日常爬虫进阶技巧:selenium加载扩展插件(extension)与配置用户数据(user-data)
Posted 囚生CY
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了日常爬虫进阶技巧:selenium加载扩展插件(extension)与配置用户数据(user-data)相关的知识,希望对你有一定的参考价值。
文章目录
序言
本文将简单阐述关于 Python \\text{Python} Python使用浏览器驱动( Selenium \\text{Selenium} Selenium)中的配置( options \\text{options} options)进阶性技巧:
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
# chrome_options.add_extension(...)
# chrome_options.add_argument(...)
# chrome_options.add_experimental_option(...)
最全的配置信息可以参考 Chrome \\text{Chrome} Chrome官网,如果无法翻墙,也可以搜到比较全的博客(如CSDN@Kosmoo),笔者不会介绍很多的配置选项,仅就配置插件与配置用户数据两点,结合实例进行阐述。
笔者撰写与爬虫相关的博客通常会围绕一个完整的爬虫任务流程进行梳理,极少选取这种技巧性的问题点来小题大做创作一篇博客。然而学习爬虫技巧并无捷径可行,只有在若干实践中不断发现障碍并设法解决后,你的经验才会不断提升,在以后遇到类似的瓶颈才能迎刃而解。
也许在阅读本文的你已经是能够熟练应用 Selenium \\text{Selenium} Selenium与 JS \\text{JS} JS逆向的方法的老手,认为在浏览器中所阅所闻都可以轻而易举地爬取得到,但是笔者确信你依然会在爬虫过程中仍然会遇到令人费解的问题,因为总是会有你不熟悉的知识。比如在相同的操作流程下, Selenium \\text{Selenium} Selenium驱动与实际浏览器操作看到的页面并不相同,在这种情况下,笔者就会非常高兴,因为问题出现将意味着爬虫技能的提升,如果始终没有问题出现,只会说明潜在的问题会越来越多,爬虫本身也便是失去了乐趣。
序言的最后,笔者将介绍本文的爬虫任务。近期组内正在准备筹办 2021 2021 2021年的国际会议,老板让我们去 Engineering Village \\text{Engineering Village} Engineering Village通过搜索各个会议名称得到若干论文链接,从中论文链接中可以获取论文作者的姓名与邮箱信息,用于发布会议征文邮件:
