无效告警优化实践总结
Posted 阿里巴巴淘系技术团队官网博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了无效告警优化实践总结相关的知识,希望对你有一定的参考价值。
对于7*24小时不间断运行的后台服务,监控告警是稳定性运行的基石。很多开发者都有过这样的经历,对服务的每一个指标都做了严格的监控和告警,唯恐漏掉告警导致问题无法发现,导致每天接收到大量的无效告警,告警的泛滥逐渐麻痹了警惕性,结果真实的问题初漏端倪时却被忽略,最终导致了严重的故障。
如何提升告警的有效性,准确识别问题,同时又不至于淹没在大量的无效告警中,正是本文所探讨的内容。
告警是可靠性的基础
首先来看一下告警的重要性,为什么我们需要耗费这么多精力来优化告警。虽然我们都期望一个服务是没有故障的,但事实确是不存在 100% 没问题的系统,我们只能不断提升服务的可靠性,我们期望做到:
-
对服务当前状态了如指掌,尽在掌控
-
能够第一时间发现问题,并且快速定位问题原因
要想做到以上两点,只能依赖完善的监控&告警,监控展示服务的完整运行状态,但是不可能一直盯屏观察,并且也不可能关注到所有方面,要想被动的了解系统状态,唯有通过告警,自动检测异常情况。
所以,告警是团队监控服务质量和可用性的一个最主要手段。系统故障相关的时间问题通常用MTBF、MTTF、MTTR这三项指标来表示。
-
MTTF (Mean Time To Failure,平均无故障时间):指系统无故障运行的平均时间,取所有从系统开始正常运行到发生故障之间的时间段的平均值。MTTF = ∑T1 / N
-
MTTR (Mean Time To Repair,平均修复时间):指系统从发生故障到维修结束之间的时间段的平均值。MTTR = ∑(T2+T3) / N
-
MTBF (Mean Time Between Failure,平均失效间隔):指系统两次故障发生时间之间的时间段的平均值。MTBF = ∑(T2+T3+T1) / N

可靠性在于追求更高的MTTF和低的MTTR(平均无故障时间)。最好的情况是能够不产生故障,但不存在100%可靠的系统,当出现故障/异常时,我们需要尽可能减少MTTR(平均修复时间),告警的意义在于尽可能减少T2 + T3时间。
告警面临的现实问题
理想中的告警,不存在误报(即本来正常的,告警为异常)也不存在漏报(即本来异常的,误认为正常),所以理想的模型满足以下三点:
-
误报为0:出现的告警都是需要处理的问题
-
漏报为0:异常问题都能够告警发现
-
及时发现:能够第一时间发现问题,甚至于在导致故障前发现问题
但在实践中无法做到理想情况。要减少漏报,需要针对每一种可能发生的场景进行监控,同时配置告警,这其实并不算困难;但我们的告警往往不是太少了,而是太多了,以至于需要耗费大量时间处理无效告警,由于告警过多,容易忽略真正有用的告警,导致异常发现的时间变长,或者忽略的潜在的风险。所以对于告警,最大的问题在于如何减少无效告警,提升告警的效率。
先来看一下无效告警产生的原因。
监控系统应该解决两个问题:什么东西出故障了,以及为什么会出故障。其中“什么东西出故障了”即为现象,“为什么”则代表了原因(可能是中间原因)。现象和原因的区分是构建信噪比高的监控系统时最重要的概念。
在实践中,想绝对做到这两点几乎不可能,但我们可以无限趋向于理想模型。
告警一般是通过“现象”来判断,而是否有问题要看产生现象的原因判断。相同的现象引起的原因可能不同,这种“可能性”是导致误告警的最核心原因。
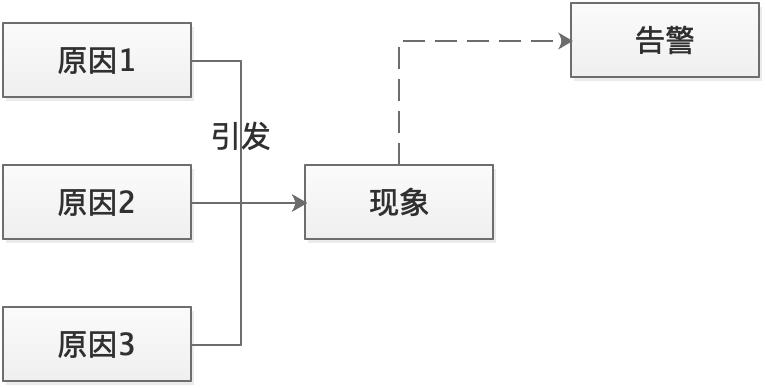
举个例子,请求失败告警,原因可能是请求内容有问题,也可能上游机器异常,或者是我们自身的服务处理异常。理想的情况肯定是期望告警有着唯一的原因,但实际上由于现实的复杂性,未必能够做到精准的区分。

减少误告警的思路,就是要尽可能减少现象产生的原因,如果能减少到唯一的一个原因,那就能很明确问题所在。
告警分类
同样是告警,对于CPU跑满这种情况需要立即处理,但对于单机健康状态告警(正常异常机器会自动置换,异常情况可能置换失败),系统并不能自动解决这种状况,但是一段时间内不处理,也不会造成影响,负载均衡设备会自动摘除。
所以这里涉及到一个告警分类的问题,当然,告警可以有很多种分类方法,分成很多种级别区别对待,但在优化无效告警的目标下,我们通过是否需要立即停下手头工作立即处理,分为三类:
-
紧急:收到报警就需要立即执行某种操作。如CPU跑满,内存跑满等。判断标准,是否对业务有影响,以及是否有潜在的未知风险
-
不紧急:系统并不能自动解决目前状况,但是一段时间内不处理,也不会造成影响。如单机出现访问不通异常。判断标准,对业务无影响,基本无潜在的风险,但最终需要人工介入处理
-
不需要处理:已知异常并且系统会自动恢复,不需要人工接入。如机器虽然出现异常,但运维底座会再一段时间内自动处理,不需要人工介入
对于一个异常,首先需要判断是否需要立即处理,区分进行优化。
对于不需要处理的异常,则完全没有必要进行告警。如果需要感知事件,可以通过邮件方式进行时候定时通知,无需通过告警渠道打断工作。
对于不紧急的告警,如果工具支持的话,应该以工单的形式定时推送,统一处理,没必要进行实时告警,减少对正常工作的打断。在工具不支持的场景,可以适当调整告警间隔时间,以及重复告警的收敛策略。如单机异常可以整点告警,避免重复打断工作,当然,如果同时超过一定百分比的机器异常,这便转换为紧急告警了,需要实时触达。
对于紧急告警,应该尽量提升其实时性和准确性,尽可能去除无效告警。那应该如何进行无效告警的识别和判断呢,接下来可以看一下告警设置的原则。
告警设置原则
每当告警发生时,值班同学需要暂停手头工作,查看告警。这种中断非常影响工作效率,增加研发成本,特别对正在开发调试的同学,影响很严重。所以,每当我们收到告警时,我们希望它能真实的反映出异常,即告警尽可能不误报(对正常状态报警);每当有异常产生时,报警应该及时发出来,即告警不能漏报(错过报警)。误报和漏报总是一对矛盾的指标。
以下是一些告警设置原则:
-
告警具备真实性:告警必须反馈某个真实存在的现象,展示你的服务正在出现的问题或即将出现的问题
-
告警表述详细:从内容上,告警要近可能详细的描述现象,比如服务器在某个时间点具体发生了什么异常
-
告警具备可操作性:每当收到告警时,一般需要做出某些操作,对于某些无须做出操作的告警,最好取消。当且仅当需要做某种操作时,才需要通知
-
新告警使用保守阈值:在配置告警之初,应尽可能扩大监控告警覆盖面,选取保守的阈值,尽可能避免漏报。
-
告警持续优化:后续持续对告警进行统计分析,对误报的告警,通过屏蔽、简化、阈值调整、更精准的体现原因等多种方式减少误报,这是一个相对长期的过程。
再以请求失败举例,如仅当请求的失败量超过某一阈值时告警,可能存在多种原因,如一些恶意构造的请求,也触发失败量告警。这样的告警既不具备真实性,也不具备可操作性,因为确实无需任何处理。对于此类情况,我们应该尽可能通过特性加以识别,从而更加精准的区分原因的告警。
善用工具
另外优化告警的一个必备条件,就是要熟悉所用告警平台使用,如果都不知道告警平台可以做到什么程度,可以设置怎样灵活的条件阈值,是很难对告警做合理优化的。
-
监控告警平台能做到什么:业务基础指标,系统基础指标,各种维度的统计方式
-
告警阈值设置:如何电话/短信告警设置
-
告警统计和趋势:有利于进行数据分析和优化告警
以请求失败举例,告警平台是否可以区分不同原因类型告警,是否可以统计成功率告警,是否可以配置持续多久告警,是否可以配置环比同比条件告警;以及不同类型的阈值区分配置,不同条件下的短信,还是电话告警,短信一段时间未处理是否可以转换为电话通知,是否可以屏蔽重复告警等等。所有的特性都有利于我们设置一个精准的告警条件。
另外平台提供的统计和趋势,有利于我们进行针对性优化,查看每天每周的TopN告警是什么,整体的趋势是什么样的,从而进行针对性优化。
告警处理流程
前面提到了告警的优化是一个持续的过程,不存在一劳永逸的事情。需要每天或者每周安排值班人员负责告警事宜,这点上确实是需要一定的投入。值班同学需要持续关注告警的有效性,对于出现的无效告警,分析清楚原因,持续优化阈值或者告警策略。
合理的告警流转流程:

处理流程中,在告警触发后,通过短信/电话等方式触达,值班处理人接单处理,再接单后处理完成前,重复的问题不再触发告警,以避免大量的重复无效告警。确认原因后结单返回原因。
可能受限于告警工具问题,不能严格的按照流程来推进(比如一次异常事件,由于告警平台不支持,处理过程中可能触发很多重复告警;系统没有反馈原因的流程等),但是值班同学心里需要有这样的流程,确保每条告警都是清清楚楚在哪个阶段,没有含糊其辞之处。
另外值班同学要强调几点注意事项
-
确保能够收到所有告警:可以通过接收人组解决,确保所有值班同学都在一个接收人组,如果有人员变动也方便修改
-
上升线路:需要判断问题的严重性,适合时机上升,增加资源快速把问题消灭再萌芽状态
-
明确根本原因:确保弄清楚问题原因,而不是表面上恢复。比如单台机器CPU跑满告警,可能存在未知的死循环问题,如果仅仅重启进程恢复,很可能掩盖了问题,导致未来出现大面积的死循环引发故障
最后告警的处理,在心态上要做到:凡事最好能在不疑处有疑,不能在有疑处不疑。
参考&引用
-
《SRC:Google运维解密》
-
《MTTR/MTTF/MTBF图解》:https://blog.csdn.net/starshinning975/article/details/102893787
-
《一篇文章了解监控告警》:https://zhuanlan.zhihu.com/p/60416209
-
《准确率、精度和召回率》:https://www.cnblogs.com/xuexuefirst/p/8858274.html
-
《告警配置的一些原则和经验》http://wsfdl.com/devops/2018/02/07/configure_alarm.html
以上是关于无效告警优化实践总结的主要内容,如果未能解决你的问题,请参考以下文章