 CTR 建模,目前取得了离线 AUC 提升 0.0015 的效果,这部分内容比较多本文不做详细介绍,以后会专门写一篇相关文章。
最终模型结构
经过以上多方面的改进优化,我们目前的模型结构示意图如下:
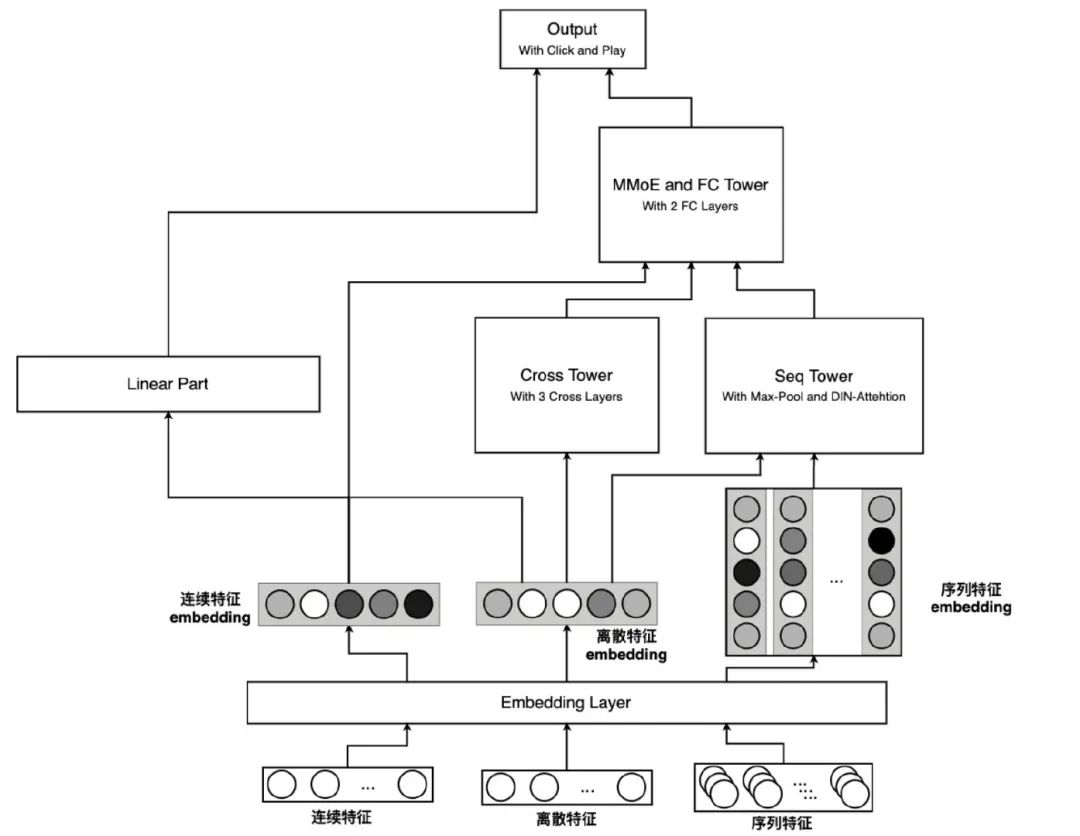
图中诸如 Seq Tower 和 MMoE Tover 的具体结构已经在前文中有所介绍,所以在这里就一笔带过。
模型校准
为什么需要校准?
