CTF逆向总结
Posted 若秀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CTF逆向总结相关的知识,希望对你有一定的参考价值。
目录
攻防世界的csaw2013reversing2:(运行乱码、int3断点考察、函数积累、不能直接运行)
攻防世界parallel-comparator-200:(.c文件、大小写字符转换算法、函数积累、相同异或为0算法积累、线程操作积累、不能直接运行)
攻防世界tt3441810:(实际TXT文件、不能直接运行、出人意料的flag、可打印字符过滤算法积累)
攻防世界open-source:(argv[]外部调用输入参数)
攻防世界Reversing-x64Elf-100:(函数逻辑封装、地址小端存放与正向、二维数组算法积累)
攻防世界EasyRE:(栈地址连续小字符串变量、栈中过渡变量反序字符串、/x7f截断字符串、运算符优先级注意)
攻防世界IgniteMe:(函数逻辑封装、大小写字符转换算法)
攻防世界notsequence:(杨辉三角算法、函数逻辑封装、IDA对char型(byte)的4*计数)
攻防世界Newbie_calculations:(非预期行为、不能直接运行、题目描述暗示、栈地址连续小数组、c语言写脚本、不同系统的特殊数、负数作循环条件)
攻防世界的no-strings-attached:(函数名称暗示,GDB动态调试,小端)
攻防世界answer_to_everything:(函数名称暗示、函数逻辑封装、出人意料的flag、题目描述暗示)
攻防世界secret-galaxy-300:(函数名称暗示、题目描述暗示、字符串拆分算法积累)
攻防世界simple-check-100:(IDA动态调试、GDB动态调试)
攻防世界re1-100:(函数逻辑封装、出人意料的flag、非预期行为)
攻防世界elrond32:(argv[]外部调用输入参数符合条件、函数逻辑封装、递归调用算法)
攻防世界dmd-50:(函数积累、地址小端存放与正向、涉及加密、出人意料的flag)
攻防世界crazy:(函数名称暗示、地址赋值算法积累、非预期行为、出人意料的flag)
攻防世界Mysterious:(地址小端存放与正向,出人意料的flag)
攻防世界流浪者:(多层交叉引用查看、函数逻辑封装、范围算法积累、函数积累)
攻防世界hackme:(可变参数混淆、随机抽取比较、取特定位数算法)
攻防世界Windows_Reverse1:(工具脱壳、不能直接运行、寄存器传参、地址差值+数组组合遍历字符串、字符ASCII码做索引、ASCII码表相关)
攻防世界Replace:(工具脱壳、解题逆向模板、>> 和 % 运算符算法积累、正向爆破)
攻防世界BABYRE:(函数名称暗示、IDA热键重新反汇编、IDA动态调试、栈地址连续小数组)
2021年10月广东强网杯,REVERSE的simplere:(迷宫结合、涉及加密、)
系统函数函数自修改:(HOOK,通常两次修改系统函数,一次改成自定义机器码,一次改回正常)
攻防世界EASYHOOK:(非预期行为、函数积累、手动机器码)
CTF 逆向总结
工具脱壳:
值传统的用工具压缩的文件,可以直接用工具来解压缩,即脱壳。
非预期行为:
指解题中出现与预想结果不符合的一系列非预期行为,这基本说明了在中间或前面存在其他自己还没分析的操作。
线程操作积累:
指解题代码中设计多线程的交叉,阻塞,共享内存等操作,由于线程知识积累较少,所以每次都要积累。
不同系统的特殊数:
指解题中遇到考察特定位数系统中特定的数的真实值的时候,需要辨认出对应的值才能继续解题。如:32位系统中100000000就是0了
题目类型总结:
题目描述暗示:
指题目给出的描述中有解题的大方向思路,以及对解题过程中出现的一些疑惑点的解释。
不能直接运行:
指解题中下载的附件无法正常运行,可能是对外界本机环境又要求,需要文件相关操作等。也可能是脱壳后地址混乱,需要修复导入表或梳理地址,还有可能是算法混淆,增加了运算时间。
游戏通关数生成flag:
指与游戏相关的可执行文件中,不是存储型flag,而是与用户输入相关的生成型flag,且以通关数生成flag。通常这种类型的题目改一下判断条件就可以全部通关获取flag了。
迷宫结合:
指解题过程中有类似于迷宫的每一步不能碰点或每一步必须符合在1维或多为字符串上的落点,如:*A**********.***.....**.....***.*********..*********B**
这称之为与迷宫结合类型。算法走迷宫过于耗时,通常整理出迷宫维数后手动来走。
汇编操作类总结:
int3断点考察:
int 3是断点的一种,代码执行到此次会抛出异常,因为这不是我们在OD之类的调试器下的断点,所以OD之类的调试器不会处理该断点的异常,而是交给系统处理,而系统的处理方式往往是强制退出。所以我们在动态调试中要改为nop,不然后面的代码就没法执行。
手动机器码:
指解题过程中遇到类似自修改代码的操作。
如HOOK原型:
byte_40C9BC = 0351;
dword_40C9BD = (char *)sub_401080 - (char *)lpAddress - 5; ;跳转到sub_401080地址处
这样写是因为汇编语言JMP address被编译后会变成机器指令码,E9 偏移地址,偏移地址=目标地址-当前地址-5(jmp和其后四位地址共占5个字节)。所以前面直接用E9,这里直接用偏移地址就省去编译生成机器码那一步。
ASCII码表类总结:
字符ASCII码做索引:
指解题中遇到如:*v1 = byte_402FF8[(char)v1[v4]]; 之类的字符做数组索引的表达式。
其中v1[v4]逐个取input_flag的单个字符,这个字符的ascii码作为偏移继续在byte_402FF8[]数组中寻址。(PS:这不是Python中list.index()函数可以用字符查找对应索引!)
ASCII码表相关:
指解题中遇到.data数据节中跟踪变量数组时显示的有大量0FFh这种不可识别字符后又有连续的可打印字符。
因为ASCII编码表里的可视字符就得是32往后了, 所以凡是位于32以前的数统统都是迷惑项,都会被显示成0FFh甚至乱码,不会被索引到的。然后后面32之后就有连续的字符串,这种就是ASCII码表。
逆向、脚本类总结:
解题逆向模板:
第一步确定Flag字符数量,第一个红框处得到flag数量是35。
第二步找到已确定的比较字符串作为基点来反推flag字符。
第三步找出逻辑中与flag直接相关的部分,该部分可以正向爆破或者从尾到头的反向逻辑。然后找到与flag没有直接关联的部分,该部分无需逆向逻辑,直接正向流程复现即可。
正向爆破:
指解题中采用枚举正向爆破的方法,让flag中的每一个字符遍历常用的字符(ascii码表中32-126),带入原伪代码中加密算法(不用逆向),如果成功,就把这个flag存入。
C语言写脚本:
指解题中对于不需要逆向逻辑的单纯去除冗余代码算法的题目,需要仿写去除冗余代码后的逻辑,由于只是仿写,所以原本的伪代码很难用python复现,这时就需要复制粘贴修改成C语言脚本了。
代码截断重写:
指解题中flag生成与用户输入无关,可以单独截断提取出flag生成的函数或逻辑,然后运行截断程序输出flag。
出人意料的flag:
指在题目中获取到了flag,但是这个flag可能长得不像flag,或者flag还要经过进一步的脑洞处理,而不是常规的解密处理。
栈、参数、内存、寄存器类总结:
栈地址连续小数组:
指一些本来应该是大数组的变量被IDA识别成分割成两个或多个连续地址的小数组来使用,可以通过查看栈中的地址排列或循环中的循环数大于单个数组空间来发现,也是需要更加细致才能分析出来。
栈地址连续小字符串变量:
指一些本来应该是大字符串的单个变量被IDA识别成分割成两个或多个连续地址的小字符串变量来使用,可以通过查看栈中的地址排列来发现,也是需要更加细致才能分析出来。
栈中过渡变量反序字符串:
指一些题目本来取输入的字符串变量的最后一位,但是IDA插入了过渡变量来使分析变得困难,如v5 = (char *)&v11 + 7;这里v11就是过渡变量,指向输入字符串input_flag的第16位,所以这里v5指向输入字符串input_flag的最后一位,栈中地址又是从下到上,高位到低位的,所以反序操作标志是v6 = *v5--;
