业务数据全用上也喂不饱AI?试试这个小样本学习工具包
Posted QbitAl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了业务数据全用上也喂不饱AI?试试这个小样本学习工具包相关的知识,希望对你有一定的参考价值。
项目作者 | 王雅晴
量子位 编辑 | 公众号 QbitAI
引言
机器学习在数据密集型的应用中取得了极佳的效果,但在数据集很小的场景下,多数机器学习算法的效果会严重受限[1]。在计算机视觉、自然语言处理等大领域下,从深度学习最初大放异彩的图像分类、文本分类,到进一步的图像生成、文本关系预测,机器学习算法取得的成就大多建立在大量数据驱动的训练算法之上。然而,高质量的标注数据在大多数领域都是很难获得的,这限制了诸多机器学习算法在相应场景下的应用能力。
在这样的背景下,小样本学习(Few Shot Learning, FSL)的提出将解决数据集规模严重受限条件下的机器学习应用问题。小样本学习方法可以在利用先验知识的前提下,仅由极少量受监督的样本,使模型通过极少步的更新快速提升泛化性能,以应用在新的相关任务上[1]。近年来,小样本学习已经应用于计算机视觉、自然语言处理、人机交互、知识图谱乃至生物计算等领域的诸多应用中。
小样本学习的研究者在编码实践过程中通常会面临原型实现和方法复现两方面的问题[2]。为了方便飞桨开发者和使用飞桨的科研人员方便地执行以下操作:
在深度学习模型上应用经典的小样本学习方法,或使用经典小样本数据集测试模型与方法
设计新的小样本学习方法,或构建新的小样本数据集
比对各种小样本学习方法在多种数据集上的效果
我们开发了PaddleFSL(Paddle toolkit for Few Shot Learning):基于飞桨的小样本学习工具包,旨在降低小样本学习研究和应用的设计与时间成本。PaddleFSL提供了低层次的工具函数与接口,以供使用者设计新的小样本学习方法或构建新的小样本学习数据集,同时也提供了经典小样本学习方法的高层次实现,以及经典的小样本数据集。
项目链接:
https://github.com/tata1661/FSL-Mate/tree/master/PaddleFSL
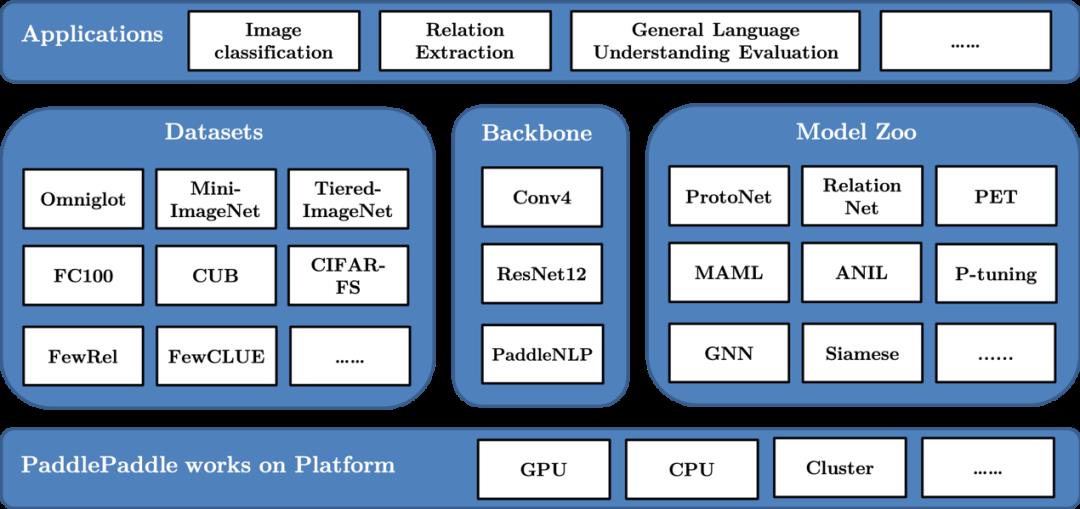
框架概览
PaddleFSL完整项目包含了以下几个部分:
样例(examples):
项目中高层次小样本算法接口的使用样例
包主体(paddlefsl):
python包的主体
paddlefsl.backbones:
诸如MLP、卷积网络、ResNet等基准模型paddlefsl.datasets:
小样本数据集构建接口,以及诸多经典的小样本数据集的预处理实现paddlefsl.model_zoo:
高层次经典小样本方法实现paddlefsl.task_sampler:
任务集的划分:
将训练和测试数据划分为N ways, K shots以及Q query pointspaddlefsl.utils:
与环境、输入输出或模型参数有关的工具函数
数据文件(raw_data):
存放原始数据文件的目录,附各个经典小样本数据集的介绍与下载地址
测试(test):
包主体每一函数和类的单元测试,同时也是使用样例文件
此外,在包主体的每一个外部接口处,我们都提供了翔实的注释,包括了模块的功能、参数的功能和使用样例。
在接下来的几个章节中,我们将从数据集加载到训练完成,逐项介绍PaddleFSL的功能及其使用方法。
安装与测试
本项目依赖飞桨开源框架v2.0或更新的版本,需要提前前往飞桨官网安装。
本项目在github开源,可以直接克隆github项目,配置环境变量后直接使用:
# 克隆项目
git clone https://github.com/tata1661/FSL-Mate.git
# 安装依赖
cd FSL-Mate/PaddleFSL
pip install -r requirements.txt
# 修改env.sh,将其中的路径设置为PaddleFSL所在路径
# 随后激活环境变量
source env.sh
# 若希望长期使用本项目,可以将修改后的env.sh内容追加到.bashrc文件
cat env.sh >> ~/.bashrc
