Yarn整体架构,客户端编程
Posted Leo Han
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Yarn整体架构,客户端编程相关的知识,希望对你有一定的参考价值。
YARN(Yet Another Resource Negotiator)是hadoop生态中重要的组成部分,一种资源管理调度系统,官方给出的整体架构和交互如下:
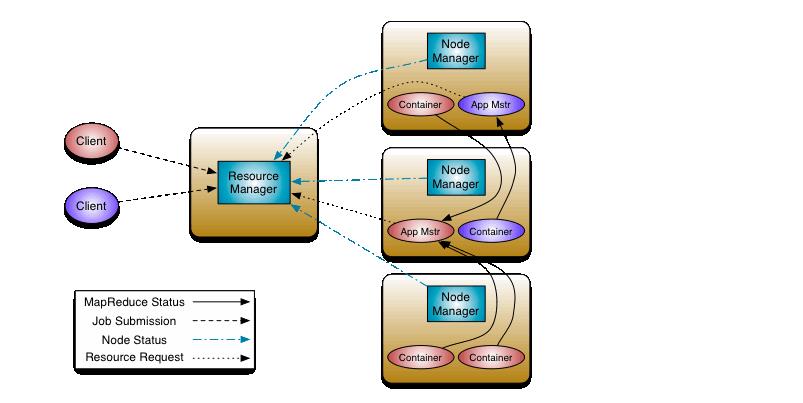
- Container
首先说明一下Container这个概念,方便后续的展开说明。YARN是一个资源管理框架,在YARN中将资源抽象成Container这个概念,YARN将CPU和内存资源抽象封装在Container中,在具体代码实现上org.apache.hadoop.yarn.server.nodemanager.containermanager.container.ContainerImpl实现了Container,其中的resource代表了具体的资源:
public abstract class Resource implements Comparable<Resource> {
@Public
@Stable
public static Resource newInstance(int memory, int vCores) {
Resource resource = Records.newRecord(Resource.class);
resource.setMemorySize(memory);
resource.setVirtualCores(vCores);
return resource;
}
...
}
另外,Container由NodeManager启动,并监控;ResourceManager调度Container
接下来聊聊YARN中的三个重要模块:ResourceManager、NodeManager、ApplicationMaster
- ResourceManager
整个YARN运行期间有且仅有一个RM(ResourceManager)(如果是HA,有两个,但是只有一个处于Active状态),RM负责整个YARN的资源管理和调度,主要有两个组件: -
- Scheduler:对提交到YARN中的应用根据不同的调度算法进行资源的分配,
-
- ApplicationsManager: 管理YARN中应用程序的app master,负责接收应用程序的提交、为appmaster启动提供资源、监控应用程序、出现故障时重启应用。
- NodeManager,NodeManager是在YARN中的每个节点上工作,可以理解为RM在单个节点的上一个代理,主要负责节点上资源管理,处理RM和APP Master来的命令
