机器学习sklearn----初识KMeans
Posted iostreamzl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习sklearn----初识KMeans相关的知识,希望对你有一定的参考价值。
概述
KMeans是一种无监督学习的方法。他是一种分类算法。用于探索原始数据,将原始数据中相同属性的样本归为一类。这篇文章只讲KMeans的简单使用,关于评估结果好坏的内容,看我下一篇文章。
KMeans中几个概念
- 簇: 即分组,KMeans将数据分为K个簇,簇间差异大,簇内差异小
- 质心: 簇中所有数据的均值就是该簇的质心。例如二维平面中一个簇的点的质心为该簇中所有点很纵坐标坐标的均值
- 簇内误差: 样本点到他所在的质心的距离之和,用来衡量簇的差异
KMeans工作过程
- 随机抽取K个样本点,作为初始质心
- 将每个样本划分到离他最近的质心所在簇
- 将每个样本分好簇后,计算每个簇的新的质心
- 重复2,3过程,知道新的质心不在产生变化
KMeans使用示例
导入相关模块
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
import warnings
%matplotlib inline
# 忽略警告
warnings.filterwarnings("ignore")
生成原始数据
这里使用sklearn中make_blobs方法来产生原始数据,关于该方法的使用,看我的另一篇文章。这里用这个方法生成的数据会返回标签(即每个样本所属的分类),方便验证KMeans的结果。
# 产生用于KMeans聚类的数据
# 在实际的生活中,我们并不会知道数据的分簇情况,这是需要我们用KMEans来探究的
X, y = make_blobs(n_samples=1000, n_features=2, centers=5, random_state=1)
# 展示原始数据
plt.figure(figsize=(8, 5))
plt.scatter(X[:, 0], X[:, 1])
# 在我们不知道原始数的分簇情况下
# 我们根据散点图可以合理的猜测,分簇情况可能为2,4,5等
# 实际中具体的要分为几个簇需要根据具体的业务来进行判断
通过KMeans分类
这里我是假设数据又4个簇(虽然我知道5个簇才是正确的,这里只是展示KMeans的使用,不必在太纠结与结果的准确度),在现实中,具体要划分为几个簇需要依据业务需求以及模型需求来确定。
通过n_clusters参数来设置需要分簇的数量
# 假设将数据分为4簇
cluster_4 = KMeans(n_clusters=4).fit(X)
# 需要说明的是,在KMeans中不需要去预测标签
# 也就是说在我们fit完成后,KMeans自动将我们的数据分为了n_cluster个簇
# 我们可以通过属性来查看每个样本对应的分簇情况,以及其他的一些数据
KMeans常用属性
labels_查看分簇结果
# 通过labels_属性查看每个样本所属的簇
cluster_4.labels_

cluster_centers_查看每个簇的质心
# 通过属性cluster_centers_来查看每个簇的质心
cluster_4.cluster_centers_
# array([[-5.98544724, -2.94134241],
# [-1.80916412, 2.65609291],
# [-7.05942132, -8.07760549],
# [-9.98028373, -3.90557712]])
inertia_查看KMeans分类结果的误差
# 通过inertia_来查看分簇的误差
cluster_4.inertia_
# 3336.779415794397
分类结果展示
# 画出聚类后的情况
plt.figure(figsize=(10,6))
plt.scatter(
x=X[:, 0],
y=X[:, 1],
c=cluster_4.labels_,
s=20
)
# 画出质心
plt.scatter(cluster_4.cluster_centers_[:, 0], cluster_4.cluster_centers_[:, 1], marker='X', s=70, c='red')
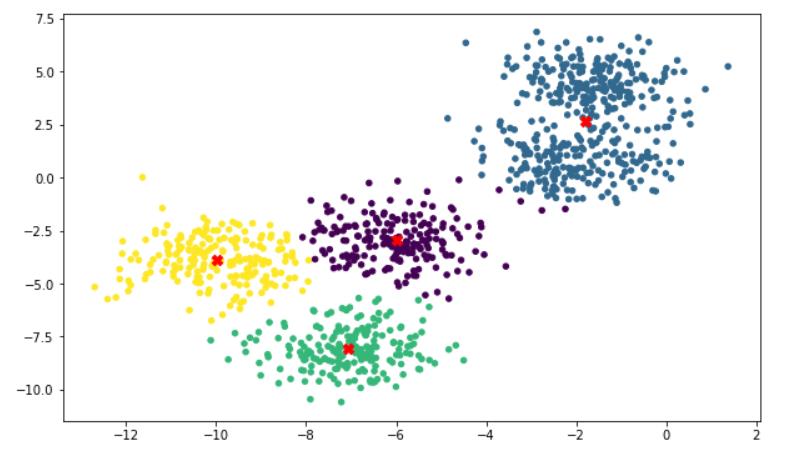
可以看出来分类的效果还是很明显的。如果原始数据只有4类的话,这个结果无疑是很正确的。
KMeans中的predict方法
在前面我们讲到KMeans其实是不需要进行结果预测的,他在fit步骤就讲数据分成了K个簇。并且可以通过属性labels_来查看分簇分段结果。那么为什么sklearn还是提供了这个接口呢。
原因:KMeans是一个十分耗时的操作(不断的计算每个样本到质心的距离)。在数据量很小的情况下我们可能很难察觉到时间的消耗。当我们的数据量比较大比如有50w的数据。那KMeans直接去运算将是一个很漫长的过程。这时候就需要用到predict方法了。在这50w的数据下,可能我们只需要2k的数据就能基本计算出这50w的数据的质心了。那么我们就可以用这2k数据训练出来的KMeans对象调用predict方法,将其余的数据进行分簇,这会大大的减少KMeans的运行时间(虽然会有一些小误差)。
总结
这里主要讲了KMeans的入门用法,关于他的一些详细内容与评估标准,会在后面的文中详细介绍。
以上是关于机器学习sklearn----初识KMeans的主要内容,如果未能解决你的问题,请参考以下文章
转:机器学习sklearn19.0聚类算法——Kmeans算法
机器学习sklearn----KMeans实例(图片数据矢量量化的应用)