source ~/.bashrc本项目也同时在pypi发布,可以通过更便捷的pip安装包主体(paddlefsl),但这种方式不包含样例(examples)、数据文件(raw_data)与测试文件(test):
pip install paddlefsl安装完成后,可以通过以下的指令快速测试安装是否成功:
# 启动一个python解释器
python
>>> import paddlefsl
>>> paddlefsl.__version__
'1.0.0'数据集
我们的项目提供了计算机视觉数据集(CVDataset)和关系分类数据集(RCDataset)两种模板数据集接口,以及继承自CVDataset的六种图像分类数据集(Omniglot[3], Mini-ImageNet[4], Tiered-ImageNet[5], CIFAR-FS[6], FC100[7], CU-Birds[8])与继承自RCDataset的一种关系分类数据集(FewRel1.0[9])。此外,我们还提供了中文自然语言处理小样本领域的评测基准数据集FewCLUE[15]。
以Mini-ImageNet为例,若要使用该数据集,仅需从项目提供的地址下载原始数据文件(mini-imagenet.tar.gz),并将其放置在raw_data目录下,包主体代码会自动解压并处理数据文件:
# python代码
from paddlefsl.vision.datasets import MiniImageNet
# 训练数据集,使用默认的numpy模式,数据集返回的格式是numpy数组
training_set = MiniImageNet(mode='train')
image, label = training_set[0]
print(image) # 打印出一个numpy数组
# 验证数据集,使用pil模式,数据集返回的格式是pil图像
validation_set = MiniImageNet(mode='valid', backend='pil')
image, label = validation_set[0]
image.show() # 拥有图形界面的系统会显示一只鸟的图像用户也可以将原始数据文件放置在任意一个有权限的目录下,并将该目录通过root参数传递给数据集。
在小样本学习的框架下,数据集常被划分为N ways(一个任务中有N种类别的样本待分类)、K shots(K个有标签的样本用于模型更新)和Q query points(Q个有标签的样本用于模型效果的评估或进一步更新),因而本项目在数据集类中预置了随机任务集划分:
# 划分一个任务:task是paddlefsl.task_sampler中TaskSet类的实例
task = training_set.sample_task_set(ways=5, shots=5)
# 返回shape为(25, 3, 84, 84)的numpy数组,25代表了任务中5个类(5 ways)每类5个样本(5 shots)
print(task.support_images.shape)而在关系分类数据集(RCDataset)中,返回值的类型有text(文本)和numpy(numpy数组)两种可选项,若选择numpy则需要为数据集传入一种初始化器:
from paddlefsl.datasets import FewRel
from paddlefsl.backbones import RCInitVector
# 选择基于wiki语料库的GloVE词向量作为文本初始化
init_vector = RCInitVector('glove-wiki')
# 训练数据集,使用默认的numpy模式,传入文本初始化器
train_dataset = FewRel(mode='train', max_len=100, vector_initializer=init_vector)
print(train_dataset[0]) # 一个numpy数组和一个关系标签
valid_dataset = FewRel(mode='valid', backend='text')