地址小端存放与正向:
指字符串数字等在内存中是反向存放的,如v7 = ‘ebmarah’,如果用地址来取的话要反向,如果用数组下标来取的话才是正向。
高低位分割数:
指一些本来应该是两个小类型变量的数被IDA识别成一个大类型然后分成高位和低位来使用,需要更加细致才能分析出来。
可变参数混淆:
指解题中IDA伪代码显示出来的参数数量超出,不符合逻辑,也不知道多附加了什么操作。查看反汇编才发现并没有传入那么多的参数,原伪代码中之所以有那么多参数是因为C语言的可变参数的特性,有些参数显示了但是并没有用上。
地址差值+数组组合遍历字符串:
指解题中遇到地址减地址的操作如:v4 = input_flag - v1; 然后通过数组组合如:v1[v4]。
这里V1作为地址和v4作为数组v1[v4]执行的是v1+v4的操作,就是v4+v1=input_flag。因为数组a[b]本质就是在数组头地址a加上偏移量b来遍历数组的,所以这里是一种遍历input_flag的新操作。
寄存器传参:
指解题中涉及寄存器作为参数传入,但是有时候IDA无法反汇编出寄存器参数的传入。解题中发现异常如:传入参数为input_flag,但是比较的却是另一个变量,这时就可能是寄存器传参了,要通过查看汇编代码来发现。
/x7f截断字符串:
/x7f可以阻断字符串,在IDA中会把一个长字符串分隔成两行的短字符串。如:xIrCj~<r|2tWsv3PtI /x7f zndka
argv[]外部调用输入参数符合条件:
指解题中需要使用命令行传入参数。
如:int main( int argc, char *argv[] )
$./a.out testing1 testing2
应当指出的是,argv[0] 存储程序的名称,argv[1] 是一个指向第一个命令行参数的指针,*argv[n] 是最后一个参数。如果没有提供任何参数,argc 将为 1,否则,如果传递了一个参数,argc 将被设置为 2。
函数类总结:
函数逻辑封装:
指关键逻辑被封装成自定义函数,需要自己双击跟进并总结出函数作用,需要通过动态调试验证猜想的作用。
函数名称暗示:
指题目给出的自定义函数名称有含义,可以概括该函数的大致作用,来给总结函数作用提出一些方向性的指导。
函数积累:
指题目中有没做笔记的函数需要终点重温和积累一下。
IDA等软件类总结:
GDB动态调试:
指使用GDB来进行ELF文件的动态调试。
IDA动态调试:
指使用IDA来进行ELF或windows文件的动态调试。
IDA热键重新反汇编:
指解题中必须使用IDA热键对处理过或未处理的的错误反汇编代码重新分析,以至生成新的正确的反汇编代码,多用在混淆和花指令区。
IDA热键a生成数组:
指解题中对IDA零散的单个字符可以使用热键a生成数组,即长字符串。如果中间没有截断,则可以正常生成字符串。
IDA对char型(byte)的4*计数:
指解题中虽然IDA伪代码显示的 i 是 int 型,但是计算的时候通常会变成 4*i ,这通常会具有干扰性,所以我们要知道这是IDA默认把 i 当成byte类型即可,4*i 和 int 型的 i 是一样的。
单层交叉引用查看:
指在解题中只能确定一些少量的被调用函数,这些函数可能是自定义函数也可能系统函数。通过IDA的function call或Ctrl+x操作来查看改函数被谁调用,从而找到主逻辑所在的函数。
多层交叉引用查看:
指在解题中一开始获得的是比较深层次的被调用函数,需要多次查看交叉引用才能锁定最终的主逻辑所在函数。
算法类总结:
main算法逻辑平铺:
指主要算法代码都在main函数中,不涉及解题算法之外的其它操作,而且代码逻辑平铺、显而易见,没有把关键逻辑分成自定义函数形式,不需要频繁跟进函数。
范围算法积累:
指解题中有涉及用户输入的范围内判断以及逆向算法时对于范围处理的过程中值得注意和积累的地方。
地址赋值算法积累:
指解题中涉及对关键字符串如用户输入字符串的操作,原代码中会先把输入字符的地址赋值给变量,即让一个变量指向输入字符串然后再开始修改,这是两步操作,需要辨认。