偏差是指模型对于整体数据集或部分数据集的预测结果,整体偏高或偏低。在广告系统中,我们不仅需要把最合适的广告排在前面,还需要精确计算这一次曝光的“价格”。所以对于广告系统中,偏差指标与衡量排序的 AUC 都很重要。如果偏差>0,说明我们多花了冤枉钱来买低质量曝光机会,如果偏差<0 说明我们损失了一些“物美价廉”曝光机会。这里我们的偏差定义为:
模型的偏差主要有以下 4 个来源:
训练样本采样
这个很容易理解,有些时候算法同学为了正负样本比例的平衡,会将负样本进行下采样,这会导致训练集中的点击样本占比偏高,从而导致模型高估的偏差。对于这种情况,建议能不采样就别采样。
冷启动
当模型中使用了 ID 类特征时,对于冷启动的情况,模型并没有学习过冷启动 ID 的 embedding。相当于该 embedding 的参数值依然保持为模型 compile 时生成的随机数。对于二分类问题,模型中的一部分参数被替换为随机数,会让魔性的预测结果向 0.5 方向移动(即当 CTR<0.5 时产生高估,CTR>0.5 时产生低估)。这种情况的原因也很好解释,我们考虑如下一个非常简单的 LR 模型的例子:
当样本非冷启动时,w1 和 w2 都是训练充分的,整个 LR 模型没有偏差,或偏差很低。但当样本为冷启动时(假设 x1,x2 是 ID 类特征),w1 和 w2 的取值都是随机生成的随机数(通常均值为 0),而 x1 和 x2 都为 1,这时 w1x1+w2x2 的均值自然为 0,从而 y 的均值为 0.5。
总结来说就是,模型中未受训练的随机数,会让魔性的预测结果向“瞎猜”方向移动,而对于二分类来说,模型“瞎猜”的均值就是 0.5。所以冷启动会带来偏向 0.5 的偏差。对于这种情况,一种方案是在项目迭代中逐步用泛化性特征取代 ID 类特征,另外一种方案就是在线学习。
数据分布迁移
随着时间的推移线上数据分布发生变化,包括线上的特征分布、特征与点击的条件分布都已经改变了,这时模型就会有偏差(比如极端情况下,我用去年的数据训模型,在今年的环境上线,明显是不合理的)。这种偏差和前面介绍的“冷启动偏差”类似,也会一定程度上偏向于 0.5。对于这种情况,需要我们及时更新模型,在线学习是解决这个问题的法宝。
模型收敛到局部最优解
理论上,当模型学习的恰如其分,当 LogLoss 取到最小值,且未出现过拟合的情况,模型输出的期望一定等于真实标签的期望。所以当模型仅是收敛到局部最优解时,势必存在一个子数据集上的偏差期望是非零的。对于这种情况我们只能尽量通过模型结构、正则等方式去避免。模型假设空间越大,越容易收敛到局部最优解,所以我们在进行模型版本迭代时,尽可能不要以引入大量参数为代价,去追求细微的效果提升。这短期看是可以取得更好的效果,但长期看其实是给自己挖坑。
缩放校准公式
常用的校准方案 Isotonic Regression 和 Platt Calibration。但是本文主要想介绍另一种更简单的方案——在论文《Practical Lessons from Predicting Clicks on Ads at Facebook》中,作者采用了一种缩放公式来进行校准:
其中 x 为校准前 CTR,w 为负样本采样率。该校准公式虽然简单,但是却具有良好的性质:
无偏性:只要 x 在采样后的数据集上是无偏的,那 x‘就是在未采样数据集上就是无偏的,这一性质在 Isotonic Regression 中是无法保证的
一一映射:任意 x 可以得到唯一 x‘,且任务 x’也可以得到唯一 x,这在 Platt Calibration 中是无法保证的
连续性:Isotonic Regression 是非参数的阶梯函数,相比之下该公式是一个连续函数,不需要对 x 进行分桶
以上都是很好的性质,但是该公式也存在问题,就是他只有一个表示缩放比例的参数 w,它只能够解决“训练样本采样”带来的偏差,或缓解“整体数据分布迁移”带来的偏差。对于由于模型训练不充分导致的分桶偏差(如对 A 部分样本高估,对 B 部分样本低估,但总体上互相抵消了)就无法解决了。
我们通过 reliability diagram 来对比下缩放公式校准与 Isotonic Regression 的效果。下图中蓝色线是未校准的 pCTR,橙色线是缩放公式校准的结果,绿色线是 Isotonic 校准的结果,可以看出校准缩放公式的整体校准效果,完全可以和 Isotonic Regression 匹敌。
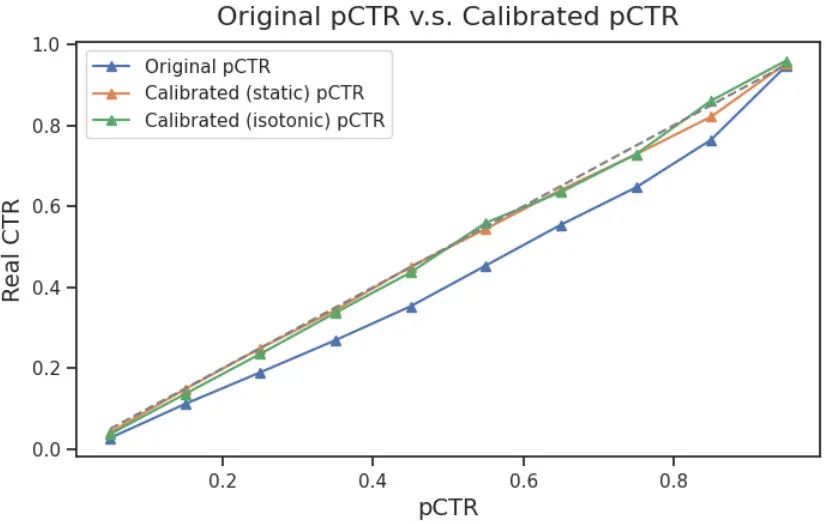
另外因为他是连续的,可以支持梯度训练,对未来的在线学习有更好的兼容性。而且他不需要对 pCTR 进行分桶,不会存在高 pCTR 处因为样本量太少而导致波动大的问题。真是一个好方法呢!