print(valid_dataset[0]) # 一个语句、关系头、关系尾和一个关系标签此外,用户可以直接通过继承CVDataset和RCDataset构建自己的数据集:根据用户自己的原始数据文件格式,在新的数据集类中实现获取元素、数据集长度、划分随机任务集三个接口,即可构建新的小样本数据集。用户也可以直接效仿本项目给出的原始数据格式,将新数据的数据格式调整后,直接通过传递root参数给已有的数据集,从而更便捷地构建新数据集。
经典小样本方法的高层次接口
我们的项目在paddlefsl.model_zoo中提供了五种经典的小样本方法的高层次接口(MAML, ANIL, ProtoNet, RelationNet, Siamese),以及三种小样本NLP方法的直接实现(PET[16], P-Tuning[17], EFL[18])。
MAML(Model-Agnostic Meta-Learning)是一种经典的,可应用于任何使用梯度下降训练的模型,并可以适用于包括分类、回归、强化学习等多种任务的小样本学习方法。MAML不引入新的模块,仅使用先验知识调整目标模型的参数,使之具备出色的泛化性能,可以在很有限的几步梯度下降之后快速学习适应新任务[10]。
ANIL(Almost No Inner Loop)是一种针对MAML算法的分析与改进。MAML算法对于目标模型的参数在外层循环(outer loop)与内层循环(inner loop)都进行了调整,而ANIL则在内层循环固定了模型的主体部分参数,仅对最后一层进行微调(fine-tune)。该方法使用更少的计算开销得到了与MAML同样好的效果,并同时证明了MAML的方法让模型取得了特征复用(feature reuse)的效果[11]。
ProtoNet(Prototypical Networks)是一种更为经典的、简单有效的小样本方法。它利用极少的带标签样本,让模型学得另一个参数空间的原型特征(prototype),然后比对待分类样本的原型特征和已知类别原型特征的距离,从而做出分类决策。该方法思路简单,计算复杂度低,且在分类问题上有着非常不错的表现,并且可以延伸至零样本学习(zero-shot learning)[12]。
RelationNet(Relation Network)是一种在ProtoNet基础上的提升改进。在使用目标模型学习到另一个参数空间的原型特征后,该方法增加了一个关系网络(relation network)用以专门学习比较待分类样本原型特征和已知类别原型特征的相似性,而不需要重新调整已知网络[13]。
Siamese (Siamese Networks)是一种早期的小样本学习方法。该方法设计了一种孪生结构,很自然地学习如何更好地度量输入内容的相似度,从而使用极少的标签样本来获得预测新样本的能力[14]。
我们在paddlefsl.model_zoo中实现了上述五种算法的完整的训练和测试逻辑。以MAML为例,用户仅需传入待测数据集和相关的算法超参和训练配置,即可直接开始训练或测试,并自动保存训练得到的模型参数:
import paddle
import paddlefsl
from paddlefsl.model_zoo import maml
# MAML, Mini-ImageNet, Conv, 5 Ways, 1 Shot
TRAIN_DATASET = paddlefsl.datasets.MiniImageNet(mode='train')
VALID_DATASET = paddlefsl.datasets.MiniImageNet(mode='valid')
TEST_DATASET = paddlefsl.datasets.MiniImageNet(mode='test')
MODEL = paddlefsl.backbones.Conv(input_size=(3, 84, 84), output_size=5)
def main():
train_dir = maml.meta_training(train_dataset=TRAIN_DATASET,
valid_dataset=VALID_DATASET,
ways=5,
shots=1,
model=MODEL,
