Kubernetes 应用问题的通用排查思路 - 大数据从业者之 Kubernetes 必知必会
Posted 明哥的IT随笔
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kubernetes 应用问题的通用排查思路 - 大数据从业者之 Kubernetes 必知必会相关的知识,希望对你有一定的参考价值。
大家好,我是明哥!
本片文章介绍下 Kubernetes 应用问题的通用排查思路,分享一个线上此类问题的排查案例,总结下背后的相关知识,以飨读者,大家共勉!
1 技术趋势大背景
我们知道,大数据进一步发展的一个趋势,就是大数据和云计算进一步融合(包括在底层更加青睐存储计算分离的架构,在底层更加青睐对象存储),在部署架构上支持混合云和多云场景,拥抱云计算走向云原生化。
对应到底层具体技术堆栈上,体现在各个主流大数据平台和底层的大数据组件,纷纷开始支持以 Kubernetes 和 Docker 为代表的容器系列技术栈。
所以大数据从业者,需要不断扩展自己的技能包,掌握 Kubernetes 和 Docker 的基础知识和常见命令,才能在排查大数据相关问题时不至于捉襟见肘,因技能储备短缺,无从下手。
在此分享一个大数据平台中 docker 容器相关故障的排查案列,并介绍下此类问题的背后知识和排查思路,以飨读者,大家共勉!
2 问题现象
星环大数据平台 TDH 中, zookeeper 服务无法正常启动。我们知道 TDH 中,各个服务其实是在 k8s 的管控下运行于 docker 容器中,通过 kubectl get pods -owide |grep -i zoo 可以发现,对应的 pod 的状态是CrashLoopBackOff,如下图所示:

3 背后知识:什么是 CrashLoopBackOff?
某个 pod 处于 CrashloopBackOff, 意味着该 pod 中的容器被启动了,然后崩溃了,接下来又被自动启动了,但又崩溃了,如此周而复始,陷入了(starting, crashing, starting,crashing)的循坏.
注意:pod 中的容器之所以会被自动重启,其实是通过 PodSpec 中的 restartPolicy 指定的,该配置项默认是 Always,即失败后会自动重启:
-
A PodSpec has a restartPolicy field with possible values Always, OnFailure, and Never which applies to all containers in a pod, the default value is Always;
-
The restartPolicy only refers to restarts of the containers by the kubelet on the same node (so the restart count will reset if the pod is rescheduled in a different node).
-
Failed containers that are restarted by the kubelet are restarted with an exponential back-off delay (10s, 20s, 40s …) capped at five minutes, and is reset after ten minutes of successful execution.
4 背后知识:为什么会发生 CrashLoopBackOff 错误?
pod 的 CrashLoopBackOff 错误还是挺常见的,该错误可能会因为多种原因被触发,几个主要的上层原因有:
-
Kubernetes 集群部署有问题;
-
该 pod 或 pod 底层的 container 的某些参数被配置错了;
-
该 pod 内部的 container 中运行的应用程序,在多次重启运行时都一直处于失败状态;
5 背后知识:如何排查 pod 容器底层的应用程序的故障?
当 pod 容器底层的应用程序运行出现故障时,通用的排查思路,一般是:
-
步骤一:通过命令 kubectl describe pod xxx 获取 pod 详细信息
-
步骤二:通过命令 kubectl logs xxx 查看 pod 容器底层的应用程序的日志
-
步骤三:进一步获取并查看 pod 容器底层的应用程序的其它日志文件,深挖问题原因
有的小伙伴可能会有疑问,上述步骤二和步骤三都是查看 pod 容器底层的应用程序的日志,有什么区别呢?
