六万字 HTTP 必备干货学习,程序员不懂网络怎么行,一篇HTTP入门 不收藏都可惜!
Posted 呆呆敲代码的小Y
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了六万字 HTTP 必备干货学习,程序员不懂网络怎么行,一篇HTTP入门 不收藏都可惜!相关的知识,希望对你有一定的参考价值。
目录

📢前言
作为一名程序员,可能多数人都偏向于后端敲代码,但是关于Web的知识可千万不能忘呀!
还有对网络协议感兴趣的小伙伴,这篇HTTP基础知识入门对你也很有帮助,可以了解HTTP的一整套流程
所以本篇博客就来重拾HTTP的基础知识,最不济看完也要入门吧!!!
文章可能会理论偏多,所以看不完的记得收藏收藏收藏!要不然以后就找不到了哦~
本文会从HTTP的基本概述、演变历史、缓存、Cookie、跨源资源共享、消息、会话和连接管理等方面进行一个基本的介绍
有些地方可能介绍的不够深刻,想单独了解某一块的还需要自己进行深入了解啦!
本文知识介绍一些HTTP的基本知识,最起码跟别人提及的时候不会一问三不知! 完全够用!
🎬六万字 HTTP 必备干货学习,程序员不懂网络怎么行,一篇HTTP入门不收藏都可惜!
首先,要知道 HTTP 是什么,懂一些网络知识的人应该都知道HTTP就是一种超文本传输协议,相对应的还有SSH、FTP等等其它的协议
-
超文本传输协议(HTTP)是一种应用层用于传输超媒体文档的协议,例如html。是互联网上应用最为广泛的一种网络协议 -
它专为 Web 浏览器和 Web 服务器之间的
通信而设计,但也可用于其他目的。 -
HTTP 遵循经典的
客户端-服务器模型,客户端打开连接发出请求,然后等待直到收到响应。 -
HTTP 是一个
无状态协议,这意味着服务器不会在两个请求之间保留任何数据(状态)。 -
HTTP 是一种
可扩展协议,它依赖于资源和统一资源标识符 (URI)、简单的消息结构和客户端-服务器通信流等概念。在这些基本概念之上,多年来开发了许多扩展,这些扩展使用新的 HTTP 方法或标头添加了更新的功能和语义。
HTTP 协议五个特点:
- 支持客户/服务器模式。
- 简单快速:
客户向服务器请求服务时,只需传送请求方法和路径。 - 灵活:
HTTP允许传输任意类型的数据对象。
正在传输的类型由Content-Type(Content-Type是HTTP包中用来表示内容类型的标识)加以标记。 - 无连接:
无连接的含义是限制每次连接只处理一个请求。
服务器处理完客户的请求,并收到客户的应答后,即断开连接。
采用这种方式可以节省传输时间。 - 无状态:
无状态是指协议对于事务处理没有记忆能力,服务器不知道客户端是什么状态。
即我们给服务器发送 HTTP 请求之后,服务器根据请求,会给我们发送数据过来,但是,发送完,不会记录任何信息(Cookie和Session孕育而生)。
🍇网络结构图解
先来几种关于网络协议相关知识的图片,来大概认识一下
下面是七层和五层结构
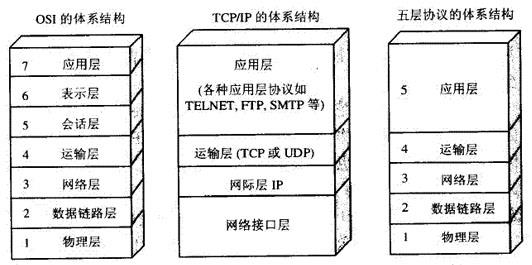
这是四层协议对应七层彼标准协议


7层是指OSI七层协议模型,主要是:应用层(Application)、表示层(Presentation)、会话层(Session)、传输层(Transport)、网络层(Network)、数据链路层(Data Link)、物理层(Physical)。
| OSI 模型 | 主要协议 | 单位 | 功能 | 主要设备 | TCP/IP |
|---|---|---|---|---|---|
| 应用层 | Telnet、FTP、HTTP、SNMP等 | 数据流 | 确定通信对象,提供访问网络服务的接口 | 网关 | 应用层 |
| 表示层 | CSS GIF HTML JSON XML GIF | 数据流 | 负责数据的编码、转化(界面与二进制数据转换,高级语言与机器语言的转换)数据压缩、解压,加密、解密。根据不同应用目的处理为不同的格式,表现出来就是我们看到的各种各样的文件扩展名。 | 网关 | 应用层 |
| 会话层 | FTP SSH TLS HTTP(S) SQL | 数据流 | 负责建立、维护、控制会话单工(Simplex)、半双工(Half duplex)、全双工(Full duplex)三种通信模式的服务 | 网关 | 应用层 |
| 传输层 | TCP UDP | 数据段 | 负责分割、组合数据,实现端到端的逻辑连接三次握手(Three-way handshake),面向连接(Connection-Oriented)或非面向连接(Connectionless-Oriented)的服务,流控(Flow control)等都发生在这一层。是第一个端到端,即主机到主机的层次。 | 网关 | 应用层 |
| 网络层 | IP(IPV4、IPV6) ICMP | 数据包 | 负责管理网络地址,定位设备,决定路由 | 路由器,网桥路由器 | 应用层 |
| 数据链路层 | 802.2、802.3ATM、HDLC | 帧 | 负责准备物理传输,CRC校验,错误通知,网络拓扑,流控等 | 交换机、网桥、网卡 | 应用层 |
| 物理层 | V.35、EIA/TIA-232 | 比特流 | 就是实实在在的物理链路,负责将数据以比特流的方式发送、接收 | 集线器、中继器,电缆,发送器,接收器 | 应用层 |
数据传输流程演示


🍓HTTP概述
HTTP是一个协议(协议是定义数据是如何内或计算机之间交换规则的系统。
设备之间的通信要求设备就正在交换的数据格式达成一致。定义格式的一组规则称为协议),其允许资源,诸如HTML文档的抓取。
它是Web 上任何数据交换的基础,它是一种客户端-服务器协议,这意味着请求由接收方(通常是 Web 浏览器)发起。
从获取的不同子文档(例如文本、布局描述、图像、视频、脚本等)重建完整的文档。

客户端和服务器通过交换单独的消息(而不是数据流)进行通信。客户端(通常是 Web 浏览器)发送的消息称为请求,服务器发送的作为应答的消息称为响应。

HTTP 设计于 1990 年代初,是一种随着时间的推移而发展的可扩展协议。它是通过TCP或通过TLS加密的 TCP 连接发送的应用层协议,尽管理论上可以使用任何可靠的传输协议。
由于其可扩展性,它不仅用于获取超文本文档,还用于获取图像和视频,或者将内容发布到服务器,例如 HTML 表单结果。HTTP 还可用于获取部分文档以按需更新网页。
🏳️🌈基于 HTTP 的系统的组件
HTTP 是一种客户端-服务器协议:请求由一个实体发送,即用户代理(或代表它的代理)。大多数情况下,用户代理是一个 Web 浏览器,但它可以是任何东西,例如爬行 Web 以填充和维护搜索引擎索引的机器人。
每个单独的请求都被发送到一个服务器,该服务器处理它并提供一个称为response的答案。例如,在客户端和服务器之间有许多实体,统称为代理,它们执行不同的操作并充当网关或缓存。

实际上,在浏览器和处理请求的服务器之间有更多的计算机:有路由器、调制解调器等等。由于 Web 的分层设计,这些隐藏在网络层和传输层中。HTTP 位于应用层之上。尽管对于诊断网络问题很重要,但底层大多与 HTTP 的描述无关。
客户端:用户代理
所述用户代理是作用于用户的代表任何工具。此角色主要由 Web 浏览器执行;其他可能性是工程师和 Web 开发人员用来调试他们的应用程序的程序。
浏览器始终是发起请求的实体。它永远不是服务器(尽管多年来已经添加了一些机制来模拟服务器启动的消息)。
为了呈现一个网页,浏览器发送一个原始请求来获取代表该页面的 HTML 文档。然后解析此文件,发出与执行脚本、要显示的布局信息 (CSS) 以及页面中包含的子资源(通常是图像和视频)相对应的附加请求。然后,Web 浏览器混合这些资源以向用户呈现一个完整的文档,即 Web 页面。浏览器执行的脚本可以在后续阶段获取更多资源,浏览器会相应地更新网页。
网页是超文本文档。这意味着显示文本的某些部分是可以激活(通常通过单击鼠标)以获取新网页的链接,从而允许用户指导他们的用户代理并在 Web 中导航。浏览器在 HTTP 请求中转换这些方向,并进一步解释 HTTP 响应以向用户呈现清晰的响应。
网络服务器
在通信通道的另一侧,是服务器,它根据客户端的请求提供文档。服务器实际上只是一台机器:这是因为它实际上可能是一组服务器,共享负载(负载平衡)或询问其他计算机的复杂软件(如缓存、数据库服务器或电子商务服务器),完全或部分按需生成文档。
服务器不一定是一台机器,但可以在同一台机器上托管多个服务器软件实例。使用 HTTP/1.1 和Host标头,它们甚至可能共享相同的 IP 地址。
代理
在 Web 浏览器和服务器之间,许多计算机和机器中继 HTTP 消息。由于 Web 堆栈的分层结构,其中大部分在传输、网络或物理级别运行,在 HTTP 层变得透明,并可能对性能产生重大影响。那些在应用层操作的通常称为代理。这些可以是透明的,在不以任何方式更改它们的情况下转发它们收到的请求,或者是不透明的,在这种情况下,它们将在将请求传递给服务器之前以某种方式更改请求。代理可以执行多种功能:
- 缓存(缓存可以是公共的或私有的,如浏览器缓存)
- 过滤(如防病毒扫描或家长控制)
- 负载平衡(允许多个服务器为不同的请求提供服务)
- 身份验证(控制对不同资源的访问)
- 日志记录(允许存储历史信息)
🏳️🌈HTTP 的基本方面
HTTP 很简单
HTTP 通常被设计为简单易读,即使在 HTTP/2 中通过将 HTTP 消息封装到帧中引入了额外的复杂性。HTTP 消息可以被人类阅读和理解,为开发人员提供了更容易的测试,并降低了新手的复杂性。
HTTP 是可扩展的
HTTP/1.0 中引入的HTTP 标头使该协议易于扩展和试验。甚至可以通过客户端和服务器之间关于新标头语义的简单协议来引入新功能。
HTTP 是无状态的,但不是无会话的
HTTP 是无状态的:在同一连接上连续执行的两个请求之间没有链接。对于试图与某些页面进行连贯交互的用户(例如,使用电子商务购物篮)而言,这立即有可能成为问题。但是,虽然 HTTP 本身的核心是无状态的,但 HTTP cookie 允许使用有状态的会话。使用标头可扩展性,HTTP Cookie 被添加到工作流中,允许在每个 HTTP 请求上创建会话以共享相同的上下文或相同的状态。
HTTP 和连接
连接是在传输层控制的,因此从根本上超出了 HTTP 的范围。虽然 HTTP 不要求底层传输协议是基于连接的;只要求它是可靠的,或者不丢失消息(因此至少会出现错误)。在 Internet 上最常见的两种传输协议中,TCP 是可靠的,而 UDP 则不是。因此,HTTP 依赖于基于连接的 TCP 标准。
在客户端和服务器可以交换 HTTP 请求/响应对之前,它们必须建立 TCP 连接,这个过程需要多次往返。HTTP/1.0 的默认行为是为每个 HTTP 请求/响应对打开单独的 TCP 连接。当多个请求连续发送时,这比共享单个 TCP 连接效率低。
为了缓解这个缺陷,HTTP/1.1 引入了流水线(被证明难以实现)和持久连接:可以使用Connection标头部分控制底层 TCP 连接。HTTP/2 更进一步,通过在单个连接上多路复用消息,帮助保持连接温暖和更高效。
正在进行实验以设计更适合 HTTP 的更好的传输协议。例如,谷歌正在试验快讯 它建立在 UDP 之上,以提供更可靠、更高效的传输协议。
🏳️🌈HTTP可以控制什么
随着时间的推移,HTTP 的这种可扩展特性允许对 Web 进行更多控制和功能。缓存或身份验证方法是 HTTP 历史早期处理的函数。相比之下,放宽原点约束的能力直到2010 年代才被添加。
以下是可通过 HTTP 控制的常见功能列表。
- 缓存
如何缓存文档可以由 HTTP 控制。服务器可以指示代理和客户端缓存什么以及缓存多长时间。客户端可以指示中间缓存代理忽略存储的文档。 - 放宽来源限制
为防止窥探和其他隐私侵犯,Web 浏览器强制在 Web 站点之间进行严格分离。只有来自同一来源的页面才能访问网页的所有信息。虽然这样的约束对服务器来说是一种负担,但 HTTP 头可以在服务器端放松这种严格的分离,让文档成为来自不同域的信息的拼凑;甚至可能有与安全相关的原因这样做。 - 身份验证
某些页面可能受到保护,以便只有特定用户才能访问它们。基本身份验证可以由 HTTP 提供,或者使用WWW-Authenticate和类似的标头,或者通过使用HTTP cookie设置特定会话。 - 代理和隧道
服务器或客户端通常位于 Intranet 上,并向其他计算机隐藏其真实 IP 地址。HTTP 请求然后通过代理来跨越这个网络障碍。并非所有代理都是 HTTP 代理。例如,SOCKS 协议在较低级别运行。其他协议,如 ftp,可以由这些代理处理。 - 会话
使用 HTTP cookie 允许您将请求与服务器的状态联系起来。尽管基本 HTTP 是无状态协议,但这会创建会话。这不仅适用于电子商务购物篮,而且适用于允许用户配置输出的任何站点。
🏳️🌈HTTP 流
当客户端想要与服务器(最终服务器或中间代理)通信时,它执行以下步骤:
- 打开一个 TCP 连接:TCP 连接用于发送一个或多个请求,并接收一个应答。客户端可以打开一个新的连接,重用一个现有的连接,或者打开几个到服务器的 TCP 连接。
- 发送 HTTP 消息:HTTP 消息(在 HTTP/2 之前)是人类可读的。在 HTTP/2 中,这些简单的消息被封装在帧中,无法直接读取,但原理保持不变。例如
GET / HTTP/1.1
Host: developer.mozilla.org
Accept-Language: fr
- 读取服务器发送的响应,如:
HTTP/1.1 200 OK
Date: Sat, 09 Oct 2010 14:28:02 GMT
Server: Apache
Last-Modified: Tue, 01 Dec 2009 20:18:22 GMT
ETag: "51142bc1-7449-479b075b2891b"
Accept-Ranges: bytes
Content-Length: 29769
Content-Type: text/html
<!DOCTYPE html... (here comes the 29769 bytes of the requested web page)
- 关闭或重用连接以进行进一步的请求。
如果激活 HTTP 流水线,则可以发送多个请求,而无需等待完全接收到第一个响应。HTTP 流水线已被证明难以在现有网络中实现,其中旧软件与现代版本共存。HTTP 流水线已在 HTTP/2 中被取代,在帧内具有更强大的多路复用请求。
🏳️🌈HTTP 消息
HTTP 消息,如 HTTP/1.1 及更早版本中所定义,是人类可读的。在 HTTP/2 中,这些消息被嵌入到一个二进制结构中,一个frame,允许优化,如压缩头和多路复用。即使在这个版本的 HTTP 中只发送了原始 HTTP 消息的一部分,每条消息的语义也没有改变,客户端重新构造(虚拟)原始 HTTP/1.1 请求。因此,理解 HTTP/1.1 格式的 HTTP/2 消息很有用。
HTTP 消息有两种类型,请求和响应,每种都有自己的格式。
请求
HTTP 请求示例:
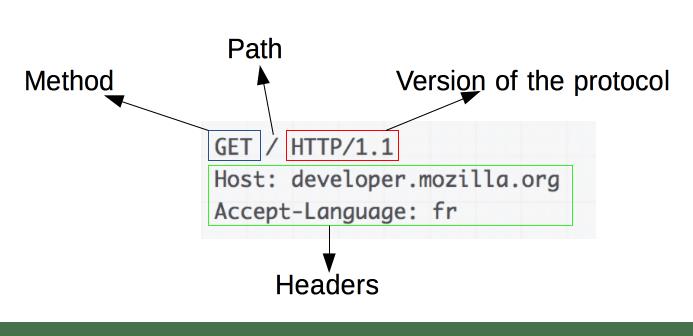
请求由以下元素组成:
-
一个HTTP方法,通常是一个动词等GET,POST或像一个名词OPTIONS或HEAD定义客户端想要执行操作。通常,客户端想要获取资源(使用GET)或发布HTML 表单的值(使用POST),但在其他情况下可能需要更多操作。
-
要获取的资源的路径;从上下文中显而易见的元素中剥离的资源 URL,例如没有协议( http://)、域(此处为developer.mozilla.org)或 TCP端口(此处为80)。
-
HTTP 协议的版本。
-
为服务器传达附加信息的可选标头。
响应
一个示例响应:
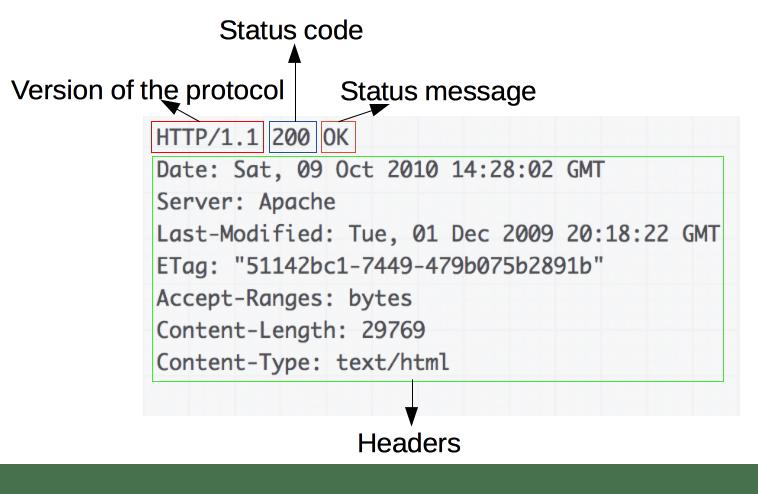
响应由以下元素组成:
- 他们遵循的 HTTP 协议的版本。
- 一个状态代码(status code),表示如果请求成功,或没有,以及为什么。
- 状态消息,状态代码的非权威性简短描述。
- HTTP标头,就像请求的标头一样。
- 可选地,包含获取的资源的正文。
🏳️🌈基于 HTTP 的 API
最常用的基于 HTTP 的API是XMLHttpRequestAPI,它可以用于在用户代理和服务器之间交换数据。现代Fetch API提供了相同的功能和更强大、更灵活的功能集。
另一个 API,服务器发送事件( server-sent events),是一种单向服务,它允许服务器使用 HTTP 作为传输机制向客户端发送事件。
使用该EventSource接口,客户端打开一个连接并建立事件处理程序。客户端浏览器自动将到达 HTTP 流的消息转换为适当的Event对象,将它们传递给已为事件注册的事件处理程序(type如果已知),或者onmessage如果没有建立特定类型的事件处理程序,则传递给事件处理程序。
HTTP 是一种易于使用的可扩展协议。客户端-服务器结构与添加标头的能力相结合,允许 HTTP 与 Web 的扩展功能一起发展。
尽管 HTTP/2 增加了一些复杂性,但通过在帧中嵌入 HTTP 消息来提高性能,消息的基本结构自 HTTP/1.0 以来一直保持不变。会话流保持简单,允许使用简单的HTTP 消息监视器对其进行调查和调试。

🍉HTTP 的演变
HTTP(超文本传输协议)是万维网的底层协议。由 Tim Berners-Lee 及其团队在 1989 年至 1991 年间开发的 HTTP 经历了许多变化,保留了大部分简单性并进一步塑造了其灵活性。HTTP 已经从早期在半可信实验室环境中交换文件的协议演变为现代互联网迷宫,现在承载高分辨率和 3D 图像、视频。
🏳️🌈万维网的发明
1989 年,在欧洲核子研究中心工作期间,蒂姆·伯纳斯-李 (Tim Berners-Lee) 撰写了一份在 Internet 上构建超文本系统的提案。最初将其称为Mesh,后来在 1990 年实施期间更名为万维网。 它基于现有的 TCP 和 IP 协议构建,由 4 个构建块组成:
- 一种表示超文本文档的文本格式,即超文本标记语言(HTML)。
- 一个交换超文本文档的简单协议,超文本传输协议(HTTP)。
- 一个显示(以及编辑)超文本文档的客户端,即网络浏览器。第一个网络浏览器被称为 万维网。
- 一个服务器用于提供可访问的文档,即 httpd 的前身。
这四个部分于 1990 年底完成,且第一批服务器已经在 1991 年初在 CERN 以外的地方运行了。 1991 年 8 月 16 日,Tim Berners-Lee 在公开的文本超新闻组上发表的文章被视为是万维网公共项目的开始。
HTTP在应用的早期阶段非常简单,后来变成了HTTP/0.9,有时也可以上网协议单行(one-line)。
🏳️🌈HTTP/0.9 – 单行协议
最初版本的HTTP协议并没有版本号,之后的版本号被定位在0.9,以各个版本的版本为准。 HTTP/0.9非常简单:请求由单行语句构成,以唯一的方法GET开头,其后跟目标资源的路径(游戏连接到服务器,协议、服务器、端口号这些都不是必须的)。
GET /mypage.html
响应也极其简单的:只包含响应文档。
<HTML>
这是一个非常简单的HTML页面
</HTML>
跟后来的不同版本,HTTP/0.9 的响应内容没有包含 HTTP 头,这表明只有 HTML 文件可以发送,无法传输其他类型的文件;也没有状态码或错误代码:出现问题,一个特殊的包含问题描述信息的HTML文件将被发回,供人们查看。
🏳️🌈HTTP/1.0 – 构建可扩展性
由于 HTTP/0.9 协议的应用十分有限,服务器和服务器迅速扩展内容浏览范围更广:
- 协议版本信息现在会随着请求发送(HTTP/1.0被添加到了GET行)。
- 状态码会在响应开始时发送,使浏览器能够了解请求执行成功或失败,并相应调整行为(如更新或本地使用)。
- 引入了HTTP头的概念,无论是对于请求还是响应,都允许传输元数据,使协议变得非常灵活,扩展性很强。
- 在新 HTTP 头的帮助下,具备了传输除纯文本 HTML 文件以外的其他类型文档的能力(感谢Content-Type头)。
一个典型的请求像这样:
GET /mypage.html HTTP/1.0
User-Agent: NCSA_Mosaic/2.0 (Windows 3.1)
200 OK
Date: Tue, 15 Nov 1994 08:12:31 GMT
Server: CERN/3.0 libwww/2.17
Content-Type: text/html
<HTML>
一个包含图片的页面
<IMG SRC="/myimage.gif">
</HTML>
接下来是第二个连接,请求获取图片:
GET /myimage.gif HTTP/1.0
User-Agent: NCSA_Mosaic/2.0 (Windows 3.1)
200 OK
Date: Tue, 15 Nov 1994 08:12:32 GMT
Server: CERN/3.0 libwww/2.17
Content-Type: text/gif
(这里是图片内容)
在 1991-1995 年,这些新扩展并没有被引入到标准中以辅助帮助工作,而作为一种尝试:服务器和浏览器添加了这些新扩展功能,但出现了大量的互操作问题。直到 1996 年11 月,为了解决这些问题,一份新的文档(RFC 145)被发表出来,描述了如何操作实践这些新扩展功能。文档 RFC 1945 定义了 HTTP/1.0,但它是狭义的,不是官方标准。
🏳️🌈HTTP/1.1 – 模块化的协议
HTTP/1.0 多种不同的实现方式在实践文档中,自1995 年开始,即HTTP/1.0 发布的下一年,就开始修订HTTP 的第一个标准版本。在1997 年初,HTTP1. 1 标准发布,就在HTTP/1.0发布后。
HTTP/1.1删除了大量的歧义内容并引用了声明:
- 连接可以一次,节省了很多时间打开TCP连接加载网页文档资源的时间。
- 第一次增加就化技术,允许在第一个通知被完全发送之后第二个请求,以降低延迟。
- 支持响应分块。
- 引入额外的检测控制。
- 引入内容协商机制,包括语言、编码、编码等,并允许客户端和服务器之间约定以最合适的内容进行交换。
- 感谢Host头,能够使不同的域名配置在同一个IP地址的服务器上。
一个典型的请求流程, 所有请求都通过一个连接实现,看起来就像这样:
GET /en-US/docs/Glossary/Simple_header HTTP/1.1
Host: developer.mozilla.org
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:50.0) Gecko/20100101 Firefox/50.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate, br
Referer: https://developer.mozilla.org/en-US/docs/Glossary/Simple_header
200 OK
Connection: Keep-Alive
Content-Encoding: gzip
Content-Type: text/html; charset=utf-8
Date: Wed, 20 Jul 2016 10:55:30 GMT
Etag: "547fa7e369ef56031dd3bff2ace9fc0832eb251a"
Keep-Alive: timeout=5, max=1000
Last-Modified: Tue, 19 Jul 2016 00:59:33 GMT
Server: Apache
Transfer-Encoding: chunked
Vary: Cookie, Accept-Encoding
(content)
GET /static/img/header-background.png HTTP/1.1
Host: developer.mozilla.org
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:50.0) Gecko/20100101 Firefox/50.0
Accept: */*
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate, br
Referer: https://developer.mozilla.org/en-US/docs/Glossary/Simple_header
200 OK
Age: 9578461
Cache-Control: public, max-age=315360000
Connection: keep-alive
Content-Length: 3077
Content-Type: image/png
Date: Thu, 31 Mar 2016 13:34:46 GMT
Last-Modified: Wed, 21 Oct 2015 18:27:50 GMT
Server: Apache
(image content of 3077 bytes)
HTTP/1.1 在1997年1月以 RFC 2068 文件发布。
🏳️🌈超过21年的扩展
由于HTTP协议的可扩展性 – 创建新的头部和方法是很容易的 – 即使HTTP/1.1协议进行过两次修订,RFC 2616 发布于1999年6月,而另外两个文档 RFC 7230-RFC 7235 发布于2014年6月,作为HTTP/2的预览版本。
HTTP协议已经稳定使用超过21年了。
HTTP 用于安全传输
-
HTTP最大的变化发生在1994年底。HTTP在基本的TCP/IP协议栈上发送信息,网景公司(Netscape Communication)在此基础上创建了一个额外的加密传输层:SSL 。SSL 1.0没有在公司以外发布过,但SSL 2.0及其后继者SSL 3.0和SSL 3.1允许通过加密来保证服务器和客户端之间交换消息的真实性,来创建电子商务网站。SSL在标准化道路上最终成为TLS,随着版本1.0, 1.1, 1.2的出现成功地关闭漏洞。TLS 1.3 目前正在形成。
-
与此同时,人们对一个加密传输层的需求也愈发高涨:因为 Web 最早几乎是一个学术网络,相对信任度很高,但如今不得不面对一个险恶的丛林:广告客户、随机的个人或者犯罪分子争相劫取个人信息,将信息占为己有,甚至改动将要被传输的数据。随着通过HTTP构建的应用程序变得越来越强大,可以访问越来越多的私人信息,如地址簿,电子邮件或用户的地理位置,即使在电子商务使用之外,对TLS的需求也变得普遍。
HTTP 用于复杂应用
-
Tim Berners-Lee 对于 Web 的最初设想不是一个只读媒体。 他设想一个 Web 是可以远程添加或移动文档,是一种分布式文件系统。 大约 1996 年,HTTP 被扩展到允许创作,并且创建了一个名为 WebDAV 的标准。 它进一步扩展了某些特定的应用程序,如 CardDAV 用来处理地址簿条目,CalDAV 用来处理日历。
-
但所有这些 *DAV 扩展有一个缺陷:它们必须由要使用的服务器来实现,这是非常复杂的。并且他们在网络领域的使用必须保密。
-
在 2000 年,一种新的使用 HTTP 的模式被设计出来:representational state transfer (或者说 REST)。 由 API 发起的操作不再通过新的 HTTP 方法传达,而只能通过使用基本的 HTTP / 1.1 方法访问特定的 URI。 这允许任何 Web 应用程序通过提供 API 以允许查看和修改其数据,而无需更新浏览器或服务器:all what is needed was embedded in the files served by the Web sites through standard HTTP/1.1。 REST 模型的缺点在于每个网站都定义了自己的非标准 RESTful API,并对其进行了全面的控制;不同于 *DAV 扩展,客户端和服务器是可互操作的。 RESTful API 在 2010 年变得非常流行。
自 2005 年以来,可用于 Web 页面的 API 大大增加,其中几个 API 为特定目的扩展了 HTTP 协议,大部分是新的特定 HTTP 头:
- Server-sent events,服务器可以偶尔推送消息到浏览器。
- WebSocket,一个新协议,可以通过升级现有 HTTP 协议来建立。
放松Web的安全模型
HTTP和Web安全模型–同源策略是互不相关的。事实上,当前的Web安全模型是在HTTP被创造出来后才被发展的!这些年来,已经证实了它如果能通过在特定的约束下移除一些这个策略的限制来管的宽松些的话,将会更有用。这些策略导致大量的成本和时间被花费在通过转交到服务端来添加一些新的HTTP头来发送。这些被定义在了Cross-Origin Resource Sharing (CORS) or the Content Security Policy (CSP)规范里。
不只是这大量的扩展,很多的其他的头也被加了进来,有些只是实验性的。比较著名的有Do Not Track (DNT) 来控制隐私,X-Frame-Options, 还有很多。
🏳️🌈HTTP/2 - 为了更优异的表现
-
这些年来,网页愈渐变得的复杂,甚至演变成了独有的应用,可见媒体的播放量,增进交互的脚本大小也增加了许多:更多的数据通过HTTP请求被传输。HTTP/1.1链接需要请求以正确的顺序发送,理论上可以用一些并行的链接(尤其是5到8个),带来的成本和复杂性堪忧。比如,HTTP管线化(pipelining)就成为了Web开发的负担。
-
在2010年到2015年,谷歌通过实践了一个实验性的SPDY协议,证明了一个在客户端和服务器端交换数据的另类方式。其收集了浏览器和服务器端的开发者的焦点问题。明确了响应数量的增加和解决复杂的数据传输,SPDY成为了HTTP/2协议的基础。
HTTP/2在HTTP/1.1有几处基本的不同:
- HTTP/2是二进制协议而不是文本协议。不再可读,也不可无障碍的手动创建,改善的优化技术现在可被实施。
- 这是一个复用协议。并行的请求能在同一个链接中处理,移除了HTTP/1.x中顺序和阻塞的约束。
- 压缩了headers。因为headers在一系列请求中常常是相似的,其移除了重复和传输重复数据的成本。
- 其允许服务器在客户端缓存中填充数据,通过一个叫服务器推送的机制来提前请求。
在2015年5月正式标准化后,HTTP/2取得了极大的成功,在2016年7月前,8.7%的站点已经在使用它,代表超过68%的请求 。高流量的站点最迅速的普及,在数据传输上节省了可观的成本和支出。
这种迅速的普及率很可能是因为HTTP2不需要站点和应用做出改变:使用HTTP/1.1和HTTP/2对他们来说是透明的。拥有一个最新的服务器和新点的浏览器进行交互就足够了。只有一小部分群体需要做出改变,而且随着陈旧的浏览器和服务器的更新,而不需Web开发者做什么,用的人自然就增加了。
🏳️🌈后HTTP/2进化
随着HTTP/2.的发布,就像先前的HTTP/1.x一样,HTTP没有停止进化,HTTP的扩展性依然被用来添加新的功能。特别的,我们能列举出2016年里HTTP的新扩展:
- 对Alt-Svc的支持允许了给定资源的位置和资源鉴定,允许了更智能的CDN缓冲机制。
- Client-Hints 的引入允许浏览器或者客户端来主动交流它的需求,或者是硬件约束的信息给服务端。
- 在Cookie头中引入安全相关的的前缀,现在帮助保证一个安全的cookie没被更改过。
HTTP的进化证实了它良好的扩展性和简易性,释放了很多应用程序的创造力并且情愿使用这个协议。今天的HTTP的使用环境已经于早期1990年代大不相同。HTTP的原先的设计不负杰作之名,允许了Web在25年间和平稳健得发展。修复漏洞,同时却也保留了使HTTP如此成功的灵活性和扩展性,HTTP/2的普及也预示着这个协议的大好前程。

🍒HTTP 缓存
通过复用以前获取的资源,可以显著提高网站和应用程序的性能。Web 缓存减少了等待时间和网络流量,因此减少了显示资源表示形式所需的时间。通过使用 HTTP缓存,变得更加响应性。
🏳️🌈不同种类的缓存
-
缓存是一种保存资源副本并在下次请求时直接使用该副本的技术。当 web 缓存发现请求的资源已经被存储,它会拦截请求,返回该资源的拷贝,而不会去源服务器重新下载。这样带来的好处有:缓解服务器端压力,提升性能(获取资源的耗时更短了)。对于网站来说,缓存是达到高性能的重要组成部分。缓存需要合理配置,因为并不是所有资源都是永久不变的:重要的是对一个资源的缓存应截止到其下一次发生改变(即不能缓存过期的资源)。
-
缓存的种类有很多,其大致可归为两类:私有与共享缓存。共享缓存存储的响应能够被多个用户使用。私有缓存只能用于单独用户。本文将主要介绍浏览器与代理缓存,除此之外还有网关缓存、CDN、反向代理缓存和负载均衡器等部署在服务器上的缓存方式,为站点和 web 应用提供更好的稳定性、性能和扩展性。
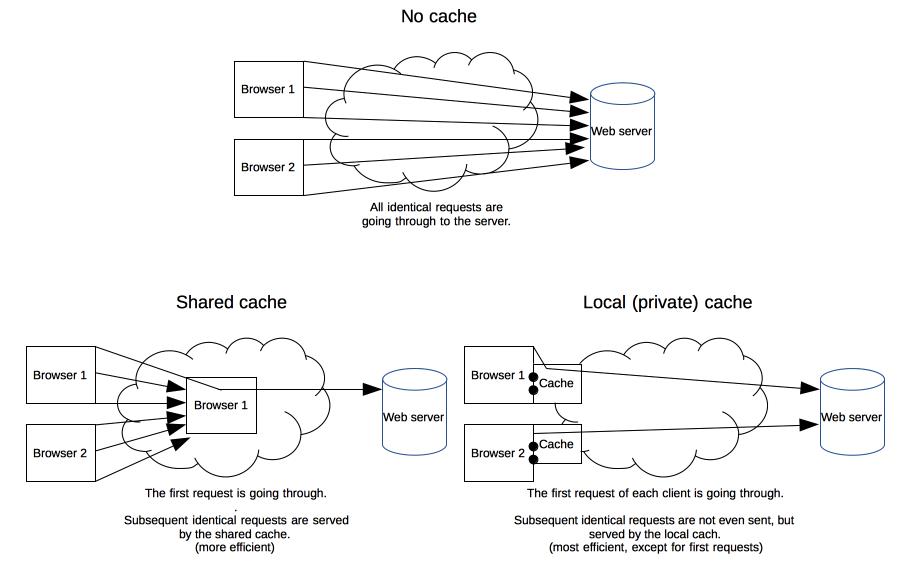
(私有)浏览器缓存
私有缓存只能用于单独用户。你可能已经见过浏览器设置中的“缓存”选项。浏览器缓存拥有用户通过 HTTP 下载的所有文档。这些缓存为浏览过的文档提供向后/向前导航,保存网页,查看源码等功能,可以避免再次向服务器发起多余的请求。它同样可以提供缓存内容的离线浏览。
(共享)代理缓存
共享缓存可以被多个用户使用。例如,ISP 或你所在的公司可能会架设一个 web 代理来作为本地网络基础的一部分提供给用户。这样热门的资源就会被重复使用,减少网络拥堵与延迟。
🏳️🌈缓存操作的目标
虽然 HTTP 缓存不是必须的,但重用缓存的资源通常是必要的。然而常见的 HTTP 缓存只能存储 GET 响应,对于其他类型的响应则无能为力。缓存的关键主要包括request method和目标URI(一般只有GET请求才会被缓存)。 普遍的缓存案例:
- 一个检索请求的成功响应: 对于 GET请求,响应状态码为:200,则表示为成功。一个包含例如HTML文档,图片,或者文件的响应。
- 永久重定向: 响应状态码:301。
- 错误响应: 响应状态码:404 的一个页面。
- 不完全的响应: 响应状态码 206,只返回局部的信息。
- 除了 GET 请求外,如果匹配到作为一个已被定义的cache键名的响应。
针对一些特定的请求,也可以通过关键字区分多个存储的不同响应以组成缓存的内容。具体参考下文关于 Vary 的信息。
🏳️🌈缓存控制
Cache-control 头
HTTP/1.1定义的 Cache-Control 头用来区分对缓存机制的支持情况, 请求头和响应头都支持这个属性。通过它提供的不同的值来定义缓存策略。
没有缓存
缓存中不得存储任何关于客户端请求和服务端响应的内容。每次由客户端发起的请求都会下载完整的响应内容。
Cache-Control: no-store
缓存但重新验证
如下头部定义,此方式下,每次有请求发出时,缓存会将此请求发到服务器(译者注:该请求应该会带有与本地缓存相关的验证字段),服务器端会验证请求中所描述的缓存是否过期,若未过期(注:实际就是返回304),则缓存才使用本地缓存副本。
Cache-Control: no-cache
私有和公共缓存
“public” 指令表示该响应可以被任何中间人(译者注:比如中间代理、CDN等)缓存。若指定了"public",则一些通常不被中间人缓存的页面(译者注:因为默认是private)(比如 带有HTTP验证信息(帐号密码)的页面 或 某些特定状态码的页面),将会被其缓存。
而 “private” 则表示该响应是专用于某单个用户的,中间人不能缓存此响应,该响应只能应用于浏览器私有缓存中。
Cache-Control: private
Cache-Control: public
过期
过期机制中,最重要的指令是 “max-age=”,表示资源能够被缓存(保持新鲜)的最大时间。相对Expires而言,max-age是距离请求发起的时间的秒数。针对应用中那些不会改变的文件,通常可以手动设置一定的时长以保证缓存有效,例如图片、css、js等静态资源。
详情看下文关于缓存有效性的内容。
Cache-Control: max-age=31536000
验证方式
当使用了 “must-revalidate” 指令,那就意味着缓存在考虑使用一个陈旧的资源时,必须先验证它的状态,已过期的缓存将不被使用。详情看下文关于缓存校验的内容。
Cache-Control: must-revalidate
Pragma 头
Pragma 是HTTP/1.0标准中定义的一个header属性,请求中包含Pragma的效果跟在头信息中定义Cache-Control: no-cache相同,但是HTTP的响应头没有明确定义这个属性,所以它不能拿来完全替代HTTP/1.1中定义的Cache-control头。通常定义Pragma以向后兼容基于HTTP/1.0的客户端。
🏳️🌈新鲜度
-
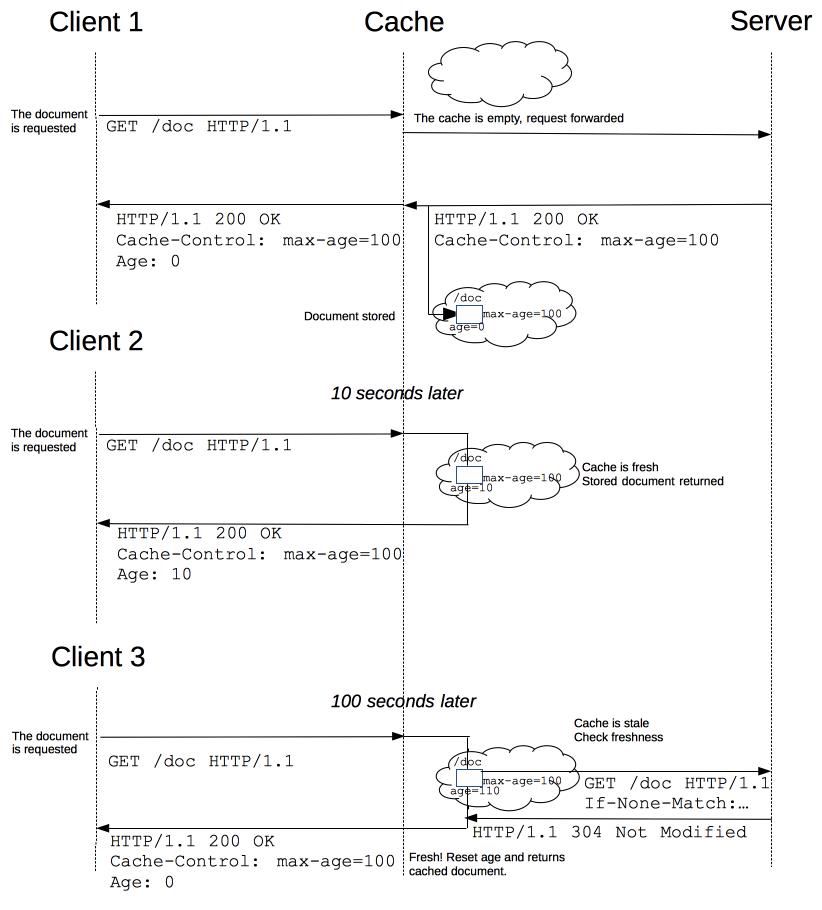
理论上来讲,当一个资源被缓存存储后,该资源应该可以被永久存储在缓存中。由于缓存只有有限的空间用于存储资源副本,所以缓存会定期地将一些副本删除,这个过程叫做缓存驱逐。另一方面,当服务器上面的资源进行了更新,那么缓存中的对应资源也应该被更新,由于HTTP是C/S模式的协议,服务器更新一个资源时,不可能直接通知客户端更新缓存,所以双方必须为该资源约定一个过期时间,在该过期时间之前,该资源(缓存副本)就是新鲜的,当过了过期时间后,该资源(缓存副本)则变为陈旧的。
-
驱逐算法用于将陈旧的资源(缓存副本)替换为新鲜的,注意,一个陈旧的资源(缓存副本)是不会直接被清除或忽略的,当客户端发起一个请求时,缓存检索到已有一个对应的陈旧资源(缓存副本),则缓存会先将此请求附加一个If-None-Match头,然后发给目标服务器,以此来检查该资源副本是否是依然还是算新鲜的,若服务器返回了 304 (Not Modified)(该响应不会有带有实体信息),则表示此资源副本是新鲜的,这样一来,可以节省一些带宽。若服务器通过 If-None-Match 或 If-Modified-Since判断后发现已过期,那么会带有该资源的实体内容返回。
下面是上述缓存处理过程的一个图示:

对于含有特定头信息的请求,会去计算缓存寿命。比如Cache-control: max-age=N的头,相应的缓存的寿命就是N。通常情况下,对于不含这个属性的请求则会去查看是否包含Expires属性,通过比较Expires的值和头里面Date属性的值来判断是否缓存还有效。如果max-age和expires属性都没有,找找头里的Last-Modified信息。如果有,缓存的寿命就等于头里面Date的值减去Last-Modified的值除以10(注:根据rfc2626其实也就是乘以10%)。
缓存失效时间计算公式如下:
expirationTime = responseTime + freshnessLifetime - currentAge
上式中,responseTime 表示浏览器接收到此响应的那个时间点。
改进资源
-
我们使用缓存的资源越多,网站的响应能力和性能就会越好。为了优化缓存,过期时间设置得尽量长是一种很好的策略。对于定期或者频繁更新的资源,这么做是比较稳妥的,但是对于那些长期不更新的资源会有点问题。这些固定的资源在一定时间内受益于这种长期保持的缓存策略,但一旦要更新就会很困难。特指网页上引入的一些js/css文件,当它们变动时需要尽快更新线上资源。
-
web开发者发明了一种被 Steve Souders 称之为 revving 的技术[1] 。不频繁更新的文件会使用特定的命名方式:在URL后面(通常是文件名后面)会加上版本号。加上版本号后的资源就被视作一个完全新的独立的资源,同时拥有一年甚至更长的缓存过期时长。但是这么做也存在一个弊端,所有引用这个资源的地方都需要更新链接。web开发者们通常会采用自动化构建工具在实际工作中完成这些琐碎的工作。当低频更新的资源(js/css)变动了,只用在高频变动的资源文件(html)里做入口的改动。
-
这种方法还有一个好处:同时更新两个缓存资源不会造成部分缓存先更新而引起新旧文件内容不一致。对于互相有依赖关系的css和js文件,避免这种不一致性是非常重要的。
加在加速文件后面的版本号不一定是一个正式的版本号字符串,如1.1.3这样或者其他固定自增的版本数。它可以是任何防止缓存碰撞的标记例如hash或者时间戳。
🏳️🌈缓存验证
-
用户点击刷新按钮时会开始缓存验证。如果缓存的响应头信息里含有"Cache-control: must-revalidate”的定义,在浏览的过程中也会触发缓存验证。另外,在浏览器偏好设置里设置Advanced->Cache为强制验证缓存也能达到相同的效果。
-
当缓存的文档过期后,需要进行缓存验证或者重新获取资源。只有在服务器返回强校验器或者弱校验器时才会进行验证。
ETags
-
作为缓存的一种强校验器,ETag 响应头是一个对用户代理(User Agent, 下面简称UA)不透明(译者注:UA 无需理解,只需要按规定使用即可)的值。对于像浏览器这样的HTTP UA,不知道ETag代表什么,不能预测它的值是多少。如果资源请求的响应头里含有ETag, 客户端可以在后续的请求的头中带上 If-None-Match 头来验证缓存。
-
Last-Modified 响应头可以作为一种弱校验器。说它弱是因为它只能精确到一秒。如果响应头里含有这个信息,客户端可以在后续的请求中带上 If-Modified-Since 来验证缓存。
-
当向服务端发起缓存校验的请求时,服务端会返回 200 ok表示返回正常的结果或者 304 Not Modified(不返回body)表示浏览器可以使用本地缓存文件。304的响应头也可以同时更新缓存文档的过期时间。
🏳️🌈Vary 响应
Vary HTTP 响应头决定了对于后续的请求头,如何判断是请求一个新的资源还是使用缓存的文件。
当缓存服务器收到一个请求,只有当前的请求和原始(缓存)的请求头跟缓存的响应头里的Vary都匹配,才能使用缓存的响应。

- 使用vary头有利于内容服务的动态多样性。例如,使用Vary: User-Agent头,缓存服务器需要通过UA判断是否使用缓存的页面。如果需要区分移动端和桌面端的展示内容,利用这种方式就能避免在不同的终端展示错误的布局。另外,它可以帮助 Google 或者其他搜索引擎更好地发现页面的移动版本,并且告诉搜索引擎没有引入Cloaking。
Vary: User-Agent
因为移动版和桌面的客户端的请求头中的User-Agent不同, 缓存服务器不会错误地把移动端的内容输出到桌面端到用户。

🍑HTTP cookies
RFC 6265定义了 cookie 的工作方式。在处理 HTTP 请求时,服务器可以在 HTTP 响应头中通过HTTP Headers Set-Cookie 为客户端设置 cookie。然后,对于同一服务器发起的每一个请求,客户端都会在 HTTP 请求头中以字段 Cookie 的形式将 cookie 的值发送过去。也可以将 cookie 设置为在特定日期过期,或限制为特定的域和路径。
HTTP Cookie(也叫 Web Cookie 或浏览器 Cookie)是服务器发送到用户浏览器并保存在本地的一小块数据,它会在浏览器下次向同一服务器再发起请求时被携带并发送到服务器上。通常,它用于告知服务端两个请求是否来自同一浏览器,如保持用户的登录状态。Cookie 使基于无状态的HTTP协议记录稳定的状态信息成为了可能。
Cookie 主要用于以下三个方面:
- 会话状态管理(如用户登录状态、购物车、游戏分数或其它需要记录的信息)
- 个性化设置(如用户自定义设置、主题等)
- 浏览器行为跟踪(如跟踪分析用户行为等)
Cookie 曾一度用于客户端数据的存储,因当时并没有其它合适的存储办法而作为唯一的存储手段,但现在随着现代浏览器开始支持各种各样的存储方式,Cookie 渐渐被淘汰。由于服务器指定 Cookie 后,浏览器的每次请求都会携带 Cookie 数据,会带来额外的性能开销(尤其是在移动环境下)。新的浏览器API已经允许开发者直接将数据存储到本地,如使用 Web storage API (本地存储和会话存储)或 IndexedDB 。
要查看Cookie存储(或网页上能够使用其他的存储方式),你可以在开发者工具中启用存储查看(Storage Inspector )功能,并在存储树上选中Cookie。
🏳️🌈创建Cookie
当服务器收到 HTTP 请求时,服务器可以在响应头里面添加一个 Set-Cookie 选项。浏览器收到响应后通常会保存下 Cookie,之后对该服务器每一次请求中都通过 Cookie 请求头部将 Cookie 信息发送给服务器。另外,Cookie 的过期时间、域
以上是关于六万字 HTTP 必备干货学习,程序员不懂网络怎么行,一篇HTTP入门 不收藏都可惜!的主要内容,如果未能解决你的问题,请参考以下文章
爆肝六万字整理的python基础,快速入门python的首先
六万字长文!让你懂透编译原理——第七章 语义分析和中间代码产生