meta_lr=0.002,
inner_lr=0.03,
iterations=10000,
meta_batch_size=32,
inner_adapt_steps=5,
report_iter=10)
if __name__ == '__main__':
main()此外,我们还在样例(examples)中提供了PET[16]、P-Tuning[17]和EFL[18]在FewCLUE任务上的实现。FewCLUE的任务将额外地依赖paddlenlp包,其实现过程中使用了百度的中文NLP预训练模型ERNIE1.0,并汇报了三种算法的效果。
我们利用本项目实现的经典算法高层次接口测试了所有数据集上的效果,并与原论文或其他论文复现的效果做了比对。结果显示,我们的实现均达到了原论文方法使用其他机器学习框架汇报的结果,在多数任务上提升了原有的效果。具体的结果数据在样例(examples)中给出(https://github.com/tata1661/FSL-Mate/tree/master/PaddleFSL/examples)
低层次常用工具函数
除了完整的训练和测试实现接口外,本项目还提供了丰富的低层次工具函数,用以实现常用的小样本学习基本操作,例如原型特征(prototype)的计算、模型的克隆(clone)、固定步长的单步梯度下降等等。

原型特征的计算和比较由ProtoNet提出(如上图),因此该功能在paddlefsl.model_zoo.protonet中封装并提供接口get_prototype()。该函数传入所有带标签样本的特征,以及其对应的标签,即可返回按标签顺序排列的各个类别对应原型特征。以RelationNet为例:
...
# 获取一个任务集
task = dataset.sample_task_set(ways=ways, shots=shots, query_num=query_num)
# 利用task_sampler将任务集的数据转化为paddle.Tensor
task.transfer_backend('tensor')
# 计算support数据和query数据的特征
support_embeddings = embedding_model(task.support_data)
query_embeddings = embedding_model(task.query_data)
# 调用原型特征函数,获取按标签顺序排列的各个类别对应原型特征
prototypes = protonet.get_prototypes(support_embeddings, task.support_labels, ways, shots)
# 使用关系网络计算query数据特征与原型特征的相似度
relation_score = relation_model(prototypes, query_embeddings)
...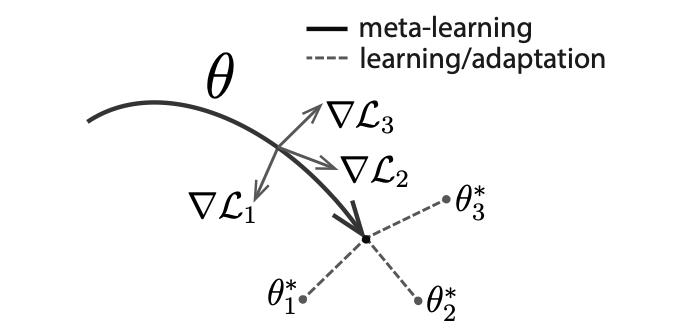
模型的克隆和单步梯度下降是MAML及其改进型ANIL所依赖的操作。该方法不引入其他模块,仅仅通过梯度对目标模型做调整,目标模型的参数将被通过外层循环和内层循环两次调整。在内层循环中,对于模型的调整不可以直接作用于原目标模型的所有参数,而是需要累积多个任务的梯度,最终对原模型加以调整,这就要求模型的梯度保留,最上层微调,而主体部分参数在累积后再做调整(如上图)。
因此,我们引入了模型克隆(clone)的功能:与机器学习框架中张量的克隆相同,被克隆的新模型并不与原模型共享内存,从而实现独立的调整,但同时要和原模型共享计算图,从而实现梯度的关联与累积。该功能在paddlefsl.utils中封装为接口clone_model():
import paddlefsl.utils as utils
# 训练一个简单的分类器
train_data = paddle.to_tensor([[0.0, 0.0], [1.0, 1.0]], dtype='float32')
train_label = paddle.to_tensor([0, 1], dtype='int64')
test_data = paddle.to_tensor([[0.99, 0.99]], dtype='float32')
