TextCNN代码解读及实战
Posted AI浩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TextCNN代码解读及实战相关的知识,希望对你有一定的参考价值。
摘要
这几天使用TextCNN做文本分类,记录一下学习过程,数据集使用cnews,代码参考github上的代码,地址:https://github.com/BeHappyForMe/Multi_Model_Classification,对重点的代码做了注解,方便自己的理解。关注公众号“AI小浩”,回复“textcnn实战”,获取代码和数据集。
Text模型的计算过程
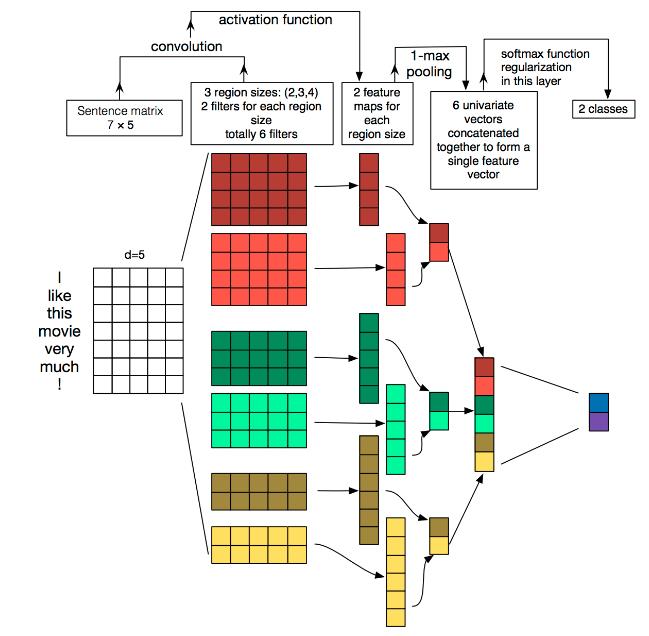
TextCNN的详细过程原理图如下:
代码:
class CNN(nn.Module):
def __init__(self, vocab_size, embedding_dim, num_filter,
filter_sizes, output_dim, dropout=0.2, pad_idx=0):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx=pad_idx)
self.convs = nn.ModuleList([
nn.Conv2d(in_channels=1, out_channels=num_filter,
kernel_size=(fs, embedding_dim))
for fs in filter_sizes
])
# in_channels:输入的channel,文字都是1
# out_channels:输出的channel维度
# fs:每次滑动窗口计算用到几个单词,相当于n-gram中的n
# for fs in filter_sizes用好几个卷积模型最后concate起来看效果。
self.fc = nn.Linear(len(filter_sizes) * num_filter, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, text):
embedded = self.dropout(self.embedding(text)) # [batch size, sent len, emb dim]
embedded = embedded.unsqueeze(1) # [batch size, 1, sent len, emb dim]
print(embedded.shape)
# 升维是为了和nn.Conv2d的输入维度吻合,把channel列升维。
conved = [F.relu(conv(embedded)).squeeze(3) for conv in self.convs]
print(conved[0].shape,conved[1].shape,conved[2].shape)
# conved = [batch size, num_filter, sent len - filter_sizes+1]
# 有几个filter_sizes就有几个conved
pooled = [F.max_pool1d(conv,conv.shape[2]).squeeze(2) for conv in conved] # [batch,num_filter]
print(pooled[0].shape,pooled[1].shape,pooled[2].shape)
x_cat=torch.cat(pooled, dim=1)
print(x_cat.shape)
cat = self.dropout(x_cat)
# cat = [batch size, num_filter * len(filter_sizes)]
# 把 len(filter_sizes)个卷积模型concate起来传到全连接层。
return self.fc(cat)
TextCNN详细过程:
-
Embedding:第一层是图中最左边的7乘5的句子矩阵,每行是词向量,维度=5,这个可以类比为图像中的原始像素点。
对应代码:
self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx=pad_idx)输入的vocab_size是7,embedding_dim是5。
在forward函数中执行embedding后,得到7×5的矩阵。举证的shape为[batch,7,5]
经过 embedded.unsqueeze(1),第二维的前面增加一维,满足卷积的输入,此时的shape为[batch,1,7,5]
-
Convolution:然后经过 kernel_sizes为(2,5),(3,5),(4,5) 的一维卷积层,5是embedding_dim的大小。每个kernel_size 有两个输出 channel。
对应代码:
self.convs = nn.ModuleList([ nn.Conv2d(in_channels=1, out_channels=num_filter, kernel_size=(fs, embedding_dim)) for fs in filter_sizes ])在forward函数中
将升维后的数据,放入卷积中,执行:
conved = [F.relu(conv(embedded)).squeeze(3) for conv in self.convs]卷积的公式为:N=(W-F+2P)/S+1,经过计算第四维数据变成了1,所以就可以降维,降维后的到三个卷积结果,shape分别是:
torch.Size([batch, 2, 4]) torch.Size([batch, 2, 3]) torch.Size([batch, 2, 2]) -
MaxPolling:第三层是一个1-max pooling层,这样不同长度句子经过pooling层之后都能变成定长的表示。
对应forward:
pooled = [F.max_pool1d(conv,conv.shape[2]).squeeze(2) for conv in conved] # [batch,num_filter]由于卷积核的大小是第三维,根据卷积公式可以计算出,经过池化,第三维的大小变成了1。然后再降维,就得到了三个定长的一维向量,向量分别是:
torch.Size([batch, 2]) torch.Size([batch, 2]) torch.Size([batch, 2])然后,将三个向量拼接:
x_cat=torch.cat(pooled, dim=1)就得到了一维向量,向量的大小为:torch.Size([batch, 6])
-
FullConnection and Softmax:最后接一层全连接的 softmax 层,输出每个类别的概率。
说明:
通道(Channels):
- 图像中可以利用 (R, G, B) 作为不同channel;
- 文本的输入的channel通常是不同方式的embedding方式(比如 word2vec或Glove),实践中也有利用静态词向量和fine-tunning词向量作为不同channel的做法。