校准模型的改进
对于分桶偏差,TEG 发表的《Field-aware Calibration: A Simple and Empirically Strong Method for Reliable Probabilistic Predictions》理论上可以缓解这个问题。原文将分段离散的 Isotonic Regression 改进为分段连续的多段线性函数,结合一个输入为样本特征的 DNN,一起得到校准结果。
因为在校准模型中,通过 DNN 的方式考虑到了其他特征(如媒体 ID 等),所以可以缓解模型对桶 A 高估,桶 B 低估但总体抵消的情况。但是我们在业务中发现,我们的分桶偏差(分媒体、分游戏、分广告展示形式)也都维持在比较低的水平,与整体偏差差不太多,所以暂时没有必要针对该问题进行专门优化。
Part3
在线学习
前文中提到了偏差产生的原因,其中“冷启动”与“数据分布偏移”产生的偏差都可以靠及时更新模型来消除,而提高模型更新频率的终极解决方案就是在线学习。线上模型进行服务的同时,利用线上实时样本实时地训练模型,并实时的利用最新模型部署服务的方案。在线学习可以将模型的更新频率提升到分钟级甚至秒级。
整体机制
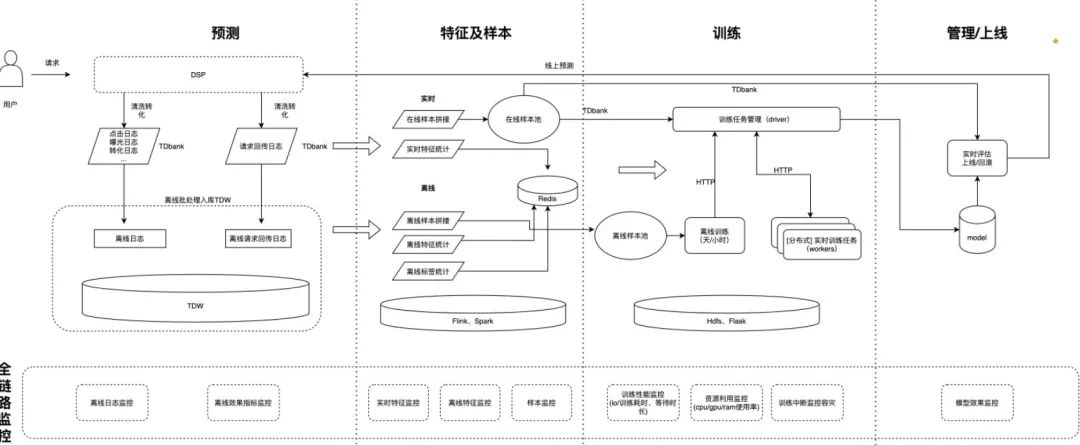
上图为在线学习的整体机制,主要分为四个部分:
DSP 预测:通过 tf.Serving 进行线上预测服务,同时上报曝光、点击、特征日志
特征及样本:实时消费曝光、点击、特征日志,通过 request_id 进行实时 join,拼接实时训练样本,并上报 tdbank
模型实时训练:实时消费前置模块上报的实时样本(感谢 TEG 数平同学 dockerzhang 和 gosonzhang 同学提供的 tubemq-python-sdk),可实现不同的训练触发策略、参数冻结、样本回放策略,以及实时调整模型训练过程中 LR、优化器等参数
模型上线管理:接收实时产出的模型文件,并根据策略对其进行评估、上线、回滚等操作
其中模型训练部分与算法或策略相关性最高,下面详细介绍该模块的一些功能设计。
主要挑战
在线学习与离线训练的最大区别就是,在线学习的样本是实时获取的,所以实时样本无法和离线样本一样进行全局 shuffle。这使每一时刻下的实时样本分布与全局整体分布有很大差异。举个例子:随着时间的推移,上午的数据分布和下午的数据分布就有很大的差异,下两图展示了以 13 点区分的上午、下午的所有曝光中,游戏的占比和媒体的占比。
