如何利用 Elastic 可观测性监测容器化的 Kafka
Posted 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何利用 Elastic 可观测性监测容器化的 Kafka相关的知识,希望对你有一定的参考价值。
Kafka 是分布式事件流处理平台,具有高可用性,既可以在裸机、虚拟化环境或容器化环境中运行,也可以作为托管服务运行。本质上,Kafka 是一种发布/订阅(简称“pub/sub”)系统,通过提供“代理”来分发事件。发布者将事件发布到主题,而使用者订阅主题。当新事件被发送到某个主题时,订阅该主题的使用者会收到新事件通知。如此一来,发布者不必了解所发布事件的使用者,多个客户端也可以收到活动通知。例如,当有新订单下达时,网店可能会发布一个附带订单详情的事件,然后可能会通知订单分拣部门的使用者从货架提取相应货物,并通知装运部门的使用者打印标签,或通知任何其他相关人员采取行动。您可以通过配置使用者分组和分区来控制哪些使用者能够收到新消息。
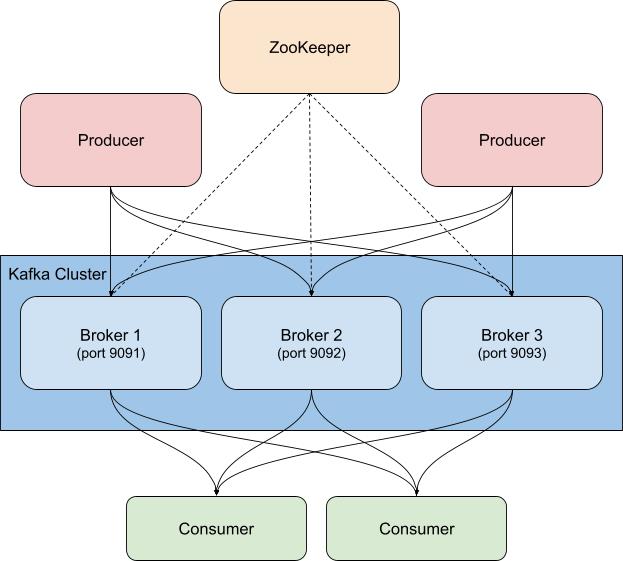
Kafka 通常与 ZooKeeper 一起部署,后者用于存储主题、分区以及副本/冗余信息之类的配置信息。对 Kafka 集群以及相关联 ZooKeeper 实例的监测不可厚此薄彼,因为如果 ZooKeeper 出现问题,Kafka 集群也无法独善其身。
Kafka 和 Elastic Stack 有多种搭配使用方法。您可以通过配置 Metricbeat 或 Filebeat 将数据发送到 Kafka 主题,也可以从 Kafka 到 Logstash 或从 Logstash 到 Kafka 发送数据,还可以使用 Elastic 可观测性监测 Kafka 和 ZooKeeper,从而密切关注集群,这也是本篇博文接下来所要探讨的内容。还记得上文提到的“订单详情”事件吗?借助 Kafka 输入插件,Logstash 也可以订阅这些事件,并将数据引入 Elasticsearch 集群。您可以通过添加业务(或有助于了解环境内部真实状况的任何其他数据)来提高系统的可观测性。
监测 Kafka 时的注意事项
Kafka 拥有多个活动部件,包括服务本身以及使用 Kafka 的客户端;服务通常由多个代理和 ZooKeeper 实例组成,客户端即生产者和使用者。Kafka 提供多种类型的指标,一些指标通过代理本身提供,另一些通过 JMX 提供。代理可提供有关分区和使用者分组的指标。您可以通过分区将消息拆分给多个代理来实现并行处理。使用者从单个主题分区接收消息,并且可以聚集成组,一起使用某个主题中的所有消息。您可以借助这些使用者分组将负载拆分到多个工作线程。
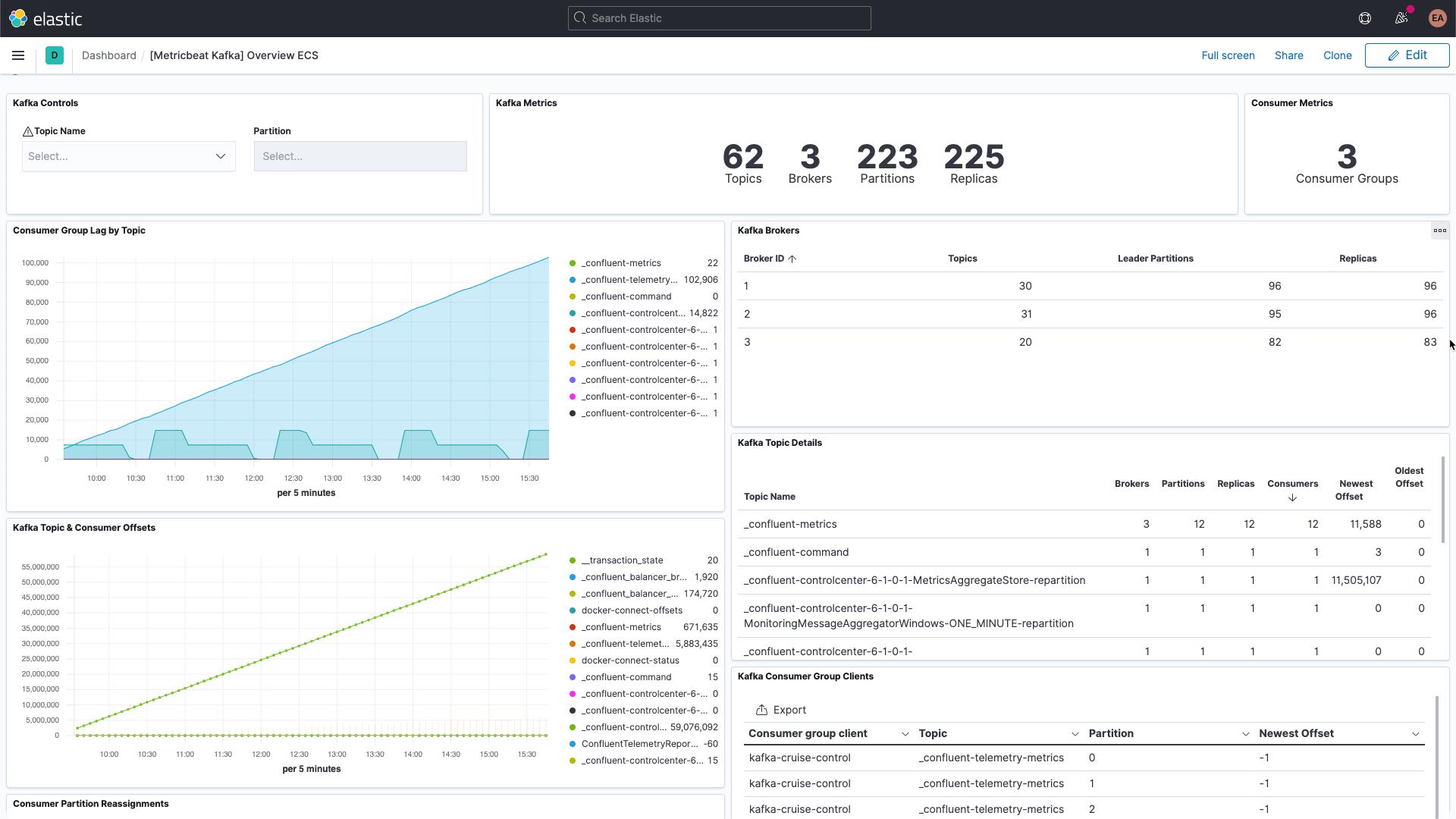
Kafka 每一条消息分别具有一个偏移量。偏移量本质上就是一种表示消息在消息序列中位置的标识符。生产者将消息添加到主题,此时每一条消息都会获得一个新的偏移量。分区中的最新偏移量显示最新 ID。使用者从主题中接收消息,而最新偏移量和使用者收到的偏移量之差就是使用者延迟。使用者总是会略微滞后于生产者。如果使用者延迟不断增长,则需要多加注意,这意味着您可能需要增加使用者数量来处理相应负载。
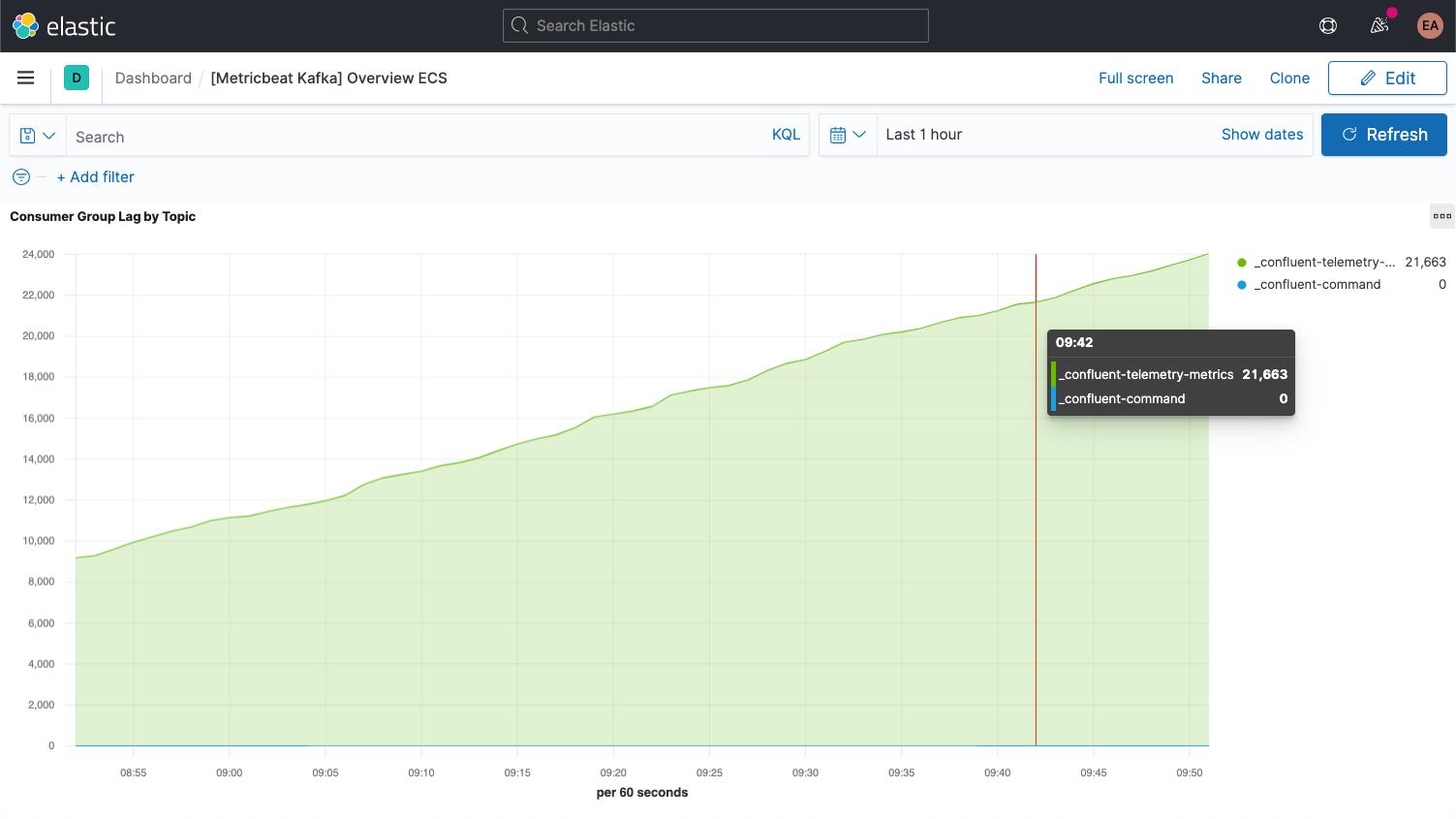
查看有关主题本身的指标时,务必要关注每一个没有使用者的主题,这可能表示某些应该运行的对象未运行。
完成所有设置后,接下来我们将介绍另外一些有关代理的关键指标。
设置 Kafka 和 Zookeeper
在示例中,我们将基于 Confluent Platform 运行一个容器化的 Kafka 集群和单个 ZooKeeper 实例,该集群已扩展至三个 Kafka 代理(cp-server 镜像)。在实践中,您可能还需要使用更加稳健、可用性更高的 ZooKeeper 配置。
我已克隆这些设置,并切换到了 cp-all-in-one 目录:
git clone https://github.com/confluentinc/cp-all-in-one.git cd cp-all-in-one
本篇博文中的剩余事项均将在该 cp-all-in-one 目录中完成。
在设置过程中,我调整了端口,以便于区分端口与代理之间的搭配(每一个代理都向主机公开,因此代理需要使用不同的端口)。例如,broker3 位于端口 9093。此外,为保证一致性,我还将第一个代理的名称更改为 broker1。若要查看插桩前的完整文件,请从官方存储库访问此 GitHub 分叉。
重组端口后,broker1 的配置如下所示:
broker1:
image: confluentinc/cp-server:6.1.0
hostname: broker1
container_name: broker1
depends_on:
- zookeeper
ports:
- "9091:9091"
- "9101:9101"
environment:
KAFKA_BROKER_ID:1
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP:PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS:PLAINTEXT://broker1:29092,PLAINTEXT_HOST://broker1:9091
KAFKA_METRIC_REPORTERS: io.confluent.metrics.reporter.ConfluentMetricsReporter
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR:1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS:0
KAFKA_CONFLUENT_LICENSE_TOPIC_REPLICATION_FACTOR:1
KAFKA_CONFLUENT_BALANCER_TOPIC_REPLICATION_FACTOR:1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR:1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR:1
KAFKA_JMX_PORT:9101
KAFKA_JMX_HOSTNAME: localhost
KAFKA_CONFLUENT_SCHEMA_REGISTRY_URL: http://schema-registry:8081
CONFLUENT_METRICS_REPORTER_BOOTSTRAP_SERVERS: broker1:29092
CONFLUENT_METRICS_REPORTER_TOPIC_REPLICAS:1
CONFLUENT_METRICS_ENABLE: 'true'
CONFLUENT_SUPPORT_CUSTOMER_ID: 'anonymous'可以看到,我还将所有的主机名 broker 更改为了 broker1。当然,docker-compose.yml 中引用 broker 的所有其他配置块也要更改,以便实现反射集群中的三个节点等目的,Confluent 控制中心现在依赖这三个代理:
control-center:
image: confluentinc/cp-enterprise-control-center:6.1.0
hostname: control-center
container_name: control-center
depends_on:
- broker1
- broker2
- broker3
- schema-registry
- connect
- ksqldb-server
(...)收集日志和指标
Kafka 和 ZooKeeper 服务正在容器中运行,前者最初包含三个代理。如果进行缩放,或要让 ZooKeeper 端更加稳健,我可以让此操作动态完成,而不必重新配置和重新启动监测。为实现此目的,除了 Kafka 集群,我们还要在 Docker 容器中运行监测功能,并使用 Elastic Beats 基于提示的自动发现功能。
基于提示的自动发现功能
为进行监测,我们要从 Kafka 代理和 ZooKeeper 实例收集日志和指标。我们将使用 Metricbeat 获取指标,并使用 Filebeat 获取日志,这两者均要在容器中运行。要启动此进程,需要分别下载两者的 Docker 形式的配置文件,即 metricbeat.docker.yml 和 filebeat.docker.yml。我会将此监测数据发送到 Elastic Cloud 中 Elasticsearch Service 的 Elastic 可观测性部署(若要跟进此操作,可以注册免费试用版)。若要自行管理集群,可以免费下载 Elastic Stack,并在本地运行它,在此提供的说明适用于这两种场景。
无论是使用 Elastic Cloud 上的部署,还是运行自管型集群,您都需要指定集群的路径(Kibana URL 和 Elasticsearch URL)和用于登录集群的凭据。Kibana 端点可用于加载默认仪表板和配置信息,而 Elasticsearch 可用于接收 Beats 所发送的数据。Cloud ID 借助 Elastic Cloud 将端点信息封装在一起:
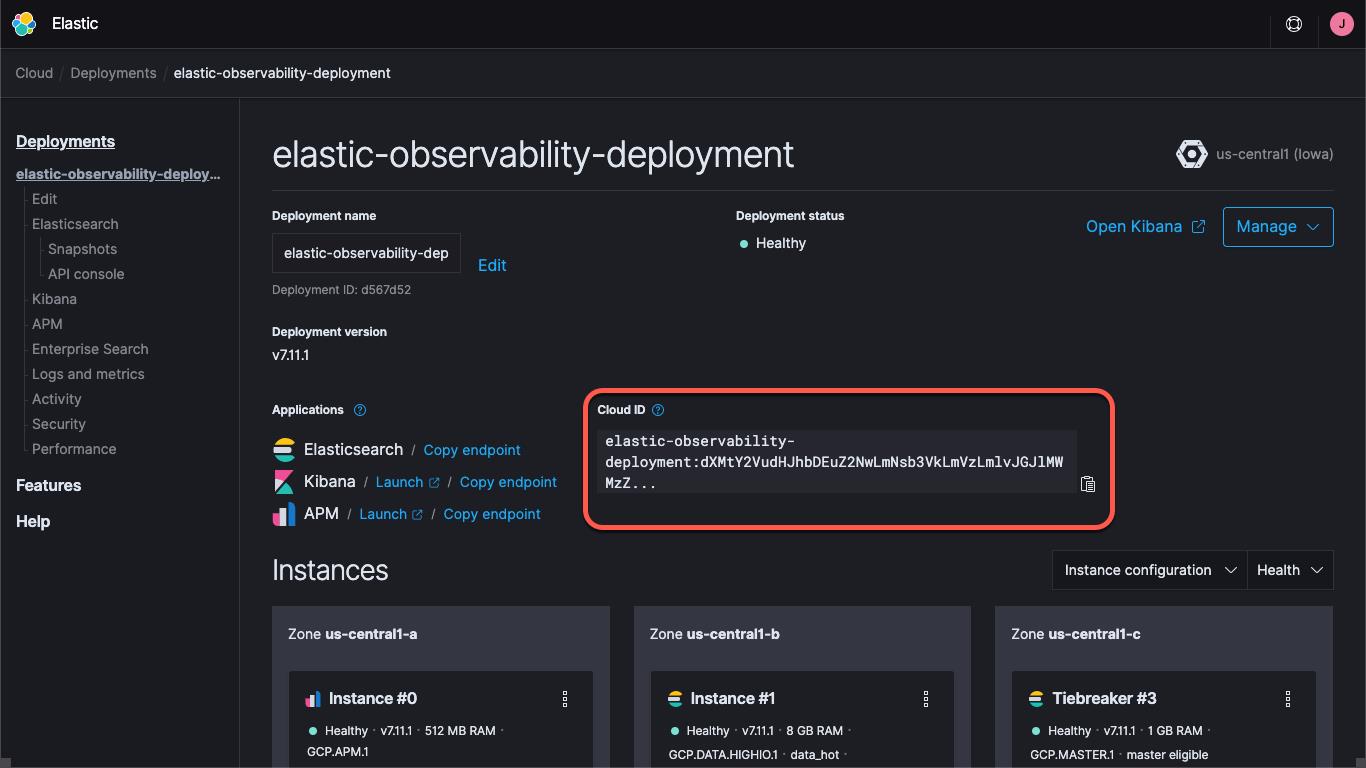
在 Elastic Cloud 上创建部署时,您将获得为 elastic 用户提供的密码。为了方便,我将在本篇博文中使用这些凭据,但最好的做法是创建 API 密钥或创建具有完成任务所需最低权限的用户或角色。
我们继续操作,接下来将加载 Metricbeat 和 Filebeat 的默认仪表板。此操作只需执行一次,与针对每个 Beat 执行的操作相似。要加载 Metricbeat 并行项,请运行:
docker run --rm \\
--name=metricbeat-setup \\
--volume="$(pwd)/metricbeat.docker.yml:/usr/share/metricbeat/metricbeat.yml:ro" \\
docker.elastic.co/beats/metricbeat:7.11.1 \\
-E cloud.id=elastic-observability-deployment:dXMtY2VudHJhbDEuZ2NwLmNsb3VkLmV... \\
-E cloud.auth=elastic:some-long-random-password \\
-e -strict.perms=false \\
setup此命令会创建 Metricbeat 容器(即 metricbeat-setup),装载已下载的 metricbeat.docker.yml 文件,连接到 Kibana 实例(可从 cloud.id 字段获取),并运行 setup 命令,该命令将加载仪表板。如果未使用 Elastic Cloud,则要改为通过 setup.kibana.host 和 output.elasticsearch.hosts 字段提供 Kibana URL 和 Elasticsearch URL,以及各自的凭据字段,命令如下所示:
docker run --rm \\
--name=metricbeat-setup \\
--volume="$(pwd)/metricbeat.docker.yml:/usr/share/metricbeat/metricbeat.yml:ro" \\
docker.elastic.co/beats/metricbeat:7.11.1 \\
-E setup.kibana.host=localhost:5601 \\
-E setup.kibana.username=elastic \\
-E setup.kibana.password=your-password \\
-E output.elasticsearch.hosts=localhost:9200 \\
-E output.elasticsearch.username=elastic \\
-E output.elasticsearch.password=your-password \\
-e -strict.perms=false \\
setup-e -strict.perms=false 有助于缓解不可避免的 Docker 文件所有权/权限问题。
同样,要设置日志并行项,请运行有关 Filebeat 的相似命令:
docker run --rm \\
--name=filebeat-setup \\
--volume="$(pwd)/filebeat.docker.yml:/usr/share/filebeat/filebeat.yml:ro" \\
docker.elastic.co/beats/filebeat:7.11.1 \\
-E cloud.id=elastic-observability-deployment:dXMtY2VudHJhbDEuZ2NwLmNsb3VkLmV... \\
-E cloud.auth=elastic:some-long-random-password \\
-e -strict.perms=false \\
setup默认情况下,这些配置文件已设置,以用于监测一般的容器,并收集容器日志和指标。此设置在某种程度上有所帮助,但我们还需要确保它们还会捕获特定于服务的日志和指标。如前文所述,为确保这一点,我们要配置 Metricbeat 和 Filebeat 容器,以使用自动发现功能。完成此操作的方法有许多种。我们可以将 Beats 配置设置为查找特定镜像或名称,但这需要提前了解许多内容。因此我们将改为使用基于提示的自动发现功能,让容器本身指示 Beats 如何监测它们。