一维卷积(conv-1d):
- 图像是二维数据;
- 文本是一维数据,因此在TextCNN卷积用的是一维卷积(在word-level上是一维卷积;虽然文本经过词向量表达后是二维数据,但是在embedding-level上的二维卷积没有意义)。一维卷积带来的问题是需要通过设计不同 kernel_size 的 filter 获取不同宽度的视野。
Pooling层:
利用CNN解决文本分类问题的文章还是很多的,比如这篇 A Convolutional Neural Network for Modelling Sentences 最有意思的输入是在 pooling 改成 (dynamic) k-max pooling ,pooling阶段保留 k 个最大的信息,保留了全局的序列信息。
Embedding方式:
-
数据量较大:可以直接随机初始化embeddings,然后基于语料通过训练模型网络来对embeddings进行更新和学习。
-
数据量较小:可以利用外部语料来预训练(pre-train)词向量,然后输入到Embedding层,用预训练的词向量矩阵初始化embeddings。(通过设置weights=[embedding_matrix])。
-
-
静态(static)方式:训练过程中不再更新embeddings。实质上属于迁移学习,特别是在目标领域数据量比较小的情况下,采用静态的词向量效果也不错。(通过设置trainable=False)
-
非静态(non-static)方式:在训练过程中对embeddings进行更新和微调(fine tune),能加速收敛。(通过设置trainable=True)
-
数据集
数据集采用cnews数据集,包含三个文件,分别是cnews.train.txt,cnews.val.txt,cnews,test.txt。类别:体育, 娱乐, 家居, 房产, 教育, 时尚, 时政, 游戏, 科技, 财经,共10个类别。
构建词向量
-
第一步,读取预料,做分词。
-
思路:
-
1、创建默认方式的分词对象seg。
-
2、打开文件,按照行读取文章。
-
3、去掉收尾的空格,将label和文章分割开。
-
4、将分词后的文章放到src_data,label放入labels里。
-
5、返回结果。
-
我对代码做了注解,如下:
-
def read_corpus(file_path): """读取语料 :param file_path: :param type: :return: """ src_data = [] labels = [] seg = pkuseg.pkuseg() #使用默认分词方式。 with codecs.open(file_path,'r',encoding='utf-8') as fout: for line in tqdm(fout.readlines(),desc='reading corpus'): if line is not None: # line.strip()的意思是去掉每句话句首句尾的空格 # .split(‘\\t’)的意思是根据'\\t'把label和文章内容分开,label和内容是通过‘\\t’隔开的。 # \\t表示空四个字符,也称缩进,相当于按一下Tab键 pair = line.strip().split('\\t') if len(pair) != 2: print(pair) continue src_data.append(seg.cut(pair[1]))# 对文章内容分词。 labels.append(pair[0]) return (src_data, labels) #返回文章内容的分词结果和labels -
经过这个步骤得到了labels和分词后的文章。如下代码:
src_sents, labels = read_corpus('cnews/cnews.train.txt')
对labels做映射:
labels = {label: idx for idx, label in enumerate(labels)}
得到labels对应的idx的字典,idx的值是最后一次插入label的值。
第二步 构建词向量
这一步主要用到vocab.py的from_corpus方法
思路:
1、创建vocab_entry对象。
2、对分词后的文章统计词频,生成一个词和词频构成的字典。
3、从字典中取出Top size - 2个元素。
4、获取元素的词。
5、执行add方法将词放入vocab_entry,生成词和id,id就是词对应的向量值。
代码如下:
@staticmethod
def from_corpus(corpus, size, min_feq=3):
"""从给定语料中创建VocabEntry"""
vocab_entry = VocabEntry()
# chain函数来自于itertools库,itertools库提供了非常有用的基于迭代对象的函数,而chain函数则是可以串联多个迭代对象来形成一个更大的迭代对象
# *的作用:返回单个迭代器。
# word_freq是个字典,key=词,value=词频
word_freq = Counter(chain(*corpus)) # Counter 是实现的 dict 的一个子类,可以用来方便地计数,统计词频
valid_words = word_freq.most_common(size - 2) # most_common()函数用来实现Top n 功能,在这里选出Top size-2个词
valid_words = [word for word, value in valid_words if value >= min_feq] # 把符合要求的词找出来放到list里面。
print('number of word types: {}, number of word types w/ frequency >= {}: {}'
.format(len(word_freq), min_feq, len(valid_words)))
for word in valid_words: # 将词放进VocabEntry里面。
vocab_entry.add(word)
return vocab_entry
创建完成后将词向量保存到json文件中
vocab = Vocab.build(src_sents, labels, 50000, 3)
print('generated vocabulary, source %d words' % (len(vocab.vocab)))
vocab.save('./vocab.json')
训练
训练使用Train_CNN.py,先看分析main方法的参数。
参数
parse = argparse.ArgumentParser()
parse.add_argument("--train_data_dir", default='./cnews/cnews.train.txt', type=str, required=False)