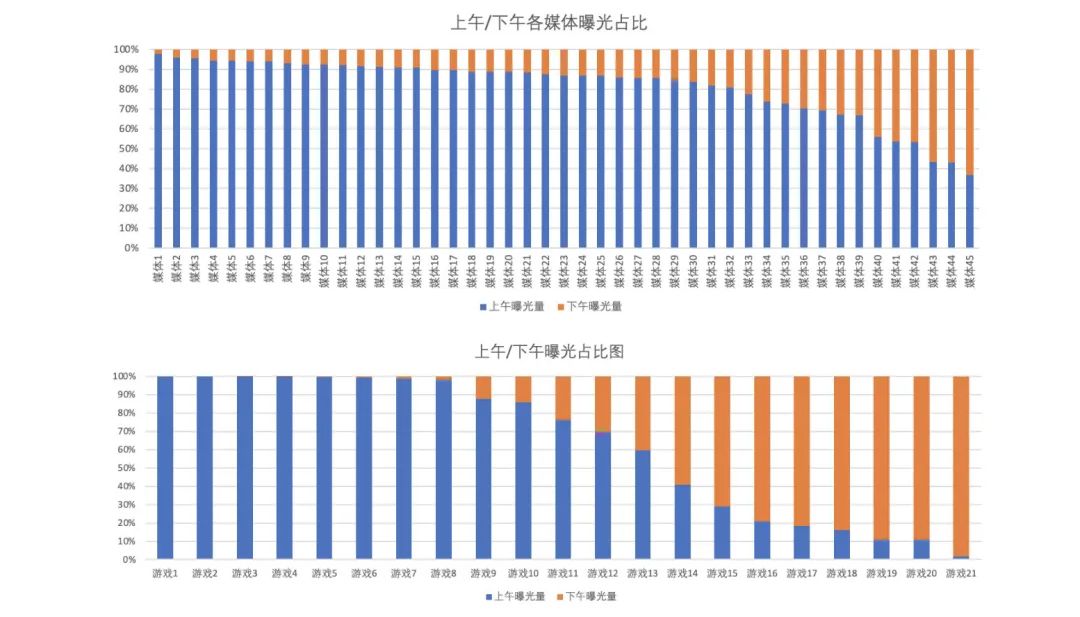
可以看出,随着时间的推移,首先媒体流量分布就会产生变化,加之预算、频控等策略影响,Item 分布也会产生变化。如果直接采用简单增量训练(直接 load 旧模型,train 新数据的方式),很容易产生灾难性遗忘(Catastrophic Forgetting),也就是模型“学飞了”。具体表现我们在下一节介绍。
参数冻结
由于实时数据无法进行全局 shuffle,导致实时样本与离线样本分布差异很大,所以如果模型直接采用简单增量训练会产生灾难性遗忘的问题。我们基于以下三条假设提出参数冻结的方案:
Embedding 主要学习 User/Item 的表征;复杂的交叉结构(如 FC、Cross 等结构),主要学习用户与 Item 的交叉信息(如“男性喜欢玩枪战游戏”)
线上分布的变化,主要体现在 Item/User 分布的变化(新建广告/新接入媒体等);而不是用户偏好的变化(比如男性用户上午喜欢打 CF,下午突然集体改玩爱消除)
在离线模型中,模型已经用大量的数据,比较好的训练了交叉结构
我们在实时训练时,冻结模型的 FC 层、Cross 层等交叉结构的参数,令其不进行更新,仅使用实时样本更新 Embedding 层的参数。离线实验效果如下:
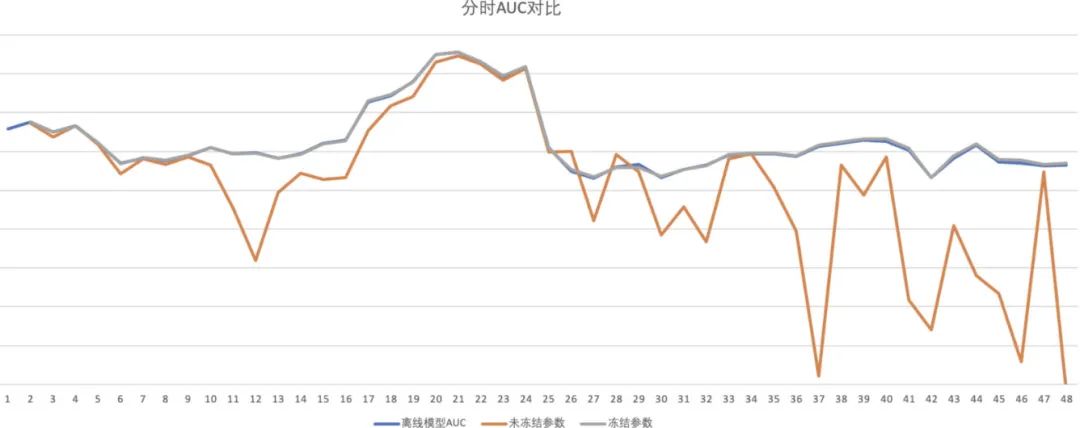
横轴是小时,纵轴是 AUC,橙色线是采用简单增量训练,蓝色线是离线模型,灰色线是采用了参数冻结的增量训练。可以看出在没有进行参数冻结的情况下,模型效果始终不如离线模型,且到了后期模型的 AUC 甚至会低至 0.5-0.6 之间。这说明数据分布的变化对模型训练的影响十分严重。而采用了参数冻结后,模型没有出现灾难性遗忘的情况,且模型 AUC 平均提高了 0.0007(即灰色线比蓝色线高 0.0007,图中很难看出来)。在多日的线上 AB 实验中显示,采用了参数冻结后,线上点击率相对离线模型提升了约 2.8%左右。
另外需要注意的是,参数冻结的方案是以牺牲模型学习能力的方式来换取模型的稳定性,冻结的参数越多模型越稳定,但是学习能力也会大打折扣。所以该方案是一把双刃剑,还需要其他方案的配合才能取得较好的效果。
样本回放
