性能分析之TPS从300到750的过程
Posted zuozewei
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了性能分析之TPS从300到750的过程相关的知识,希望对你有一定的参考价值。
背景
前几天在 7DGroup 的群中,小鹏同学提了一个问题。
群里一顿讨论。终于有了优化的结果。小鹏特此记录。
先画一个架构图:

画架构图是为了知道请求是从哪里到哪里,做性能分析一定先画个图,脑子里就会有路径的概念了。
问题1:TPS呈锯齿状,忽高忽低
直接上图如下:

163 服务器(4c/8g),cpu 使用率在 60 %左右,15 分钟负载没有超过 cpu 总核数,因此 163 服务器表现良好。还有上升空间。
164 服务器(2c/4g)本身配置较低,cpu 使用率在 60 %左右,15 分钟负载跟 cpu 总核数基本持平。可作为优化点考虑。


106 服务器(4c/8g)cpu 使用率在 60%,15分 钟负载也没有超过 cpu 总核数,表现也算良好,还有一定的上升空间。
107 服务器(2c/8g)cpu 使用率已经达到 100%,15 分钟负载已经超过 CPU 总核数一倍,明显已经压满了。


数据库服务器(8c/16g)CPU 使用率在 30 左右,15 分钟平均负载 2 低于 CPU 总核数 8,明显压力没在数据库上。

询问开发后得知,在该项目中加入了动态流量分布(备注如下),了解了动态流量分布的代码逻辑之后,发现 TPS 的锯齿状的间隔时间正好 是30s,TPS 锯齿状的原因是动态流量分布导致的。虽然在将流量分给空闲的服务器的时候,TPS 是高了,但是从配置低的 107 服务器来看,不管有没有将它的流量分走,它都是撑不住的。
优化方案:
- 将107下线,找一台和106配置相同的机器做测试。
备注:动态流量分布即根据实际服务器的负载以及 CPU 使用率,动态的将流量分给相对空闲的服务器,每 30 s一次做轮询,轮询发现 A 服务器 CPU 以及负载过高,接下来的 30 s会将流量引流到空闲的服务器上。在做轮询的同时,流量是均匀分布的。
问题2:调整数据库参数
针对问题 1 将 107 下线,找一台和 106 配置相同的机器做测试,还是测试相同的接口。
从全局监控角度来看,TPS 达到 610/2=300 多,服务器的 CPU 使用率约占到 60%,且各个服务器并没有出现负载,由此可见服务器均没有压满,还有上升空间。
但是使用mysqlreport来看,发现有几个参数需要做下调整。
InnoDB Buffer Pool 这个参数值使用率到了100了,肯定是到了瓶颈。

Tables 这个值也用到了100%,这块需要修改下。

Query cache 没有开。Block Fragment 达到 100%
Block Fragmnt:是指内存块碎片,如果你有一个返回超小结果的海量查询,默认的块大小(即4KB)可能会导致大量的内存碎片,这个时候,需要降低"query_cache_min_res_unit"的值,比值越大,碎片越多,一般不建议超过20%。


优化方案:
先调整下InnoDB Buffer Pool
show variables like 'innodb_buffer_pool%';
SET GLOBAL innodb_buffer_pool_size= 1207959552; #调成1g,后面又调整成了2g,需要根据实际情况调整
再调整:table_open_cache 和 query_cache。
set GLOBAL table_open_cache = 1000;
set GLOBAL query_cache_type = 1;
或修改配置文件:
sudo vim /etc/mysql/mysql.conf.d/mysqld.cnf
innodb_buffer_pool_size = 2G
table_open_cache = 1000
query_cache_type = 1
调整 MySQL 配置参数之后,TPS 还是不高,大概 640/2=310 多,看来数据库不是性能瓶颈,而且 TPS 还是不规律,还是每30s就波动一次,建议把动态分配流量去掉之后再测试。
调整 MySQL 参数之后的 MySQLReport 数据:



问题3:网络队列
去掉动态分配流量之后,还是相同的接口 TPS 较为稳 定400 左右。
发现问题:所有服务器各个指标的使用率都不高,但是 CRM 和 MySQL之间的互相出现队列。需要查找下原因。


