python高级算法与数据结构:treap用于构造平衡二叉树的算法分析
Posted tyler_download
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python高级算法与数据结构:treap用于构造平衡二叉树的算法分析相关的知识,希望对你有一定的参考价值。
treap数据结构用于记录两个维度的索引,一个维度跟随二叉树性质,能做到完全排序,另一个维度跟随堆性质,能做到部分排序,实际上treap本质目的并不在于此,它的目的在于用来平衡二叉树。在某些情况下二叉树可能会变成链表,例如依次插入已经排好序的元素时,所有的元素会沿着节点的有孩子,这种二叉树就不具备lg(n)搜索效率。
很多方法用来解决这个问题,例如2-3树,红黑树等。这些方法存在问题在于操作相当复杂,你去搜索一下红黑树的插入或删除操作就能体会它们应用起来的复杂性。前几节详细描述了treap如何根据其节点优先级,通过左右旋转的方式来调节节点位置,其实这个操作就能用来对二叉树进行平衡,例如下图二叉树两边高度不一致:
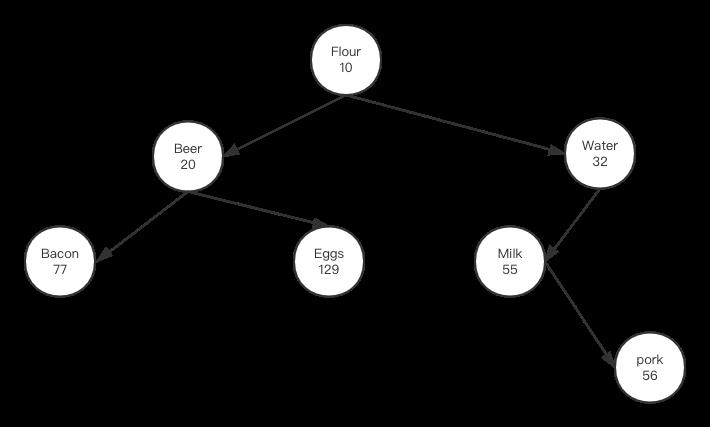
可以看到左子树比右子树矮,如果要调节两边一样高,那么我们把Milk节点的优先级改的小于其父节点Water,例如将其优先级改成31,这样Milk节点使用一次右旋转就能实现两边平衡:
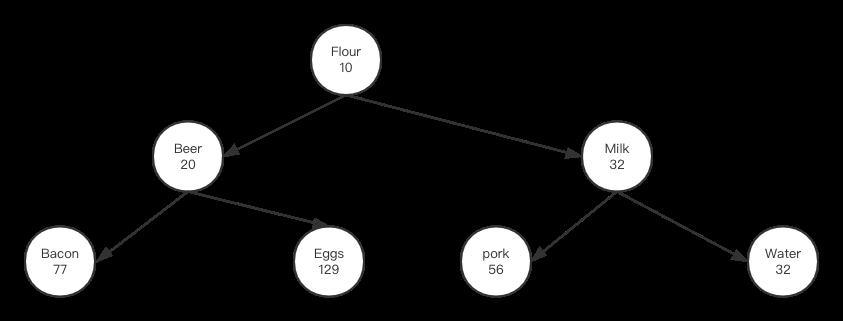
在实际应用时,简单的修改节点的优先级来实现二叉树平衡并不好做。首先我们要判断二叉树从哪个节点开始不平衡,第二是发现不平衡时,到底选哪个节点进行旋转。要解决这些难点,我们需要引入随机化。此时我们节点对应的优先级数值不再是整数,而是不大于1的小数用来表示概率。
每次有新的节点插入时,我们随机给该节点在区间[0,1]内取值,这里我们要对原来实现的插入函数进行一些修改:
def insert_random(self, key):
return self.insert(key, random.uniform(0, 1))
在代码中我们插入节点时,不再要求插入优先级,而是我们为节点获取一个区间[0,1]之间的随机值。一旦使用到随机化,我们分析其复杂度时就要着眼于数学期望。所有我们先设定一个数学期望变量 D k D_{k} Dk,它用来表示节点 n k n_{k} nk的深度,其中下标k表示,如果把n个节点根据它们对应的字符串进行排序,那么节点 n k n_{k} nk在排序后位置为第k个。
也就是说 D k D_{k} Dk表示从根节点到节点 N k N_{k} Nk总共经历了多少个节点。同时我们再定义一个随机变量 N i N_{i} Ni,如果下标为i的节点,也就是节点 n i n_{i} ni如果是节点 n k n_{k} nk的祖先,那么它就取值为1,要不然就取值为0,于是变量 D k D_{k} Dk 的值就可以表示为: D k = ∑ 0 n − 1 N i {D}_{k}=\\sum _{0}^{n-1}{N}_{i} Dk=∑0n−1Ni。计算 D k D_{k} Dk的数学期望就有E[ D k D_{k} Dk] = ∑ 0 n − 1 E [ N i ] \\sum _{0}^{n-1}E[{N}_{i}] ∑0n−1E[Ni],现在问题就在于如何计算 E [ N i ] E[{N}_{i}] E[Ni].,
我们再定义一个新变量N(i, k),它表示所有字符串大小在节点i和节点k之间的所有节点集合,如果节点i的字符串大于节点k,那么它就取所有节点对应字符串大于等于节点k但小于等于节点i的所有节点集合,如果节点i的字符小于节点k也是同理,因此有:
N
(
i
,
k
)
=
N
(
k
,
i
)
=
{
n
i
,
n
i
+
1
,
.