二维数组算法积累:
指解题中涉及二维数组,用户输入与二维数组要取的下标相关,逆向时要明确是二维数组逻辑以及一维在哪里确定,举例如: *(char *)(v3[i % 3] + 2 * (i / 3)) - *(char *)(i + a1) != 1
字符串拆分算法积累:
指解题中IDA对多个连续的字符串按打乱的顺序以下标的方式分别按多组赋值,这种字符串拆分赋值的方式需要动态调试或耐性的一个个跟踪分析才能梳理清楚。
相同异或为0算法积累:
指解题中遇到特定异或为0的条件则可以采用上面的定律。如: *result = (108+argument[1]) ^ argument[2] = 0 即 argument[2]=(108+argument[1]) 因为相同异或才为0
可打印字符过滤算法积累:
指解题中遇到flag等关键字符在内的混杂的大量字符中,要通过多层过滤来一步步生成flag的算法,可打印字符范围内可用算法如:if ord(i)>=32 and ord(i)<=125:
大小写字符转换算法:
指解题中有一些算法范围波动比较少,看似逻辑相关,实际上只是大小写的ASCII值转换而已。
递归调用算法:
指解题中遇到函数内递归调用自己,传入参数也会在调用时修改的算法,当需要用python仿写递归算法时可以通过超范围的循环来实现递归,因为设置同样的条件,递归不满足时仿写的循环也会退出。
杨辉三角算法:
指解题中遇到对传统数学算法的代码实现,辨认的特征是通过关键代码判断是否符合杨辉三角算法的特性,如:在一维中用(n*(n+1)/2的前n行总数来遍历到特定行,又如:2^n来求第n行的和等。通常涉及等差、等比数列。
>> 和 % 运算符算法积累:
指解题中遇到 >> 和 % 运算符的操作。>> 运算符其实是不带余数的除法 / 算法,单取整数部分。% 运算符其实是不带整数的求余运算,单取余数部分。
如: v6 = (v5 >> 4) % 16 是除以16后的整数部分, v7 = ((16 * v5) >> 4) % 16 是乘16后除16再取16内的余数,也就是直接取16内的余数。一个取整数,一个取余数,所以他们的逆向算法就是16 * v6 + v7
运算符优先级注意:
指解题中应该要准确判断长运算式的优先级顺序,写脚本中也应该尽可能使用括号来固定优先级,否则会出现结果的错误。
负数作循环条件:
指解题中遇到负数作循环条件的情景需要明白这不是死循环,而是正数大循环。如:while(-1) ,在32位里 -1 就是 FFFFFFFF,就是100000000 - 1。所以这一下子就转正了!如果是while(-a2),所以就循环100000000 - a2次。
涉及加密:
指题目中存在加密,可能是传统的MD5、RSA或base64等,也可能是非传统的加密方式。
随机抽取比较:
指在解题中以随机数做基准,取各个对应的字符进行比较。其实就是在相同的字符中取随机但同样的位来比较,所以逆向是要顺序取。
取特定位数算法:
指解题中遇到源代码有__int8这样的限制,这是取前8位,python中可以使用&0xff这种方法,因为&在Python中是逻辑与运算,所以与的时候就保留了前8位,如:flag+=chr((v12^v15)&0xff)。取前16,32位都可以套用这个方法。
main函数主逻辑分析(C语言)
不能正常运行的exe文件类型:
bugku 逆向入门:(实际TxT文件、不能直接运行)

直接去掉.exe后缀用记事本打开,直接搜索bugku,无果。看到文件开头:

是base64加密的图片,于是用在线网址(http://tool.chinaz.com/tools/imgtobase/)解密得到二维码:(扫码即得flag)
攻防世界的csaw2013reversing2:(运行乱码、int3断点考察、函数积累、不能直接运行)
win32无壳,那么既然是windows的直接双击运行一下看看:

这个就是乱码的flag了,乱码有好多种,base64加密等等这些,我们一个个排除,先扔入IDA中查看伪代码。要先看C或C++伪代码再分析反汇编结构图最后才看反汇编文本!!!!