- Figure 1 \\text{Figure 1} Figure 1: Engineering Village \\text{Engineering Village} Engineering Village搜索页面
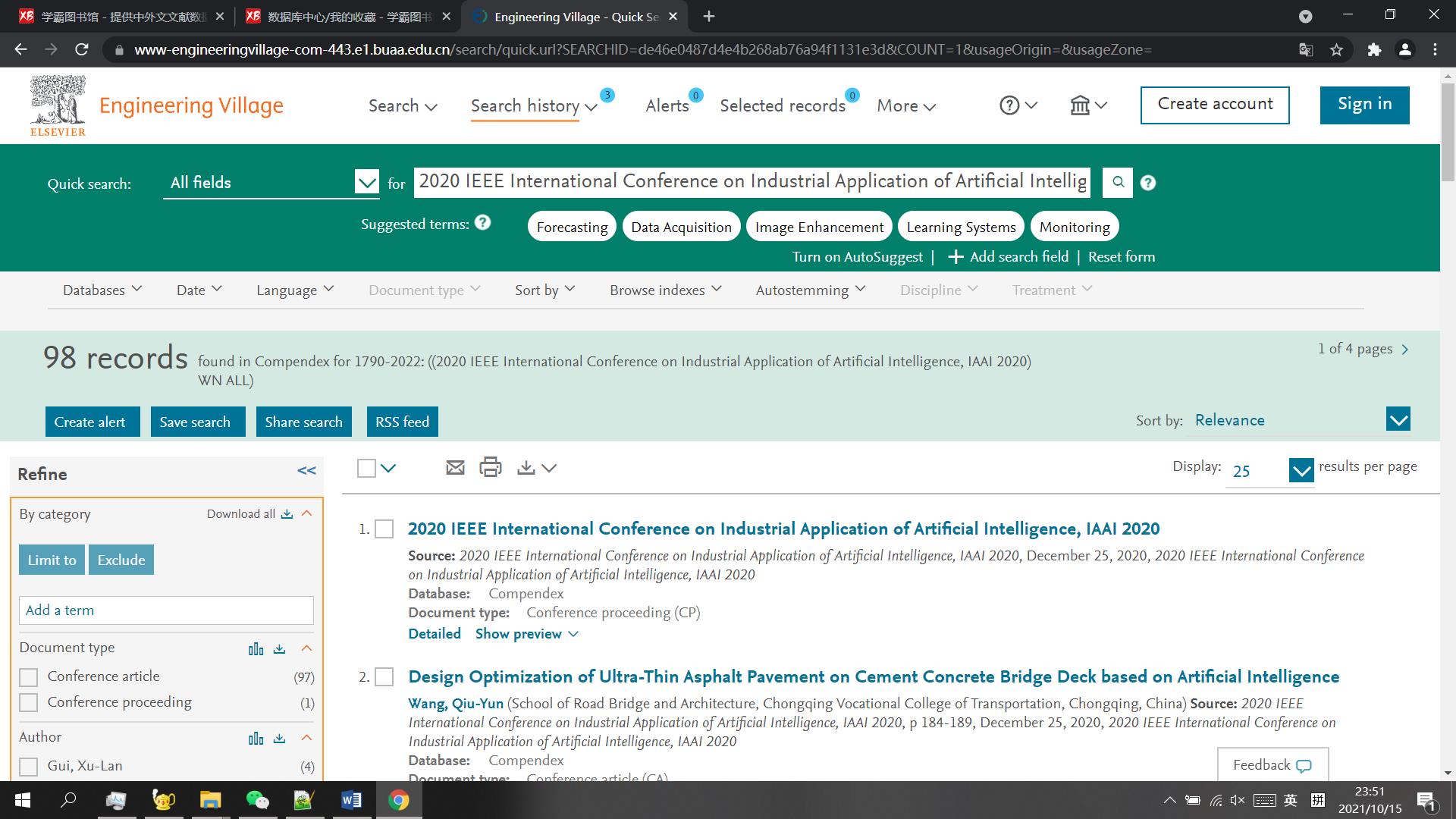
由于笔者所在的高校没有访问 Engineering Village \\text{Engineering Village} Engineering Village数据库的权限,好在老板给了学霸图书馆的 VIP \\text{VIP} VIP(相当于借用其他高校的统一身份认证信息去访问 Engineering Village \\text{Engineering Village} Engineering Village,类似 VPN \\text{VPN} VPN)。然而校园网访问 Engineering Village \\text{Engineering Village} Engineering Village的效率实在是过于迟缓,而且经常性地会发生页面崩溃的情况,这使得人工完成收集姓名与邮箱的任务并不容易。
事实上去年在筹办会议时笔者已经写好了爬虫逻辑,虽然今年 Engineering Village \\text{Engineering Village} Engineering Village的页面完全没有发生更新,去年的爬虫逻辑依然可行,但是今年学霸图书馆提供的高校通道发生了更新,需要下载插件才能借用其他高校的统一身份认证信息去访问 Engineering Village \\text{Engineering Village} Engineering Village:
- Figure 2 \\text{Figure 2} Figure 2:插件安装说明。注意该插件只能在 Chrome \\text{Chrome} Chrome内核的浏览器中安装,火狐浏览器与 Edge \\text{Edge} Edge一定无法安装,因此本文的 S e l e n i u m \\rm Selenium Selenium要求必须在 Chrome \\text{Chrome} Chrome上启用,需要先行安装 Chromedriver \\text{Chromedriver} Chromedriver,具体方法详见https://www.cnblogs.com/lfri/p/10542797.html
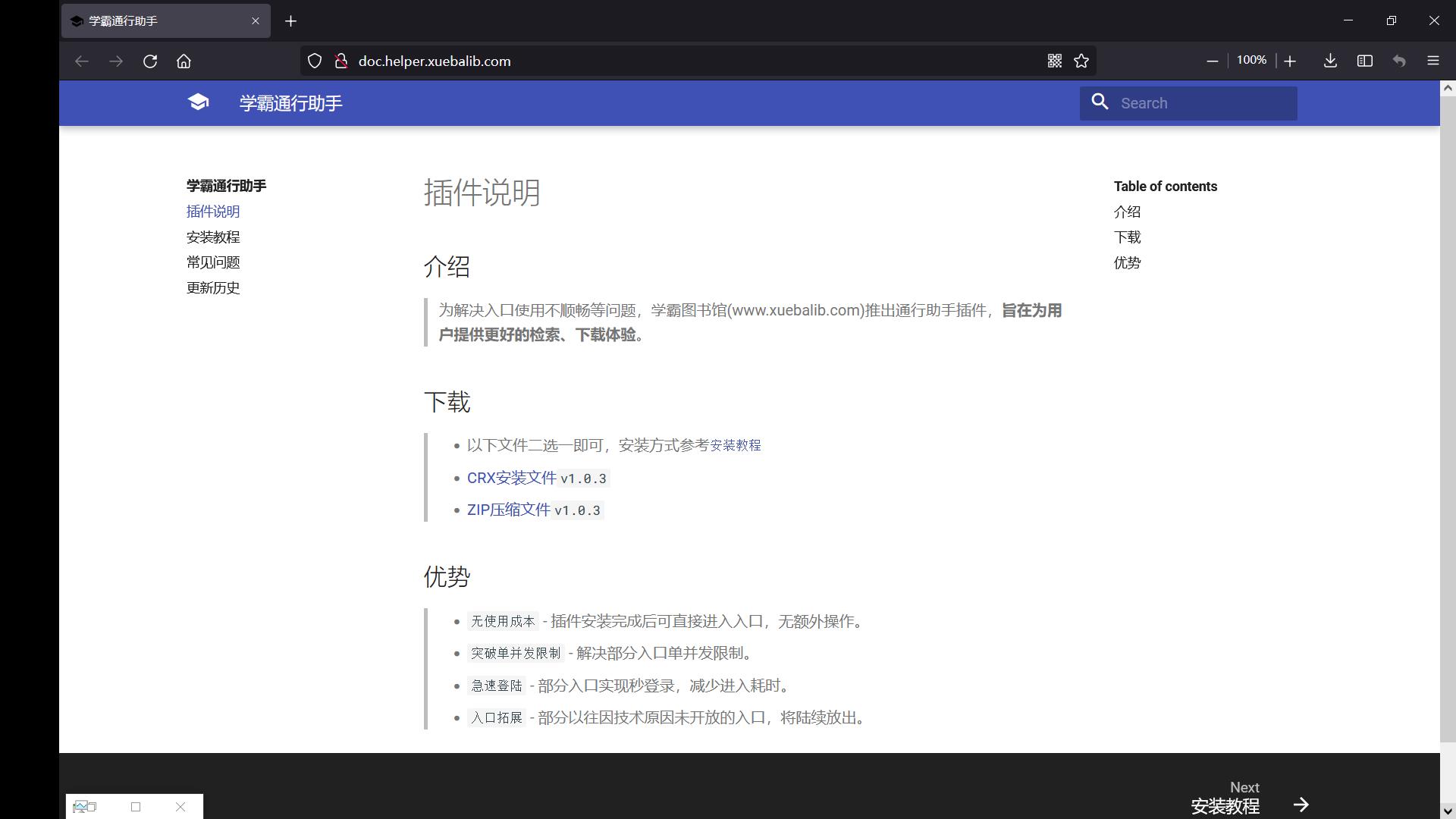
对本文的爬虫任务并不感兴趣的朋友,可以直接跳过接下来的序言内容直接阅读正文部分。
