MCMC笔记:蒙特卡罗方法
Posted UQI-LIUWJ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MCMC笔记:蒙特卡罗方法相关的知识,希望对你有一定的参考价值。
0 前言:关于采样
0.1 采样的动机
1)采样可能本身就是任务
2)求和或者求积分

0.2 什么是好的样本?
1)样本趋向于高概率的区域
2)样本是相互独立的
0.3 采样是困难的
1)概率分布函数很复杂,导致采样困难
2)高维变量不易采样
1 介绍
蒙特卡洛方法(Monte Carlo Method):基于采样的随机近似方法。
该方法旨在求得复杂概率分布下的期望值:
其中zi是从概率分布p(z∣x) 中取的样本,也就是从概率分布中取N个点来近似计算这个积分。
但是,由于p(z∣x) 比较复杂,所以有的时候我们可能不知道应该怎么采样。
注:这里的z|x,有些地方直接写成z,表示的是一个意思
2 采样方法
2.1 概率分布采样
- a.求得概率密度函数PDF的累计密度函数CDF
- b.求CDF的反函数
- c.在0-1之间均匀取样,带入反函数,得到取样点
以上图为例,左图为概率密度函数,右图为相应的累计密度函数(也就是从负无穷到相应点的概率密度函数的累加和)
不难发现累计密度函数的取值范围是[0,1]。同时 因为均匀分布易于采样,所以我们可以从均匀分布U(0,1)之间随机采样,采样的点作为cdf的值域,找到相应的x。这些x就是我们的样本点。
换一种思路考虑就是,pdf大的位置,cdf“上升”得快,那么“占据”值域的区间就长,随机取样后就更易于停留在这些值域上,那么对应位置的x被采样到的概率也就比较大。

但是,大部分PDF很难求得CDF。。。
2.2 拒绝采样
对于较复杂的概率分布 p(z) ,引入简单的提议分布(proposal distribution)q(z),使得对任意的
,然后对q(z) 进行采样获得样本。
这里的M是一个常数,因为如果没有M的话p和q都是概率密度函数,那么概率密度函数的积分恒为1,所以不可能一个恒大于另一个的。
人为构造的q需要是一个采样容易的分布。

以上图为例(上图的k就是我们前面说的M ),如果落在白色的区域,那么这个点可以选取,如果落在阴影区域,那么这个点不能选取。
这个的意思就是是否落在白色区域内
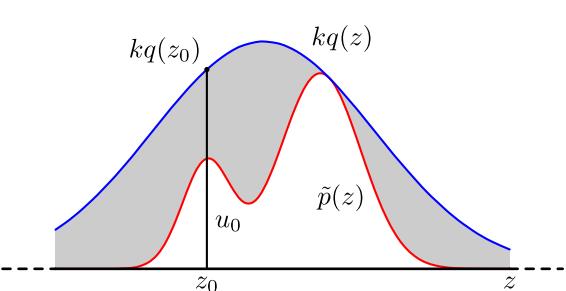
优点:容易实现
缺点:采样效率可能不高如果p(z)的涵盖体积占Mq(z)的涵盖体积的比例很低,就会导致拒绝的比例很高,抽样效率很低。
一般在高维空间抽样,会遇到维度灾难的问题,即使p(z)与Mq(z)很接近,两者涵盖体积的差异也可能很大。
2.3 重要性采样
不对z采样,直接对他的期望进行采样
于是在q(z)中采样,并通过权重计算和。

缺点:权重⾮常⼩的时候,效率非常低
2.4 Sampling Importance Resampling
这种方法,首先和上面⼀样进行采样,然后在采样出来的N个样本中,重新采样,这个重新采样,使⽤每个样本点的权重作为概率分布进行采样。
参考资料:机器学习-白板推导系列(十三)-MCMC(Markov Chain Monte Carlo)_哔哩哔哩_bilibili
以上是关于MCMC笔记:蒙特卡罗方法的主要内容,如果未能解决你的问题,请参考以下文章