测开之并发编程篇・《并发并行线程队列进程和协程》
Posted 七月的小尾巴
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了测开之并发编程篇・《并发并行线程队列进程和协程》相关的知识,希望对你有一定的参考价值。
并发编程
并发和并行
多任务概念
多任务的概念简单的说,就是我们的操作系统可以同时运行多个任务。

cpu与多任务的关系:
首先我们来思考一下,单核cpu可不可以执行多个人任务?
- 答案是可以的。由于CPU执行代码都是顺序执行的,操作系统会轮流让各个任务交替执行,假设任务1执行耗时0.01s,切换到任何2,任何2执行0.01秒,在切换到任何3,执行0.01秒…这样反复执行下去,表面上看,每个任务都是交替执行的,但是由于CPU的执行速度是在太快了,我们感觉就像任务在同时运行一样。
- 真正的并行执行多任务,只能在多核CPU上实现,但是,由于任务数量远远多于CPU的核心数量,所以,操作系统也会自动把多任务轮流调度到每个核心上执行。
并发和并行
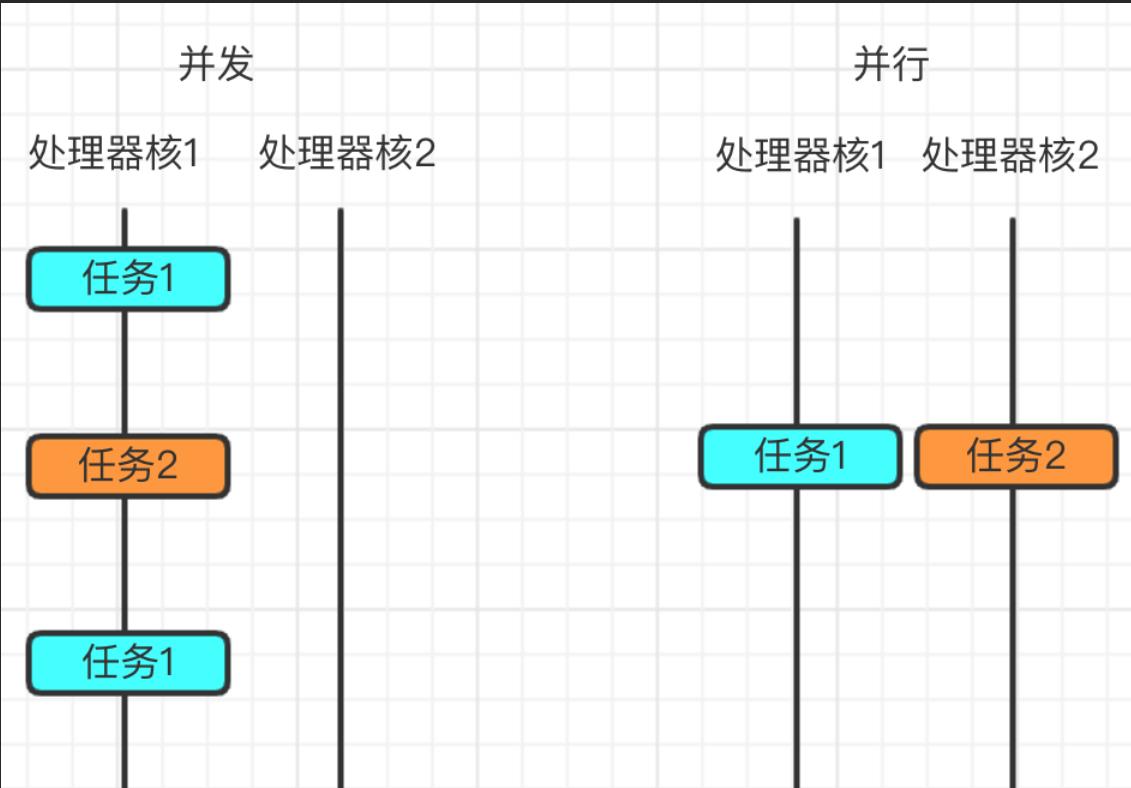
- 并发:指的是任务数多余cpu核数,通过操作系统的各种任务调度算法,实现用多个任务“一起”执行(实际上总有一些任务不在执行,因为切换任务的速度相当快,看上去一起执行而已)
- 并行:指的是任务数小于等于cpu核数,即任务真的一起执行。
下面这张图可以看出并发和并行之间区别:
同步和异步
- 同步(协同步调):是指线程在访问某一个资源时,获取了资源的返回结果之后才会执行其他操作(先做某件事,在做某些事)
- 异步(步调各异):与同步相对,是指线程在访问某一资源时,无论是否取得返回结果,都进行下一步操作;当有了资源返回结果时,系统自会通知线程。
多线程
threading 模块介绍
python 中 的 thread 模块是比较底层的模块,python 的 threading 模块是对thread做了一些包装的,可以更加方便的被使用。
# 创建线程对象
threading.Thread(target=func)
# 参数 target 指定线程执行的任务(函数)
| 方法 | 说明 |
|---|---|
run() | 用以表示线程活动的方法 |
start() | 启动线程活动 |
join([time]) | 设置主线程会等待time秒后在往下执行,time默认为子线程结束,多个子线程之间设置的值会叠加 |
下面我们用代码来实现多线程:
import time
from threading import Thread
def work1():
for i in range(5):
time.sleep(1)
print("work1-这里是函数1--{}".format(i))
def work2():
for i in range(6):
time.sleep(1)
print("work2--这里是函数2-{}".format(i))
def work3():
for i in range(6):
time.sleep(1)
print("work3--这里是函数3-{}".format(i))
if __name__ == '__main__':
s_t = time.time()
# 创建一个线程
t1 = Thread(target=work1)
# 执行线程
t1.start()
# 创建一个线程:
t2 = Thread(target=work2)
t2.start()