如果对本文所述的爬虫任务感兴趣的朋友,可以去学霸图书馆申请注册一个新账号,登录账号后访问Welcome页面可以获得免费的 24 24 24小时 VIP \\text{VIP} VIP体验,这将有利于你对接下来本文爬虫代码的使用。重新登陆账号后进入数据库大全,在外文数据库大全中找到 Engineering Village EI \\text{Engineering Village EI} Engineering Village EI工程链接进入:
- Figure 3 \\text{Figure 3} Figure 3:找到 Engineering Village EI \\text{Engineering Village EI} Engineering Village EI工程数据库链接
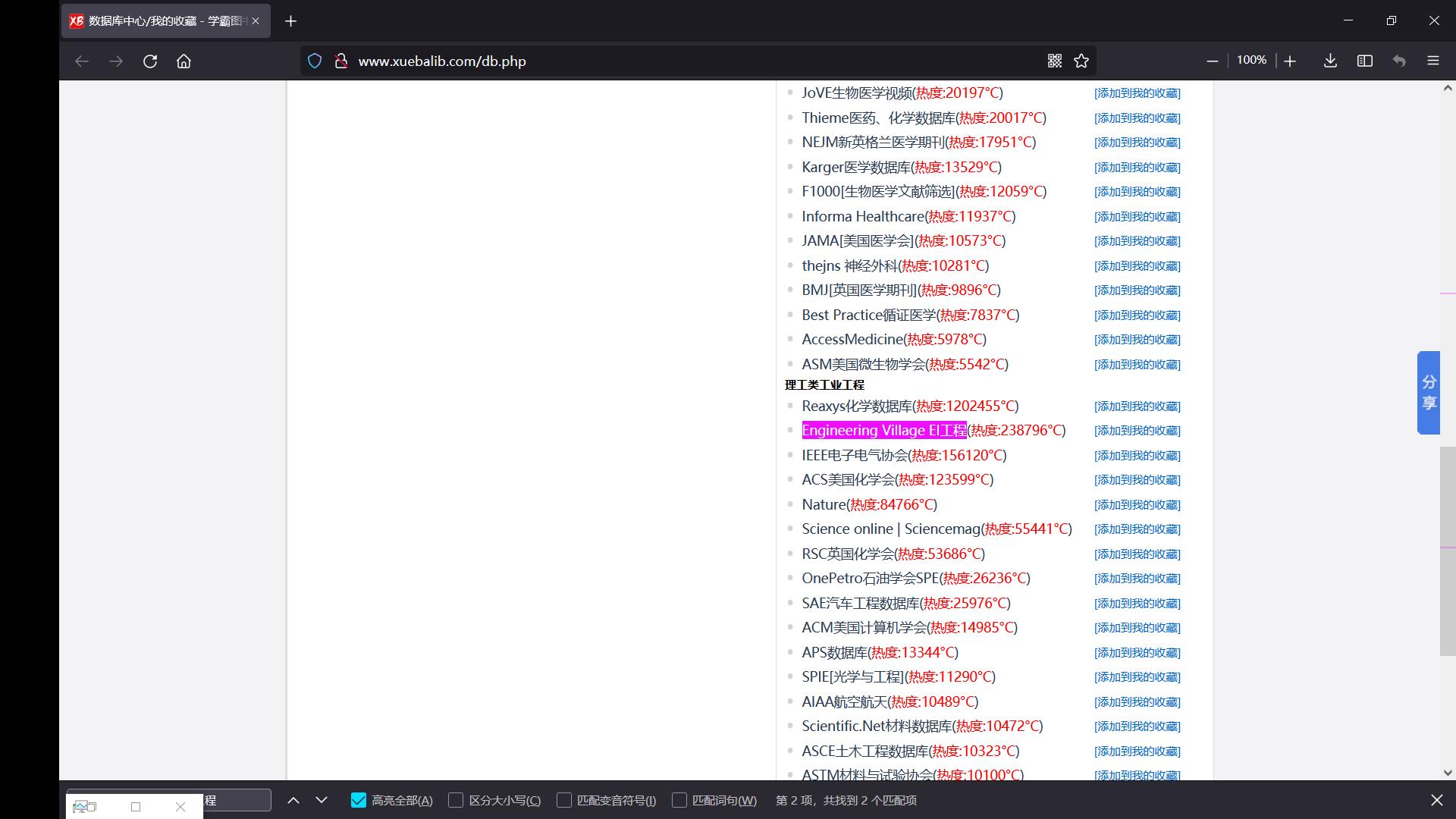
即可找到以下两个通道,注意这两个通道可能过一段时间就不存在了,去年笔者使用的是沈阳工业大学的通道,今年的两个分别是中科大与北航的通道,虽然以后通道可能也会发生变化,但是
Engineering Village
\\text{Engineering Village}
Engineering Village的爬虫逻辑通常是不会变的,因此本文爬虫的维护范围仅限于进入通道:
- Figure 4 \\text{Figure 4} Figure 4:找到高校通道链接
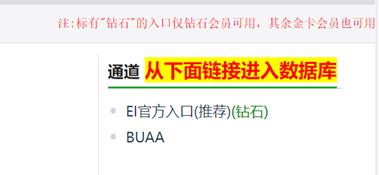
点击上图中任意一个通道链接即发现上文中所提及的插件:
- Figure 5 \\text{Figure 5} Figure 5: 2021 2021 2021更新内容,需要安装插件访问通道,该插件的安装并不复杂,按照教程选择第二种 zip \\text{zip} zip格式的在 Chrome \\text{Chrome} Chrome中手动安装解压包,之后弃用可以直接彻底删除。

本文的问题从这里开始。
1 Selenium \\text{1 Selenium} 1 Selenium加载插件( Chromedriver \\text{Chromedriver} Chromedriver)
第 1 1 1点比较浅显。
即便你根据 Figure 2 \\text{Figure 2} Figure 2在 Chrome \\text{Chrome} Chrome上安装好插件后,使用 Chrome \\text{Chrome} Chrome的 Selenium \\text{Selenium} Selenium驱动访问通道时依然会卡在 Figure 5 \\text{Figure 5} Figure 5的提示页面上,这是一件很 tricky \\text{tricky} tricky的事情。