model = paddle.nn.Linear(2, 2)
loss_fn, opt = paddle.nn.CrossEntropyLoss(), paddle.optimizer.Adam(parameters=model.parameters())
for epoch in range(100):
predict = model(train_data)
loss = loss_fn(predict, train_label)
loss.backward()
opt.step()
# 训练好的模型可以进行0-1分类
print(model(test_data))
# 使用utils.clone_model()实现模型的克隆
model_cloned = utils.clone_model(model)
# 克隆后的模型获取了原模型参数的内容,同样可以进行简单的0-1分类
print(model_cloned(test_data))同样是在基于梯度的MAML与ANIL方法中,由于模型主体参数梯度累积后调整与微调最上层的矛盾,在内层循环的微调中不可以直接使用模型的优化器进行梯度下降,而应该手动设置固定的步长(inner_loop_learning_rate)进行不干预优化器的梯度下降。该功能封装在paddlefsl.utils中,提供接口gradient_descent():
import paddlefsl.utils as utils
# 训练一个简单的分类器
train_data = paddle.to_tensor([[0.0, 0.0], [1.0, 1.0]], dtype='float32')
train_label = paddle.to_tensor([0, 1], dtype='int64')
test_data = paddle.to_tensor([[0.99, 0.99]], dtype='float32')
model = paddle.nn.Linear(2, 2)
loss_fn, opt = paddle.nn.CrossEntropyLoss(), paddle.optimizer.Adam(parameters=model.parameters())
for epoch in range(100):
predict = model(train_data)
loss = loss_fn(predict, train_label)
loss.backward()
opt.step()
# 训练好的模型可以进行0-1分类
print(model(test_data))
# 使用utils.clone_model()实现模型的克隆
model_cloned = utils.clone_model(model)
# 克隆后的模型获取了原模型参数的内容,同样可以进行简单的0-1分类
print(model_cloned(test_data))除了举例的三种低层次操作接口外,paddlefsl还提供了更多丰富的工具函数。用户可以在源码或样例中查看并体验(https://github.com/tata1661/FSL-Mate/tree/master/PaddleFSL/paddlefsl/utils)
小样本学习资源库

PaddleFSL代码整合在小样本学习综述与前沿论文追踪项目FSL-Mate中共同开源发布。FSL-Mate项目是一个旨在整合小样本学习研究成果与最新研究进展的资源仓库,该项目基于王雅晴博士于2020年6月发表在ACM Computing Surveys (CSUR)上的小样本学习综述文章Generalizing from a few examples: A survey on few-shot learning扩展而来。CSUR是计算机领域权威顶刊,JCR1区,Core A* ,该小样本学习综述为CSUR 2019-2021年间最高引论文,也是ESI 2021高引论文。我们将持续更新和维护该仓库,携手对小样本学习感兴趣的开发者和研究人员,共同推进小样本学习领域的发展,敬请关注与下载体验!
欢迎大家点开Github链接学习源码或获取工具包!
