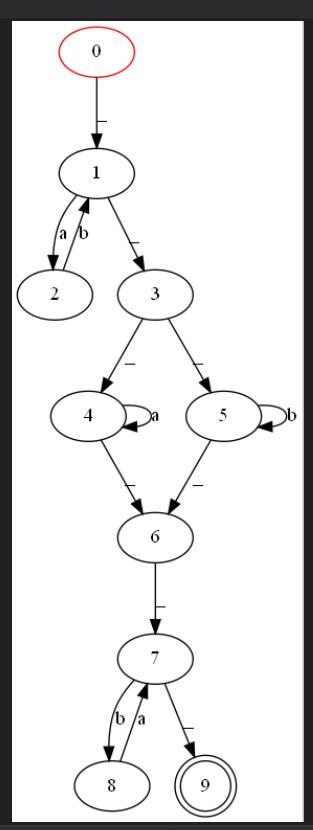
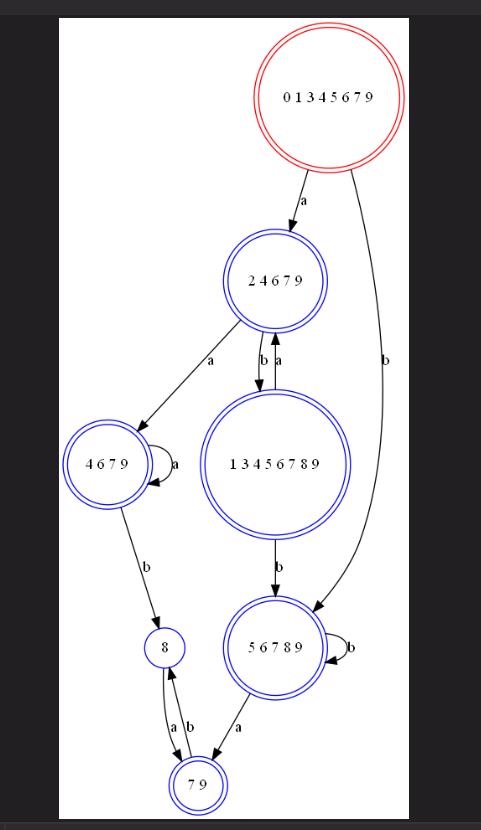
第三方库graphviz的安装方法:https://blog.csdn.net/lizzy05/article/details/88529483
建议直接使用Linux环境,不需要使用环境变量
代码如下
def printlist(l):
for i in range(len(l)):
print(l[i], end=" ")
print("----------------------------输入NFA样例-----------------------------")
ab = eval(input("请输入变量的个数"))
print("请输入变量名称(用_(下划线)表示空)")
aabb = []
for i in range(1, ab + 1):
aabb_eval = input("第" + str(i) + "个变量的名称是: ")
aabb.append(aabb_eval)
printlist(aabb)
# [a,b,c]
# 输入变量的个数之后将为这个创造字典
l = [{} for i in range(ab)] # 创建和变量相同个数的字典
n = 0
while n < ab:
print("开始构造变量" + aabb[n] + "的两节点状态")
while True:
status = input("请输入起始状态")
end_status = input("请输入终止状态")
if status != '#' or end_status != '#':
l[n].setdefault(status, end_status)
else:
print(aabb[n] + "变量的构造输入已经结束")
break
n = n + 1
for i in range(len(l)):
if aabb[i] == '_':
print("空变量的节点起始关系为:" + str(l[i]))
else:
print("变量" + aabb[i] + "的节点起始关系为:" + str(l[i]))
print(l)
# 空变量的节点起始关系为:{'2': '3', '1': '4', '5': '6'}
# 变量a的节点起始关系为:{'1': '4', '3': '5'}
# 变量b的节点起始关系为:{'5': '2', '3': '5'}
key_list = []
for i in range(len(l)):
for k in l[i].keys():
if k not in key_list:
key_list.append(k)
print("状态节点有:", end=" ")
# {1,2,3,4,5}
printlist(key_list)
print()
start = input('请输入起始节点')
end_list = []
a = ""
while a != "#":
a = input("请输入终止节点(集),以#表示结束")
end_list.append(a)
end_list.pop()
print("起始节点是:" + start)
print("终止节点(集)是:", end="")
printlist(end_list)
# 变量a的节点起始关系为:{'1': '2', '3': '4'}
# 变量b的节点起始关系为:{'1': '3', '5': '2'}
# 空变量的节点起始关系为:{'2': '3', '4': '5'}
# 状态节点有: 1 3 5 2 4
# 请输入起始节点1
# 请输入终止节点(集),以#表示结束3
# 请输入终止节点(集),以#表示结束#
# 起始节点是:1
# 终止节点(集)是:3
print()
print("\\n-------------------将状态节点保存到文件中-----------------")
with open('nfa.txt', 'w') as f:
f.write(start + "\\n")
for i in range(len(end_list)):
f.write(end_list[i] + " ")
f.write("\\n")
for j in range(len(l)): # j表示第几个字典
for k in range(len(l[j])): # k表示第几个键值对
for m in l[j].keys(): # m表示第几个键
f.write(m + " " + aabb[j] + " " + l[j][m] + "\\n")
print("\\n------------------读取文件中的信息----------------------")
with open('nfa.txt', 'r') as r:
nfa = []
for line in r.readlines(): # 将文件数据内容保存到nfa列表当中
line_rstrip = line.rstrip('\\n')
nfa.append(line_rstrip)
# print(nfa)
begin_start = nfa[0].split() # 起始节点
#print(begin_start)
end_end_list = nfa[1].split() # 终止节点
#print(end_end_list)
# 如果是按照前面的方法创建的,那么以上代码没有必要,直接用start和end_list即可
trans_nfa = nfa[2:]
#print(trans_nfa)
for i in range(len(trans_nfa)):
trans_nfa[i] = trans_nfa[i].split()
#print(trans_nfa)
# #[['1', 'a', '2'], ['3', 'a', '4'], ['1', 'a', '2'], ['3', 'a', '4'], ['1', 'b', '2'], ['3', 'b',
# '4'], ['1', 'b', '2'], ['3', 'b', '4'], ['1', '_', '2']] 所有的状态已经标识好了
state_to_draw = [] # 状态节点