笔者不敢确信地说 Selenium \\text{Selenium} Selenium默认不会加载该插件,因为 Figure 2 \\text{Figure 2} Figure 2中事实上提供了两种插件安装方法,但是第一种( crx \\text{crx} crx文件)似乎无法在 Chrome \\text{Chrome} Chrome中安装,因此只能使用第二种( zip \\text{zip} zip文件)安装方法,但是在本文第 3 3 3部分源码中 81-84 \\text{81-84} 81-84行依然是可以为浏览器驱动配置安装 crx \\text{crx} crx的插件的。
chrome_options = webdriver.ChromeOptions() # 初始化Chrome选项
chrome_options.add_extension(self.extension_path) # 安装学霸图书馆通道插件
chrome_options.add_argument(r'user-data-dir=C:\\Users\\lenovo\\AppData\\Local\\Google\\Chrome\\User Data')
chrome_options.add_experimental_option('useAutomationExtension', False)
这是很有迷惑性的点,因为浏览器驱动(
Selenium
\\text{Selenium}
Selenium)中的配置(
options
\\text{options}
options)有一项是--disable-plugins,即禁用插件,看起来似乎如果不配置--disable-plugins参数,浏览器上已经安装的插件是会默认生效的。但是实践结果并非如此,即便不配置--disable-plugins参数,插件也不会默认启用,或者可能插件(
plugins
\\text{plugins}
plugins)与扩展(
extensions
\\text{extensions}
extensions)并不是指同一样事物?
另外无法使用add_extension方法安装
zip
\\text{zip}
zip格式的插件,虽然在
Chrome
\\text{Chrome}
Chrome的扩展安装页面中开启开发者模式时可以安装解压的
zip
\\text{zip}
zip文件。
总之省略第 3 3 3部分源码中的第 82 82 82行将无法跳过 Figure 5 \\text{Figure 5} Figure 5页面,关于浏览器插件的问题仍然有待考察。
2 Selenium \\text{2 Selenium} 2 Selenium配置 User Data \\text{User Data} User Data的方法与用途( Chromedriver \\text{Chromedriver} Chromedriver)
这是本次爬虫最令笔者费解的点。
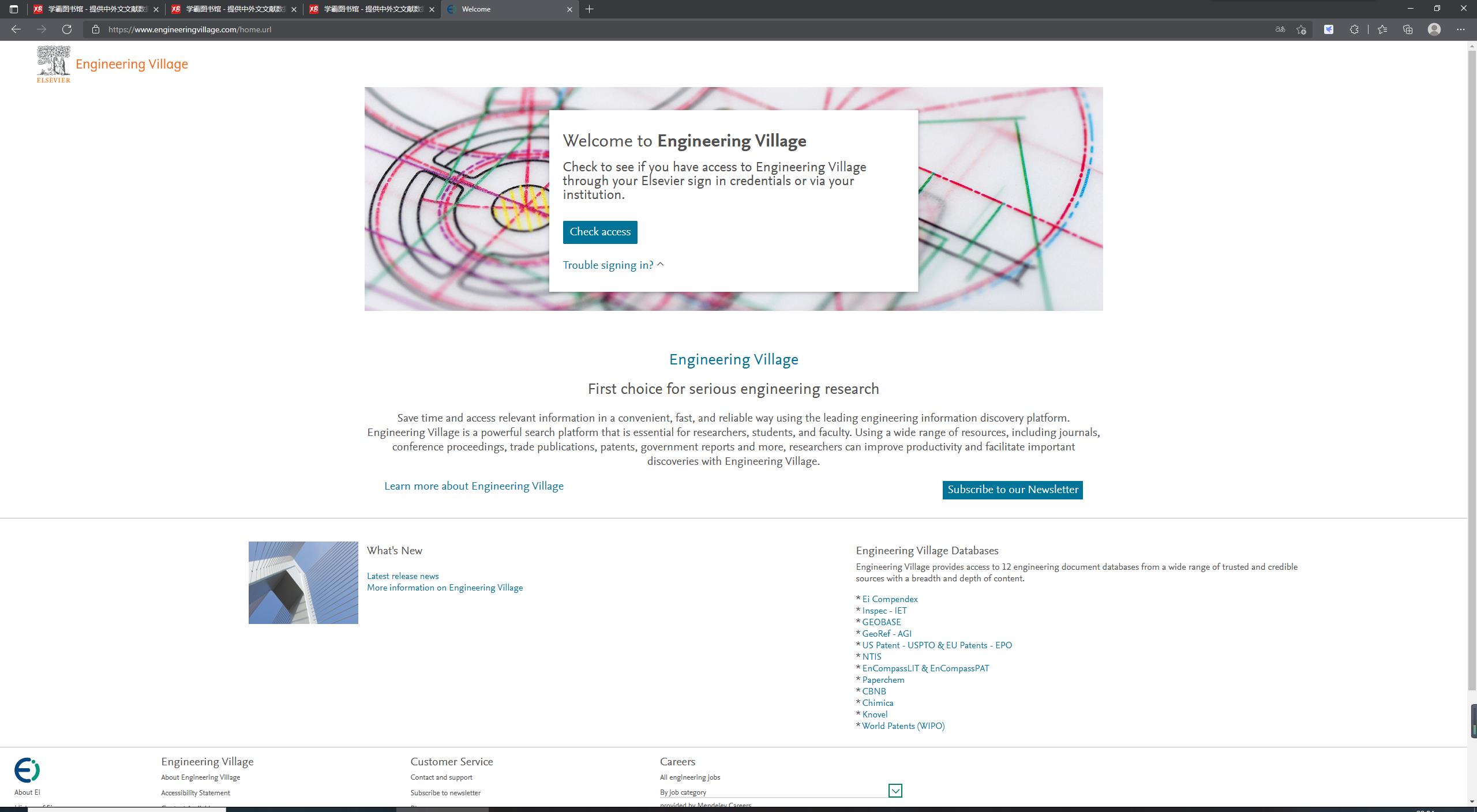
事实上不用走 Figure 4 \\text{Figure 4} Figure 4所示的通道也是有办法进入 Engineering Village \\text{Engineering Village} Engineering Village的,只要在登陆学霸图书馆后直接在地址栏中输入访问http://www.engineeringvillage.com即可得到 Figure 1 \\text{Figure 1} Figure 1的页面(此时已经获得访问 Engineering Village \\text{Engineering Village} Engineering Village数据库的权限,可以进行搜索查询),这种方法其实会更加稳定。
但是笔者在使用 Selenium \\text{Selenium} Selenium驱动时,登陆学霸图书馆后直接在地址栏中输入访问http://www.engineeringvillage.com却始终只能停留在 Welcome \\text{Welcome} Welcome页面上,即仍然需要登陆验证权限。
- Figure 6 \\text{Figure 6} Figure 6:无法进入 Figure 1 \\text{Figure 1} Figure 1所示的页面(停留在欢迎界面上)
这个问题困扰了笔者很长时间,最终只能屈服于走
Figure 4
\\text{Figure 4}
Figure 4的通道,但是
Figure 4
\\text{Figure 4}
Figure 4中给出的
BUAA
\\text{BUAA}
BUAA通道频繁的崩溃,甚至昨晚一夜到今早都没有修复,笔者确信这不是因为插件的问题,于是今早开始测试不同的
options
\\text{options}
options参数,想知道到底是哪个参数致使这两者的区别。
最终发现在第 3 3 3部分源码中的第 83 83 83行,即:
chrome_options.add_argument(r'user-data-dir=C:\\Users\\lenovo\\AppData\\Local\\Google\\Chrome\\User Data')
在添加了user-data-dir参数后,问题迎刃而解。
事实上这个参数将非常有用,许多历史记录、 C o o k i e \\rm Cookie Cookie信息、网站登陆信息都保存在 User Data \\text{User Data} User Data文件夹中。如一些网站支持浏览器记住登陆信息,如果不添加 User Data \\text{User Data} User Data参数,这些被记住的信息是无法在 Selenium \\text{Selenium} Selenium驱动的浏览器中生效的,如果添加该参数,即可轻松的跳过很多网站的登陆验证,而可以免于复杂的验证码处理流程。
3 3 3 源码与运行说明
源码与 crx \\text{crx} crx插件以及示例的关键词文本笔者已经上传至:
链接: https://pan.baidu.com/s/1F2AGagKI89Lqi2_leeo5gw 提取码: hm4q
最后笔者提供本爬虫的完整代码。
仅需修改 xuebalib.py \\text{xuebalib.py} xuebalib.py中的 261 , 262 , 265 261,262,265 261,262,265行的用户名、密码及 crx \\text{crx} crx插件路径即可运行。
另外你需要检查
83
83
83行中的
User Data
\\text{User Data}
User Data路径是否与你计算机上的路径吻合,一般来说
Windows
\\text{Windows}
Windows系统中
Chrome
\\text{Chrome}
Chrome的用户数据路径都是C:\\Users\\lenovo\\AppData\\Local\\Google\\Chrome\\User Data,但是你最好重新确认一次。
代码格式已经做了优化,注释详细且控制台输出信息可读性较强。
# -*- coding: UTF-8 -*-
# @author: caoyang
# @email: caoyang@163.sufe.edu.cn
import time
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
# 读取存放搜索关键词的文件
# 文件中的每一行只记录一条关键词
# 以'#'开头的行会被自动忽略, 尽量不要出现空行
def load_keywords(filepath: str) -> list:
with open(filepath, 'r', encoding='utf8') as f:
keywords = f.read().splitlines()
return list(filter(lambda x: not x.startswith('#'), keywords))
class Xuebalib(object):
def __init__(self,
keywords: list,
username: str,
password: str,
host: str,
extension_path: str=None,
mode: str='expert') -> None:
self.keywords = keywords[:]
self.username = username