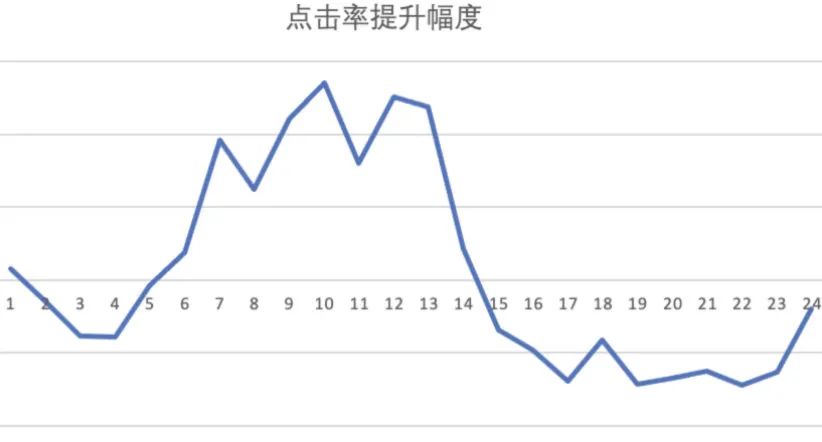
仅仅进行参数冻结也不能完全解决灾难性遗忘的问题,仅仅是以牺牲学习能力来换取稳定性。即使采用了参数冻结后,我们依然发现了问题:模型的效果在一天内并不稳定。如下图所示,实验组的效果上午好,下午差,下图为一天内对照组的点击率提升幅度(对照组 CTR-实验组 CTR)。虽然一天内平均后总体向好,但是这并不是我们期望的结果。
考虑到前面介绍的,一天内数据分布变化极大,模型确实存在 “学了上午,忘了下午” 的情况,所以我们添加了样本回放功能,即从昨天的样本中根据一定策略,选取部分离线样本,与在线实时样本一起给模型进行增量训练。离线样本的选取策略为:过去一天当前小时以后的样本(即~{YYYYMM(DD-1)23}的样本)进行采样,与实时样本按照一定比例混合。
之所以采用这样的策略,是考虑到样本回放主要是让模型不要仅仅“着眼于当下”,还要考虑“未来的数据分布”。比如现在是下午 1 点,那实时样本都是 1 点左右的样本,而 1 点之前的样本模型已经训练过了,但是模型不知道 1 点之后的数据会是什么样子。所以我们就从昨天的样本中选取 1 点之后的样本加入进去。
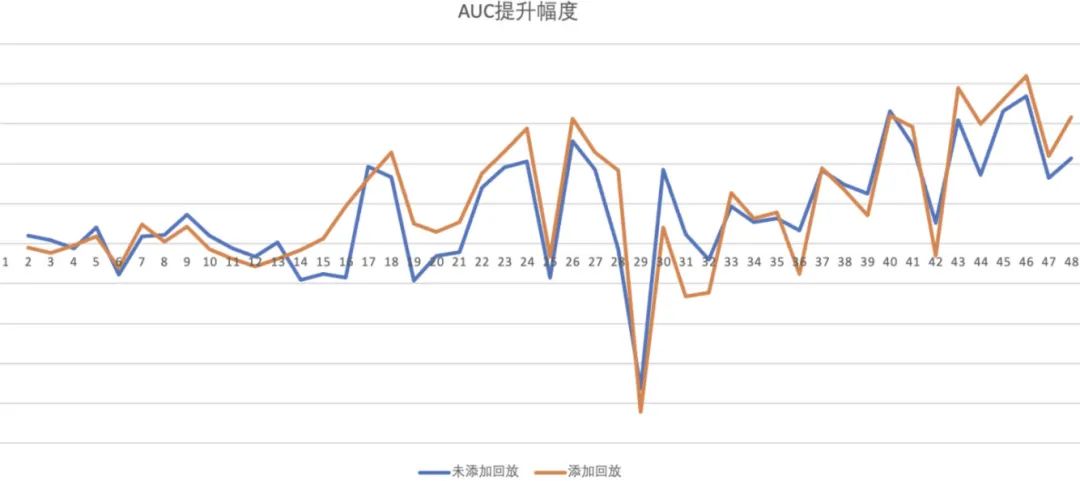
下图为 AUC 提升幅度对比图,蓝色线为仅冻结参数未添加回放,橙色线为冻结参数+样本回放。可见添加样本回放后,模型的效果进一步提升,AUC 相对离线模型平均提升约 0.001。
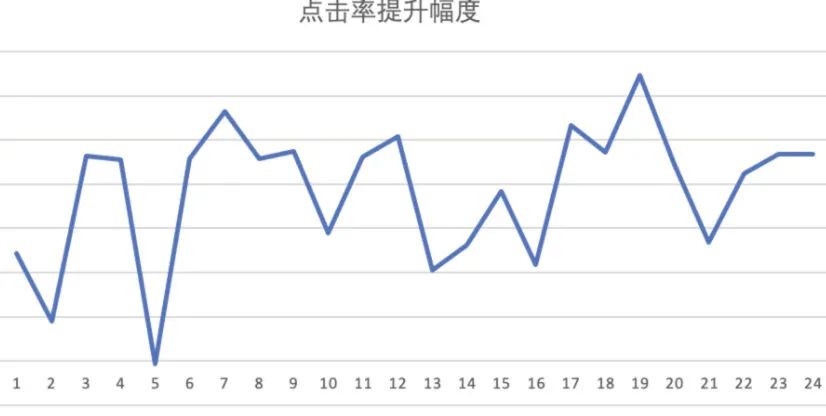
另外多日的线上的 AB 实验显示,加入样本回放后线上点击率相对提升 3%-6%,而且成功解决了前面提到的,模型效果在一天内“上午好,下午坏”的灾难性遗忘问题。下图为优化后对照组的点击率提升幅度(对照组 CTR-实验组 CTR)。
蒸馏学习
前面提到的两种方法中,参数冻结需要牺牲模型学习能力,样本回放需要牺牲样本的实时性(因为混入了早期离线样本),都涉及到一种权衡取舍。我们的最终目的无非是希望模型能够在学习的过程中“不要忘本”,不要忘记那个“最初的自己”。而蒸馏学习正好可以用 teacher 模型来影响 student 模型,让其学习 teacher 模型的信息,这与我们的目的不谋而合。