para_to_draw = [] # 转换变量
for i in range(len(trans_nfa)):
state_to_draw.append(trans_nfa[i][0])
state_to_draw.append(trans_nfa[i][2])
para_to_draw.append(trans_nfa[i][1])
# print(state_to_draw)
# print(para_to_draw)
state0 = list(set(state_to_draw)) # 去除节点重复
state0.sort(key=state_to_draw.index) # 对节点进行排序
para0 = list(set(para_to_draw))
para0.sort(key=para_to_draw.index)
# print(state0) # ['0', '1', '2', '4', '3', '6', '5', '7', '8', '9', '10']
# print(para0) # ['_', 'a', 'b']
if '_' in para0:
para0.remove('_')
# 去掉空
_closure = dict() # 表示空串可以到达的集合
print("\\n--------------开始作图-------------------")
from graphviz import Digraph
def draw_nfa():
g = Digraph('G', filename='nfa.gv', format='png')
for i in range(len(trans_nfa)):
g.edge(trans_nfa[i][0], trans_nfa[i][2], label=trans_nfa[i][1])
for i in range(len(begin_start)):
g.node(begin_start[i], color='red')
for i in range(len(end_end_list)):
g.node(end_end_list[i], shape='doublecircle')
g.view()
draw_nfa()
print("\\n------------nfa作图完毕------------------")
print("\\n-----------开始进行NFA转DFA---------------")
## 寻找所有空闭包
for i in range(len(state0)):
res = [state0[i]] # 第i个节点
# print(res)
for j in range(len(trans_nfa)):
if trans_nfa[j][0] == state0[i] and trans_nfa[j][1] == '_':
# 如果目前研究的节点里面存在着空
res.extend(trans_nfa[j][2])
# 这里用
_closure[state0[i]] = list(set(res))
# 到此,一个状态所有的空闭包都会显现出来,接下来只要一查到底即可
# print(_closure)
# {'0': ['1', '0', '7'], '1': ['1', '2', '4'], '2': ['2'], '4': ['4'], '3': ['6', '3'], '6': ['7', '6', '1'], '5': ['5', '6'], '7': ['7'], '8': ['8'], '9': ['9'], '10': ['10']}
# 空闭包的递归查询------
def find_closure(state_input):
state_now = _closure[state_input] # 查询输入一个状态下是否有空闭包 ['1', '0', '7']
state_now_list = []
for state_now_para in state_now:
state_now_list = state_now_list + _closure[state_now_para] # 递归查询
state_now_list = list(set(state_now_list))
## 尝试输出
#print(state_now_list) # ['0', '7', '1', '2', '4']
while set(state_now) != set(state_now_list): # 多次查询
state_now = state_now_list
state_now_list = []
for state_now_para in state_now:
state_now_list = state_now_list + _closure[state_now_para]
state_now_list = list(set(state_now_list))
return state_now_list
A = find_closure(state0[0]) # 初始状态的空闭包
#print(A) # ['1', '7', '4', '2', '0']
def find_state(l_state):
res = dict() # 创建一个字典,里面的值是状态集合
for c in para0: # ['_', 'a', 'b']
res_two = []
for i in range(len(l_state)):
for j in range(
len(trans_nfa)): # [['0', '_', '1'], ['1', '_', '2'], ['1', '_', '4'], ['2', 'a', '3'], ['3', '_', '6'], ['4', 'b', '5'], ['5', '_', '6'], ['6', '_', '7'], ['7', 'a', '8'], ['8', 'b', '9'], ['9', 'b', '10'], ['6', '_', '1'], ['0', '_', '7']]