.
.
,
N
k
}
N(i,k)=N(k,i)=\\{{n}_{i},{n}_{i+1},...,{N}_{k}\\}
N(i,k)=N(k,i)={ni,ni+1,...,Nk}
现在我们需要证明一个引理:
对所有i!=k, 0 <= i, k <= n - 1, 如果节点
n
i
n_{i}
ni是节点
n
k
n_{k}
nk的祖先,当且仅当
n
i
n_{i}
ni的优先级是N(i,k)对应的节点集合中最小的。
我们用归纳法来进行大概证明。先看只有两个节点的情况,也就是节点 n k n_{k} nk在排好序的情况下,它紧跟着节点 n i n_{i} ni。假设节点 n i n_{i} ni是两者中最小的那个,那么此时在二叉树中会有两者情况,第一是 n i n_{i} ni位于节点 n k n_{k} nk的左子树,但由于算法必须确保所有节点满足小堆性质,由于 n k n_{k} nk的优先级大,因此 n i n_{i} ni会经过一系列旋转直到 n k n_{k} nk变成它的孩子节点,如下图所示:
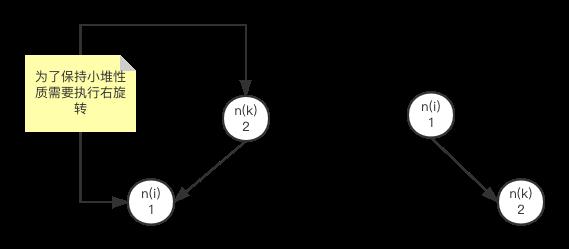
如果 n k n_{k} nk的优先级比 n i n_{i} ni小,那么道理也一样。这里需要强调的是,当N(i,k)节点集合只有2个节点时,两个节点根据他们的字符串排序后,一定是相邻的,如果他们不相邻,那么根据N(i,k)的定义,它对应的节点集合就不止两个,与我们的假设不符。
假设N(i,k)在保护t个节点的时候,该结论成立,那么我们看它包含t+1个节点的时候。假设其中节点 n i n_{i} ni的优先级最小, n k n_{k} nk的优先级最大,同时假设优先级第二大的节点为 n j n_{j} nj,根据我们前面的论证, n i n_{i} ni是 n j n_{j} nj的祖先节点,因为这两个节点满足前面证明的两个节点时的情况,此时我们把 n i n_{i} ni从集合中拿开,于是剩下的集合只包含t个节点,而且根据假设 n j n_{j} nj是 n k n_{k} nk的祖先节点,因为在剩下的t个节点中, n j n_{j} nj的优先级最小。由于 n i n_{i} ni是 n j n_{j} nj的祖先,同时 n j n_{j} nj又是 n k n_{k} nk的祖先,因此 n i n_{i} ni就是 n k n_{k} nk的祖先。
接下来我们求解 E [ N i ] E[{N}_{i}] E[Ni]的值,当 n i n_{i} ni是 n k n_{k} nk的祖先时, N i N_{i} Ni取值1,但是我们要计算 n i n_{i} ni是 n j n_{j} nj祖先的概率,也就是计算 n i n_{i} ni在集合N(i,k)中优先级取值最小的概率,记住前面我们提到,每个节点的优先级是随机在(0, 1]中分配的,所以N(i,k)中包含的节点数量为|k-i|+1,因此 n i n_{i} n