main主函数伪代码如图:

那么解题关键就在前面了:
memcpy_s(lpMem, MaxCount, &unk_409B10, MaxCount);//这个是复制函数,把&unk_409B10处的字符串赋值给lpMem,分析后可知这是乱码的flag,双击跟踪&unk_409B10也可以看到是弹框中输出的乱码。
if ( sub_40102A() || IsDebuggerPresent() ) //这是判断函数,如果判断是调试器运行就执行这个解密
{
__debugbreak();
sub_401000(v3 + 4, lpMem);//这个双击跟踪进去后发现是一个运算函数,那么只能是解密算法所在了
ExitProcess(0xFFFFFFFF); //解密后就退出了,就没有后面的弹框了,需要我们自己想办法。
}
分析完了,我们开始解题,也是好几种方法:
1:静态调试:根据sub_401000的解密算法自己仿照C语言或python脚本解密,因为参数都可以跟踪到。
2:动态调试:在onllydbg中进入解密流程内,解密后查看寄存器或跳转到messageboxA中进行弹出即可。
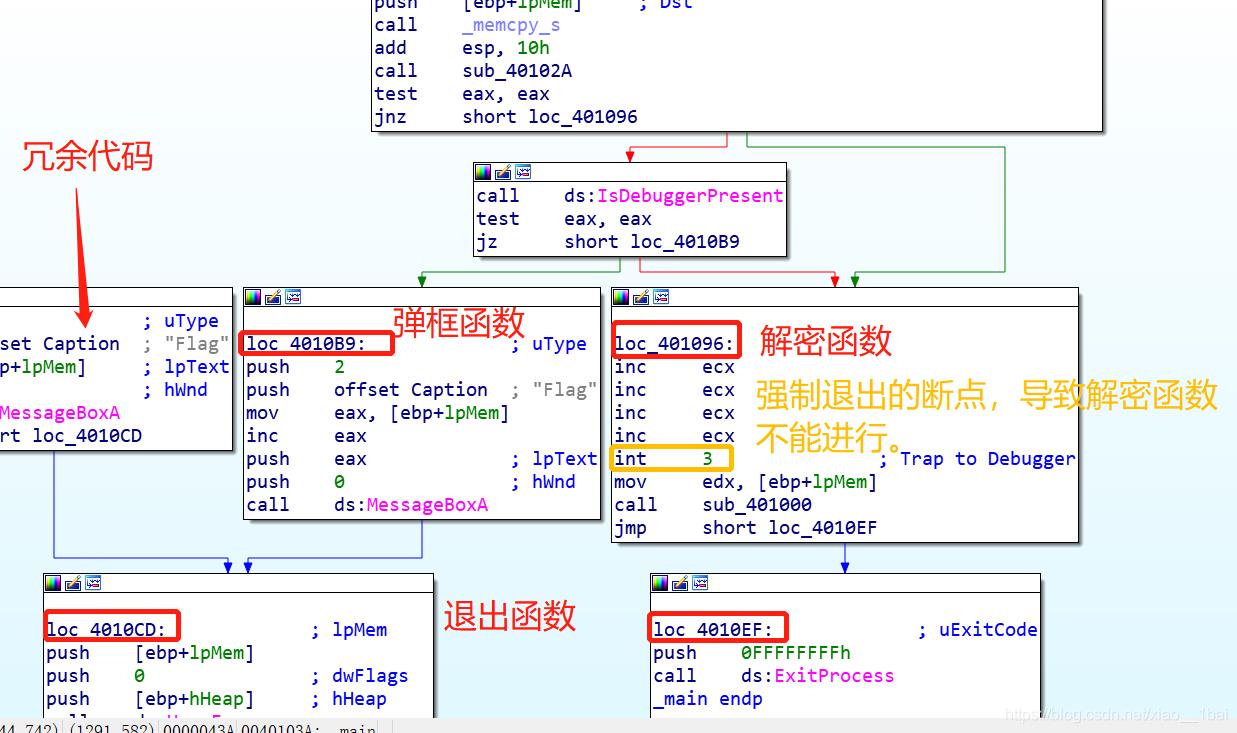
这里我用的动态调试:按照流程看完C语言伪代码后我们来看反汇编结构图:
有了前面分析基础就看懂得多了:loc_4010B9:是弹框函数所在,loc_401096:是解密函数所在,最左边那个应该是冗余代码,loc_4010EF和loc_4010CD: 都是退出函数所在。
注意这里loc_401096有个int 3;这是断点的一种,代码执行到此次会抛出异常,因为这不是我们在OD之类的调试器下的断点,所以OD之类的调试器不会处理该断点的异常,而是交给系统处理,而系统的处理方式往往是强制退出。所以我们在动态调试中要改为nop,不然后面的代码就没法执行
那么我们上onllydbg修改int 3;断点为nop:
可以看到我改了几个地方:
1:
002B1094的 jz short loc_4010B9改成jnz short loc_4010B9,虽然我也不知道为什么我用onllydbg调试还是进不去解密函数,可能onllydbg被认为不是调试器吧。
2:
002B109A 的int 3;断点强制退出被我改成了002B109A nop,标识空操作,避免退出。
3:
002B10A3的 jmp 0453d212.002B10EF改成jmp 0453d212.002B10B9 因为这里原来解完密后就退出的,我把它转到原来loc_4010B9:的messageboxA函数去作为弹框内容输出了。(ps:我本来是跳转到最IDA反汇编结构图的左边那个冗余函数的,因为我看它也是MessageboxA函数,结果弹出个空框,对比后才发现它比第二个MessageboxA少了几行代码,原来是个坑,难怪。),当然也可以解完密之后下断点读取寄存器内容也行。

这样就弹出flag了:

攻防世界parallel-comparator-200:(.c文件、大小写字符转换算法、函数积累、相同异或为0算法积累、线程操作积累、不能直接运行)
下载附件,一个.c后缀的文件,devc++中查看代码。
这里犯下第一个错误:混淆代码太多,线程一开始没学,简单学了后发现也和解题逻辑没有太大关系,可以把线程划分为系统函数这一块:
#include <stdlib.h>
#include <stdio.h>
#include <pthread.h> //linux的线程库 ,所以要在linux中才可运行
#define FLAG_LEN 20
void * checking(void *arg) {
char *result = malloc(sizeof(char));
char *argument = (char *)arg;
*result = (argument[0]+argument[1]) ^ argument[2]; //对 first_letter、 differences[i]、 user_string[i]进行简单操作
return result;
}
int highly_optimized_parallel_comparsion(char *user_string)
{
int initialization_number;
int i;
char generated_string[FLAG_LEN + 1];
generated_string[FLAG_LEN] = '\\0';
while ((initialization_number = random()) >= 64); //无用循环
int first_letter;
first_letter = (initialization_number % 26) + 97; //initialization_number从0~25取值 +97后ASCII对应小写的a~z
pthread_t thread[FLAG_LEN]; //创建数组型的线程标识符 ,20线程句柄
char differences[FLAG_LEN] = {0, 9, -9, -1, 13, -13, -4, -11, -9, -1, -7, 6, -13, 13, 3, 9, -13, -11, 6, -7}; //定义20个元素的char数组
char *arguments[20]; //定义20个char型的指针数组
for (i = 0; i < FLAG_LEN; i++) {
arguments[i] = (char *)malloc(3*sizeof(char)); //每个指针指向3个char字节划分的数组头
arguments[i][0] = first_letter; //first_letter由于 initialization_number = random()而未确定
arguments[i][1] = differences[i]; //已确定
arguments[i][2] = user_string[i]; //用户输入字符,未确定
pthread_create((pthread_t*)(thread+i), NULL, checking, arguments[i]); //调用上面checking函数对arguments三字节数组进行简单操作
}
void *result; //定义一个数组,用上面的异步线程赋值
int just_a_string[FLAG_LEN] = {115, 116, 114, 97, 110, 103, 101, 95, 115, 116, 114, 105, 110, 103, 95, 105, 116, 95, 105, 115}; //定义一个20个元素的数组
for (i = 0; i < FLAG_LEN; i++) {以上是关于CTF逆向总结的主要内容,如果未能解决你的问题,请参考以下文章