使用基于提示的自动发现功能时,要为 Docker 容器添加标签。当其他容器启动时,metricbeat 和 filebeat 容器(尚未启动)会收到通知,以便于它们启动监测。我们要设置代理容器,以便其接受 Kafka Metricbeat 和 Filebeat 模块的监测,此外还需要让 Metricbeat 使用 ZooKeeper 模块来获取指标。Filebeat 会收集 ZooKeeper 日志,但不会执行任何特殊分析。
ZooKeeper 配置过程比 Kafka 更简单,因此我们将首先配置它。ZooKeeper 的 docker-compose.yml 中的初始配置如下所示:
zookeeper:
image: confluentinc/cp-zookeeper:6.1.0
hostname: zookeeper
container_name: zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT:2181
ZOOKEEPER_TICK_TIME:2000我们要在此 YAML 中添加 labels 块,用于指定模块、连接信息和指标集,如下所示:
labels:
- co.elastic.metrics/module=zookeeper
- co.elastic.metrics/hosts=zookeeper:2181
- co.elastic.metrics/metricsets=mntr,server此命令会指示 metricbeat 容器使用 zookeeper 模块监测相应容器,并告诉此容器可通过主机/端口 zookeeper:2181(即已配置用于侦听的 ZooKeeper 端口)访问相应容器。此命令还会指示该容器使用 ZooKeeper 模块中的 mntr 和 server 指标集。需要补充说明的是,较新的 ZooKeeper 版本禁用某些“四个字母单词”命令,因此我们还需要通过 KAFKA_OPTS 在部署的批准列表中添加 srvr 和 mntr 命令。完成此操作后,compose 文件中的 ZooKeeper 配置如下所示:
zookeeper:
image: confluentinc/cp-zookeeper:6.1.0
hostname: zookeeper
container_name: zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT:2181
ZOOKEEPER_TICK_TIME:2000
KAFKA_OPTS: "-Dzookeeper.4lw.commands.whitelist=srvr,mntr"
labels:
- co.elastic.metrics/module=zookeeper
- co.elastic.metrics/hosts=zookeeper:2181
- co.elastic.metrics/metricsets=mntr,server从代理处捕获日志非常简单;只需为日志记录模块 co.elastic.logs/module=kafka 的每一个代理添加标签。获取代理指标会略微复杂一些。Metricbeat Kafka 模块中有五个不同的指标集:
- 使用者分组指标
- 分区指标
- 代理指标
- 使用者指标
- 生产者指标
前两个指标集源自代理本身,而后三个是通过 JMX 获取。最后两个指标集(consumer 和 producer)分别只适用于基于 Java 的使用者和生产者(Kafka 集群的客户端),因此我们不在此予以介绍(但它们遵循的模式与我们将要介绍的内容相同)。由于前两个指标集的配置方式相同,因此我们先介绍它们。broker1 的 compose 文件中的初始 Kafka 配置如下所示:
broker1:
image: confluentinc/cp-server:6.1.0
hostname: broker1
container_name: broker1
depends_on:
- zookeeper
ports:
- "9091:9091"
- "9101:9101"
environment:
KAFKA_BROKER_ID:1
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP:PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS:PLAINTEXT://broker1:29091,PLAINTEXT_HOST://broker1:9091
KAFKA_METRIC_REPORTERS: io.confluent.metrics.reporter.ConfluentMetricsReporter