# 创建一个线程:
t3 = Thread(target=work3)
t3.start()
# 主线程等待子线程执行
t1.join()
t2.join()
t3.join()
e_t = time.time()
print(e_t - s_t)
结果:
work2--这里是函数2-0
work3--这里是函数3-0
work1-这里是函数1--0
work3--这里是函数3-1work1-这里是函数1--1
work2--这里是函数2-1
work3--这里是函数3-2work2--这里是函数2-2work1-这里是函数1--2
work1-这里是函数1--3work2--这里是函数2-3work3--这里是函数3-3
work2--这里是函数2-4work3--这里是函数3-4
work1-这里是函数1--4
work3--这里是函数3-5
work2--这里是函数2-5
6.097839832305908
按照我们上方的代码,如果不是多线程执行的话, work1、 work2、 work3分别需要执行5s、6s、6s。按照单线程模式执行,他们总共需要执行17s,那么此时我们通过 threading.Thread(target=func) 来创建多线程,线程之间会同步执行。
自定义线程类
上面我们讲的是多线程多个任务去执行,那么假设我们现在有一个需求场景,需要实现同一个功能函数实现多线程执行,应该怎么实现呢?
我们可以定义一个自定义的线程类:
import time
from threading import Thread
class MyThread(Thread):
def run(self):
for i in range(1, 100):
time.sleep(0.01)
print("{}请求第{}次".format(self.name, i))
if __name__ == '__main__':
# 定义5个线程
for i in range(5):
t = MyThread(name='线程{}'.format(i + 1))
t.start()
下面我们可以看一下Thread中的初始化方法参数
class Thread:
"""A class that represents a thread of control.
This class can be safely subclassed in a limited fashion. There are two ways
to specify the activity: by passing a callable object to the constructor, or
by overriding the run() method in a subclass.
"""
_initialized = False
def __init__(self, group=None, target=None, name=None,
args=(), kwargs=None, *, daemon=None):
上面我们可以看到,Thread初始化参数中,可以传 target、name、group,我们来看一下这三个参数分别是做什么用的。
- target:指定任务函数
- name:指定线程名
- group:指定线程分组
线程任务函数的传递
在我们编写程序时,通常有些类或者函数,我们需要传递参数,那么通过多线程的形式,threading.Thread(target=func) 我们所传递的是函数名称,参数在多线程中应该如何传递呢?