if trans_nfa[j][0] == l_state[i] and trans_nfa[j][1] == c:
res_two.append(trans_nfa[j][2])
result = []
for k in res_two:
result = result + find_closure(k)
res[c] = list(set(result))
return res
number = 0
length = 1
state_list = []
state_list.append(A) # [['0', '7', '1', '2', '4']]
while number < length:
A2 = find_state(state_list[number])
number = number + 1
for c in para0:
temp = 1
for p in range(length):
if set(A2[c]) == set(state_list[p]):
temp = 0
if temp == 1:
state_list.append(A2[c])
length = length + 1
#print(state_list)
# [['0', '2', '4', '1', '7'],
# ['2', '3', '6', '4', '8', '1', '7'],
# ['2', '6', '4', '5', '1', '7'],
# ['9', '2', '6', '4', '5', '1', '7'],
# ['2', '6', '4', '10', '5', '1', '7']]
#获取开始节点和结束节点
dfa_begin = []
dfa_end = []
for i in range(len(begin_start)):
# 查看是否存在空……变量
dfa_begin.append(find_closure(begin_start[i]))
for j in range(len(end_end_list)):
for k in range(len(state_list)):
if end_end_list[j] in state_list[k]:
#如果nfa的结束节点是在我的某一个状态列表里面
if state_list[k] not in dfa_end:
dfa_end.append(state_list[k])
print(dfa_begin)
print(dfa_end)
while [] in state_list:
state_list.remove([])
print('DFA状态表: ', state_list)
print("DFA起始状态: ", dfa_begin)
print("DFA终止状态:", dfa_end)
# DFA状态表为: [['4', '2', '0', '1', '7'], ['4', '2', '1', '7', '8', '3', '6'], ['4', '2', '1', '7', '6', '5'], ['4', '2', '1', '7', '9', '6', '5'], ['4', '2', '1', '7', '10', '6', '5']]
# DFA开始状态: [['4', '2', '0', '1', '7']]
# DFA终止状态: [['4', '2', '1', '7', '10', '6', '5']]
def draw_dfa(state_list, begin, end):
g = Digraph('G', filename='dfa.gv', format='png')
begin_aaa = []
end_aaa = []
for i in range(len(begin)):
begin_aaa.append(" ".join(sorted(begin[i])))
for j in range(len(end)):
end_aaa.append(" ".join(sorted(end[j])))
for i in range(len(state_list)):
dicttttt = find_state(state_list[i])
for j in para0:
if state_list[i] != [] and dicttttt[j] != []:
g.edge(" ".join(sorted(state_list[i])), " ".join(sorted(dicttttt[j])), label=j)
for k in range(len(begin_aaa)):
g.node(begin_aaa[k], color='red', shape='circle')
for i in range(len(state_list)):
g.node(" ".join(sorted(state_list[i])), color='blue', shape='circle')
for j in range(len(end_aaa)):
if end_aaa[j]!=begin_aaa[0]:
g.node(end_aaa[j], shape='doublecircle')
else:
g.node(end_aaa[j], shape='doublecircle',color='red')
g.view()
draw_dfa(state_list, dfa_begin, dfa_end)
state_dfa_other_name=[ chr(65+i) for i in range(len(state_list))]
#['A', 'B', 'C', 'D', 'E']
start_char=state_dfa_other_name[ state_list.index(dfa_begin[0])]
start_char=list(start_char)
print(start_char)
end_char=[]
for i in range(len(dfa_end)):
s=state_dfa_other_name[state_list.index(dfa_end[i])]
end_char.append(s)
print(end_char)效果图: