强化学习笔记3---policy gradient基本概念
Posted Shezzaaaa
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了强化学习笔记3---policy gradient基本概念相关的知识,希望对你有一定的参考价值。
本文章为学习李宏毅老师视频的学习笔记,视频链接
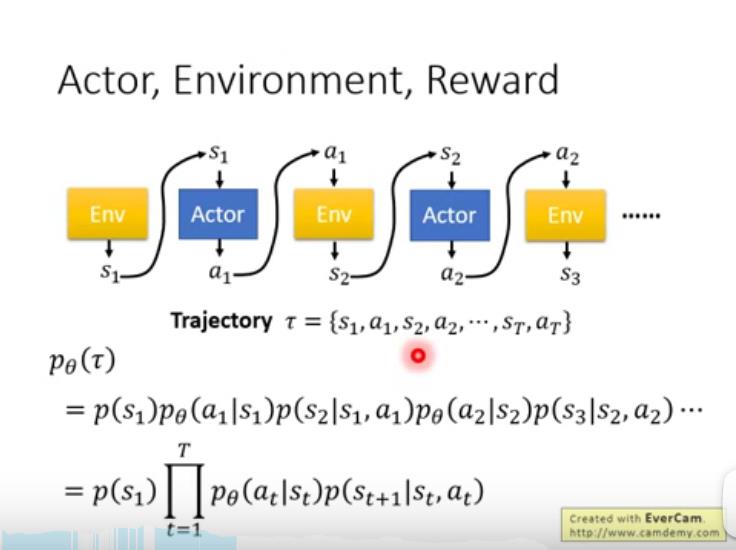
调整theta,就可以调整选择trajectory的概率
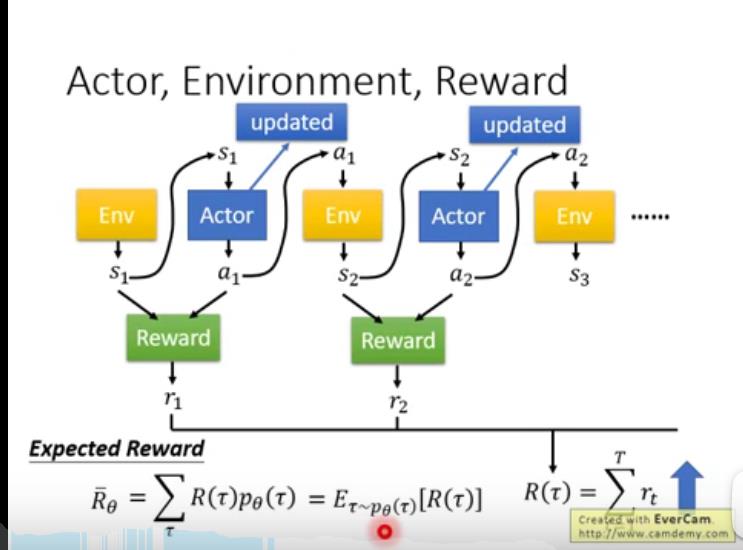
只能求出该路径奖励的期望值,方法是穷举所有路径并将奖励值加和

这么复杂的推导,咱们就是说瞟一眼就可以了,就是求reward的梯度

theta更新过程,
η
\\eta
η 是学习率

sample的概念。
R
(
τ
n
)
R(\\tau ^n)
R(τn) 是整场游戏采取
a
a
a的奖励

为了增加sample的正确率,可以将某些reward改为负。增添加baseline来实现,即
b
b
b。最简单的方式即
b
=
E
(
R
(
τ
)
)
b=E(R(\\tau))
b=E(R(τ))
讲到45:48然后没听了,有缘再见家人们
以上是关于强化学习笔记3---policy gradient基本概念的主要内容,如果未能解决你的问题,请参考以下文章