在上方源码中,初始化参数我们可以看到,还有 args=(), kwargs=None,其中args是已元组的形式传递,而kwargs我们可以传字典类型的参数。
下面我们来看一下函数的传递方式:
from threading import Thread
def work1(name, age):
for i in range(5):
time.sleep(1)
print("{}work1-打孔--{}-年龄{}".format(name, i, age))
if __name__ == '__main__':
# 给任务函数传递参数:
# 方式一:args(args是一个元组)
Thread(target=work1, args=('张三',19)).start()
# 方式二: kwargs (kwargs是一个字典)
Thread(target=work1, kwargs={'name': "张三", "age": 18}).start()
字典实现传参的方式:
class MyThread(Thread):
def __init__(self, url):
# 使用父类方法
super().__init__()
# 初始化url,因为在多线程中,参数被默认为私有属性
# 因此我们可以初始化我们的请求参数,在程序中使用此参数
self.url = url
def run(self):
args = self.url
print(args)
for i in range(10):
time.sleep(0.1)
print("{}请求第{}次".format(self.name, i))
if __name__ == '__main__':
# 自定义线程类 参数 传递 需要重写init方法 在init方法中保存参数即可
t1 = MyThread(url='www.baidu.com')
t1.start()
Thread(target=work1, args=('张三', 19)).start()
多线程资源共享和资源竞争问题
在我们使用多线程时,可能会出现一些问题,如果不了解情况的小伙伴在初期使用多线程时会出现一些问题,下面我们来用一个简单例子讲解:
from threading import Thread
a = 0
def work1():
global a
for i in range(10000000):
a += 1
print("这是函数1------a:", a)
def work2():
global a
for i in range(10000000):
a += 1
print("这是函数2------a:", a)
if __name__ == '__main__':
t1 = Thread(target=work1)
t1.start()
t2 = Thread(target=work2)
t2.start()
t1.join()
t2.join()
print("主线程---全局a:", a)
结果:
work1------a: 12195902
work2------a: 12479479
主线程---全局a: 12479479
首先我们来定义一个全局变量 a ,那么按照我们正常的单线程执行这两个函数时,函数中使用for循环,并且每执行一次 a 的变量值就会+1,我们循环执行 10000000次,最终a的变量值应该是 2000000。但是当我们多线程执行时,会发现 a 这个全局变量值变成了12479479。
那么究竟是因为什么呢?
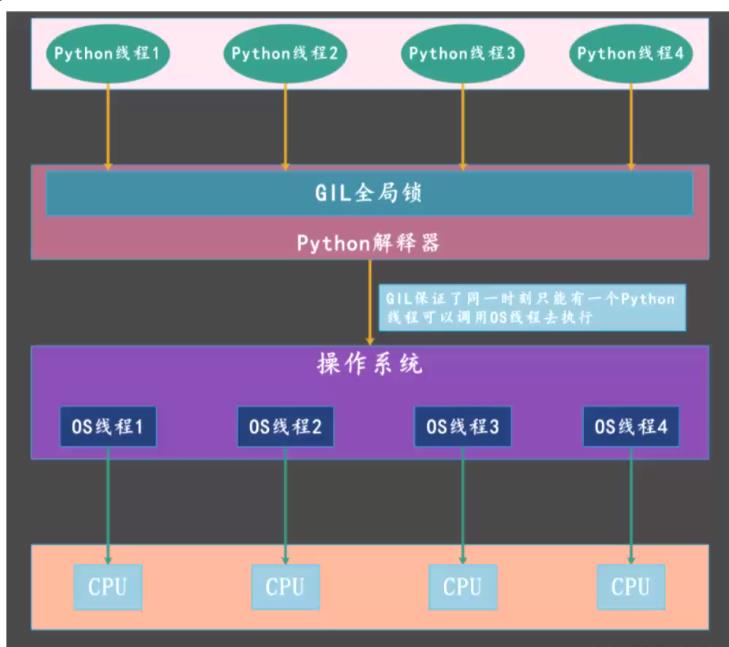
这里主要是因为多线程是共享全局变量的,python的多线程都是无法并行执行,多线程无法利用多核cpu的资源,在同一时间,只能有一个线程真正执行,原因是因为python解释器中有一把 GIL(全局解释器锁),这个是python的设计缺陷。
GIL 全局解释锁
GIL 是最流程的 CPython 解释器(平常称为 Python)中的一个技术术语,中文译为全局解释器锁,其本质上类似操作系统的 Mutex。GIL 的功能是:在 CPython 解释器中执行的每一个 Python 线程,都会先锁住自己,以阻止别的线程执行。
线程释放GIL的情况:线程执行遇到IO耗时操作或者说线程执行时间达到一个阈值,ticket达到100时,线程会释放GIL。
互斥锁
- 线程同步能够保证多个线程安全访问竞争资源,最见到那的同步机制就是引入互斥锁。
- 互斥锁为资源引入一个状态,锁定/非锁定
- 某个线程要更改共享数据时,先将其锁定,此资源的状态该为“锁定”,其他线程不能更改直到该线程释放资源,将资源状态变成“非锁定”,其他的线程才能再次锁定该资源
- 互斥锁保证了每次只有一个线程进行写入操作,从而保证了多线程情况下数据的正确性
- Threading模块中定义了Lock类,可以方便的处理锁定:
# 创建锁
mutex = threading.Lock()
# 锁定
mutex.acquire()
# 释放
mutex.release()
注意:
- 如果这个锁之前时没有上锁的,那么acquire不会堵塞
- 如果在调用acquire对这个锁上锁之前,他已经被其他线程上了锁,那么此时acquire会堵塞,知道这个锁解锁为止。
通过锁解决资源竞争问题
那么上面我们既然出来了资源竞争问题,那么就会有专门针对这个的解决方案,我们可以使用 Lock 去创建一把锁,当我线程执行是引用了这个全局变量,我们可以使用 mutex.acquire()方法进行上锁,当我们使用完成之后,就可以使用 mutex.acquire()解锁。