其实步骤二和步骤三在底层查看的是应用程序的不同的日志文件,其底层细节跟 kubernetes 的日志机制,以及该 pod 底层的应用程序将日志写向何处有关:
-
kubectl logs 展示的是 pod 底层的 container 的标准输出 stdout 和标准错误 stderr 的日志;
-
应用程序写到其它文件的日志,kubectl logs 展示不了,需要获取日志文件路径,并自行查看;
-
k8s 建议应用程序将日志写到 container 的标准输出 stdout 和标准错误 stderr;
-
容器内的应用程序可以将日志直接写到 container 的标准输出 stdout 和标准错误 stderr;
-
如果容器内的应用程序不能或不方便将日志直接写到 container 的标准输出 stdout 和标准错误 stderr,可以使用 sidecar 即边车模式,在应用程序的 container 所在的 pod 内部署另一个 sidecar container,该 sidecar container 负责读取应用程序的日志文件并输出到其标准输出 stdout 和标准错误 stderr 里;
-
k8s 在底层会通过运行在各个节点的 kubelet 来收集节点中所有 container 的 stdout 和 stderr 日志,并写到一个 kubelet 管理的本地文件中;
-
用户执行 kubectl logs xx 命令时,该命令在底层会调用该 container 对应节点上的 kubelet 来检索其管理的本地日志文件,以获取日志;
-
用户使用 kubectl log xxx 来检索应用程序日志,省去了用户登录 k8s 集群中对应节点查看对应日志的繁琐操作,提供了很大遍历;
ps. 我们这里讨论的是运行在 k8s 容器中的应用程序的日志,除了应用程序的日志,其实整个k8s 集群中还有很多系统组件的日志,如:docker,kubelet,kube-proxy,kube-apiserver,kube-scheduler,etcd等。
6 问题排查复盘
按照上述通用问题排查思路,我们复盘回顾下该 CrashLoopBackOff 问题的排查经过。
6.1:问题排查复盘:通过命令 kubeclt describe pod xxx 获取 pod 详细信息
该命令输出的部分截图如下,通过输出中 Events 部分,我们可以获取如下信息:该 pod 被成功地分配到了某个节点上,然后镜像拉取成功,然后 contaier 创建和启动成功,但随后 contaier 中程序运行失败,最后 pod 进入到了 BackOff 状态:
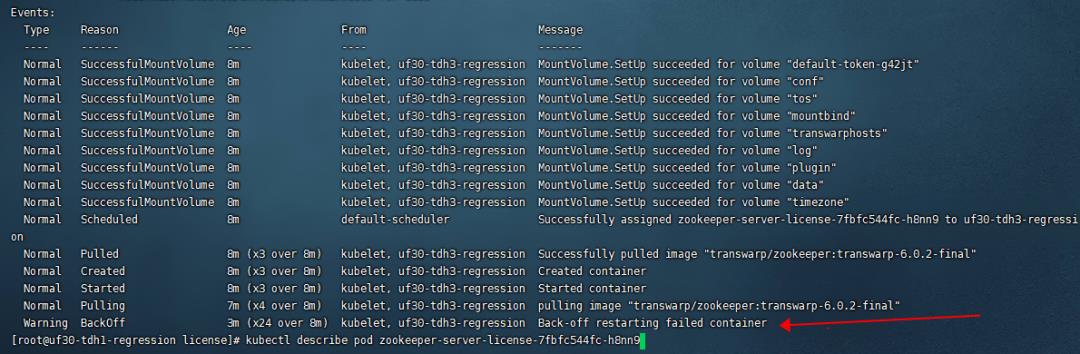
该命令的详细输出如下:
kubectl describe pod zookeeper-server-license-7fbfc544fc-h8nn9
Name: zookeeper-server-license-7fbfc544fc-h8nn9
Namespace: default
Priority: 0
PriorityClassName: <none>
Node: uf30-tdh3-regression/10.20.159.115
Start Time: Mon, 11 Oct 2021 16:56:30 +0800
Labels: name=zookeeper-server-license
pod-template-hash=3969710097
podConflictName=zookeeper-server-license
Annotations: <none>
Status: Running
IP: 10.20.159.115
Controlled By: ReplicaSet/zookeeper-server-license-7fbfc544fc
Containers:
zookeeper-server-license:
Container ID: docker://0887c97ab185f1b004759e8c85b48631f511cb43088424190c3f27c715bb8414
Image: transwarp/zookeeper:transwarp-6.0.2-final
Image ID: docker-pullable://transwarp/zookeeper@sha256:19bf952dedc70a1d82ba9dd9217a2b7e34fc018561c2741d8f6065c0d87f8a10
Port: <none>
Args:
boot.sh
LICENSE_NODE
