Elasticsearch:Data pipeline: Kafka => Flink => Elasticsearch
Posted 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch:Data pipeline: Kafka => Flink => Elasticsearch相关的知识,希望对你有一定的参考价值。
昨天我写了一篇关于 Flink 和 Elasticsearch 方面的文章 “Elasticsearch:使用 Apache Flink、Elasticsearch 打造实时事件处理及搜索”。在那篇文章中,我详细地描述了如何把 Flink 的数据写入到 Elasticsearch 中。在实际的使用过程中,我们可能经常会使用到 Kafka,并把 Kafka 里的数据经过 Flink 处理后再写入到 Elasticsearch 中。在今天的文章中,我将来详述如何实现。

安装
如果你还没有安装好自己的 Elastic Stack 及 Flink 的话,请参阅我之前的文章 “Elasticsearch:使用 Apache Flink、Elasticsearch 打造实时事件处理及搜索”。按照里面的步骤,我们分别进行安装,并启动 Elasticsearch,Kibana 及 Flink。
接下来,我们需要安装 Kafka。
Linux
我们可以参考文章 “Elastic:使用 Kafka 部署 Elastic Stack” 来安装 Kafka。 简单地说就是:
Kafka 使用 ZooKeeper 来维护配置信息和同步,因此在设置 Kafka 之前,我们需要先安装 ZooKeeper:
sudo apt-get install zookeeperd接下来,让我们下载并解压缩 Kafka:
wget https://apache.mivzakim.net/kafka/2.4.0/kafka_2.13-2.4.0.tgz
tar -xzvf kafka_2.13-2.4.0.tgz
sudo cp -r kafka_2.13-2.4.0 /opt/kafka现在,我们准备运行 Kafka,我们将使用以下脚本进行操作:
sudo /opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties你应该开始在控制台中看到一些 INFO 消息:

我们接下来打开另外一个控制台中,并为 Apache 日志创建一个主题:
/opt/kafka/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic mytopic我们创建了一个叫做 mytopic 的 topic。上面的命令将返回如下的结果:
Created topic apache.我们现在已经完全为开始管道做好了准备。
macOS
MacOS 的安装也非常的直接。我们直接使用如下的命令来进行分别安装 zookeeper 及 Kafka:
brew installl zookeeper
brew install kafka它们的安装目录分别位于如下的位置:
/usr/local/bin/zkServer
/usr/local/opt/kafka/bin/kafka-server-start
我们使用如下的命令来启动 zookeeper:
$ zkServer start
ZooKeeper JMX enabled by default
Using config: /usr/local/etc/zookeeper/zoo.cfg
Starting zookeeper ... STARTED我们使用如下的命令来启动 Kafka:
$ /usr/local/opt/kafka/bin/kafka-server-start /usr/local/etc/kafka/server.properties当然你也可以启动 Kafka 为一个服务,而不是想上面的那样值运行一次:
brew services start kafka接下来,我们使用如下的命令来创建一个叫做 mytopic 的 topic:
kafka-topics --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic mytopic$ kafka-topics --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic mytopic
Created topic mytopic.这样我们就准备好了。
创建演示例子
接下来,我们将使用 Java 来构建一个展示的例子。它使用 API 来访问 Flink。如上所示,我们将使用 Flink 的 enviornment,source,transform 及 sink APIs 来构建我们的应用。为了方便大家学习,我已经把我的项目上传到 github 了。你需要使用如下的命令来进行下载:
git clone https://github.com/liu-xiao-guo/kafka-flink-elasticsearch你可以使用你自己喜欢的 IDE 来创建一个新的项目来开始。
KafkaElasticsearch.java
import java.util.*;
import java.util.logging.Logger;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.RuntimeContext;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.elasticsearch.ElasticsearchSinkFunction;
import org.apache.flink.streaming.connectors.elasticsearch.RequestIndexer;
import org.apache.flink.streaming.connectors.elasticsearch7.ElasticsearchSink;
import org.apache.flink.streaming.util.serialization.SimpleStringSchema;
import org.apache.http.HttpHost;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.Requests;
public class KafkaElasticsearch {
// private static final Logger log = Logger.getLogger(KafkaElasticsearch.class.getSimpleName());
private static final Logger log = Logger.getLogger(KafkaElasticsearch.class.getSimpleName());
public static void main(String[] args) throws Exception {
System.out.println("Starting ....");
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// Configure kafka parameters
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
env.enableCheckpointing(5000);
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers("localhost:9092")
.setTopics("mytopic")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStreamSource<String> kafkaData = env.fromSource(source,
WatermarkStrategy.noWatermarks(), "Kafka Source");
DataStream<String> transSource = kafkaData.map(new MapFunction<String, String>() {
@Override
public String map(String s) {
System.out.println("Received message: " + s);
return s;
}
});
try {
List<HttpHost> hosts = new ArrayList<>();
hosts.add(new HttpHost("localhost", 9200, "http"));
ElasticsearchSink.Builder<String> builder = new ElasticsearchSink.Builder<>(hosts,
new ElasticsearchSinkFunction<String>() {
@Override
public void process(String s, RuntimeContext runtimeContext, RequestIndexer requestIndexer) {
Map<String, String> jsonMap = new HashMap<>();
jsonMap.put("message", s);
IndexRequest indexRequest = Requests.indexRequest();
indexRequest.index("kafka-flink");
// indexRequest.id("1000");
indexRequest.source(jsonMap);
requestIndexer.add(indexRequest);
}
});
// Define a sink
builder.setBulkFlushMaxActions(1);
transSource.addSink(builder.build());
// Execute the transform
env.execute("flink-es");
} catch (Exception e) {
e.printStackTrace();
}
}
}整个代码的设计非常简单。如果你有什么不清楚的,请参阅我之前的文章 “Elasticsearch:使用 Apache Flink、Elasticsearch 打造实时事件处理及搜索” 以及 Apache Kafka Connector。
我们运行上面的应用,并在一个 terminal 中使用 Kafka 安装自带的工具向 Kafka 的 topic “mytopic” 进行写入数据:
kafka-console-producer --broker-list localhost:9092 --topic mytopic
我们在 Kibana 中查看索引 kafka-flink:
GET kafka-flink/_search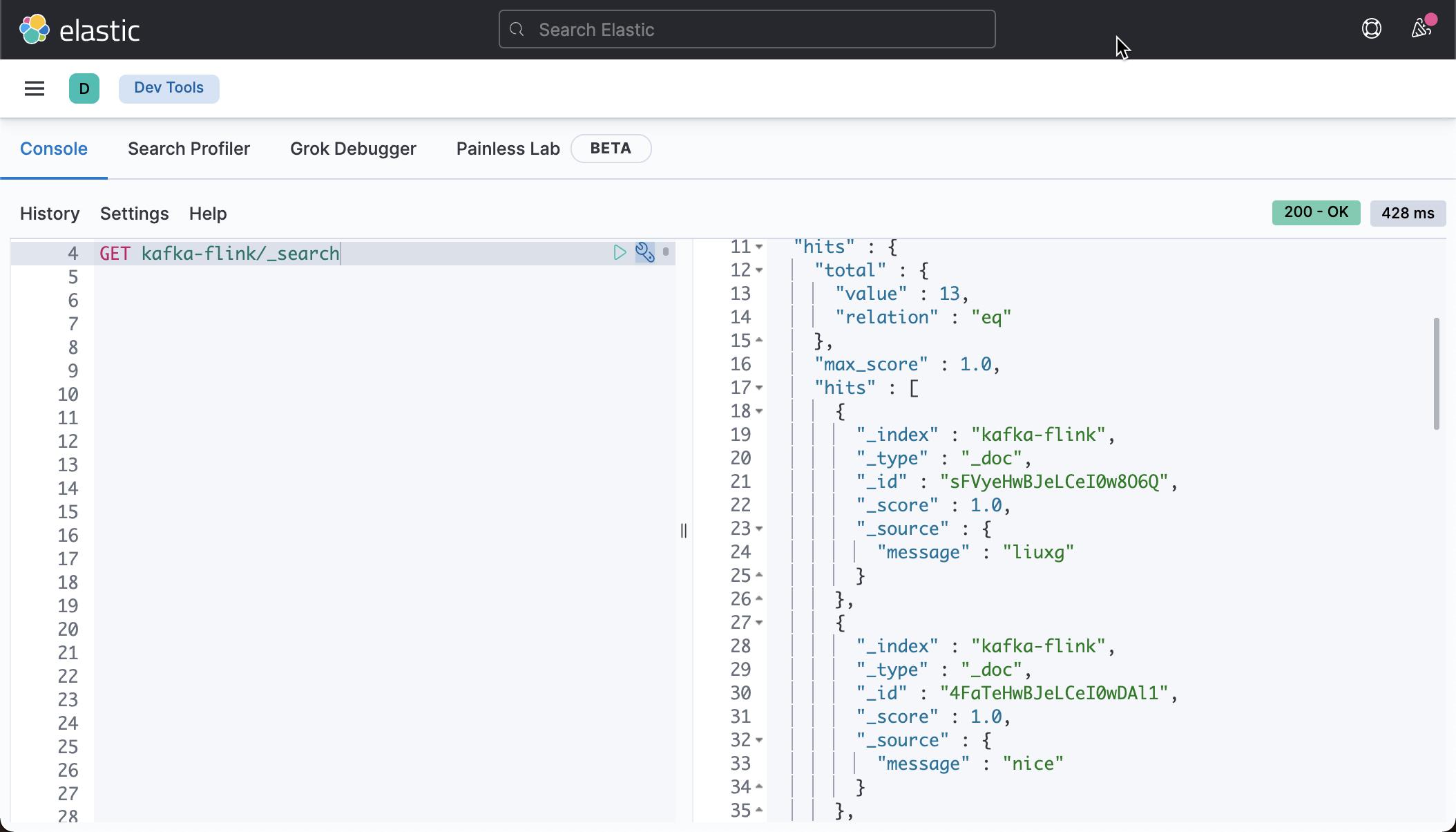
从上面,我们可以看出来我们发送到 mytopic 的数据最终到达 Elasticsearch。
参考:
以上是关于Elasticsearch:Data pipeline: Kafka => Flink => Elasticsearch的主要内容,如果未能解决你的问题,请参考以下文章