Elasticsearch 如何实现相似推荐功能?
Posted 铭毅天下
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch 如何实现相似推荐功能?相关的知识,希望对你有一定的参考价值。
1、什么是相似推荐?
拿我们身边的算法“投喂”为主的头条、抖音、微信视频号等举例,如果你喜欢乒乓球,每天推送给你的都是乒乓球比赛视频集锦;如果你喜欢成功人士演讲,每天都是马云、马化腾、刘强东等商业巨鳄的演讲。
再拿电商的示例如下:比如我近期购买的吴军老师推荐的科普经典巨著《从一到无穷大》,京东会给我推荐樊登读书带火的书《微积分原理》。

其实,在实际业务实战环节,或多或少也会有类似的功能,Elasticsearch 有没有类似功能呢?
大家实战环节遇到的问题也大致如下:
Q1:ES 有相似搜索这个功能吧?我记得有个 suggester吧?
Q2:ES有没有处理相似文字的案例?把相似文章聚合起来。
来自《死磕Elasticsearch 知识星球》微信群
2、Elasticsearch 相似推荐功能实现
这里不得不介绍:MLT 检索。对!你没看错。不是:MIT(麻省理工学院),是 Elasticsearch 一种检索类型 MLT(More Like This Query )。
看下图,建立个全局认识。MLT 属于:Query DSL下的专业检索(Specialized queries)的范畴。

3、More Like This 检索介绍
More Like This 检索定义:查找与给定文档“相似”的文档。
4、More Like This 底层逻辑
MLT 查询简单地从输入的待查询文本中提取文本,对其进行分析,通常在字段中使用相同的分析器,然后选择具有最高 tf-idf 的前 K 个词组以形成这些词组的组合查询语句。
假设我们想找到与给定输入文档相似的所有文档。显然,输入文档本身应该是该类型查询的最佳匹配。为什么呢?基于 Lucene tf-idf 评分公式计算得出的呀。
如下就是 Lucene tf-idf 评分模型。

如果对此评分不了解的同学,推荐阅读:
干货 | 一步步拆解 Elasticsearch BM25 模型评分细节
MLT 查询的本质是:从待检索语句中提取文本,然后用分词器切分,选择 tf-idf 分值高的前 K 个术语形成检索语句。基于检索语句返回的结果就是相似度查询结果。
为避免歧义,对照的英文如下:
The MLT query simply extracts the text from the input document, analyzes it, usually using the same analyzer at the field, then selects the top K terms with highest tf-idf to form a disjunctive query of these terms.
如果原理还不够清晰,我将核心 Lucene 源码的逻辑简要说明如下:
步骤 1:根据输入的待查询的文档,抽取词组单元(term),结合TF*IDF 评分形成优先级队列。
抽取词时会过滤掉停用词、不满足最小词频的词等不满足限定条件的词。
步骤 2:结合步骤 1 的优先级队列,生成布尔查询语句。

Lucene 源码部分截图
循环超过最大查询词数目,则停止构建查询语句。
最大查询数据值 max_query_terms 默认是:25。增加此值会以牺牲查询执行速度为代价提供更高的准确性。
步骤 3:基于步骤2构造的布尔查询语句,获取查询结果。
返回结果就是类似推荐功能的相似文章。
看的出来,这比我们常见的精准匹配 term query 和全文检索 match query、match_pharse query 都要复杂很多。
5、More Like This 前置条件
执行 MLT 的字段必须被索引并且类型为 text 或 keyword。此外,当对文档使用相似度检索时,必须启用 _source 或设置为 stored 或存储为 term_vector。为了加快分析速度,可以在索引时存储 terrm vectors。
读者看到这里可能会疑惑:啥叫 term vectors ?
有必要解释一下:
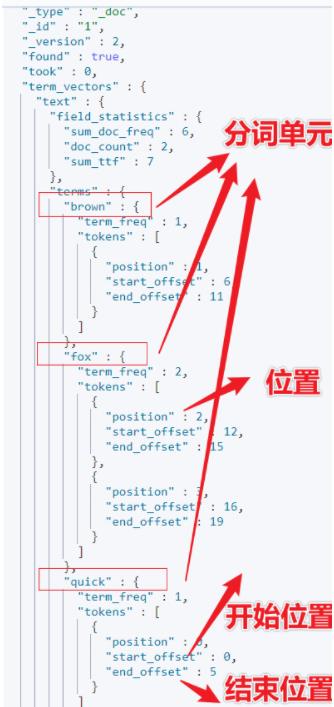
term vectors 组成:
terms 分词单元列表。
每个分词单元的位置 position 和序号。
分词后的单词或字在原有串中的起始位置 start_offset 、结束位置 end_offset 和偏移值。
有效载荷。与位置相关的用户定义的二进制值。
给了一堆术语,还是看不懂,再来?!
给个例子,一看就明白了。
PUT my-index-0000012
{
"mappings": {
"properties": {
"text": {
"type": "text",
"term_vector": "with_positions_offsets"
}
}
}
}
PUT my-index-0000012/_doc/1
{
"text": "Quick brown fox fox"
}
GET /my-index-0000012/_termvectors/1position 更精确的说法是:序号。
Quick 的 position 为 0;
brown 的 position 为 1;
quick 的 start_offset 为 0;
quick 的 end_offset 为 5。
6、More Like This 实战一把
光说不练是假把式,实战一把,一探究竟。
插入一批数据,数据来源:百度热点新闻 。
DELETE news
PUT news
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_smart"
}
}
}
}
POST news/_bulk
{ "index": { "_id":1 }}
{"title":"演唱会突发意外!知名男星受伤,本人最新回应"}
{ "index": { "_id":2 }}
{"title":"张杰演唱会主办方道歉:舞台升降设备出现故障"}
{ "index": { "_id":3 }}
{"title":"谢娜发文回应张杰受伤"}
{ "index": { "_id":4 }}
{"title":"张杰回应受伤:不会有大碍,请歌迷和家人朋友们放宽心"}
{ "index": { "_id":5 }}
{"title":"张杰表演时从电梯坠落 手指血流不止"}
{ "index": { "_id":6 }}
{"title":"谢娜回应张杰受伤:他问的第一句话就是怕吓到女儿"}
{ "index": { "_id":7 }}
{"title":"张杰演唱会出意外后,发长文给粉丝报平安,谢娜透露张杰本人..."}
{ "index": { "_id":8}}
{"title":"张杰明星资料大全爱奇艺泡泡"}PS:以上仅是百度公开的热点新闻,以此举例相似查询,别无其他用途,特此说明。
执行 MLT:
POST news/_search
{
"query": {
"more_like_this": {
"fields": [
"title"
],
"like": [
"张杰开演唱会从升降机上掉落"
],
"analyzer": "ik_smart",
"min_doc_freq": 2,
"min_term_freq": 1
}
}
}返回结果如下:

以如上截图最后一条数据为例,强调说明一下:注意到一个细节,返回结果只是相似,并没有真正做到语义相关。
7、More Like This 核心语法详解
参数看着很好解释,但着实非常难理解,特此解读如下:
"min_doc_freq": 2
最小的文档频率,默认为 5。
什么意思呢?
就拿上面的示例来说,至少得有两篇文章才可以,不管这两篇文章与输入相关与否。
更具体点说,如果bulk 写入仅一篇document,哪怕和标题一致也无法返回结果。
"min_term_freq": 1
文档中词组的最低频率,默认是2,低于此频率的会被忽略。
什么意思呢?
就是待检索语句的其中一个分词单元的词频的最小值。
PUT news
{
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "ik_smart"
}
}
}
}
POST news/_bulk
{ "index": { "_id":1 }}
{"title":"张杰演唱会突发意外!知名男星受伤,本人最新回应"}
{ "index": { "_id":2 }}
{"title":"hello kitty"}
POST news/_search
{
"query": {
"more_like_this": {
"fields": [
"title"
],
"like": [
"张杰回应张杰受伤"
],
"analyzer": "ik_smart",
"min_doc_freq": 1,
"min_term_freq": 2
}
}
}上面的例子更有说服力。
更为具体的说,like部分待检索语句的分词词频要至少有一个 >=2 。
更多参数建议参考官方文档,不再赘述。
8、Elasticsearch 相似推荐其他的实现方案
在第 6 部分提及,more like this 并没有实现完全的相关度推荐,出现了“噪音” 数据。
所以,实战环节使用 more like this 多半基于燃眉之急。
如果想深入的实现相似度推荐,推荐方案:
基于类似 simhash 的方式,给每个文档打上 hash 值,基于海明距离实现相似度推荐。
如果想再深入就需要借助:
基于协同过滤的推荐算法、基于关联规则的推荐算法、基于知识的推理算法或者组合推理算法实现。
9、小结
本文介绍了 Elasticsearch 中实现相似推荐的 More Like This 检索方法、实现原理、案例解读。
目的是给大家业务系统实现相似推荐提供了理论和实践支撑。
大家实战环节如何实现的相似推荐呢?欢迎留言讨论细节。
参考
https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-mlt-query.html
https://spoon-elastic.com/all-elastic-search-post/more-like-this-query-mlt-suggest-similar-content-with-elasticsearch/
https://qbox.io/blog/mlt-similar-documents-in-elasticsearch-more-like-this-query/
https://spoon-elastic.com/all-elastic-search-post/more-like-this-query-mlt-suggest-similar-content-with-elasticsearch/
https://newbedev.com/elasticsearch-more-like-this-query
https://www.linkedin.com/pulse/finding-similar-documents-elasticsearch-morelikethis-fl%C3%A1vio-knob?articleId=6657988773374111744
《Lucene 原理与代码分析》
推荐
1、重磅 | 死磕 Elasticsearch 方法论认知清单(2021年国庆更新版)
2、Elasticsearch 7.X 进阶实战私训课(口碑不错)
更短时间更快习得更多干货!
已带领70位球友通过 Elastic 官方认证!
中国仅通过百余人

比同事抢先一步学习进阶干货!
以上是关于Elasticsearch 如何实现相似推荐功能?的主要内容,如果未能解决你的问题,请参考以下文章