State: Terminated
Reason: Error
Exit Code: 1
Started: Mon, 11 Oct 2021 17:12:09 +0800
Finished: Mon, 11 Oct 2021 17:12:10 +0800
Last State: Terminated
Reason: Error
Exit Code: 1
Started: Mon, 11 Oct 2021 17:07:07 +0800
Finished: Mon, 11 Oct 2021 17:07:08 +0800
Ready: False
Restart Count: 8
Environment:
ZOOKEEPER_CONF_DIR: /etc/license/conf
Mounts:
/etc/license/conf from conf (rw)
/etc/localtime from timezone (rw)
/etc/tos/conf from tos (rw)
/etc/transwarp/conf from transwarphosts (rw)
/usr/lib/transwarp/plugins from plugin (rw)
/var/license from data (rw)
/var/log/license/ from log (rw)
/var/run/secrets/kubernetes.io/serviceaccount from default-token-g42jt (ro)
/vdir from mountbind (rw)
Conditions:
Type Status
Initialized True
Ready False
PodScheduled True
Volumes:
data:
Type: HostPath (bare host directory volume)
Path: /var/license
HostPathType:
conf:
Type: HostPath (bare host directory volume)
Path: /etc/license/conf
HostPathType:
log:
Type: HostPath (bare host directory volume)
Path: /var/log/license/
HostPathType:
mountbind:
Type: HostPath (bare host directory volume)
Path: /transwarp/mounts/license
HostPathType:
plugin:
Type: HostPath (bare host directory volume)
Path: /usr/lib/transwarp/plugins
HostPathType:
timezone:
Type: HostPath (bare host directory volume)
Path: /etc/localtime
HostPathType:
transwarphosts:
Type: HostPath (bare host directory volume)
Path: /etc/transwarp/conf
HostPathType:
tos:
Type: HostPath (bare host directory volume)
Path: /etc/tos/conf
HostPathType:
default-token-g42jt:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-g42jt
Optional: false
QoS Class: BestEffort
Node-Selectors: zookeeper-server-license=true
Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
node.kubernetes.io/unreachable:NoExecute for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulMountVolume 15m kubelet, uf30-tdh3-regression MountVolume.SetUp succeeded for volume "default-token-g42jt"
Normal SuccessfulMountVolume 15m kubelet, uf30-tdh3-regression MountVolume.SetUp succeeded for volume "conf"