parse.add_argument("--dev_data_dir", default='./cnews/cnews.val.txt', type=str, required=False)
parse.add_argument("--test_data_dir", default='./cnews/cnews.test.txt', type=str, required=False)
parse.add_argument("--output_file", default='deep_model.log', type=str, required=False)
parse.add_argument("--batch_size", default=8, type=int)
parse.add_argument("--do_train", default=True, action="store_true", help="Whether to run training.")
parse.add_argument("--do_test", default=True, action="store_true", help="Whether to run training.")
parse.add_argument("--learnning_rate", default=5e-4, type=float)
parse.add_argument("--num_epoch", default=50, type=int)
parse.add_argument("--max_vocab_size", default=50000, type=int)
parse.add_argument("--min_freq", default=2, type=int)
parse.add_argument("--embed_size", default=300, type=int)
parse.add_argument("--dropout_rate", default=0.2, type=float)
parse.add_argument("--warmup_steps", default=0, type=int, help="Linear warmup over warmup_steps.")
parse.add_argument("--GRAD_CLIP", default=1, type=float)
parse.add_argument("--vocab_path", default='vocab.json', type=str)
parse.add_argument("--num_filter", default=100, type=int, help="CNN模型一个filter的输出channels")
参数说明:
train_data_dir:训练集路径。
dev_data_dir:验证集路径
test_data_dir:测试集路径
output_file:输出的log路径
batch_size:batchsize的大小。
do_train:是否训练,默认True、
do_test:是否测试,默认True
learnning_rate:学习率
num_epoch:epoch的数量
max_vocab_size:词向量的个数
min_freq:词频,过滤低于这个数值的词
embed_size:Embedding的长度。
dropout_rate:dropout的值。
warmup_steps:设置预热的值。
vocab_path:词向量保存的路径
num_filter:卷积输出的数量。
构建词向量
vocab = build_vocab(args)
label_map = vocab.labels
print(label_map)
build_vocab的方法:
def build_vocab(args):
if not os.path.exists(args.vocab_path):
src_sents, labels = read_corpus(args.train_data_dir)
labels = {label: idx for idx, label in enumerate(labels)}
vocab = Vocab.build(src_sents, labels, args.max_vocab_size, args.min_freq)
vocab.save(args.vocab_path)
else:
vocab = Vocab.load(args.vocab_path)
return vocab
创建模型
创建CNN模型,将模型放到GPU上,调用train方法,训练。
cnn_model = CNN(len(vocab.vocab), args.embed_size, args.num_filter, [2, 3, 4], len(label_map),
dropout=args.dropout_rate)
cnn_model.to(device)
print(cnn_model.parameters)
train(args, cnn_model, train_data, dev_data, vocab, dtype='CNN')
对train方法做了一些注解,如下:
def train(args, model, train_data, dev_data, vocab, dtype='CNN'):
LOG_FILE = args.output_file
#记录训练log
with open(LOG_FILE, "a") as fout:
fout.write('\\n')
fout.write('==========' * 6)
fout.write('start trainning: {}'.format(dtype))
fout.write('\\n')
time_start = time.time()
if not os.path.exists(os.path.join('./runs', dtype)):
os.makedirs(os.path.join('./runs', dtype))
tb_writer = SummaryWriter(os.path.join('./runs', dtype))
# 计算总的迭代次数
t_total = args.num_epoch * (math.ceil(len(train_data) / args.batch_size))
optimizer = AdamW(model.parameters(), lr=args.learnning_rate, eps=1e-8)#设置优化器
scheduler = get_linear_schedule_with_warmup(optimizer=optimizer, num_warmup_steps=args.warmup_steps,
num_training_steps=t_total) #设置预热。
criterion = nn.CrossEntropyLoss()# 设置loss为交叉熵
global_step = 0
total_loss = 0.
