测开之内存管理篇・《内存管理机制》
Posted 七月的小尾巴
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了测开之内存管理篇・《内存管理机制》相关的知识,希望对你有一定的参考价值。
内存管理机制
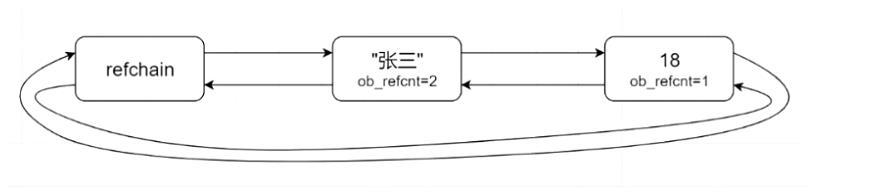
在python中创建对象的时候,首先会去申请内存地址,然后对这个对象进行初始化,所有的对象都会维护在一个叫做 refachain 的双向循环链表中,每个数据都保存如下信息:
- 链表中数据前后数据的指针
- 数据的类型
- 数据值
- 数据的引用计数
- 数据的长度(list,dict…)
引用计数机制
引用计数增加:
- 对象被创建
- 对象被别的变量应用(另外起了一个名字)
- 对象被作为元素,放在容器中(比如被当着元素放在列表或者字典中)
- 对象被当成参数传递进函数中
引用计数的减少:
- 对象的别名被显式的销毁
- 对象的一个别名被赋值给其他对象(例如:原来的a=10,我们改成a=100,那么此时10的引用计数就减少了)
- 对象从容器中移除,或者容易被销毁(例:对象从列表中移除,或者列表被销毁)
- 一个引用离开了他的作用域(调用函数的时候传进去的参数,在函数运行结束后,该参数的引用被销毁)
上面这么描述可能有写抽象,下面我们通过实例具体查看一下
>>> a = 1000
>>> print(id(a))
140728749462288
首先当我们创建一个变量a的时候,此时python解释器会给a这个变量分配一个内存地址,我们可以看到上方a的内存地址是 140728749462288。
那么假设现在我们现在设置b 的a,然后使用 sys.getrefcount(a),查看这个a这个对应的引用计数,我们可以看到是3。
>>> a = 1000
>>> b = a
>>> sys.getrefcount(a)
3
为什么这里会变成3了,因为当我们a赋值一个变量时,此时引用计数是1次,然后我们使用b赋值等于a时,此时引用计数应该是2次,之所以是3次是因为 sys.getrefcount(a)自身是一个函数,那么当我们 对象被当成参数传递进函数中,因此引用计数为3。
那么剩下的我们也不难理解,当我们的对象放在列表、字典等容器中,会也计数一个。
数据池和缓存
小整数池
下面我们在来看一个非常有意思的现象:
>>> a = 1000
>>> b = 1000
>>> print(id(a))
2334204996144
>>> print(id(b))
2334204997136
首先,我们分别定义 a、b两个变量,此时设置的变量值是一致的,都是1000,我们去查看python底层分配的内存地址,可以看到他们的内存地址是不一样的。
那么下面我们将a和b的变量值,都改成1,再来看看:
>>> a = 1
>>> b = 1
>>> print(id(a))
140728749459120
>>> print(id(b))