Normal SuccessfulMountVolume 15m kubelet, uf30-tdh3-regression MountVolume.SetUp succeeded for volume "tos"
Normal SuccessfulMountVolume 15m kubelet, uf30-tdh3-regression MountVolume.SetUp succeeded for volume "mountbind"
Normal SuccessfulMountVolume 15m kubelet, uf30-tdh3-regression MountVolume.SetUp succeeded for volume "transwarphosts"
Normal SuccessfulMountVolume 15m kubelet, uf30-tdh3-regression MountVolume.SetUp succeeded for volume "log"
Normal SuccessfulMountVolume 15m kubelet, uf30-tdh3-regression MountVolume.SetUp succeeded for volume "plugin"
Normal SuccessfulMountVolume 15m kubelet, uf30-tdh3-regression MountVolume.SetUp succeeded for volume "data"
Normal SuccessfulMountVolume 15m kubelet, uf30-tdh3-regression MountVolume.SetUp succeeded for volume "timezone"
Normal Scheduled 15m default-scheduler Successfully assigned zookeeper-server-license-7fbfc544fc-h8nn9 to uf30-tdh3-regression
Normal Pulled 15m (x3 over 15m) kubelet, uf30-tdh3-regression Successfully pulled image "transwarp/zookeeper:transwarp-6.0.2-final"
Normal Created 15m (x3 over 15m) kubelet, uf30-tdh3-regression Created container
Normal Started 15m (x3 over 15m) kubelet, uf30-tdh3-regression Started container
Normal Pulling 15m (x4 over 15m) kubelet, uf30-tdh3-regression pulling image "transwarp/zookeeper:transwarp-6.0.2-final"
Warning BackOff 44s (x70 over 15m) kubelet, uf30-tdh3-regression Back-off restarting failed container6.2 问题排查复盘:通过命令 kubectl logs xxx 查看 pod 容器底层的应用程序的日志
接下来我们尝试通过命令 kubectl logs xxx 查看 pod 容器底层的应用程序的日志,以期找到问题的原因,该命令的输出部分截图如下所示: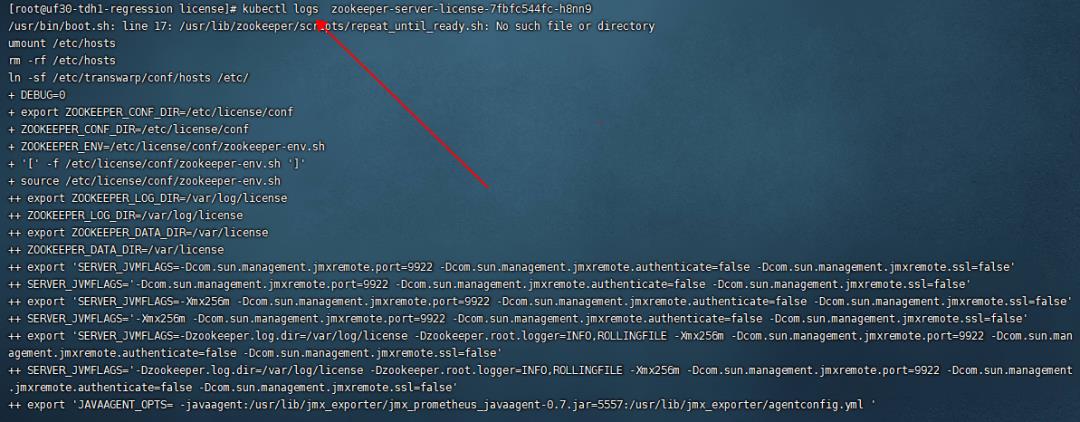
如上图所见,不幸的是,该命令的输出,没有展示出问题的根本原因。
在底层日志机制上,应该是星环 tdh 中该 zk 应用没有将日志打印到标准输出 stdout 和标准错误 stderr, 所以 kubectl logs xxx 查看不到对应的日志。
我们需要进一步排查。
6.3 问题排查复盘:进一步获取并查看 pod 容器底层的应用程序的其它日志文件,深挖问题原因
进一步排查问题,我们首先需要获取 pod 容器底层的应用程序的其它日志文件的路径。
由于 tdh 是闭源的,我们查看不到应用程序的源码,在没有联络官方客户的情况下,我们可以通过命令 kubectl describe pod xxx 查看该 pod 挂载了哪些 volume,然后猜测并验证获得具体的日志文件的路劲给,(排查问题就是要,大胆猜想,小心求证!)
该命令输出的部分截图如下,我们看到其中挂载了路径 /var/log/license: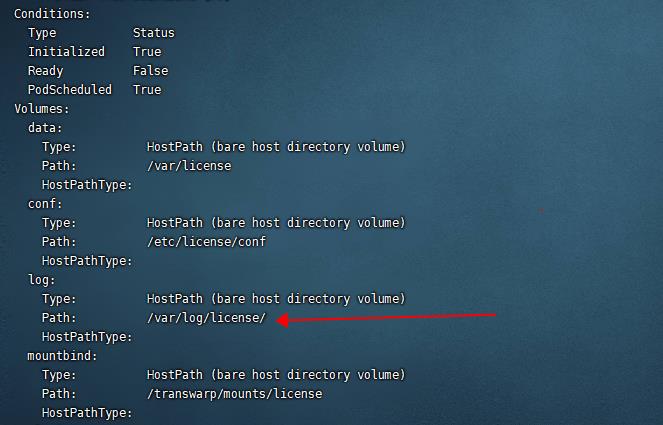
接下来我们查看这些日志文件/var/log/license,尝试深挖问题原因,注意,该文件是本地文件系统的文件,需要登录到对应的节点上去查看,该日志文件部分关键截图如下: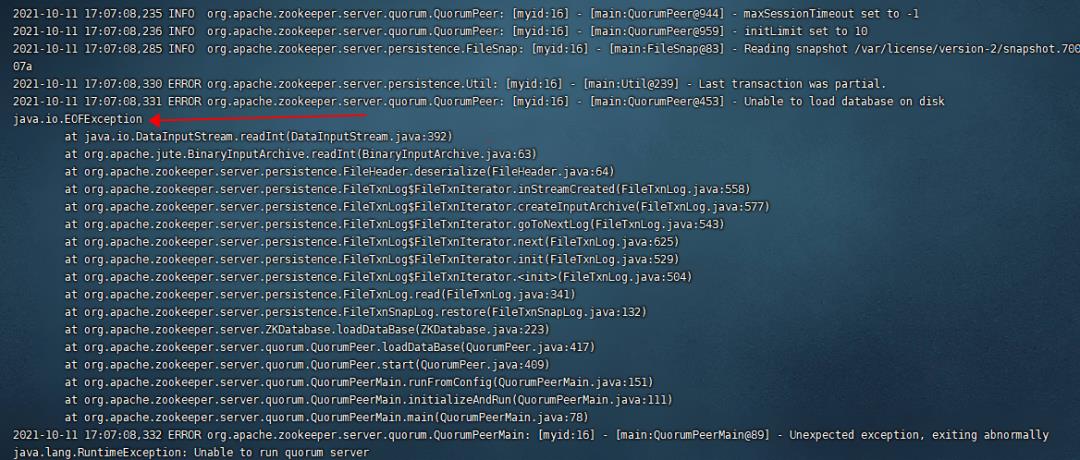
通过日志,问题原因找到了:zk 底层存储在本地文件系统中的文件 /var/license/version-2/snapshot.70000007a 损坏了,所以无法启动:
2021-10-11 17:07:08,330 ERROR org.apache.zookeeper.server.persistence.Util: [myid:16] - [main:Util@239] - Last transaction was partial.
2021-10-11 17:07:08,331 ERROR org.apache.zookeeper.server.quorum.QuorumPeer: [myid:16] - [main:QuorumPeer@453] - Unable to load database on disk
java.io.EOFException at java.io.DataInputStream.readInt(DataInputStream.java:392)该日志文件详细内容如下:
tail -50 /var/log/license/zookeeper.log
2021-10-11 17:07:08,203 INFO org.apache.zookeeper.server.DatadirCleanupManager: [myid:16] - [main:DatadirCleanupManager@101] - Purge task is not scheduled.
2021-10-11 17:07:08,212 INFO org.apache.zookeeper.server.quorum.QuorumPeerMain: [myid:16] - [main:QuorumPeerMain@127] - Starting quorum peer
2021-10-11 17:07:08,221 INFO org.apache.zookeeper.server.NioserverCnxnFactory: [myid:16] - [main:NIOServerCnxnFactory@94] - binding to port 0.0.0.0/0.0.0.0:2291
2021-10-11 17:07:08,235 INFO org.apache.zookeeper.server.quorum.QuorumPeer: [myid:16] - [main:QuorumPeer@913] - tickTime set to 9000
2021-10-11 17:07:08,235 INFO org.apache.zookeeper.server.quorum.QuorumPeer: [myid:16] - [main:QuorumPeer@933] - minSessionTimeout set to -1
2021-10-11 17:07:08,235 INFO org.apache.zookeeper.server.quorum.QuorumPeer: [myid:16] - [main:QuorumPeer@944] - maxSessionTimeout set to -1
2021-10-11 17:07:08,236 INFO org.apache.zookeeper.server.quorum.QuorumPeer: [myid:16] - [main:QuorumPeer@959] - initLimit set to 10
2021-10-11 17:07:08,285 INFO org.apache.zookeeper.server.persistence.FileSnap: [myid:16] - [main:FileSnap@83] - Reading snapshot /var/license/version-2/snapshot.70000007a
2021-10-11 17:07:08,330 ERROR org.apache.zookeeper.server.persistence.Util: [myid:16] - [main:Util@239] - Last transaction was partial.
2021-10-11 17:07:08,331 ERROR org.apache.zookeeper.server.quorum.QuorumPeer: [myid:16] - [main:QuorumPeer@453] - Unable to load database on disk
java.io.EOFException
at java.io.DataInputStream.readInt(DataInputStream.java:392)
at org.apache.jute.BinaryInputArchive.readInt(BinaryInputArchive.java:63)
at org.apache.zookeeper.server.persistence.FileHeader.deserialize(FileHeader.java:64)
at org.apache.zookeeper.server.persistence.FileTxnLog$FileTxnIterator.inStreamCreated(FileTxnLog.java:558)
at org.apache.zookeeper.server.persistence.FileTxnLog$FileTxnIterator.createInputArchive(FileTxnLog.java:577)
at org.apache.zookeeper.server.persistence.FileTxnLog$FileTxnIterator.goToNextLog(FileTxnLog.java:543)
at org.apache.zookeeper.server.persistence.FileTxnLog$FileTxnIterator.next(FileTxnLog.java:625)
at org.apache.zookeeper.server.persistence.FileTxnLog$FileTxnIterator.init(FileTxnLog.java:529)
at org.apache.zookeeper.server.persistence.FileTxnLog$FileTxnIterator.<init>(FileTxnLog.java:504)
at org.apache.zookeeper.server.persistence.FileTxnLog.read(FileTxnLog.java:341)
at org.apache.zookeeper.server.persistence.FileTxnSnapLog.restore(FileTxnSnapLog.java:132)
at org.apache.zookeeper.server.ZKDatabase.loadDataBase(ZKDatabase.java:223)
at org.apache.zookeeper.server.quorum.QuorumPeer.loadDataBase(QuorumPeer.java:417)
at org.apache.zookeeper.server.quorum.QuorumPeer.start(QuorumPeer.java:409)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.runFromConfig(QuorumPeerMain.java:151)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.initializeAndRun(QuorumPeerMain.java:111)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.main(QuorumPeerMain.java:78)
2021-10-11 17:07:08,332 ERROR org.apache.zookeeper.server.quorum.QuorumPeerMain: [myid:16] - [main:QuorumPeerMain@89] - Unexpected exception, exiting abnormally
java.lang.RuntimeException: Unable to run quorum server
at org.apache.zookeeper.server.quorum.QuorumPeer.loadDataBase(QuorumPeer.java:454)
at org.apache.zookeeper.server.quorum.QuorumPeer.start(QuorumPeer.java:409)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.runFromConfig(QuorumPeerMain.java:151)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.initializeAndRun(QuorumPeerMain.java:111)
at org.apache.zookeeper.server.quorum.QuorumPeerMain.main(QuorumPeerMain.java:78)
Caused by: java.io.EOFException
at java.io.DataInputStream.readInt(DataInputStream.java:392)
at org.apache.jute.BinaryInputArchive.readInt(BinaryInputArchive.java:63)
at org.apache.zookeeper.server.persistence.FileHeader.deserialize(FileHeader.java:64)
at org.apache.zookeeper.server.persistence.FileTxnLog$FileTxnIterator.inStreamCreated(FileTxnLog.java:558)
at org.apache.zookeeper.server.persistence.FileTxnLog$FileTxnIterator.createInputArchive(FileTxnLog.java:577)
at org.apache.zookeeper.server.persistence.FileTxnLog$FileTxnIterator.goToNextLog(FileTxnLog.java:543)
at org.apache.zookeeper.server.persistence.FileTxnLog$FileTxnIterator.next(FileTxnLog.java:625)
at org.apache.zookeeper.server.persistence.FileTxnLog$FileTxnIterator.init(FileTxnLog.java:529)
at org.apache.zookeeper.server.persistence.FileTxnLog$FileTxnIterator.<init>(FileTxnLog.java:504)
at org.apache.zookeeper.server.persistence.FileTxnLog.read(FileTxnLog.java:341)
at org.apache.zookeeper.server.persistence.FileTxnSnapLog.restore(FileTxnSnapLog.java:132)
at org.apache.zookeeper.server.ZKDatabase.loadDataBase(ZKDatabase.java:223)
at org.apache.zookeeper.server.quorum.QuorumPeer.loadDataBase(QuorumPeer.java:417)
... 4 more7 问题解决
通过以上通用问题排查思路,我们查看日志找到了问题原因:zk 底层存储在本地文件系统中的文件 /var/license/version-2/snapshot.70000007a 损坏了,所以无法启动。由于集群中 zk 是有多个节点的,且其它节点的 zk 启动是成功的,所以我们 可以删除该问题节点上述目录下的数据文件,然后重启该节点的 zk, 重启后该节点的 zk 就可以从其它节点复制数据到本地,就可以正常对外提供服务了!