logg_loss = 0.
val_acces = []
train_epoch = trange(args.num_epoch, desc='train_epoch')
for epoch in train_epoch:#训练epoch
model.train()
for src_sents, labels in batch_iter(train_data, args.batch_size, shuffle=True):
src_sents = vocab.vocab.to_input_tensor(src_sents, args.device)
global_step += 1
optimizer.zero_grad()
logits = model(src_sents)
y_labels = torch.tensor(labels, device=args.device)
example_losses = criterion(logits, y_labels)
example_losses.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), args.GRAD_CLIP)
optimizer.step()
scheduler.step()
total_loss += example_losses.item()
if global_step % 100 == 0:
loss_scalar = (total_loss - logg_loss) / 100
logg_loss = total_loss
with open(LOG_FILE, "a") as fout:
fout.write("epoch: {}, iter: {}, loss: {},learn_rate: {}\\n".format(epoch, global_step, loss_scalar,
scheduler.get_lr()[0]))
print("epoch: {}, iter: {}, loss: {}, learning_rate: {}".format(epoch, global_step, loss_scalar,
scheduler.get_lr()[0]))
tb_writer.add_scalar("lr", scheduler.get_lr()[0], global_step)
tb_writer.add_scalar("loss", loss_scalar, global_step)
print("Epoch", epoch, "Training loss", total_loss / global_step)
eval_loss, eval_result = evaluate(args, criterion, model, dev_data, vocab) # 评估模型
with open(LOG_FILE, "a") as fout:
fout.write("EVALUATE: epoch: {}, loss: {},eval_result: {}\\n".format(epoch, eval_loss, eval_result))
eval_acc = eval_result['acc']
if len(val_acces) == 0 or eval_acc > max(val_acces):
# 如果比之前的acc要高,就保存模型
print("best model on epoch: {}, eval_acc: {}".format(epoch, eval_acc))
torch.save(model.state_dict(), "classifa-best-{}.th".format(dtype))
val_acces.append(eval_acc)
time_end = time.time()
print("run model of {},taking total {} m".format(dtype, (time_end - time_start) / 60))
with open(LOG_FILE, "a") as fout:
fout.write("run model of {},taking total {} m\\n".format(dtype, (time_end - time_start) / 60))
重点注释了一下batch_iter方法,如下:
def batch_iter(data, batch_size, shuffle=False):
"""
batch数据
:param data: list of tuple
:param batch_size:
:param shuffle:
:return:
"""
batch_num = math.ceil(len(data) / batch_size)# 计算迭代的次数
index_array = list(range(len(data))) #按照data的长度,映射list
if shuffle:#是否打乱顺序
random.shuffle(index_array)
for i in range(batch_num):
indices = index_array[i*batch_size:(i+1)*batch_size]# 选出batchsize个index
examples = [data[idx] for idx in indices]# 通过index找到对应的data
examples = sorted(examples,key=lambda x: len(x[1]),reverse=True)#按照label排序
src_sents = [e[0] for e in examples] #把data中的文章放到src_sents
labels = [label_map[e[1]] for e in examples] #将标题映射label_map对应的value
yield src_sents, labels
下面一个重要的方法是vocab.vocab.to_input_tensor,核心思路:
1、将数据通过 self.words2indices方法转为词对应的数值。
2、找出一个batch中最长的数据,剩下的数据后面补0,形成统一的长度。
3、将第二步得到的结果放入torch.tensor
代码如下:
def to_input_tensor(self