学习笔记Flink—— Flink基础API及核心数据结构
Posted 别呀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了学习笔记Flink—— Flink基础API及核心数据结构相关的知识,希望对你有一定的参考价值。
一、Flink基础API-Flink编程的基本概念
1.1、Flink程序
-
Flink 程序是实现了分布式集合转换(例如过滤、映射、更新状态、join、分组、定义窗口、聚合)的规范化程序。
-
集合初始创建自 source(例如读取文件、kafka 主题,或本地内存中的集合)。
-
结果通过 sink 返回,例如,它可以将数据写入(分布式)文件,或标准输出(例如命令行终端)。
-
Flink 程序可以在多种环境中运行,独立运行或嵌入到其他程序中。可以在本地 JVM 中执行,也可以在多台机器的集群上执行
-
针对有界和无界两种数据 source 类型,可以使用 DataSet API 来编写批处理程序或使用 DataStream API 来编写流处理程序。
-
对于流处理,使用 StreamingExecutionEnvironment 和 DataStream API。
-
对于批处理,将他们替换为 ExecutionEnvironment 和 DataSet API 即可,概念是完全相同的。
1.2、DataSet和DataStream
-
Flink 用特有的 DataSet 和 DataStream 类来表示程序中的数据。
-
可以将他们视为可能包含重复项的不可变数据集合。对于 DataSet,数据是有限的,而对于 DataStream,元素的数量可以是无限的。
-
这些集合与标准的 Java 集合有一些关键的区别。首先它们是不可变的,也就是说它们一旦被创你就不能添加或删除元素了,同时也不能简单地检查它们内部的元素。
-
在 Flink 程序中,集合最初通过添加数据 source 来创建,通过使用诸如 map、filter 等 API 方法对数据 source 进行转换从而派生新的集合。
1.3、Flink程序构成
- 获取执行环境
- 加载/创建初始数据;
- 编写对数据的转换操作;
- 指定计算结果存放的位置;
- 触发程序执行;
1.3.1、获取执行环境
- Scala DataSet API : org.apache.flink.api.scala ;
- Scala DataStream API : org.apache.flink.streaming.api.scala ;
- StreamExecutionEnvironment 是所有 Flink 程序的基础,可以使用它的这些静态方法获取:

- 一般只需要使用getExecutionEnvironment(),它会根据上下文环境完成正确的工作。
- 例如,在IDE中执行程序或者作为标准的 Java 程序来执行,它会创建本机执行环境。
- 如果将程序封装成 JAR 包,然后通过命令行调用,Flink 集群管理器会执行你的 main 方法并且 getExecutionEnvironment() 会返回在集群上执行程序的执行环境。
1.3.2、加载数据集
- 针对不同的数据 source,执行环境有若干不同的读取文件的方法:你可以逐行读取 CSV 文件,或者使用完全自定义的输入格式。要将文本文件作为一系列行读取,你可以使用:

1.3.3、编写转换操作
-
通过2.的操作会得到一个DataStream数据流,然后对其应用转换操作就可以创建新的派生 DataStream。
-
通过调用 DataStream 的转换函数来进行转换。如下是一个映射转换的实例:

-
通过把原始数据集合的每个字符串转换为一个整数,从而创建出一个新的 DataStream。
1.3.4、指定计算结果存放位置& 触发程序执行
- 一旦得到了包含最终结果的 DataStream,就可以通过创建 sink 将其写入外部系统。
- 例如,下面是一些创建 sink 的示例:

- 当设定好整个程序以后只需要调用 StreamExecutionEnvironment 的 execute() 方法触发程序执行。execute() 方法返回 JobExecutionResult,它包括执行耗时和一个累加器的结果。
- 如果不需要等待作业的结束,只是想要触发程序执行,你可以调用 StreamExecutionEnvironment 的 executeAsync() 方法。这个方法将返回一个 JobClient 对象,通过 JobClient 能够与程序对应的作业进行交互。
1.4、延迟计算
-
无论在本地还是集群执行,所有的 Flink 程序都是延迟执行的:
-
当程序的 main 方法被执行时,并不立即执行数据的加载和转换,而是创建每个操作并将其加入到程序的执行计划中。
-
当执行环境调用 execute() 方法显式地触发执行的时候才真正执行各个操作。
-
延迟计算允许你构建复杂的程序,Flink 将其作为整体计划单元来执行。
1.5、指定键、值
- 一些转换操作(join, coGroup, keyBy, groupBy)要求在元素集合上定义键。
- 另外一些转换操作 (Reduce, GroupReduce, Aggregate, Windows)允许在应用这些转换之前将数据按键分组。

- Flink 的数据模型不是基于键值对的。因此不需要将数据集类型物理地打包到键和值中。
- 键都是“虚拟的”:它们的功能是指导分组算子用哪些数据来分组。
1.6、为Tuple定义键
- 最简单的方式是按照 Tuple 的一个或多个字段进行分组:

- 按照第一个、第二个字段组合来进行分组

- 使用字段表达式来定义键

1.7、指定转换函数
- 匿名函数

- 富函数

二、Flink基础API-支持的数据类型
- Java Tuple 和 Scala Case Class

Flink 将满足如下条件的 Java 和 Scala 的类作为特殊的 POJO 数据类型处理
-
类必须是公有的。
-
它必须有一个公有的无参构造器(默认构造器)。
-
所有的字段要么是公有的要么必须可以通过 getter 和 setter 函数访问。例如一个名为 foo 的字段,它的 getter 和 setter 方法必须命名为 getFoo() 和 setFoo()。
-
字段的类型必须被已注册的序列化程序所支持。

-
基本数据类型
Flink 支持所有 Java 和 Scala 的基本数据类型如 Integer、 String、和 Double。 -
常规的类
Flink 支持大部分 Java 和 Scala 的类(API 和自定义)。 除了包含无法序列化的字段的类,如文件指针,I / O流或其他本地资源。 -
值类型
值类型手工描述其序列化和反序列化。它们不是通过通用序列化框架,而是通过实现 org.apache.flinktypes.Value 接口的 read 和 write 方法来为这些操作提供自定义编码。当通用序列化效率非常低时,使用值类型是合理的。 -
Hadoop Writable
可以使用实现了 org.apache.hadoop.Writable 接口的类型。它们会使用 write() 和 readFields() 方法中定义的序列化逻辑。 -
特殊类型
可以使用特殊类型,包括 Scala 的 Either、Option 和 Try。 Java API 有对 Either 的自定义实现。 类似于 Scala 的 Either,它表示一个具有 Left 或 Right 两种可能类型的值。 Either 可用于错误处理或需要输出两种不同类型记录的算子。
三、DataStream API
3.1、数据源
一般情况下通过StreamExecutionEnvironment.addSource(sourceFunction) 就可以添加数据源。
文件类型数据源:
-
readTextFile(path): 使用TextInputFormat 按行读取文本,每行返回一个字符串。 -
readFile(fileInputFormat, path): 通过自定义fileInputFormat 来读取数据; -
readFile(fileInputFormat , path , watchType , interval , pathFilter): watchType : 新文件数据;
Socket 类型数据源:
socketTextStream: 通过socket读取数据,可以通过设置分隔符来区分每个数据。
Collection 类型数据源:
- fromCollection(Seq)
- fromCollection(Iterator)
- fromElements(elements:_*)
- fromParallelCollection(SplittableIterator)
- generateSequence(from, to)
3.2、转换操作
- 值 -> 值
- (键,值) -> (键,值)
3.3、输出源
writeAsText() / TextOutputFormat: 按行写入数据writeAsCsv(): 把元组数据通过都好进行分割写入文件print() / printToErr():把数据通过标准输出或异常输出进行打印writeUsingOutputFormat() / FileOutputFormat: 自定义 输出文件类型;writeToSocket: 通过socket 进行数据输出;addSink: 调用自定义输出源
四、DataSet API
4.1、数据源


