Hive数据库对象与用户自定义函数
Posted shi_zi_183
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hive数据库对象与用户自定义函数相关的知识,希望对你有一定的参考价值。
Hive数据库对象与用户自定义函数
Hive视图
Hive中的视图和关系型数据库中视图在概念上是一致的,都是一组数据的逻辑表示,享用基本原始表的数据而不会另生成一份数据,是纯粹的逻辑对象。本质上,视图是一条SQL语句的集合,但该条SQL不会立即执行,我们称其为逻辑视图,它没有关联的实际存储。当有查询需要引用视图时,Hive才真正开始将查询中的过滤器推送到视图中去执行。
创建视图
在Hive中使用create view命令创建视图,需要注意的是,创建的视图名字不能与Hive中已存在的表明和视图名相同,否则会抛出异常,所有我们创建的时候可以加上if not exists命令。
在Hive中创建视图的语法
create view [if not exists] db_name.view_name as select [column_name...] from table_name where...
视图是只读型的,不能对视图执行插入数据、删除数据、修改数据结构等操作。视图一旦创建就是固定的,对基础表的更新操作将不会反映在视图上,删除基础表也不会自动删除视图,若要删除视图,需要手动执行删除命令。
创建一个视图,其内容包含表sogou_20111230中关键词不为空的前1000条数据信息。
create view sogou_view as select * from sogou_20111230 where keyword is not null limit 1000;
查询视图中前10条数据
select * from sogou_view limit 10;

查看视图
1)查看所有视图和表的命令
show tables;

2)查看某个视图的命令
desc sogou_view;

3)查看某个视图详细信息的命令
desc formatted sogou_view;

视图应用实战
在搜索引擎日志数据中,统计出rank<3(即用户点击排名小于3)但搜索次数大于2的用户。要解决这个问题,首先要统计出rank<3的所有用户记录,然后这些记录数据中筛选出有多少用户的搜索次数大于2。为此,我们可以采用视图来完成这个需求。
创建统计rank<3的用户记录的视图
create view sogou_rank_view as select * from sogou_20111230 where rank < 3;
desc sogou_rank_view;

统计搜索次数大于2的用户记录
select uid,count(*) as cnt from sogou_rank_view group by uid having cnt > 2;

删除视图
删除视图的语法
drop view [if exists] [db_name.]view_name;
删除视图sogou_view
drop view if exists sogou.sogou_view;
Hive分桶表
首先,我们要明白什么是Hive分桶表。分桶表是相对于分区表来说的,分区表在前面的章节中已经介绍过,它属于一种粗细度的划分,而分桶表是对数据进行更细粒度的划分。分桶表将整个数据内容按照某列属性值的哈希值进行区分,例如按照用户ID属性分为3个桶,就是对用户ID属性值的哈希值对3取模运算,按照取模结果对数据分桶。所以,分桶的规则就是对分桶字段值进行取哈希值,然后用该哈希值除以通的个数取余数,余数决定了该条记录将会被分在那个通中。余数相同的记录会分在同一个桶中。需要注意的是,在物理结构上一个桶对应一个文件,而分区表的分区只是一个目录,至于目录下有多少个数据不确定。
创建表
通过clustered by(字段名) into bucket_num buckets分桶,意思根据字段名分成多个桶。
create table sogou_bucket(uid string,keyword string) comment 'test' clustered by(uid) into 5 buckets row format delimited fields terminated by '\\t';
以上我们完成了桶表sogou_bucket的创建,注意,我们指定了5个桶。
插入数据
必须使用启动MapReduce作业的方式才能把文件顺利分桶,若使用load data local inpath这种方式加载数据,即使设置了强制分桶,也不起作用。注意,插入数据之前,需要设置属性hive.enforce.bucketing=true,其含义是数据分桶是否被强制执行,默认为false,如果开启,则写入table数据时会启动分桶。所以必须要将该属性的值设置为true。
set hive.enforce.bucketing=true;
insert overwrite table sogou_bucket select uid, keyword from sogou_20111230 limit 10000;
select * from sogou_bucket limit 10;

我们知道分桶表是相对于分区表来说的,分桶表在物理结构上一个桶对应一个文件,而分区表一个分区对应一个目录。下面我们来查看一下分桶表sogou_bucket在HDFS文件系统上产生了几个文件。
hadoop fs -ls /user/hive/warehouse/sogou.db/sogou_bucket;

Hive用户自定义函数
用户自定义函数简介
Hive提供了大量的内置函数,HiveQL使用内置函数可以满足日常开发中所涉及的常见开发需求。但对于任何一个系统而言,都不可能将实际用户的所有需求都事先考虑周全。Hive也是一样,对于一些特殊的用户需求,Hive以提供的内置函数是满足不了的,因此一个系统的开放性就显得尤为重要了。也就是说,虽然系统不能实现考虑到所有可能的用户需求,但却可以提供一个开放的接口,允许开发人员根据个性化的需求来自定义特殊功能函数的实现。
用户自定义函数(User Defined Function,UDF)是一个允许用户扩展HiveQL的强大的功能。一旦将UDF加入到用户会话中(交互式的或者通过脚本执行的),它们将和内置函数一样,甚至可以提供联机帮助。Hive具有多种类型的UDF,每一种都会针对输入数据执行特定的转换过程。
需要注意的是,在Hive中通常使用"UDF"来表示任意的函数,包括用户自定义函数或者内置的。另外,Hive内置函数,本质上也是UDF,因为Hive本身也是一个用户。
show functions;
命令可以列举出当前Hive会话中所加载的所有函数名称,其中包括内置函数和用户加载进来的函数。
describe function function_name;
命令可以展示对应函数的简介。
UDF应用开发
UDF可以直接应用于select语句,对查询结果进行格式化处理后,再输出内容。也就是说,使用UDF和使用Hive内置函数的方式是一样的。在编写UDF的时候需要注意:首先,UDF需要继承org.apache.hadoop.hive.ql.UDF;其次,需要实现evaluat函数,该函数支持重载。
创建maven工程
file->project structure->modules->点击+号->new module->选择maven