我们采用离线模型作为 teacher,实时训练模型作为 student,在 loss 上除了 student 的 Logloss 损失,添加了 teacher 与 student 之间的交叉熵损失,两个损失的权重比为 1:0.2,目的就是让 student 模型不要离 teacher“太远”。
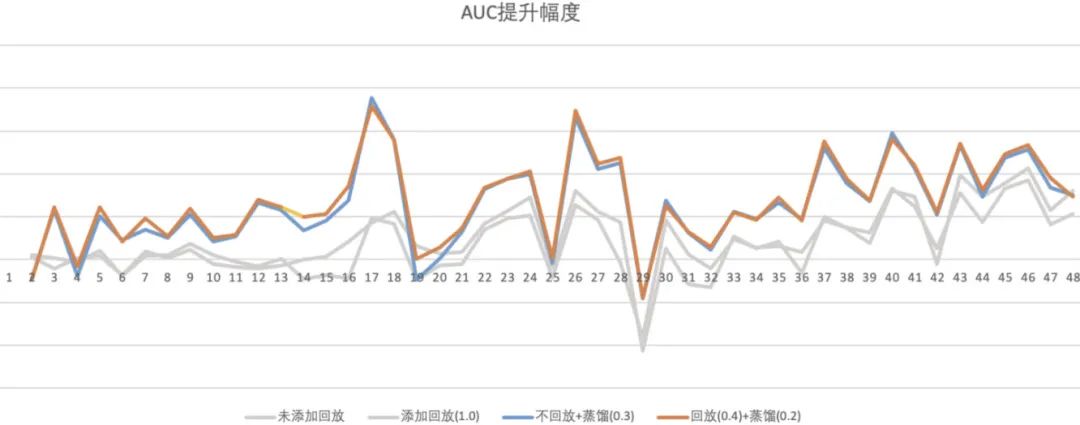
下图为蒸馏学习的离线实验效果对比图,纵轴为 AUC 提升幅度(对照组 AUC-实验组 AUC),横轴是小时。两个灰色线是前面提到的参数冻结和样本回放的效果,蓝色线和橙色线是蒸馏学习的实验结果。可见蒸馏学习的效果提升十分显著,平均 AUC 提升 0.0025 以上(不放回蒸馏 0.0025+,放回蒸馏 0.0027+)。
灵魂拷问
AUC 与 CTR 关系?
在模型优化过程中,我们曾遇到过**AUC 很高(或提升很多)但 CTR 效果不理想;或 AUC 提升幅度不大,但 CTR 提升幅度很大的情况,这是为什么呢?**想要回答这个问题,我们先来看 AUC 与 CTR 的关系。
引入 Base AUC前面提到我们的特征中包含 User 特征、Item 特征、Scene 特征和交叉特征,而广告系统的任务就是为了从广告库中选取最合适的 Item 进行展示。也就是说,如果我们把 Item 特征和交叉特征删掉,pCTR 的预估就完全不会考虑 Item 相关的信息,仅仅是给用户的“点击习惯”打个分而已。理论上这种情况下的点击率与随机推荐的点击率是相同的,因为对于每个 Item 都是相同的 ECPM(假设不考虑 pCVR、pLTV 等其他环节的影响)。
但是实际上这种情况下,因为模型中还有大量 User 特征和 Scene 特征,模型的 AUC 依然不等于 0.5(实际上依然很高,假设能达到 0.78)。说明从 0.5->0.78 这么多的 AUC 提升,其实对于 CTR 的提升没有半毛钱直接作用,因为模型只能对多个请求之间进行排序,而点击率提升需要模型对一个请求内部的多个 Item 进行排序。这种情况模型的主要作用应该是降低了偏差,我们称这时的 AUC 为 Base AUC。
AUC 提升的效果
AUC 的提升与线上 CTR 的效果并不是线性的。一般在项目初期,AUC 的提升很容易,但对 CTR 的贡献一般会很小。因为这种情况下的提升,一般主要是靠 User 侧的特征撑起来的,关于 Item 侧以及交叉特征的贡献相对较小。这个阶段的优化,对 PV 间的排序优化比较明显,但是对 PV 内的排序优化不大。