下面我们来看一下具体代码的实现:
from threading import Thread, Lock
a = 0
# 创建一把锁
mutex = Lock()
def work1():
global a
for i in range(100000):
# 上锁
mutex.acquire()
a += 1
# 释放锁
mutex.release()
print("work1------a:", a)
def work2():
global a
for i in range(100000):
# 上锁
mutex.acquire()
a += 1
# 释放锁
mutex.release()
print("work2------a:", a)
if __name__ == '__main__':
t1 = Thread(target=work1)
t1.start()
t2 = Thread(target=work2)
t2.start()
t1.join()
t2.join()
print("主线程---全局a:", a)
死锁
在线程共享多个资源的时候,如果两个线程分别占有一部分资源并且同时等待对方的资源,就会造成死锁。尽管死锁很少发生,但是一旦发生就会造成应用停止响应。下面我们来看一下一个死锁的例子。
import threading
import time
class MyThread1(threading.Thread):
def run(self):
# 对mutexA上锁
mutexA.acquire()
print(self.name + '----上锁----')
time.sleep(1)
mutexB.acquire()
print(self.name + '----上锁----')
mutexB.release()
mutexA.release()
class MyThread2(threading.Thread):
def run(self):
# 对mutexB上锁
mutexB.acquire()
print(self.name + '----上锁----')
time.sleep(1)
mutexA.acquire()
print(self.name + '----上锁----')
mutexA.release()
mutexB.release()
mutexA = threading.Lock()
mutexB = threading.Lock()
if __name__ == '__main__':
t1 = MyThread1()
t2 = MyThread2()
t1.start()
t2.start()
队列
- python的 Queue模块中提供了同步的、线程安全的列队类,包括:FIFO (先入先出)队列、LIFO(后入先出队列)、优先级队列,这些队列都实现了锁原语,能够在多线程中直接使用,可以使用队列来实现线程间的同步。
- 初始化 Queue()对象时(列如:q=Queue()),若括号中没有指定最大可接受的消息信息,或数据为负值,那么就代表可接受的消息数量没有上限
队列的方法
# 返回当前队列包含的消息数据
Queue.qsize()
# 判断如果队列为空,返回 Ture,反之 False
Queue.empty()
# 如果队列满了,返回 Ture,反之 False
Queue.full()
# 获取队列, block表示是否等待,timeout则表示等待时长
Queue.get(self, block=True, timeout=None)
# 写入队列
Queue.put(self, item, block=True, timeout=None)
# 从队列中获取数据,如果队列中没有数据,则直接抛出异常
# 感兴趣的朋友,可以看底层源码,这里相当是在 Queue.get(block=Flase)
Queue.get_nowait()
# 从队列中写入输入数据,如果队列中设置队列数量,队列数据已满,正常会处于等待状态
# 这里使用如下方法,已满则直接抛出异常
Queue.put_nowait()
# 完成一项工作后,使用 Queue.task_done() 方法可以向队列中发送一个信号,表示该任务执行完毕
Queue.task_done()
# 实际上意味着等待队列中所有任务(数据)执行完毕之后,再往下,否则一致等待
Queue.join()
FIFO先入先出队列
from queue import queue
LIFO 后入先出队列
from queue import lifoQueue
优先级队列
from queue import ProioityQueue
# 队列中元素为元组类型:(优先级、数据)
以上三种属于消息队列的类型,队列中所有的方法都是相同的,他们采用的是继承的概念,区别主要是,如先入先出,在队列中我们先将这个队列存入进去时,在获取时,他会优先获取这个队列的数据,其他队列类型也就顾名思义。
进程
什么是进程
在我们工作中,如PyChram、QQ这些程序,他们都是进程,进程是操作系统分配资源的基本单元。不仅可以通过线程完成多任务,进行也是可以的。
进程的状态
在工作中,任务数往往会大于cpu的核数,即一定有一些任务正在执行,而另外一些任务在等待cpu进行执行,因此导致有了不同的状态。
进程中的状态主要有三种:
- 就绪状态:运行的条件都已经满足了,正在等待cpu执行