self.password = password
self.host = host
self.extension_path = extension_path # 与2020年的情况出现重大区别, 2021年学霸图书馆通道进入需要安装插件, 需下载crx格式的插件并记录路径
self.mode = mode.strip().lower()
assert self.mode in ['quick', 'expert'], f'Unknown mode: {self.mode}'
self.max_trial_time = 8
@staticmethod
def get_detailurl(soup: BeautifulSoup) -> list:
"""
获取索结果页面上所有论文详情页面的链接:
:param soup: 经过BeautifulSoup解析后的页面源代码;
"""
detaillinks = soup.find_all('a', class_='detaillink')
detailurls = []
for detaillink in detaillinks:
detailurl = detaillink.attrs['href']
detailurls.append(detailurl)
return detailurls
@staticmethod
def get_author_and_email(soup: BeautifulSoup, ignore: bool=False) -> list:
"""获取论文详情页面上的作者及对应的邮箱
:param soup : 经过BeautifulSoup解析后的页面源代码;
:param ignore : 是否忽略那些没有邮箱的作者, 默认不忽略;
:return author_and_email: 作者和邮箱构成的二元组列表;
"""
author_and_email = []
if ignore:
emaillinks = soup.find_all('a', class_='emaillink')
for emaillink in emaillinks:
email = emaillink.attrs['href']
authorlink = emaillink.find_previous_sibling('a', class_='authorSearchLink')
author = str(authorlink.string)
author_and_email.append((author, email))
else:
ul = soup.find('ul'以上是关于日常爬虫进阶技巧:selenium加载扩展插件(extension)与配置用户数据(user-data)的主要内容,如果未能解决你的问题,请参考以下文章