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR:1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS:0
KAFKA_CONFLUENT_LICENSE_TOPIC_REPLICATION_FACTOR:1
KAFKA_CONFLUENT_BALANCER_TOPIC_REPLICATION_FACTOR:1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR:1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR:1
KAFKA_JMX_PORT:9101
KAFKA_JMX_HOSTNAME: broker1
KAFKA_CONFLUENT_SCHEMA_REGISTRY_URL: http://schema-registry:8081
CONFLUENT_METRICS_REPORTER_BOOTSTRAP_SERVERS: broker1:29091
CONFLUENT_METRICS_REPORTER_TOPIC_REPLICAS:1
CONFLUENT_METRICS_ENABLE: 'true'
CONFLUENT_SUPPORT_CUSTOMER_ID: 'anonymous'与 ZooKeeper 配置相似,我们需要添加标签来告诉 Metricbeat 如何收集 Kafka 指标:
labels:
- co.elastic.logs/module=kafka
- co.elastic.metrics/module=kafka
- co.elastic.metrics/metricsets=partition,consumergroup
- co.elastic.metrics/hosts='$${data.container.name}:9091'这样就会设置 Metricbeat 和 Filebeat kafka 模块,以用于收集 Kafka 日志,并从端口 9091 上的容器 broker1 收集 partition 指标和 consumergroup 指标。请注意,我使用了变量 data.container.name(利用两个美元符号进行转义),而未使用主机名,您可以根据需要使用任意模式。需要对每个代理重复此步骤,同时针对各个代理调整端口 9091(这就是我最初调整端口的原因,对于 broker2 和 broker3,我们将分别使用 9092 和 9093)。
我们可以通过运行 docker-compose up --detach 启动 Confluent 集群,现在还可以启动 Metricbeat 和 Filebeat,它们将开始收集 Kafka 日志和指标。
启动 cp-all-in-one Kafka 群集后,它会在自己的虚拟网络 cp-all-in-one_default 中创建并运行。由于我们在标签中使用了服务/主机名,因此 Metricbeat 需要在同一网络中运行,以便它可以解析这些名称并正确完成连接。为启动 Metricbeat,运行命令中要包括网络名:
docker run -d \\
--name=metricbeat \\
--user=root \\
--network cp-all-in-one_default \\
--volume="$(pwd)/metricbeat.docker.yml:/usr/share/metricbeat/metricbeat.yml:ro" \\
--volume="/var/run/docker.sock:/var/run/docker.sock:ro" \\
docker.elastic.co/beats/metricbeat:7.11.1 \\
-E cloud.id=elastic-observability-deployment:dXMtY2VudHJhbDEuZ2NwLmNsb3VkLmV... \\
-E cloud.auth=elastic:some-long-random-password \\
-e -strict.perms=falseFilebeat 的运行命令相似,但无需此网络,因为它不连接到其他容器,而是直接通过 Docker 主机运行:
docker run -d \\
--name=filebeat \\
--user=root \\
--volume="$(pwd)/filebeat.docker.yml:/usr/share/filebeat/filebeat.yml:ro" \\