而在达到了 Base AUC 之后,AUC 再想继续提升,难度会很大,但是对 CTR 的贡献会非常明显,可能 AUC 提升 0.0001 就可以给 CTR 带来收益了。因为这时的提升主要是靠交叉特征,以及模型深度挖掘用户偏好带来的,这部分提升可以直接作用在一个 PV 内部。
关于 GAUC
有同学肯定了解过《Optimized Cost per Click in Taobao Display Advertising》中提出的 GAUC 指标,这个指标就是为了解决前面提到的 PV 内/PV 间的问题,该指标其实就是针对每个用户的行为算一个 AUC,然后把所有用户的 AUC 算一个加权平均:
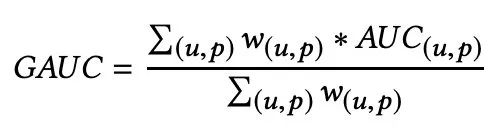
同样的道理,我们也构造了一个 Session GAUC,即把每一个 PV 上(满足同一用户、同一媒体、同一广告形式内)的曝光行为算一个 AUC,最后加权平均,但是我们遇到了一个问题。
在淘宝的场景中,一个用户的行为可能相对更长,而且不会与其他广告主进行竞争,不涉及“竞得”的问题,所以单个用户也可以有足够的曝光点击次数来计算 AUC。

但是在联盟广告场景下,我们只有成功曝光情况下才能收集到曝光样本(我们无权拿到用户在媒体 APP 上其他行为的数据,只能拿到广告相关曝光、点击等数据),而且由于存在外部竞争以及内部的底价过滤等策略的影响,我们有大量广告请求无法成功展示,每个用户的平均曝光、点击次数非常少。如果想要达到能够计算 AUC 的要求(至少 2 次曝光,且至少 1 次点击),绝大多数的用户都被过滤了。剩余的用户中,也是绝大多数只有 2 次曝光和 1 次点击的边界情况。这种情况下计算得到的 AUC 代表性极差,用少量曝光行为计算的 AUC 来代表该用户的效果,用少数行为丰富的用户效果来代替整体大盘的用户效果。结果就是大部分的用户都“被代表”了。
所以在联盟广告的场景下,GAUC 的思路并不合适。实际上只要 AUC 突破了一个门槛(即类似前面提到的 Base AUC),将 User 特征和 Scene 特征压榨干净,后续的 AUC 提升与 CTR 的提升是有很强的正相关的。所以我们大可放心继续使用 AUC 这个指标,只是在项目初期要清楚,前期的 AUC 提升主要效果是降 bias,而不是提升 CTR。
偏差与 CTR 的关系?
前一节介绍了 AUC 和 CTR 的关系,但实际上影响 CTR 的还有偏差。完全有可能在 AUC 不变的情况下,通过优化偏差来提升 CTR,这是为什么呢?
偏差本身和 CTR 没有直接关系,但是在竞价环境下,偏差可以影响我们竞得的流量质量,从而影响整体 CTR。举个简单例子,偏差是高估的,我们就花了更多钱买来低价值(低点击率)的曝光,但是整体曝光量会上升,而点击率下降;偏差是低估的,我们就舍弃了一些 ECPM 在竞得门槛附近的的曝光,留下来的都是 ECPM 更高的曝光,所以曝光量下降,但整体 CTR 提升。所以本质上这其实是一个量与质的权衡,当然权衡的最佳状态当然是偏差为 0 最好。
AB 实验你真的会用么?
AB 实验中的设备分流与请求分流
在 AB 实验中,我们经常会需要选择根据设备分流还是请求分流。
如果按照设备分流,通常需要先做 AA 实验,确保 AB 两组没有天然的差异性(即 A 组用户天然就比 B 组用户更活跃等因素的影响)。而且这个差异性可能是随时间变化的,可能工作日的时候两组差异小,周末两组差异大。所以设备分流实验中,这个因素的影响通常是不可忽略的。
有的同学会认为如果用户量足够大,是不是就可以抹平两组间的天然差异? 答案是肯定的,但是所需要的用户量会比预想的大。举一个极端的例子,在广告中如果要做 ROI 的 AB 实验,由于付费行为本身非常稀疏,且付费金额分布极其偏态(少数几个用户可能付费几十万,绝大多数付费只是首充),即使你广告大盘有 1 个亿的设备数,真正经过竞价、曝光、点击、转化后可能只剩几千个,再算上付费的可能就几十个,而这几十个里面可能只有一两个付费超过 1000 的大 R。也就是说,虽然总体用户数很多,但是真正“有影响力的关键用户”会少很多。大盘用户量需要足够大到足以使“关键用户”足够多,才能抹平 AB 两组的差异,这通常比人们直观感觉中的量级要大。
相反如果按照请求分流,好处是 AB 两组绝对不会存在差异性(除非代码有 BUG),省去了 AA 实验的步骤,可以完全避免组间天然差异带来的影响。但是有些研究用户长期行为的实验(比如品牌实验),要求用户需要长期被分到同一个组中,就不适用请求分流,必须用设备分流。
AB 实验中的辛普森悖论
如果实验组每一天的 CTR 都更高,就说明实验组更好么?
答案是:不一定!设想这样一种情况,如果实验组模型对某个本来点击率就很高高的 Item(比如一个很火的新游戏,很好看的素材等等)产生了高估,那实验组中这个 Item(游戏/素材)的占比就会更高。那实验组的整体点击率就会更高。这并不是因为模型排序排的更准,而是模型更倾向于把“曝光机会”分配给优质的 Item。
所以我们在看 AB 实验结论的时候,还是要多留一个心眼,尝试下钻去看一看是否存在辛普森悖论造成的美好的假象。
以上是关于一文搞懂CTR建模的主要内容,如果未能解决你的问题,请参考以下文章