zk 底层存储在本地文件系统中的文件,在正常节点于问题节点,对比截图如下:
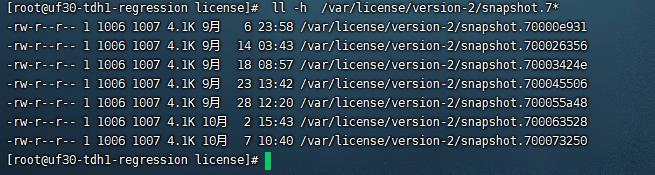
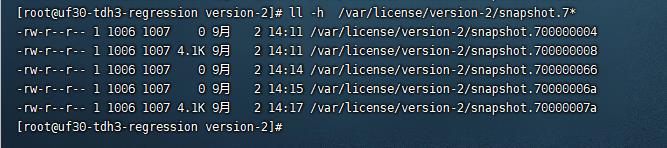
按照上述方法,清空目录重启zk后,kubectl get pods 查看服务正常,截图如下:

注意:其实 zk 也提供了系统工具 zkCleanup.sh 来清理本地数据文件,笔者没有使用该工具,而是手工备份和清空了问题节点的本地文件。大家可以自行尝试该工具。
8 知识总结
-
大数据从业者,需要不断扩展自己的技能包,掌握 Kubernetes 和 Docker 的基础知识和常见命令,才能在排查大数据相关问题时不至于捉襟见肘,因技能储备短缺,无从下手;
-
某个 pod 处于 CrashloopBackOff, 意味着该 pod 中的容器被启动了,然后崩溃了,接下来又被自动启动了,但又崩溃了,如此周而复始,陷入了(starting, crashing, starting,crashing)的循坏;
-
当 pod 容器底层的应用程序运行出现故障时,通用的排查思路,一般是:
-
步骤一:通过命令 kubectl describe pod xxx 获取 pod 详细信息;
-
步骤二:通过命令 kubectl logs xxx 查看 pod 容器底层的应用程序的日志;
-
步骤三:进一步获取并查看 pod 容器底层的应用程序的其它日志文件,深挖问题原因;
-
-
kubectl logs 展示的是 pod 底层的 container 的标准输出 stdout 和标准错误 stderr 的日志, 应用程序写到其它文件的日志,kubectl logs 展示不了,需要获取日志文件路径,并自行查看
-
k8s 建议应用程序将日志写到 container 的标准输出 stdout 和标准错误 stderr;
-
容器内的应用程序可以将日志直接写到 container 的标准输出 stdout 和标准错误 stderr;如果容器内的应用程序不能或不方便将日志直接写到 container 的标准输出 stdout 和标准错误 stderr,可以使用 sidecar 即边车模式,在应用程序的 container 所在的 pod 内部署另一个 sidecar container,该 sidecar container 负责读取应用程序的日志文件并输出到其标准输出 stdout 和标准错误 stderr 里;
-
k8s 在底层会通过运行在各个节点的 kubelet 来收集节点中所有 container 的 stdout 和 stderr 日志,并写到一个 kubelet 管理的本地文件中;
-
用户执行 kubectl logs xx 命令时,该命令在底层会调用该 container 对应节点上的 kubelet 来检索其管理的本地日志文件,以获取日志;
-
用户使用 kubectl log xxx 来检索应用程序日志,省去了用户登录 k8s 集群中对应节点查看对应日志的繁琐操作,提供了很大便利;
-
排查问题,需要大胆猜想小心求证!
!关注不迷路~ 各种福利、资源定期分享!欢迎小伙伴们扫码添加明哥微信,后台留言,拉你加群交流学习!
以上是关于Kubernetes 应用问题的通用排查思路 - 大数据从业者之 Kubernetes 必知必会的主要内容,如果未能解决你的问题,请参考以下文章