项目链接:
https://github.com/tata1661/FSL-Mate/tree/master/PaddleFSL
(另外,链接内附赠高质量领域理解手册【小样本学习综述】 ESI 2021高引论文 / CSUR 2019-2021 最高引论文)
项目作者:
王雅晴,PaddleFSL负责人、飞桨高级开发者技术专家(高级PPDE)。2019年博士毕业于香港科技大学计算机科学及工程学系。通过百度公司AIDU计划加入百度研究院商业智能实验室,现任资深研发工程师及研究员。研究方向为机器学习,并主要聚焦小样本学习、稀疏和低秩学习、生物计算等方向。现有多篇一作成果发表在ICML、NeurIPS、WWW、EMNLP、TIP等顶会顶刊上。
参考文献:
[1] Wang Y, Yao Q, Kwok J T, Ni L M. Generalizing from a few examples: A survey on few-shot learning[J]. ACM Computing Surveys (CSUR), 2020, 53(3): 1-34.
[2] Arnold S M R, Mahajan P, Datta D, et al. learn2learn: A library for meta-learning research[J]. arXiv preprint arXiv:2008.12284, 2020.
[3] Lake B M, Salakhutdinov R, Tenenbaum J B. Human-level concept learning through probabilistic program induction[J]. Science, 2015, 350(6266): 1332-1338.
[4] Vinyals O, Blundell C, Lillicrap T, et al. Matching networks for one shot learning[J]. Advances in neural information processing systems, 2016, 29: 3630-3638.
[5] Ren M, Triantafillou E, Ravi S, et al. Meta-learning for semi-supervised few-shot classification[J]. arXiv preprint arXiv:1803.00676, 2018.
[6] Bertinetto L, Henriques J F, Torr P H S, et al. Meta-learning with differentiable closed-form solvers[J]. arXiv preprint arXiv:1805.08136, 2018.
[7] Oreshkin B N, Rodriguez P, Lacoste A. Tadam: Task dependent adaptive metric for improved few-shot learning[J]. arXiv preprint arXiv:1805.10123, 2018.
[8] Wah C, Branson S, Welinder P, et al. The caltech-ucsd birds-200-2011 dataset[J]. 2011.
[9] Han X, Zhu H, Yu P, et al. Fewrel: A large-scale supervised few-shot relation classification dataset with state-of-the-art evaluation[J]. arXiv preprint arXiv:1810.10147, 2018.
[10] Finn C, Abbeel P, Levine S. Model-agnostic meta-learning for fast adaptation of deep networks[C]//International Conference on Machine Learning. PMLR, 2017: 1126-1135.
[11] Raghu A, Raghu M, Bengio S, et al. Rapid learning or feature reuse? towards understanding the effectiveness of maml[J]. arXiv preprint arXiv:1909.09157, 2019.
[12] Snell J, Swersky K, Zemel R S. Prototypical networks for few-shot learning[J]. arXiv preprint arXiv:1703.05175, 2017.
[13] Sung F, Yang Y, Zhang L, et al. Learning to compare: Relation network for few-shot learning[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 1199-1208.
[14] Koch G, Zemel R, Salakhutdinov R. Siamese neural networks for one-shot image recognition[C]//ICML deep learning workshop. 2015, 2.
[15] Li Y, Zhao Y, Hu B, et al. GlyphCRM: Bidirectional Encoder Representation for Chinese Character with its Glyph[J]. arXiv preprint arXiv:2107.00395, 2021.
[16] Liu, Xiao, Yanan Zheng, Zhengxiao Du, Ming Ding, Yujie Qian, Zhilin Yang, and Jie Tang. “GPT Understands, Too.” ArXiv:2103.10385 [Cs], March 18, 2021.
以上是关于业务数据全用上也喂不饱AI?试试这个小样本学习工具包的主要内容,如果未能解决你的问题,请参考以下文章
arcpy地理处理工具案例教程-生成范围-自动画框-深度学习样本提取-人工智能-AI
2021综述论文《小样本/GNN/深度学习/机器学习/知识图谱/NLP/CV》大集合