基于BP神经网络及Pygame创做坦克自动扫雷机
Posted Fantaley
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于BP神经网络及Pygame创做坦克自动扫雷机相关的知识,希望对你有一定的参考价值。
本文章是基于BP神经网络及Pygame创做坦克自动扫雷机案例的第三篇;本文的主要内容是BP神经网络的原理介绍以及Python中使用Keras创建BP神经网络的案例,最终实现扫雷机自动判断和转向。
目录
前言
随着人工智能的不断发展,人工智能算法在许多领域中都得到了很好的应用,本文案例就是利用BP神经网络在Pygame里判断坦克自动转向以及扫雷,本文不详细介绍神经网络的基础算法,只介绍BP神经网络的应用,没有神经网络基础的同学还请参考神经网络相关文章。
上文中提到扫雷机能够实现扫除地雷,与避障传感器也就是扫雷圈的组合,后面将根据训练的神经网络模型进行自动扫雷。

以下是本篇文章正文内容
一、BP神经网络
BP神经网络是目前为止非常成功的神经网络算法,其特点在于模型能不断得到结果反馈,每次根据训练得到的结果与预想结果进行误差分析,进而修改权值和阈值,一步一步得到能输出和预想结果一致的模型。这是众多机器学习算法中的独特的优势。
BP神经网络只需要搭建全连接层就能完成模型的搭建,在本案例中,我们需要搭建三层的神经网络模型,设计思路如下。
1.获取数据集
数据集对神经网络模型影响是非常大的,这里我们先讨论数据的输入与结果的输出。一个训练好的神经网络模型是需要对输入的数据进行处理、识别并最终得到一个想要的结果。那么在扫雷机案例中我们需要输入什么数据让坦克自动扫雷呢?我们可以利用扫雷机当前的前行角度、最近的地雷位置差来作为数据的输入,也要用作训练的数据集。
2.数据预处理
数据归一化,BP神经网络的缺点就是训练速度慢,为了提高训练效率,我们通常需要进行数据归一的预处理,由于扫雷圈的照片大小是250*250,因此我们对最近的地雷位置差除250,当前的前行角度除180,就能保证数值在[-1,1]之间。
3.模型构建
BP神经网络通常需要搭建3层网络,即输入层,隐藏层,输出层。连接输入层和隐藏层的是权值矩阵W1和编制节点B1,可以看出隐藏层运算十分简单:H=XW1+B1,从隐藏层到输入层同样也是这样计算:Y=HW2+B2。
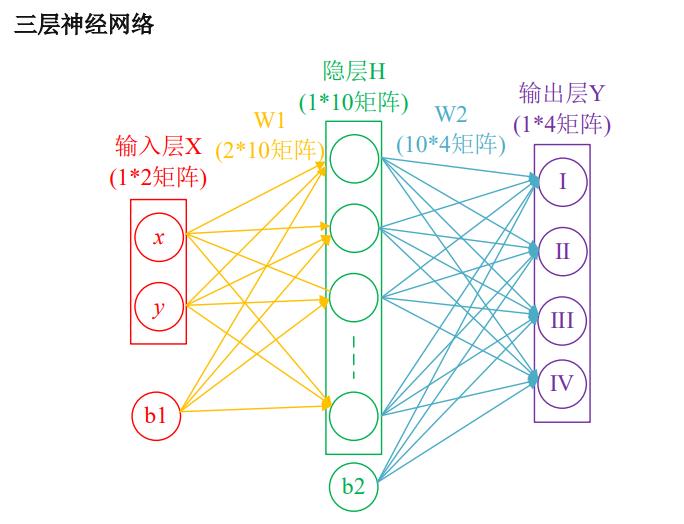
权值W和编制B对神经网络的训练结果影响很大,那么我们怎么很好的确定它们的值呢,这里就体现BP神经网络的优点:反向传播与参数优化。在每一层的输出加上激活层,如Sigmoid函数,优化的对象就是网络中的W和B,具体优化方法如下:
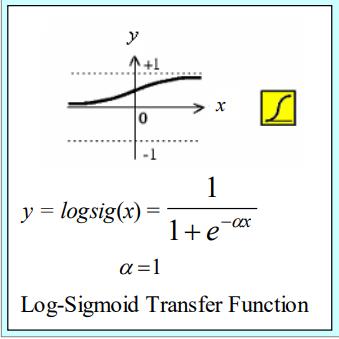

4.模型评估
训练好的模型通常会对其进行模型评估,即获取它的正确率和损失率,如果没达到好的效果则需要进行向上再次调整。通常使用的损失率函数有MSE平方损失函数、绝对值损失函数、预测值百分率损失函数、均方对数误差MSE+log等。
5.模型保存与调用
经以上步骤得到一个训练的模型后,我们通常会将模型保存,并对新的数据进行调用、预测得到新的结果。
二、Keras搭建BP神经网络模型
了解BP神经网络模型设计的步骤后,我们开始搭建扫雷机的神经网络模型.
1.Pandas生成数据集
前面讲到数据集对神经网络模型训练影响很大,所以我们这里先利用Pandas生产一个数据集。在这里数据集取扫雷机当前的前行角度、最近的地雷位置差,取30000*4个数据。4列分为3个训练列,1和结果列。3个训练列为扫雷机当前的前行角度angle、扫雷机与最近地雷X坐标差dx、扫雷机与最近地雷Y坐标差dy。结果列为0代表右转,1代表左转,总共30000个样本。
实现步骤如下:
1.引入库、生成数据
import random
import pandas as pd
df = pd.DataFrame() #数据生成后大小(30000,4)
for i in range(30000):#生产30000个数据
#随机生成最近地雷x,y坐标。值小于250是因为扫雷圈大小为250*250
mine_x=random.randint(0,250)
mine_y=random.randint(0,250)
#随机生成扫雷机x,y坐标。值小于250是因为扫雷圈大小为250*250
sweeper_x = random.randint(0, 250)
sweeper_y = random.randint(0, 250)
#随机生成扫雷机角度
angle = random.randint(-180, 180)
dx=mine_x-sweeper_x
dy=mine_y-sweeper_y
df.at[i,'DX']=dx
df.at[i,'DY']=dy
df.at[i,'Angle']=angle
这样我们就生成了30000个数据训练样本。但是结果样本,也就是右转还是左转怎么判断呢?首先最近地雷坐标在上一篇文章中通过以下函数就能判断坦克和地雷是否相碰,这里我们是来判断最近地雷的,所以我们不需要将它扫掉,这里把api的实现就是把True改成False就行,返回值是一个列表,第一个值就是最近地雷的坐标。
好了,我们知道最近地雷的坐标,那么怎么判断转向呢,对照下图(这里注意一下,y轴是越往下值越大,dx,dy都是地雷减去扫雷机)。假如最近地雷和扫雷机三个训练参数dx,dy,angle分别为:-70,-60,10,那我们就应该是左转,也就是1.可以通过以下数据再自行判断一下:
dx,dy,angle,Turn
73, 66, 131, 1
-63,-21, 108, 0
16, 118,-106, 0
41, -143,-28, 1
等等
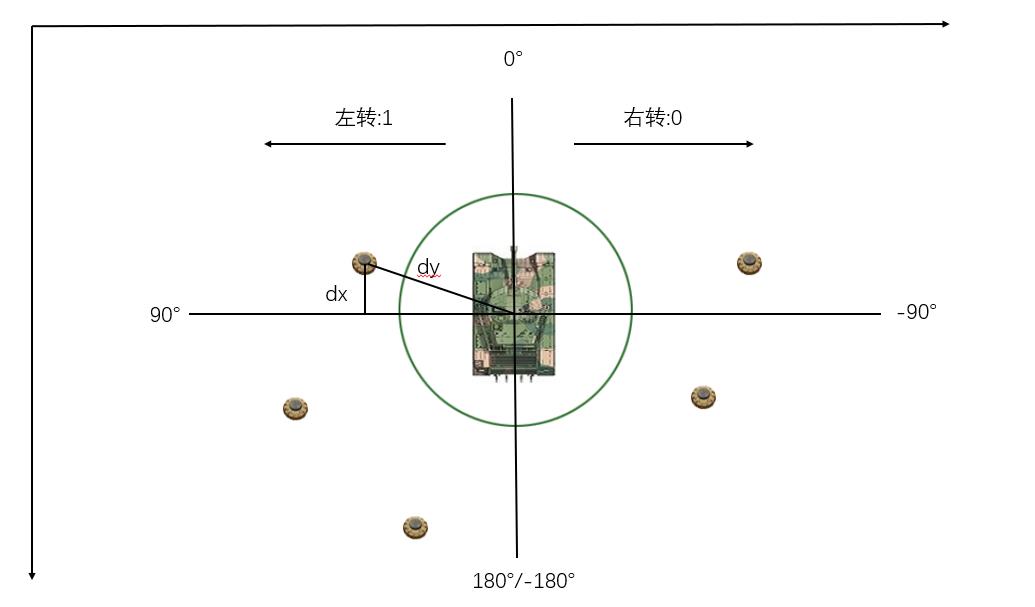
那我们是怎么判断的呢,我们看以下代码
if (dx<=0 and dy<=0 and -90<=angle<0 ) or (dx<=0 and dy<=0 and 0<=angle<=90 ) or (dx<=0 and dy>=0 and 0<=angle<=90) or (dx>=0 and dy<=0 and -90<=angle<0) or (dx<=0 and dy>=0 and -90<=angle<0) or (dx>=0 and dy<=0 and 90<angle<=180 ) or (dx>=0 and dy<=0 and -180<=angle<-90 ) or (dx>=0 and dy>=0 and 90<angle<=180 ):
df.at[i,'Turn'] = 1
elif (dx<=0 and dy<=0 and 90<angle<=180 ) or (dx<=0 and dy>=0 and 90<angle<=180) or (dx<=0 and dy<=0 and -180<=angle<-90 ) or (dx<=0 and dy>=0 and -180<=angle<-90) or (dx>=0 and dy>=0 and -180 <=angle <-90 ) or (dx>=0 and dy<=0 and 0<=angle<=90 ) or (dx>=0 and dy>=0 and 0<=angle<=90 ) or (dx>=0 and dy>=0 and -90<=angle<0 ):
df.at[i,'Turn'] = 0
这段代码就是很多种情况下判断左转还是右转,我们理解好转向方式就能很快写出。
最后我们保存成train_better.csv文件,方便模型的训练
df.to_csv(r'C:\\Users\\ASUS\\Desktop\\class design yuan (1)\\test\\train_better.csv')
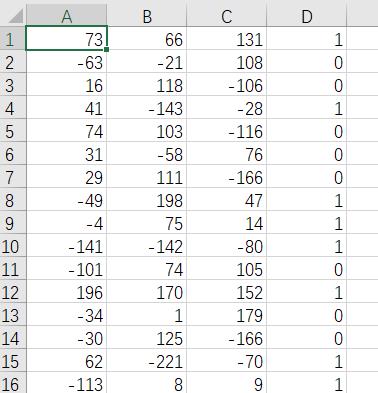
打开csv文件看一看,这里有30000个数据,我们看前面一部分就ok,可以发现数据是正确的。这里为了方便训练,这里我把数据标签dx,dy,angle,turn都去掉了。
2.引入keras库
数据集搭建好了,我们正式搭建BP神经网络。首先我们创建一个BP_Network的py文件,我们在该py文件中引入相应Keras的库。如下所示:其中numpy是神经网络不可缺少的数学计算库;
sklearn.model_selection类是对数据集划分成训练集和测试集,使模型训练更加可靠。
tensorflow.keras.models类就是创建整个神经网络的模型,所有的层数都添加在这个model里面。相当于在建房子中,model类就是整个房子框架。
tensorflow.keras.layers类就是创建神经网络模型的层数,偏置、激活函数都使在layers里设置。相当于在建房子中,layers就是一层一层地楼层构架。
import numpy as np
import tensorflow as tf
from sklearn.model_selection import train_test_split
from tensorflow.keras.layers import Dense,Activation,BatchNormalization #导入需要的层
from tensorflow.keras import regularizers #正则化
from tensorflow.keras.models import Sequential #构造模型
3.数据处理
在BP_Network.py文件中,我们先调用生成好的数据集train_better.csv文件,由于csv文件都是由逗号分开的,因此我们这里要将数据分开,并对行,列进行重新划分,确保神经网络输入层是3个神经元。代码展示如下
filepath = r'C:\\Users\\ASUS\\Desktop\\class design yuan (1)\\test\\train_better.csv'
dataset = np.loadtxt(filepath,encoding='utf-8',delimiter=',')
x = dataset[:,0:3]#dx,dy,angle
y = dataset[:,3]
y = y.reshape(30000,1)#Turn
数据划分,数据结构定义后,我们进行数据划分,这里将训练集和测试集进行55开,也就是训练集和测试集都是15000个。方便对后期模型进行评估:
x_train,x_test,y_train,y_test = train_test_split(x,y,train_size=0.5,random_state=2)
数据归一化,提高神经网络训练效率和准确率,这里对数据进行归一化,具体将dx,dy除以250(最大值),angle除以180,使所有的值在[-1,1]间。代码如下
for j in range(15000):
x_train[j][0] = x_train[j][0]/250
x_train[j][1] = x_train[j][1]/250
x_train[j][2] = x_train[j][2]/180
x_test[j][0] = x_test[j][0]/250
x_test[j][1] = x_test[j][1]/250
x_test[j][2] = x_test[j][2]/180
4.模型搭建
接下来,要正式搭建神经网络了,首先我们要搭整个框架,也就是model模型
model = Sequential()
整体框架搭好了,我们就要一层一层搭房子了,首先我们加入输入层,输入层需要三个神经元,使用偏置。
model.add(Dense(3,input_dim=3,use_bias=True))
由于我们输入的数据集里有负数,因此我们这里不适用Sigmoid激活函数,而是选用tanh函数
model.add(Activation('tanh'))
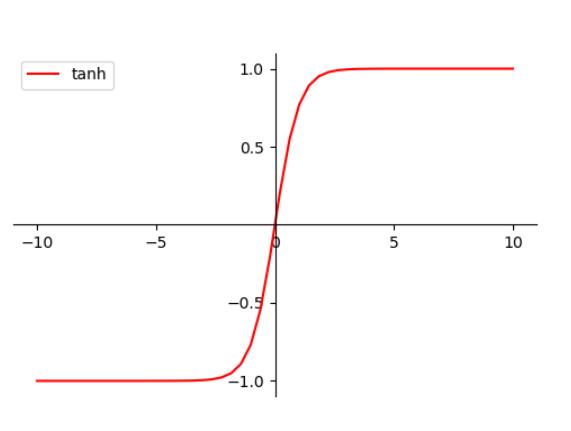
OK,第一层搭好了,接下来我们搭第二层。由于我们数据样本足够,输入层简单,在隐藏层里只是用了5个神经元,并引入L2正则化,降低模型复杂度,防止过拟合。
L2正则化: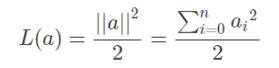
model.add(Dense(5,kernel_regularizer=regularizers.l2(0.001),use_bias=True))
之后,在这里引入BN层:BN层能够将数据归一到标准分布,可以不使用偏置,解决中间层数据分布发生改变的问题,以防止梯度消失或爆炸、加快训练速度。同样,也是用tanh激活函数。如果训练还是过拟合可以在这里加入Dropout正则化。
model.add(BatchNormalization())
model.add(Activation('tanh'))
最后,我们来到了输出层,输出层很简单,实则我们是个二分类问题,左转还是右转,即1还是0,这里使用Sigmoid激活函数。
model.add(Dense(1,use_bias=True))
model.add(Activation('sigmoid'))
4.模型编译
这里设置模型训练使用的损失函数即对数损失函数binary_crossentropy和优化方法Adam,binary_crossentropy损失函数通常在二分类问题中出现。Adam优化算法是一种对随机梯度下降法的扩展,能取得不错的效果。这里说明一下,损失函数用来衡量预测值与真实值之间的差异,优化器用来使用损失函数达到最优。
model.compile(loss=tf.keras.losses.binary_crossentropy,optimizer=tf.keras.optimizers.Adam(),metrics=tf.keras.metrics.Accuracy())
5.模型训练
模型训练中,我们要先导入测试集,设置每次送入模型中样本个数batch_size和epochs所有样本的迭代次数,由于计算机是二进制计算,这里推荐epochs使用4,16,31,64,128等。为了更好的看到训练过程中网络内部的状态和统计信息,我们加入callback回调函数,回调函数的优点是:能保存当前模型的所有权重提早结束:当模型的损失不再下降的时候就终止训练,当然,会保存最优的模型、动态调整训练时的参数,比如优化的学习率。这里我们也能利用ReduceLROnPlateau函数调整学习率。
首先导入callbacks类
from keras.callbacks import ReduceLROnPlateau
#调整学习率函数,监督损失函数,当10个epoch过去而模型性能不提升时,学习率减少的动作会被触发
reduce_lr = ReduceLROnPlateau(monitor='val_loss', patience=10, mode='auto')
训练的结果返回给history
history = model.fit(x_train,y_train,epochs=500,batch_size=64,validation_data=(x_test,y_test),callbacks=[reduce_lr])
在这里我们可以打印看一下层数结构
print(model.summary())
运行如下
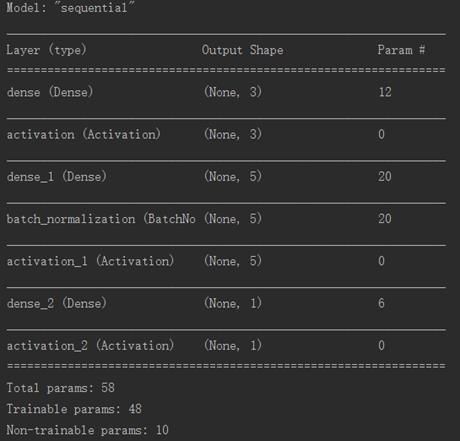
训练时间可能比较久,大家耐心等待。训练完成后,我们可以将训练结果保存,可得到model.h5文件。

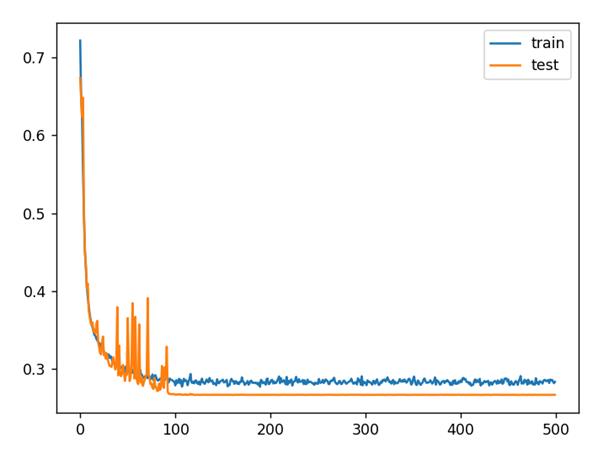
为了更加直观的显示训练结果,我们利用Matplotlib对损失率进行绘图
plt.figure()
plt.plot(history.history['loss'],label = 'train')
plt.plot(history.history['val_loss'],label = 'test')
plt.legend()
plt.grid
plt.show()
结果如图所示,效果还是不错的。
总结
好了,今天的文章就分享到这里,主要展示了BP神经网络的介绍、Pandas数据集的生成、Keras神经网络模型的搭建与训练、Matplotlib数据可视化的生成。下一篇文章将介绍用训练好的神经网络模型在扫雷机里的使用。
这里贴出整个工程的代码,网友们可根据情况使用:
BP神经网络及Pygame创做坦克自动扫雷机代码
以上是关于基于BP神经网络及Pygame创做坦克自动扫雷机的主要内容,如果未能解决你的问题,请参考以下文章