查看 106 服务器网卡中断信息。
watch -d -n 1 "cat /proc/softirqs"
发现 net_rx 分布不均匀,只有一个在忙,剩下三个都在偷懒,
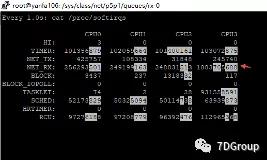
但是 si 不算太高,可以先不处理(将106物理机换成虚拟机)。
接着分析。
TPS 仍然上不去,但是到 106 和 123 服务器上执行 top 命令再按 1 后发现 us 的使用率在个别 CPU 上面冲到了100,但是第三个CPU 的使用率才为1%,很明显 CPU 使用率分布不均匀呀。
于是使用打印栈信息的命令(如下)找到了 CPU 使用率较高的一行栈信息,定位到了java的47行代码。给到开发之后,顺利解决。
top #查找到cpu高的pid
top -Hp 12941 #寻找pid是12941的相关线程
/usr/java/jdk1.8.0_102/bin/jstack
jstack -l 12941 > 12941 #打印12941的栈信息
printf '%x\\n' 12951 #将线程12951转换16进制
printf '%x\\n' 13084
vi 12941 #进入栈文件,寻找16进制的信息

通过 Java visualvm 链接之后,点击线程 dump 按钮,搜索关键词 MySQL ,发现当前有直连 MySQL 的线程,是名叫 pool-6-thread-x 的线程,并且发现它只有4个,而且从线程运行状态来看,这几个线程全绿,明显压满。怀疑是线程数量不够用导致。

优化方案
将该线程增加到 8,结果如下。

TPS 由之前的 500 左右。
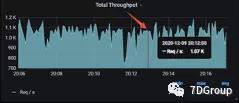
增加到 750 左右。

将线程数量加大之后,发现 TPS 虽然上去了,但是仍然在 CRM 和 MySQL 中间存在队列,这里一个潜在问题—网络。
问题4:网络带宽不足
查看各个服务器的实时带宽。

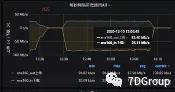
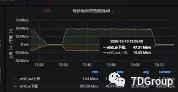
机房简易布线图:

查找交换 机B 型号:tp-link TL-SL1226 的相关参数。
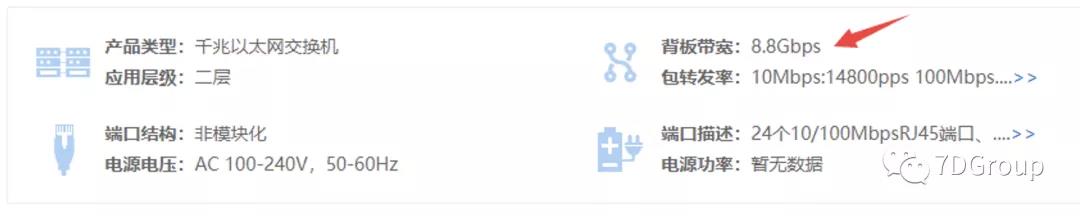
该交换机存在 2 个千兆端口,24 个百兆端口
交换机背板带宽含义:
交换机的背板带宽也叫背板容量,是交换机接口处理器或接口卡和数据总线间所能吞吐的最大数据量。背板带宽标志了交换机总的数据交换能力,单位为Gbps,一般的交换机的背板带宽从几Gbps到上百Gbps不等。一台交换机的背板带宽越高,所能处理数据的能力就越强,但同时设计成本也会越高
背板概念:我个人一直理解成电脑的总线。
背板带宽计算方式:每种端口的速率乘以端口数量之和,再乘以2。
由于进入交换记得端口使用了一个千兆端口,而进入这个端口的流量是由上个交换机的百兆端口分出来的,所以在计算过程中把他当成百兆端口来处理
知道了该交换机的背板带宽是 8.8Gbps
套用计算公式
( 25 x 端 口 速 率 + 1 x 1000 ) x 2 = 8.8 G b p s (25 x 端口速率+1x1000)x2=8.8Gbps (25x端口速率+1x1000)x2=8.8Gbps
算出上游的端口速率=140Mb/s,所以下面的分流不能超过140Mb/s
计算 47+47+35=129(由于该交换机下面还有其他的机器,使用到了流量。由此可见,网络基本被用光。)
交换机硬伤,日后再解决。
问题5:数据问题
在持续的压测过程中发现问题: TPS 存在有规律性的激增,同时也观察到了JMeter 出现报错信息。
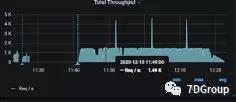

分析原因:是因为数据中有一串用户查不到信息,导致接口报错,瞬时的tps比较高。
优化方案
-
开发处理500报错。
-
使用正确的用户数据。
将后台的报错信息处理完之后,tps波动范围较小,相对稳定了。
结论
一系列优化之后,从 300 TPS 优化至 750 。

在这里,我们只是先优化了一部分应用问题。对于一个性能项目来说当然还没有结束。
后续定位和优化方向:
- 流量分配
- 物理网络带宽
- 资源使用率的具体。
对于性能来说,没有没有瓶颈的系统,性能无止境,且行且调优。
以上是关于性能分析之TPS从300到750的过程的主要内容,如果未能解决你的问题,请参考以下文章