添加依赖
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.example</groupId>
<artifactId>udfTest</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.2</version>
</dependency>
</dependencies>
</project>
该版本要与你集群的hive版本相同
编写UDF函数
新建一个UDFDemo.java
package com.example;
import org.apache.hadoop.hive.ql.exec.UDF;
public class UDFDemo extends UDF {
public String evaluate(String str){
try{
return "HelloWord"+str;
}catch (Exception e){
return null;
}
}
public int evaluate(int a,int b){
return a/b;
}
public double evaluate(double a){
return 2*a;
}
}
将UDFDemo.java应用程序打包
idea打包
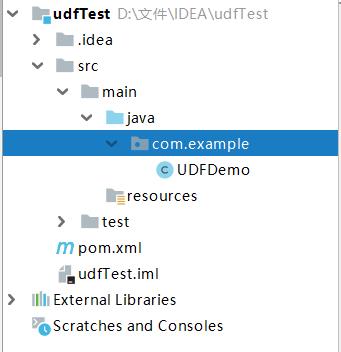
file->project structure

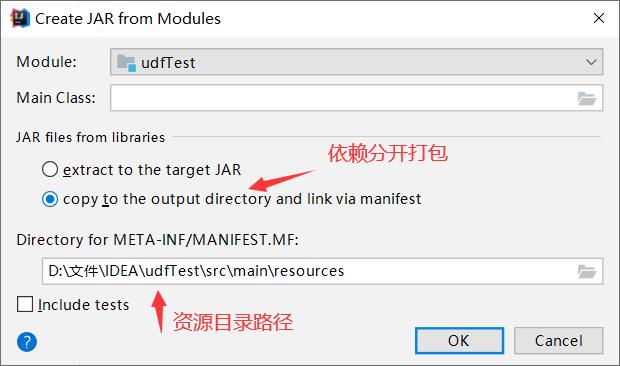



maven打包

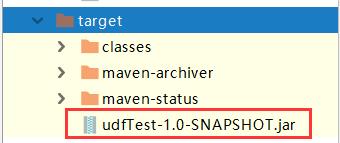
推荐使用第二种。
进入hive客户端,添加jar包

创建临时函数(相当于为Java的类名UDFDemo起一个别名)
语法格式为create temporary function helloword as '包名.类名'
create temporary function helloworld as 'com.example.UDFDemo'

查询HQL语句

删除临时函数

Hive用户自定义聚合函数
用户自定义聚合函数简介
UDAF(User Defined Aggregate Function)即用户自定义聚合函数。普通函数一般是接收一行输入,产生一个输出,而聚合函数是接收一组输入(即多行输入),然后产生一个输出。例如count函数就是一个聚合函数,因为它接收多行输入,然后产生一个输出总行数;再看substr函数,它接收一行输入,然后对这一行中的字符串进行处理再输出一个新字符串。所以,count函数属于聚合函数,而substr哈桑农户属于普通函数。
UDAF应用开发
1)UDAF的用法
使用UDAF必须要继承org.apache.hadoop.hive.ql.exec.UDAF类和org.apache.hadoop.hive.ql.exec.UDAFEvaluator接口,其中函数类需要继承UDAF类,内部类需要实现UDAFEvaluetor接口。
内部类实现UDAFEvaluetor接口,需要实现init、iterate、terminatePartial、merge、terminate等函数。
init函数实现UDAFEvaluetor接口的init函数,主要用于初始化。
terminatePartial函数没有形参,其为iterate函数轮转结束后,返回轮转数据。
merge接受terminatePartial函数的返回结果,并进行merge更新操作,其返回值类型为boolean。
terminate函数返回最终的聚集函数结果。
2)UDAF实现avg求平均值函数
package com.example;
import org.apache.hadoop.hive.ql.exec.UDAF;
import org.apache.hadoop.hive.ql.exec.UDAFEvaluator;
public class Avg extends UDAF {
/**定义求平均值对象,需要知道总和数mSum和总个数mCount**/
public static class AvgState{
private long mCount;
private double mSum;
}
public static class AvgEvaluator implements UDAFEvaluator{
private AvgState state;
public AvgEvaluator() {
super();
state=new AvgState();
init();
}
/**init函数类似于构造函数,用于UDAF的初始化**/
@Override
public void init() {
state.mCount=0;
state.mSum=0;
}
/**iterate接受传入的参数,并进行内部的轮转。其返回类型为boolean**/
public boolean iterate(Double o){
if(o!=null){
state.mSum+=o;
state.mCount++;
}
return true;
}
/**
* terminatePartial无参数,其为iterate函数轮转结束后,返回轮转数据
* terminatePartial类似于Hadoop的Combiner
* **/
public AvgState terminatePartial(){
return state.mCount==0?null:state;
}
/*
* merge接受terminatePartial的返回结果,进行数据merge操作,其返回类型为boolean
* */
public boolean merge(AvgState o){
if(o!=null){
state.mSum+=o.mSum;
state.mCount+=o.mCount;
}
return true;
}
public Double terminate(){
return state.mCount==0?null:Double.valueOf(state.mSum/state.mCount);
}
}
}

select my_avg(sal) from sogou.sogou_20111230 limit 10;

以上是关于Hive数据库对象与用户自定义函数的主要内容,如果未能解决你的问题,请参考以下文章