提交一个程序到YARN中的流程:“”
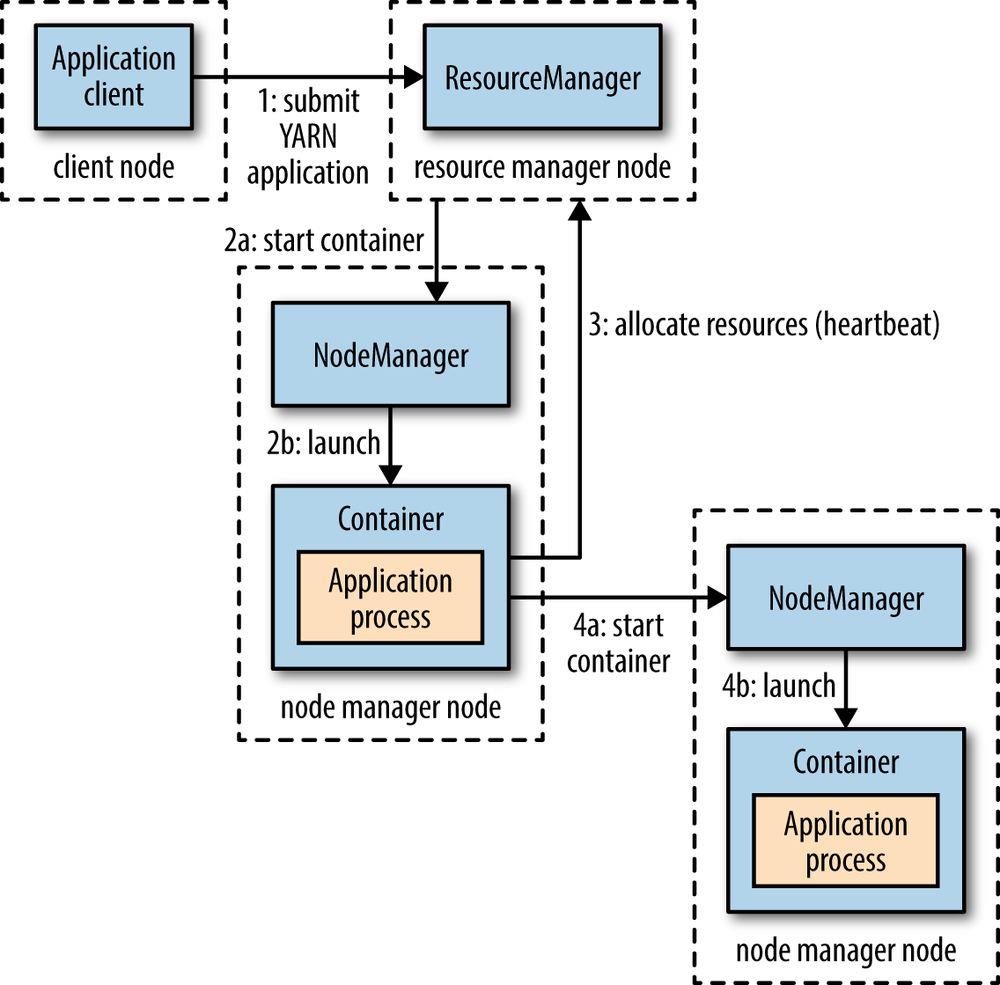
一个MapReduce作业提交流程如下:
-
作业提交
-
- 1.cleint提交作业到RM,获取到作业id(这里其实就是YARN中applicationId)
-
- 2.RM给client返回job资源的提交路径和作业id。
-
- 3.client提交jar包,切片信息和配置文件到指定的资源提交路径。
-
- 4.client提交资源后,向rm申请运行MrAppMaster
-
作业初始化
-
- 5.Rm收到client请求,将job添加到容量调度器。并分配给空闲的NM初始化job。
-
- 6.该NM创建container,并产生MrAppMaster,
-
- 7.DN下载client提交的资源到本地。
-
任务分配
-
- 8.MrAppmaster向Rm申请运行多个Maptask任务资源。
-
- 9.Rm将运行MapTask任务分配给另外的NodeManger,其他的NodeManger分别领取任务并创建容器。
-
任务运行
-
- 10.MR向接受到任务的NodeManger发送程序启动脚本。这两个NM分别启动MapTask,MapTask对数据分区排序。
-
- 11.MrAppmaster等所有Maptask执行完成之后,向RM申请容器启动ReduceTask。
-
- 12.ReduceTask向 MapTask获取相应分区的数据。
-
- 13.程序运行完毕后,MR会向RM申请注销⾃⼰
-
进度和状态更新
-
- 14.Yarn中的任务将其进度返回给应用管理器,客户端每秒(mapreduce.client.progressmonitor.pollinterval设置)向应用管理器请求进度更新,展示给用户。
-
作业完成
-
- 15.除了了向应用管理器请求作业进度外, 客户端每5秒都会通过调用waitForCompletion()来检查作业是否完成。时间间隔可以通过mapreduce.client.completion.pollinterval来设置
16.作业完成之后,应用管理器和Container会清理⼯作状态。作业的信息会被作业历史服务器存储以备之后⽤户核查。
- 15.除了了向应用管理器请求作业进度外, 客户端每5秒都会通过调用waitForCompletion()来检查作业是否完成。时间间隔可以通过mapreduce.client.completion.pollinterval来设置
YRAN作业调度器的主要三种:
1.FIFO:先进先出
2.Capacity Scheduler:容量调度器
3.FairScheduler:公平调度器
那么我们如何基于YARN提供的能力来实现类似MapReduce的程序呢 ?