4.2、输出源
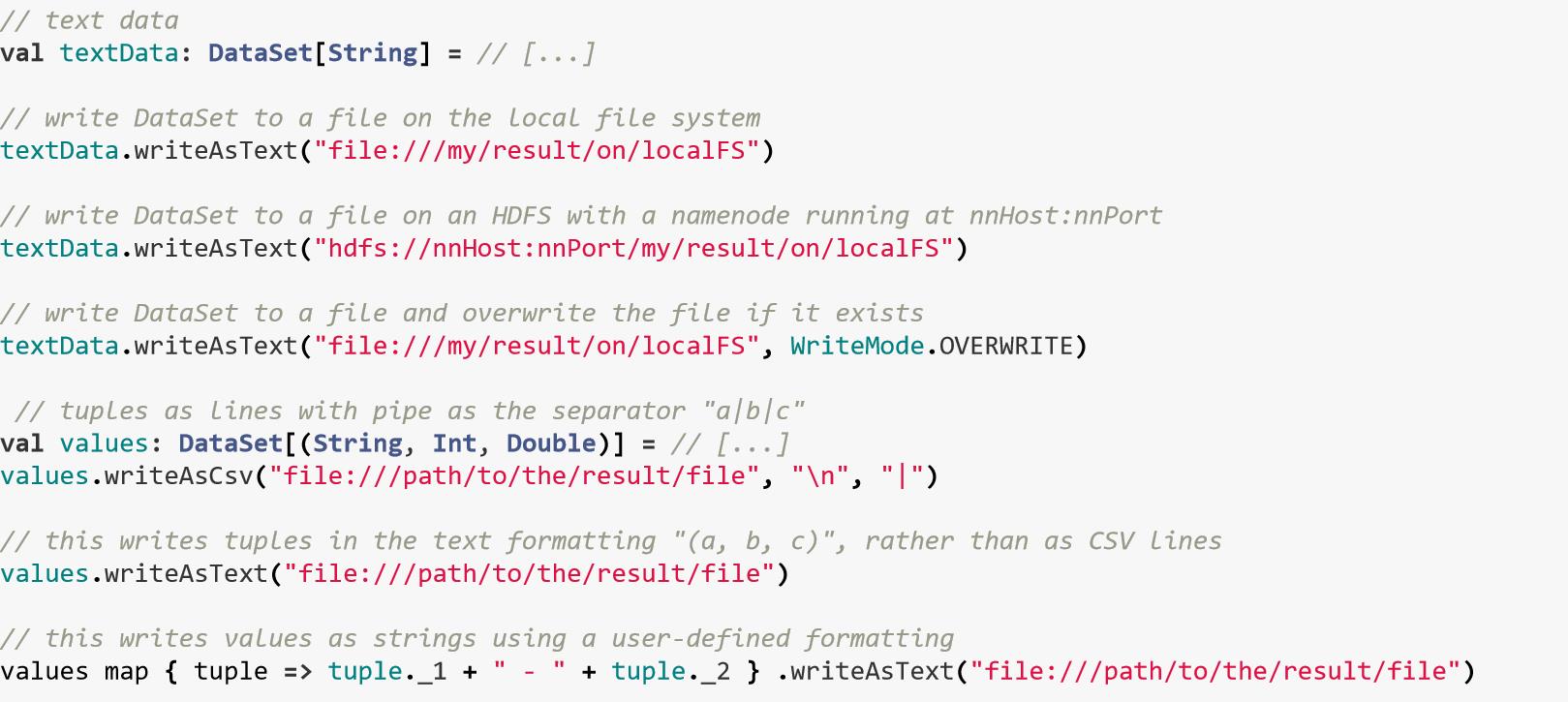
五、Table API
Table API 分为Java, Scala, Python三种,Scala API需要导入
org.apache.flink.api.scala._ 和org.apache.flink.table.api.scala._,并且Scala中字段需要使用特殊字符(’)来进行表示。
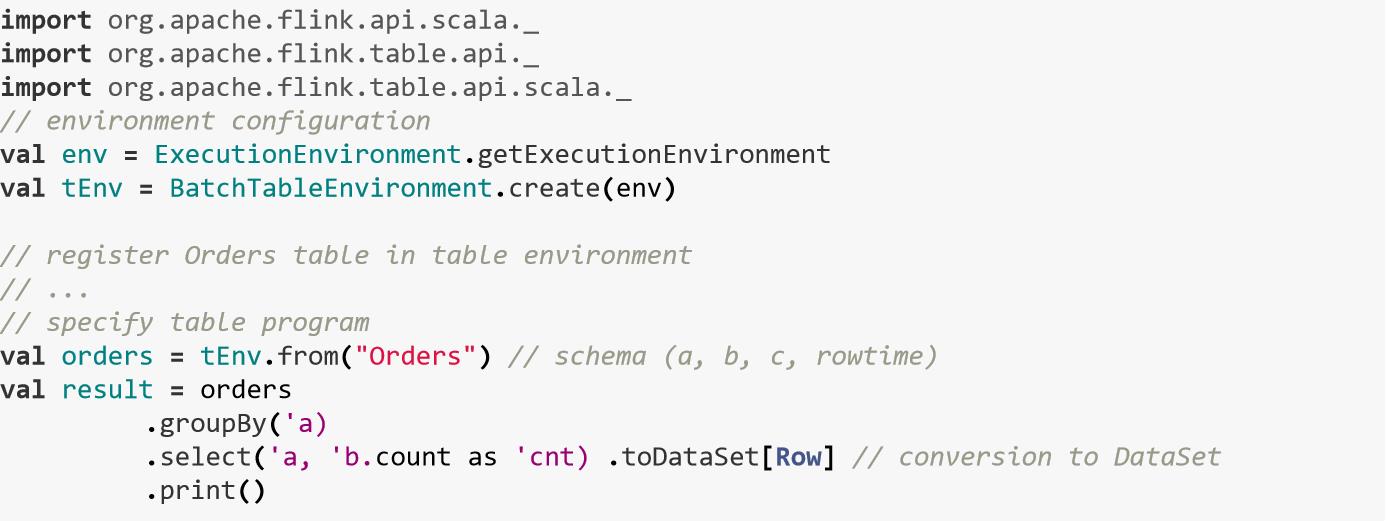
下面的例子会对Order表进行扫描,过滤null值,把a列变小写,然后针对每个小时对a进行分组,求b的平均值。

六、SQL API
启动SQL client:
./bin/sql-client.sh embedded
测试1:

可以看到

设置table模式:
SET execution.result-mode=table;
示例:

看到

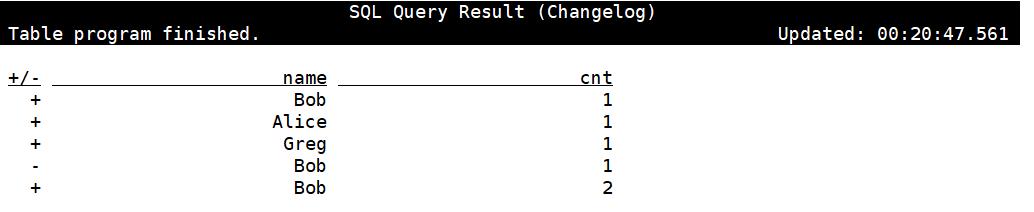
设置changelog模式
SET execution.result-mode=changelog;
示例:

看到
以上是关于学习笔记Flink—— Flink基础API及核心数据结构的主要内容,如果未能解决你的问题,请参考以下文章