140728749459120
那么我们来思考一下,为什么创建了两个不同的对象,但是内存地址却是一样的呢?
python自动将-5~256的整数进行了缓存到一个小整数池中,当你将这些整数赋值给变量时,并不会重新创建对象,而使用已经创建好的缓存对象,当删除这些数据的引用时,也不会进行回收。
Intern机制
那么此时假设我们的变量值包含数字、字母和符号,我们来查看一下他具体的内存空间分配
>>> a = 'acb23?'
>>> b = 'acb23?'
>>> print(id(a))
2334205039216
>>> print(id(a))
2334205039216
可以看到他们的内存地址也是一样的。这里我们需要了解一下 intern机制。
intern机制:它的优点是,在创建新的字符串对象时,会先在缓存池里面找是否有已经存在的相同值的对象(标识符、字母、下划线的字符串),如果有,则直接拿过来(引用),避免频繁的创建和销毁内存,提升效率。
Python中的ASCII码中的字符,分配的内存地址也是相同的。
缓存机制
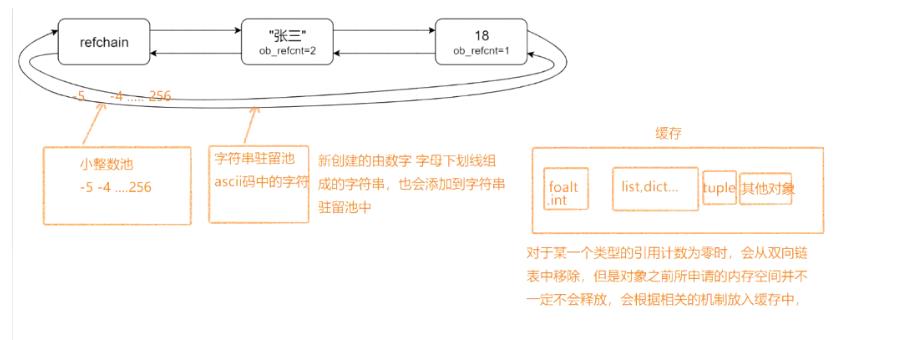
- float、int、list等一些内置的数据类型,会缓存80个对象
- 元祖会根据元祖数据长度,分别缓存元祖长度0-20的对象
- 其他的类型缓存2个对象
垃圾回收机制
python的垃圾回收机智可以用一句话来形容: 引用技术机制为主,标记-清除和分代收集两种机制为辅策略。
引用计数
- 引用计数:在之前对象的引用我们讲到了,每个对象创建之后都会有一个引用计数,当引用技术为0的时候,那么此时垃圾回收机智会把他笑会,回收内存空间。
- 引用计数存在一个缺点,那就是当两个对象出现循环引用的时候,那么这两个变量始终不会被销毁,这样就会导致内存泄露。
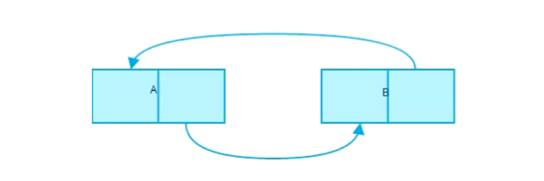
标记清除

下面这里是关于标记清楚的截图,下面我会结合分代回收一起讲。
分代回收机制
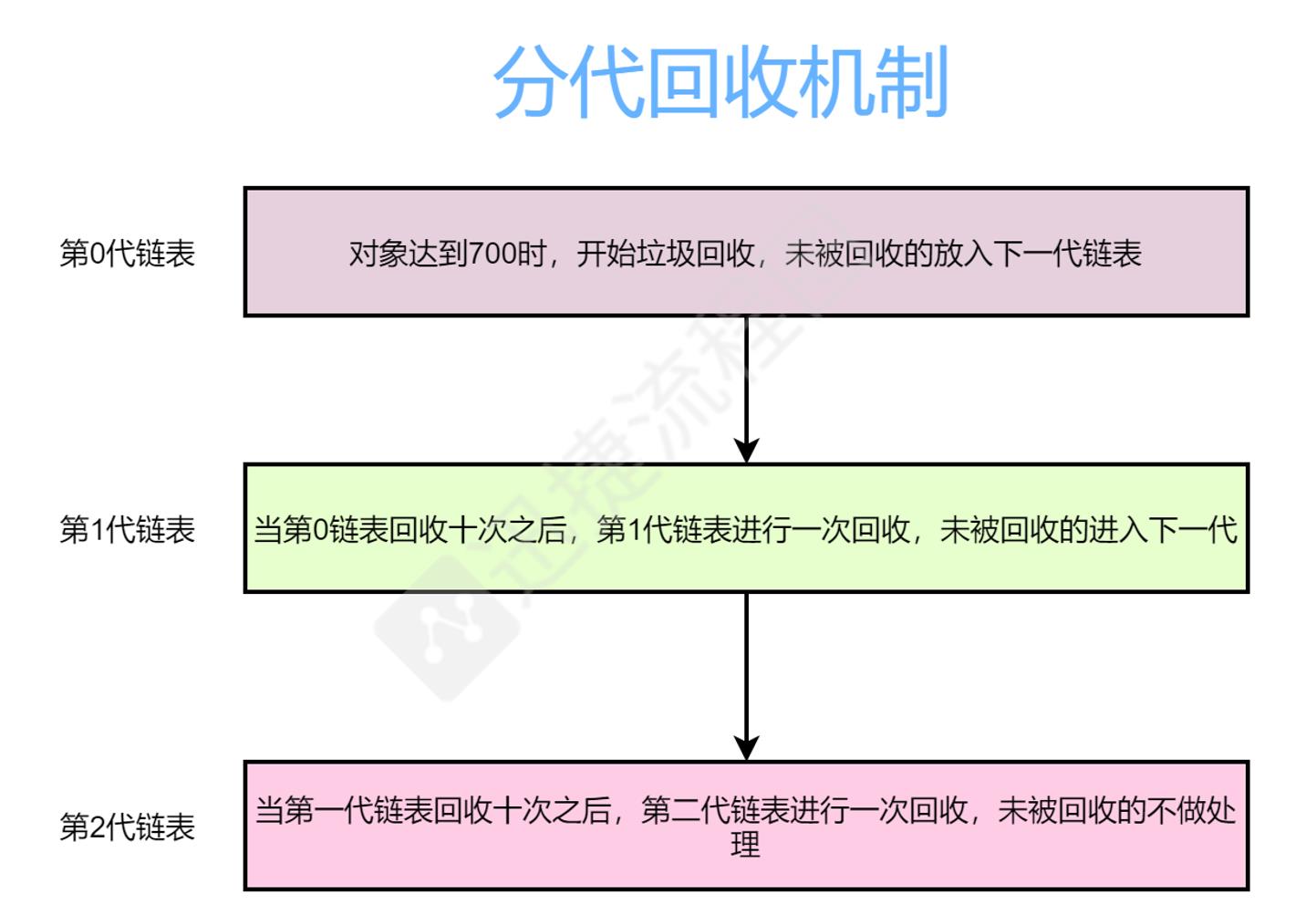
首先,我们在python中,会判断当一个对象的引用计数达到700时,就会进行垃圾回收机制。当我们执行第0代链表时,标记清除会判断一个对象的变量引用是否是全局变量,如果是全局变量,那么会收集所有引用全局变量的直接变量和间接变量,这些变量将不会被标记清除。
我们现在来看上面标记清除的图片,假设上方的圆点是全局变量,那么1、2、3三个对象就是全局变量的直接变量和间接变量,那么在执行垃圾回收机制时,这三个对象的内存将不会被销毁。4和5并没有引用全局变量,因此在回收过程中,该变量会被清除。
当我们第0代链表执行结束之后,此时会在进入第一代链表,回收机制如上图所示,不在做赘述。
这里需要注意的是,当我们程序初始化的时候,python底层可能也会引用某些变量,并不是单单指的是我们程序中执行定义的变量的引用次数。
以上是关于测开之内存管理篇・《内存管理机制》的主要内容,如果未能解决你的问题,请参考以下文章