- 执行状态:cpu正在执行其功能
- 等待状态:等待某些条件满足,例如一个程序slepp了,此时就处于等待状态
进行、线程对比
- 功能
1、进行能够完成多任务,比如在一台电脑上能够同时运行多个软件
2、线程,能够完成多任务,比如一个QQ中的多个聊天窗口 - 定义的不同
1、进程是系统进行资源分配的单位
2、线程是进程的一个实体,是CPU调度和任务分配的基本单位,它是笔进程更小的能独立运行的基本单位。线程自己基本上不拥有系统资源,只拥有一点运行中必不可少的资源(比如程序计数器,一组寄存器和栈),但是它可与同一个进程的其他线程共享进程所拥有的全部资源。
下面我们来实现一个多进程的例子
from multiprocessing import Process
import os
a = 0
def work1():
global a
for i in range(100000):
a += 1
print("子进程号{}--work2------a:", os.getpid(), a)
print('父进程id:',os.getppid())
def work2():
global a
for i in range(100000):
a += 1
print("子进程号{}--work2------a:", os.getpid(),a)
print('父进程id:', os.getppid())
def mian():
# 参数,daemon=True,设置进程是否作为守护进程,如果是守护进程,那么该子进程会同主进程一起被关闭
# p = Process(target=work1,daemon=True)
p = Process(target=work1)
p.start()
p2 = Process(target=work2)
p2.start()
# p.join()
# p2.join()
if __name__ == '__main__':
# 注意点:windows下 程序中如果有使用多进程,程序的入口一定要写在 if __name__ == '__main__'里面:
print('主进程a:',os.getpid(), a)
mian()
进程间的通信
queue.Queue和multiprocessing.Queue 有什么区别 ?
- queue.Queue: 只能在同一个进程中的多个线程之间使用
- multiprocessing.Queue:可以再多个进程之间跨进程输出数据(通信)
可以使用 multiprocessing 模块中的 Queue 实现多进程之间的数据传递,Queue 本身就是一个消息队列程序,首先用一个小实例来显示一下Queue的工作原理:
from multiprocessing import Process, Queue
import time
def work(urls):
while not urls.empty():
url = urls.get()
print(url)
time.sleep(0.5)
def main():
urls = Queue()
for i in range(100):
urls.put(f"https://www.baidu.com-{i}")
# 创建4个线程
start_time = time.time()
ts = []
for i in range(4):
t1 = Process(target=work, args=(urls,))
t1.start()
ts.append(t1)
for t in ts:
t.join()
end_time = time.time()
print('执行时间为:', end_time - start_time)
if __name__ == '__main__':
main()
线程池
程池在系统启动时即创建大量空闲的线程,程序只要将一个函数提交给线程池,线程池就会启动一个空闲的线程来执行它。当该函数执行结束后,该线程并不会死亡,而是再次返回到线程池中变成空闲状态,等待执行下一个函数。
此外,使用线程池可以有效地控制系统中并发线程的数量。当系统中包含有大量的并发线程时,会导致系统性能急剧下降,甚至导致 Python 解释器崩溃,而线程池的最大线程数参数可以控制系统中并发线程的数量不超过此数。
官网:https://docs.python.org/dev/library/concurrent.futures.html
concurrent.futures模块提供了高度封装的异步调用接口
ThreadPoolExecutor:线程池,提供异步调用
Both implement the same interface, which is defined by the abstract Executor class.
1、submit(fn, *args, **kwargs)
异步提交任务
2、map(func, *iterables, timeout=None, chunksize=1)
取代for循环submit的操作
3、shutdown(wait=True)
相当于进程池的pool.close()+pool.join()操作
wait=True,等待池内所有任务执行完毕回收完资源后才继续
wait=False,立即返回,并不会等待池内的任务执行完毕
但不管wait参数为何值,整个程序都会等到所有任务执行完毕
submit和map必须在shutdown之前
4、result(timeout=None