--volume="/mnt/data/docker/containers:/var/lib/docker/containers:ro" \\
--volume="/var/run/docker.sock:/var/run/docker.sock:ro" \\
docker.elastic.co/beats/filebeat:7.11.1 \\
-E cloud.id=elastic-observability-deployment:dXMtY2VudHJhbDEuZ2NwLmNsb3VkLmV... \\
-E cloud.auth=elastic:some-long-random-password \\
-e -strict.perms=false在每个场景下,我们都要加载配置 YAML 文件,将主机中的 docker.sock 文件映射到容器,并包含连接信息(如果运行的是自管型群集,则使用加载并行项时所用的凭据)。请注意,如果是在 Mac 上运行 Docker Desktop,则无权访问日志,因为日志存储在虚拟机内。
Kafka 和 ZooKeeper 性能和历史记录可视化
现在我们正在捕获来自 Kafka 代理的特定于服务的日志,以及来自 Kafka 和 ZooKeeper 的日志和指标。若在 Kibana 中导航到仪表板并进行筛选,您应该会看到有关 Kafka 的仪表板:
其中包括 Kafka 日志仪表板:
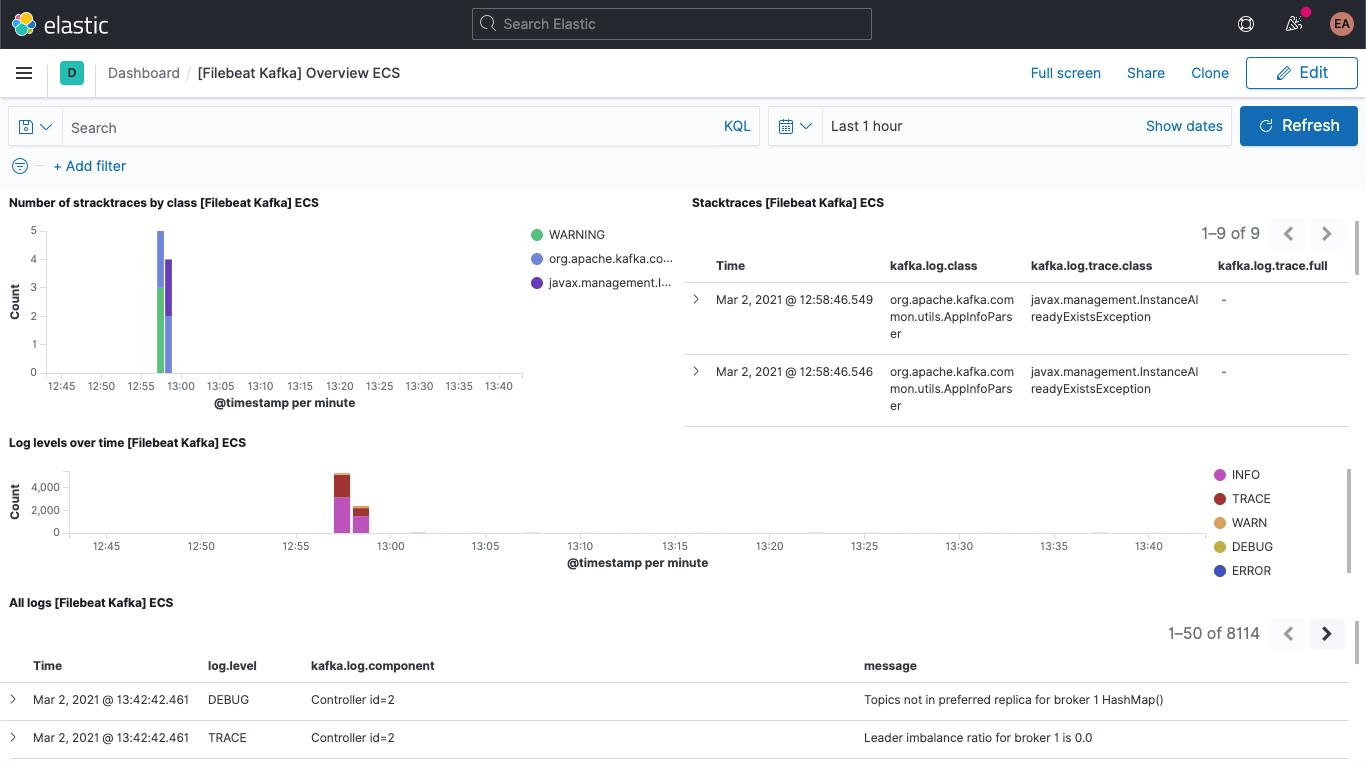
以及 Kafka 指标仪表板:
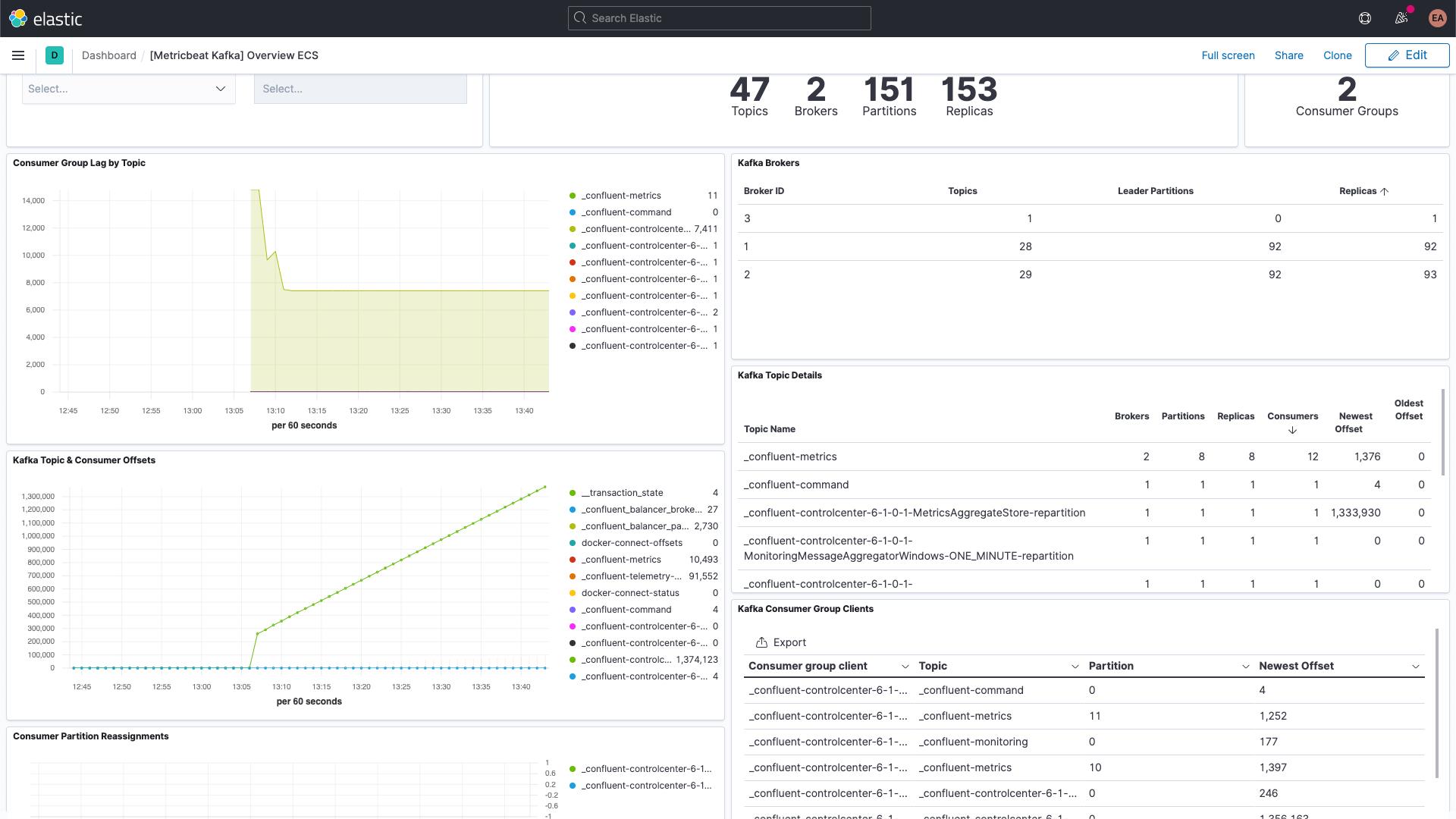
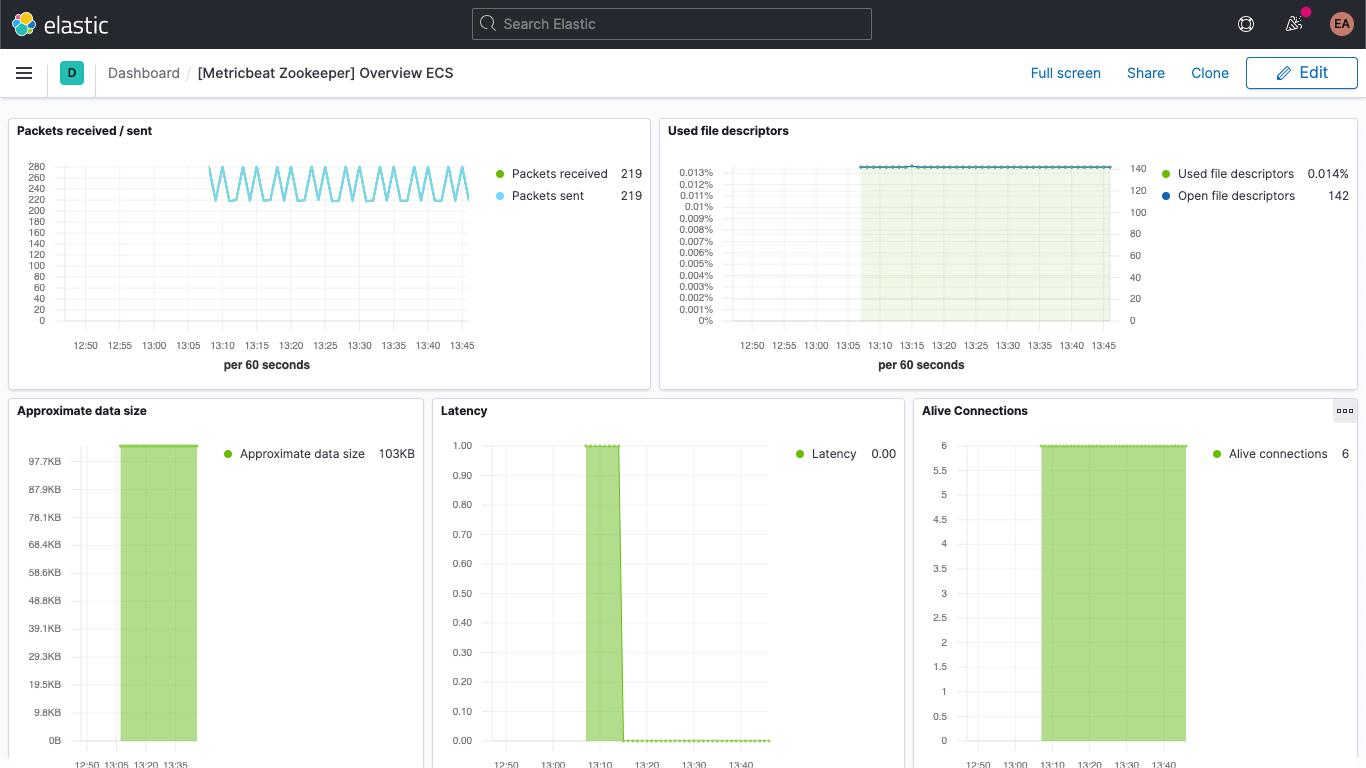
此外还有有关 ZooKeeper 指标的仪表板。
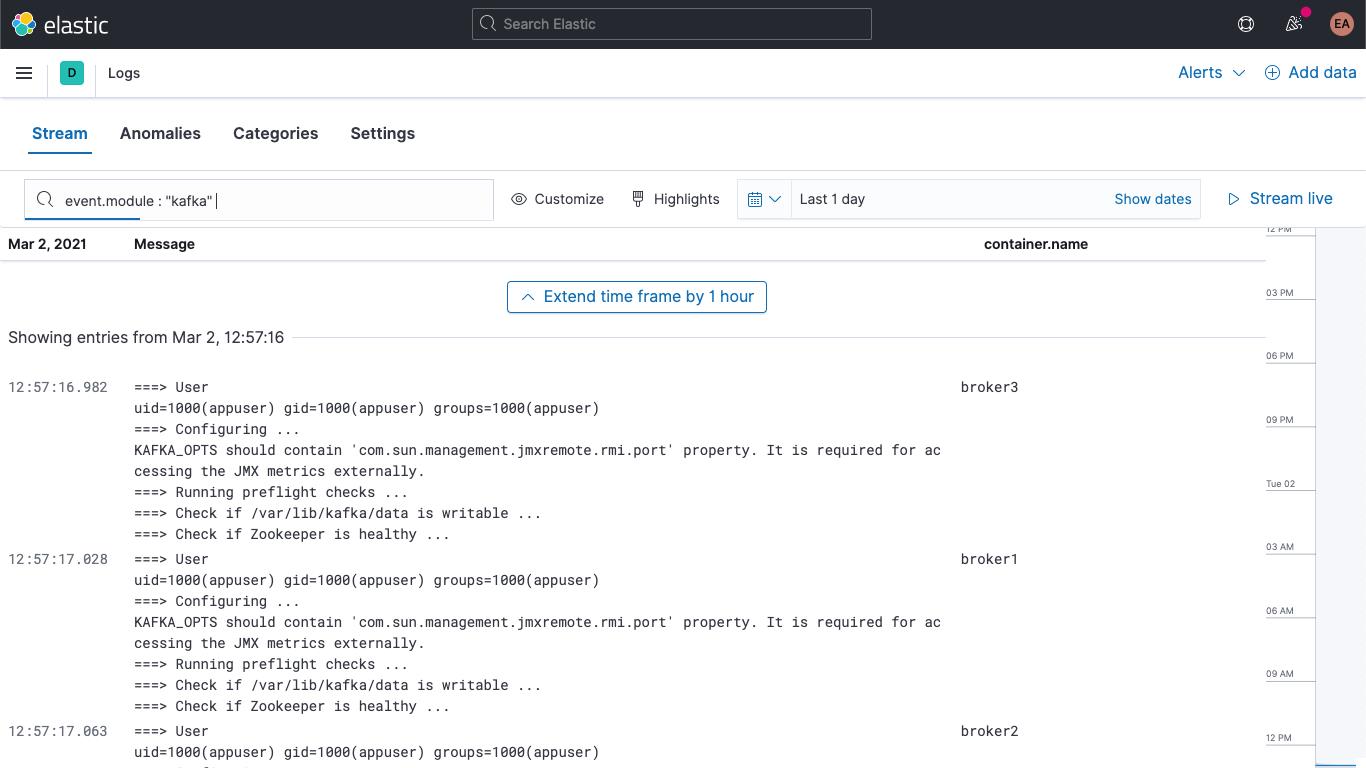
除此之外,您也可以在 Kibana 的“Logs”(日志)应用中找到 Kafka 和 ZooKeeper 日志,并可以在其中筛选、搜索、拆分日志:
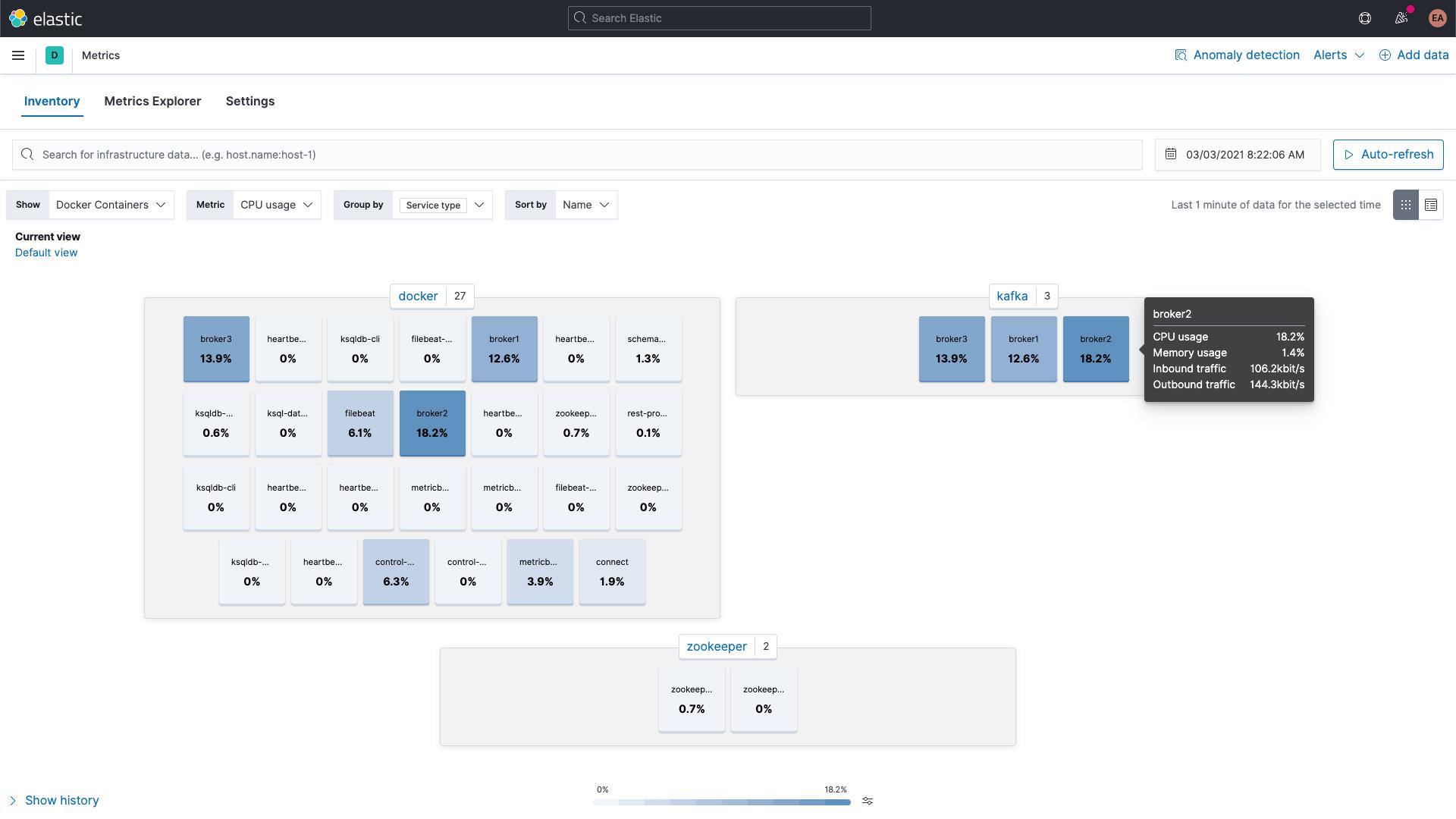
您还可以通过 Kibana 中的“Metrics”(指标)应用浏览 Kafka 和 ZooKeeper 容器的指标,按服务类型分组显示如下:
代理指标
现在让我们回到上一步,从 kafka 模块中的 broker 指标集收集指标。我已在前文中提到过,这些指标是通过 JMX 检索。代理、生产者和使用者指标集隐秘地利用 JMX 到 HTTP 桥接器 Jolokia。broker 指标集也是 kafka 模块的组成部分,但由于它使用的是 JMX,因此所用端口必须与 consumergroup 和 partition 指标集不同;也就是说,我们需要在代理的 labels 中添加新的块,这与多组提示的注释配置相似。
我们还需要 Jolokia 的 jar 文件,我们将通过卷将其添加到代理容器中,并完成设置。根据下载页,Jolokia JVM 代理的当前版本为 1.6.2,因此我们将安装此版本(-OL 会指示 cURL 将文件另存为远程名称,并指示其完成重定向):
curl -OL https://search.maven.org/remotecontent?filepath=org/jolokia/jolokia-jvm/1.6.2/jolokia-jvm-1.6.2-agent.jar我们在每个代理的配置中添加了一节内容,以便将 JAR 文件附加到容器:
volumes:
- ./jolokia-jvm-1.6.2-agent.jar:/home/appuser/jolokia.jar同时指定 KAFKA_JVM_OPTS,以将 JAR 作为 Java 代理附加(请注意,一个端口代表一个代理,因此端口 8771 到 8773 分别表示 broker1、broker2 和 broker3):
KAFKA_JMX_OPTS: '-javaagent:/home/appuser/jolokia.jar=port=8771,host=broker1 -Dcom.sun.management.jmxremote=true -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false'由于我没有对此使用任何类型的身份验证,因而必须为此启动添加一些标记。请注意,KAFKA_JMX_OPTS 中的 jolokia.jar 文件路径要与卷路径相匹配。
我们需要再做一些微调。由于我们在使用 Jolokia,因此无需在 ports 小节中公开 KAFKA_JMX_PORT。要公开的是 Jolokia 所侦听的端口 8771。我们还要从配置中删除 KAFKA_JMX_* 值。
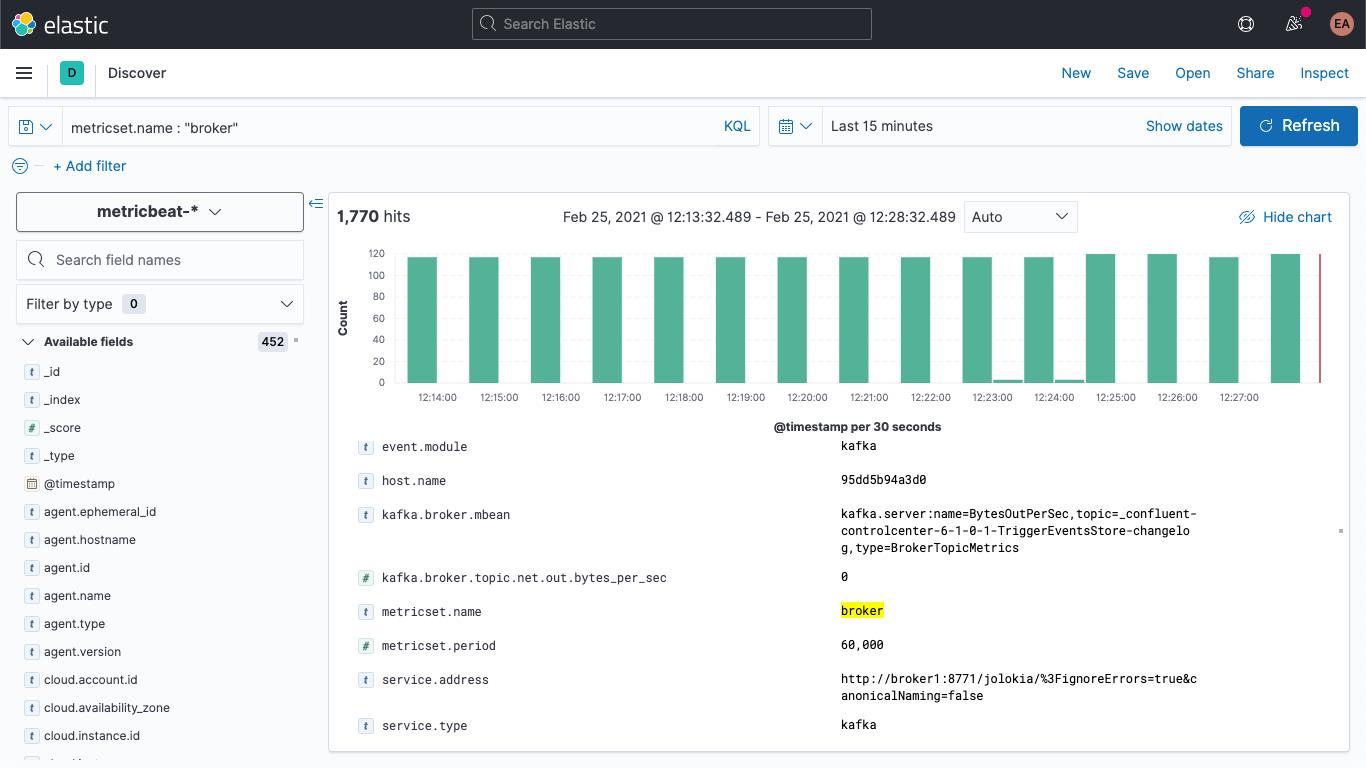
如果重启 Kafka 集群 (docker-compose up --detach),我们将看到代理指标开始出现在 Elasticsearch 部署中。若跳到“Discover”(发现)选项卡,选择 metricbeat-* 索引模式并搜索 metricset.name : "broker",此刻会发现,我确确实实拥有数据:
代理指标的结构类似于下方结构:
kafka
└─ broker
├── address
├── id
├── log
│ └── flush_rate
├── mbean
├── messages_in
├── net
│ ├── in
│ │ └── bytes_per_sec
│ ├── out
│ │ └── bytes_per_sec
│ └── rejected
│ └── bytes_per_sec
├── replication
│ ├── leader_elections
│ └── unclean_leader_elections
└── request
├── channel
│ ├── fetch
│ │ ├── failedRead More
基本显示为名称/值对,如 kafka.broker.mbean 字段所示。请看示例指标中的 kafka.broker.mbean 字段:
kafka.server:name=BytesOutPerSec,topic=_confluent-controlcenter-6-1-0-1-TriggerEventsStore-changelog,type=BrokerTopicMetrics它包含指标名称 (BytesOutPerSec)、所引用的 Kafka 主题 (_confluent-controlcenter-6-1-0-1-TriggerEventsStore-changelog),以及指标类型 (BrokerTopicMetrics)。所设置的字段随指标类型和名称而异。在此示例中,仅填充了 kafka.broker.topic.net.out.bytes_per_sec(为 0)。若以某种柱状图形式查看此数据,可以看到数据非常稀疏:
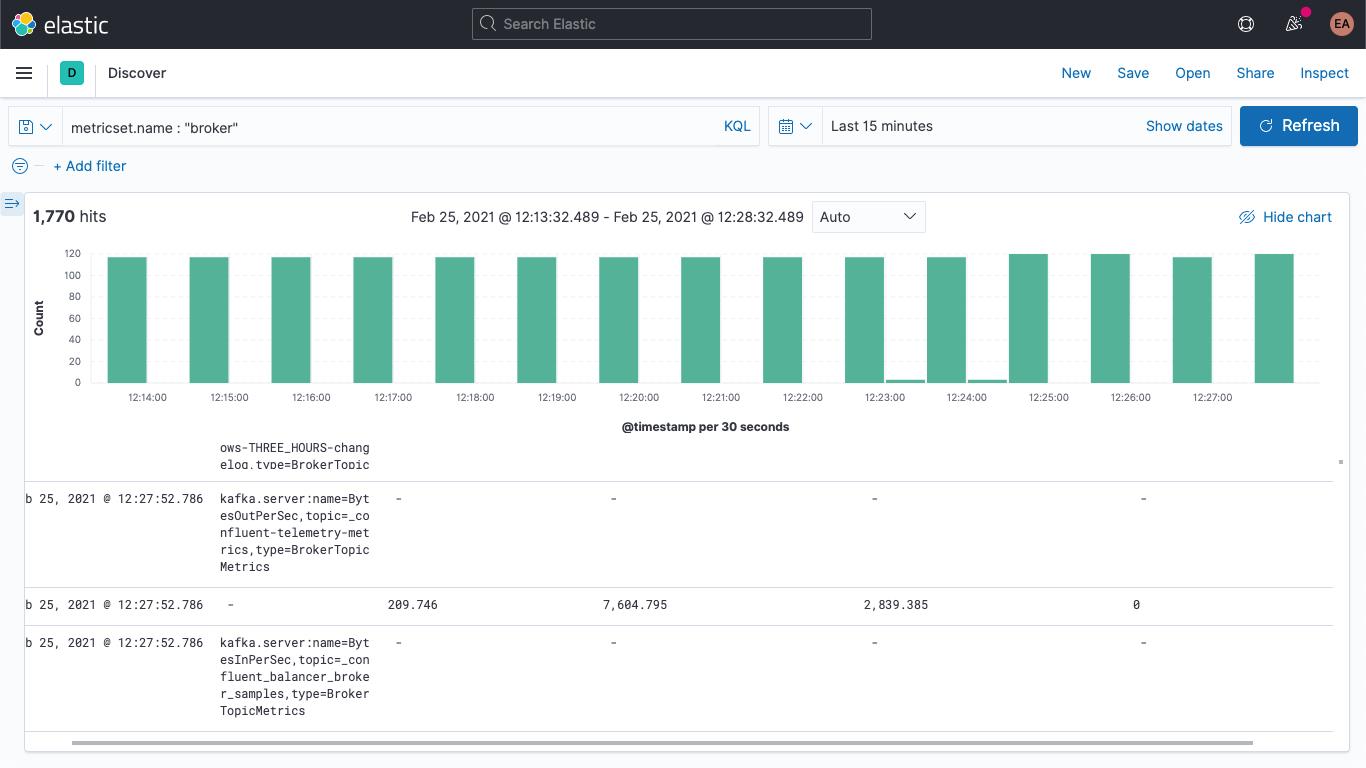
如果我们添加一个采集管道,将 mbean 字段分解为多个独立的字段,则可以将数据略微折叠,同时也能更轻松地实现数据可视化。我们会将此字段分解为三个字段:
- KAFKA_BROKER_METRIC(值为上面示例中的 beBytesOutPerSec)
- KAFKA_BROKER_TOPIC(值为上面示例中的 be_confluent-controlcenter-6-1-0-1-TriggerEventsStore-changelog)
- KAFKA_BROKER_TYPE(值为上面示例中的 beBrokerTopicMetrics)
在 Kibana 中导航到 DevTools:
到达该位置后,粘贴以下内容,以定义采集管道 kafka-broker-fields
PUT _ingest/pipeline/kafka-broker-fields
{
"processors": [
{
"grok": {
"if": "ctx.kafka?.broker?.mbean != null",
"field": "kafka.broker.mbean",
"patterns": ["kafka.server:name=%{GREEDYDATA:kafka_broker_metric},topic=%{GREEDYDATA:kafka_broker_topic},type=%{GREEDYDATA:kafka_broker_type}"
]
}
}
]
}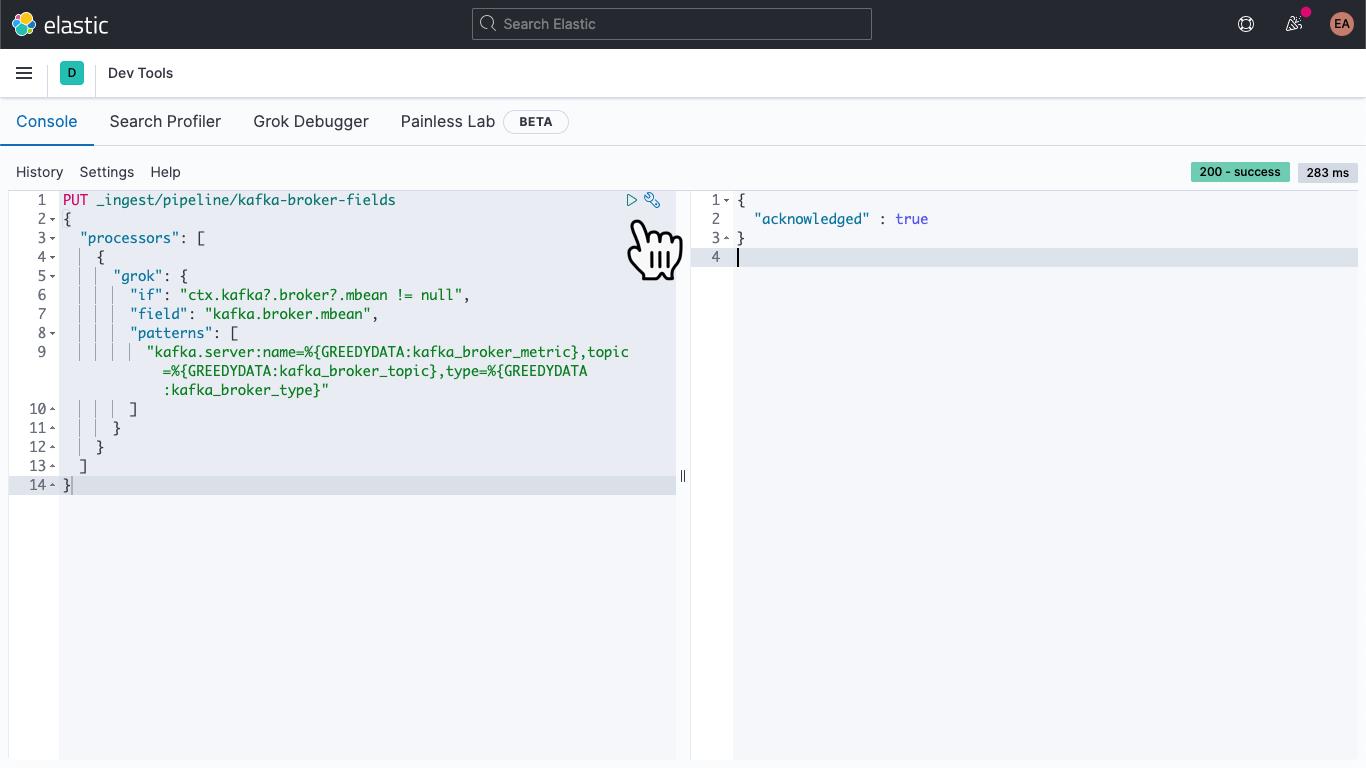
然后点击“Play”(运行)图标。最后应收到“acknowledged”(确认),如上所示。
采集管道已准备就绪,但它尚未发挥任何作用。旧数据仍然稀疏且难以理解,新数据仍会如此。我们先解决后面的问题。
在常用的文本编辑器中打开 metricbeat.docker.yml 文件,然后在 output.elasticsearch 块中添加一行(如果未使用其中的主机、用户名和密码配置,则可以删除它)并指定管道,如下所示:
output.elasticsearch:
pipeline: kafka-broker-fields此代码会告诉 Elasticsearch,传入的每个文档均应通过此管道传递,以查看 mbean 字段。重启 Metricbeat:
docker rm --force metricbeat
docker run -d \\
--name=metricbeat \\
--user=root \\
--network cp-all-in-one_default \\
--volume="$(pwd)/metricbeat.docker.yml:/usr/share/metricbeat/metricbeat.yml:ro" \\
--volume="/var/run/docker.sock:/var/run/docker.sock:ro" \\
docker.elastic.co/beats/metricbeat:7.11.1 \\
-E cloud.id=elastic-observability-deployment:dXMtY2VudHJhbDEuZ2NwLmNsb3VkLmV... \\
-E cloud.auth=elastic:some-long-random-password \\
-e -strict.perms=false可以从“Discover”(发现)中验证新文档具有新字段:
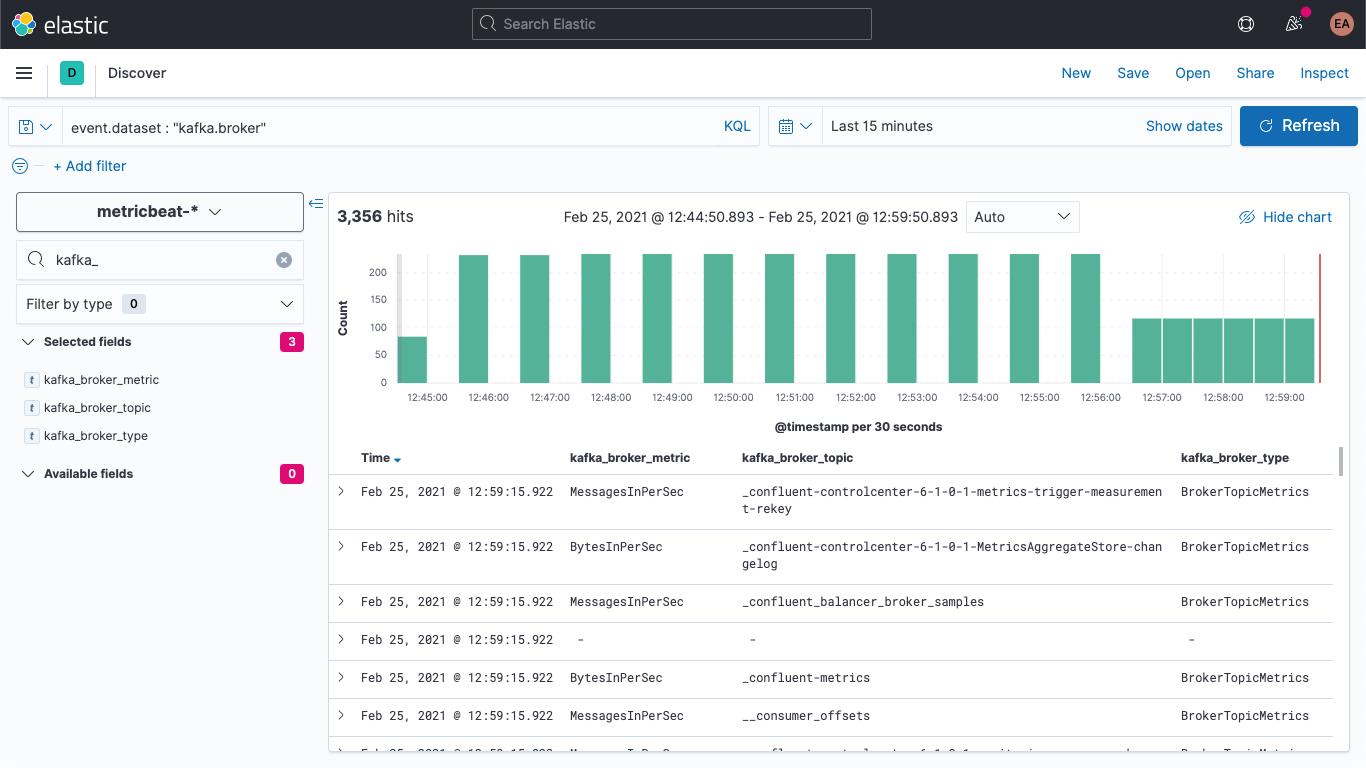
我们还可以更新旧文档,以便让它们也填充这些字段。返回 DevTools,运行以下命令:
POST metricbeat-*/_update_by_query?pipeline=kafka-broker-fields系统可能会发出警告,提示您此命令已超时,但实际它正在后台运行,并会以异步方式完成运行。
代理指标可视化
跳到“Metrics”(指标)应用,选择“Metrics Explorer”(指标浏览器)选项卡,试用下新字段。粘贴 kafka.broker.topic.net.in.bytes_per_sec 和 kafka.broker.topic.net.out.bytes_per_sec,您将看到系统将它们绘制在了一张图中:
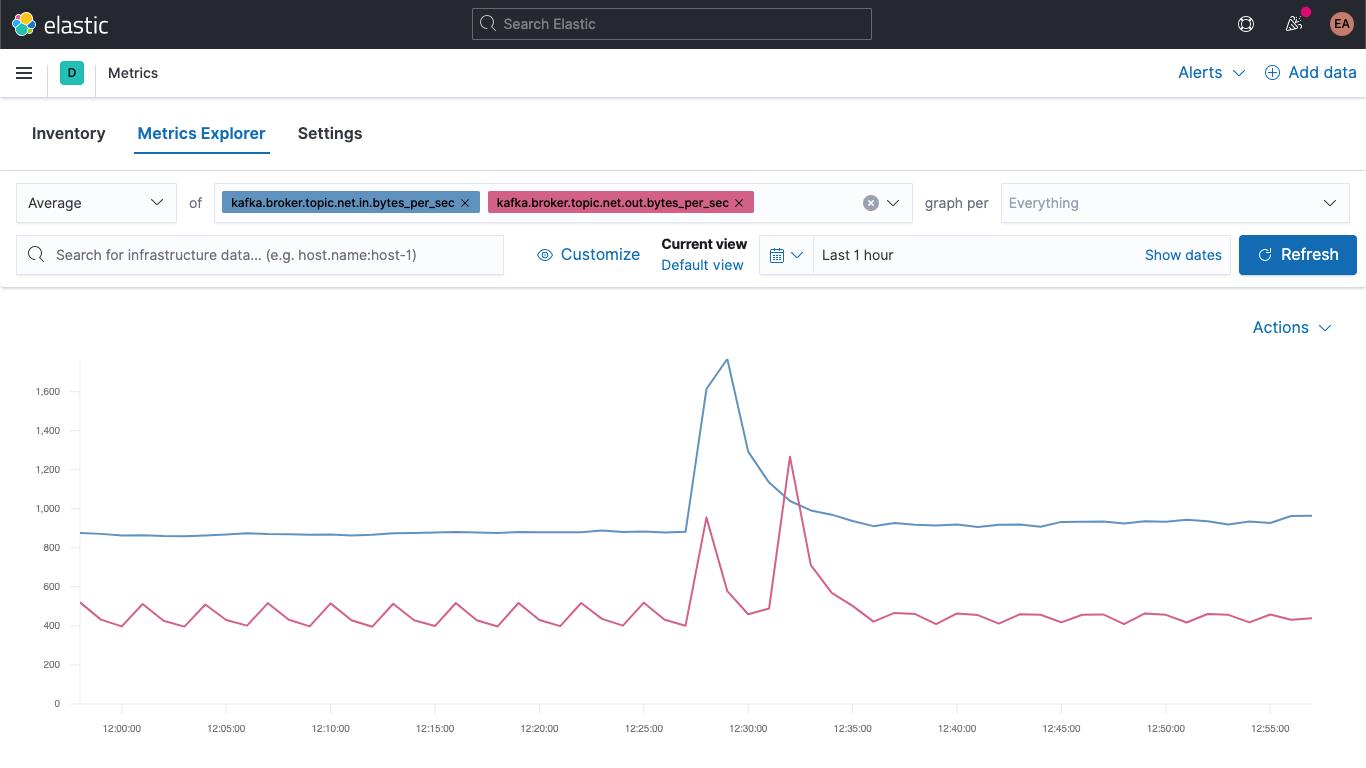
现在使用一个新字段,打开“graph per”(图表主题)下拉列表,选择 kafka_broker_topic:
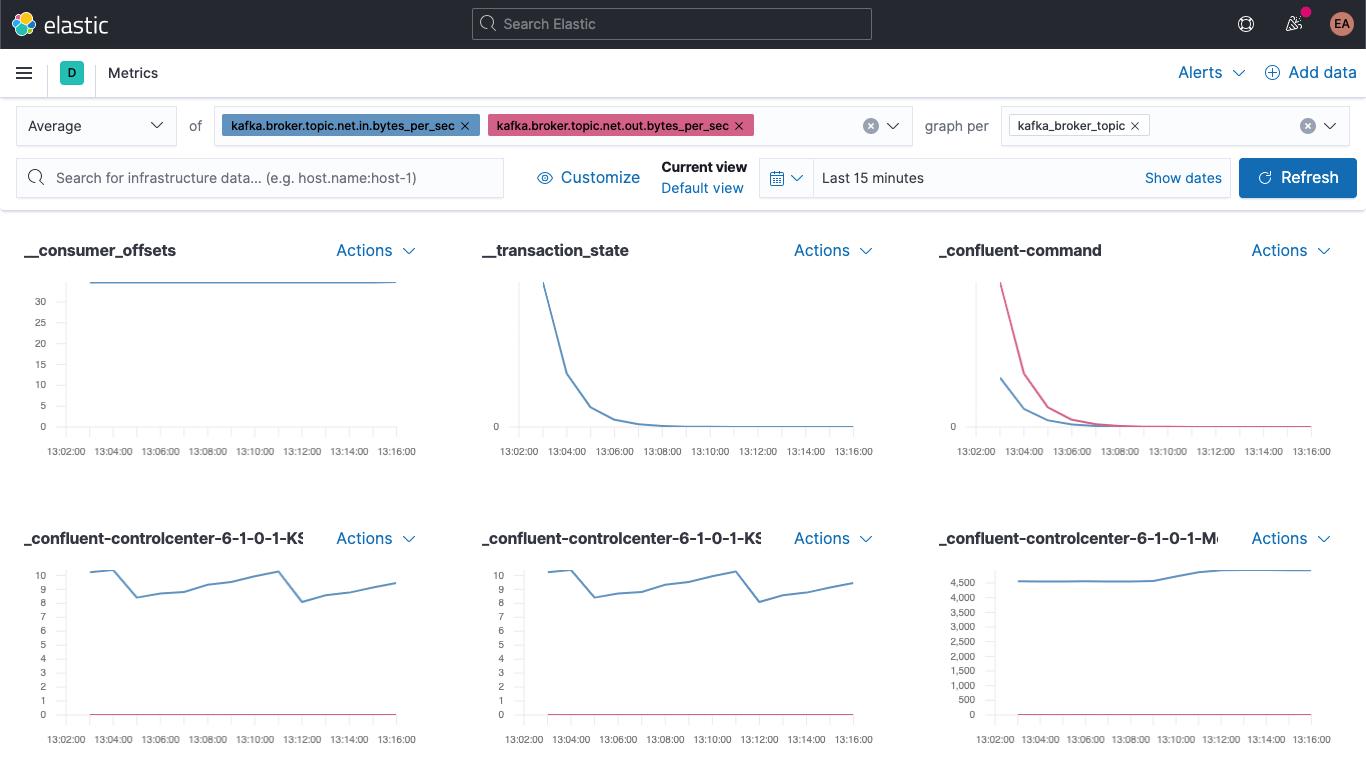
并非所有项都会具有非零值(当前集群中并没有许多正在执行的操作),但现在可以更加轻松地按主题绘制代理指标的图表,并将代理指标分解。您可以将其中的任意图表导出为可视化形式并将其加载到 Kafka 指标仪表板,也可以利用 Kibana 提供的各种图表创建自己的可视化形式。若希望通过拖放体验生成可视化形式,可尝试使用 Lens。
您可以从生成块和提取块中的故障着手,开始代理指标可视化:
kafka
└─ broker
└── request
└── channel
├── fetch
│ ├── failed
│ └── failed_per_second
├── produce
│ ├── failed
│ └── failed_per_second
└── queue
└── size
这些故障严重与否完全取决于用例。如果这些故障出现在生态系统中,并且此生态系统正在执行间歇性更新,例如更新股价或读取温度,而且我们知道很快会有其他更新,此时有几个故障可能无关紧要;但是,如果是订单系统丢弃了几条信息,后果则可能是灾难性的,因为这意味着有人将无法收到货物。
总结
现在我们可以利用 Elastic 可观测性监测 Kafka 代理和 ZooKeeper。我们还了解了如何利用提示实现自动监测新的容器化服务实例,并学习了如何利用采集管道让数据更易于可视化。您可以立即通过 Elastic Cloud 上的 Elasticsearch Service 免费试用版体验,也可以下载并在本地运行 Elastic Stack。
如果您运行的不是容器化的 Kafka 集群,而是将它作为托管服务运行,或是在裸机上运行它,请持续关注后续更新。我们将在近期发布几篇相关博文,来补充更新本篇博文:
- 如何使用 Metricbeat 和 Filebeat 监测独立的 Kafka 集群
- 如何使用 Elastic 代理监测独立的 Kafka 集群
以上是关于如何利用 Elastic 可观测性监测容器化的 Kafka的主要内容,如果未能解决你的问题,请参考以下文章
使用 Elastic 8.5 版构建强大的搜索体验,缩短实现可观测性的时间,并简化安全工作流
使用 Elastic 8.5 版构建强大的搜索体验,缩短实现可观测性的时间,并简化安全工作流