Yarn给我们提供了实现上述功能的API,我们可以参考YARN官方给出的两个例子:
- hadoop-yarn-applications-distributedshell
- hadoop-yarn-applications-unmanaged-am-launcher
通过分析这两个项目,总结大致流程如下:
- 首先向RM注册,获取当前YARN相关信息:
YarnClientApplication app = yarnClient.createApplication();
GetNewApplicationResponse appResponse = app.getNewApplicationResponse();
然后通过GetNewApplicationResponse能够获取到当前YARN的最大cpu和memory:
int maxVCores = appResponse.getMaximumResourceCapability().getVirtualCores();
long maxMem = appResponse.getMaximumResourceCapability().getMemorySize();
- 构建
ApplicationSubmissionContext:
ApplicationSubmissionContext appContext = app.getApplicationSubmissionContext();
appContext.setApplicationName(appName);
ContainerLaunchContext amContainer = Records
.newRecord(ContainerLaunchContext.class);
appContext.setAMContainerSpec(amContainer);
Priority pri = Records.newRecord(Priority.class);
pri.setPriority(amPriority);
appContext.setPriority(pri);
appContext.setQueue(amQueue);
Resource amResource = Records.newRecord(Resource.class);
amResource.setMemory(Math.min(clusterMax.getMemory(), 1024));
amResource.setVirtualCores(Math.min(clusterMax.getVirtualCores(), 4));
appContext.setResource(amResource);
Map<String, LocalResource> localResourceMap = new HashMap<String, LocalResource>();
File appMasterJarFile = new File(appMasterJar);
localResourceMap.put(appMasterJarFile.getName(), toLocalResource(fs,appResponse.getApplicationId().toString(),appMasterJarFile));
amContainer.setLocalResources(localResourceMap);
StringBuilder cmd = new StringBuilder();
cmd.append("\\"" + ApplicationConstants.Environment.JAVA_HOME.$() + "/bin/java\\"")
.append(" ")
.append(appMasterMainClass)
.append(" ");
cmd.append("1>" + ApplicationConstants.LOG_DIR_EXPANSION_VAR + Path.SEPARATOR + ApplicationConstants.STDOUT)
.append(" ")
.append("2>" + ApplicationConstants.LOG_DIR_EXPANSION_VAR + Path.SEPARATOR + ApplicationConstants.STDERR);
amContainer.setCommands(Collections.singletonList(cmd.toString()));
Map<String, String> envMap = new HashMap<String, String>();
envMap.put("CLASSPATH", hadoopClassPath());
System.out.println(hadoopClassPath());
amContainer.setEnvironment(envMap);
appContext.setAMContainerSpec(clc);
- 提交任务:
ApplicationId appId = yarnClient.submitApplication(appContext);
- 查看任务情况,等待任务结束:
ApplicationReport report = client.getApplicationReport(appId);
while (report.getYarnApplicationState() != YarnApplicationState.FINISHED) {
report = client.getApplicationReport(applicationId);
LOG.info(String.format("%f %s", report.getProgress(), report.getYarnApplicationState()));
Thread.sleep(3000);
}
以上是关于Yarn整体架构,客户端编程的主要内容,如果未能解决你的问题,请参考以下文章