PaddlePaddle:在 Serverless 架构上十几行代码实现 OCR 能力
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PaddlePaddle:在 Serverless 架构上十几行代码实现 OCR 能力相关的知识,希望对你有一定的参考价值。
简介: 飞桨深度学习框架采用基于编程逻辑的组网范式,对于普通开发者而言更容易上手,同时支持声明式和命令式编程,兼具开发的灵活性和高性能。

飞桨 (PaddlePaddle) 以百度多年的深度学习技术研究和业务应用为基础,是中国首个自主研发、功能完备、 开源开放的产业级深度学习平台,集深度学习核心训练和推理框架、基础模型库、端到端开发套件和丰富的工具组件于一体。
飞桨深度学习框架采用基于编程逻辑的组网范式,对于普通开发者而言更容易上手,同时支持声明式和命令式编程,兼具开发的灵活性和高性能。另外飞桨不仅广泛兼容第三方开源框架训练的模型部署,并且为不同的场景的生产环境提供了完备的推理引擎,包括适用于高性能服务器及云端推理的原生推理库 Paddle Inference,面向分布式、流水线生产环境下自动上云、A/B 测试等高阶功能的服务化推理框架 Paddle Serving,针对于移动端、物联网场景的轻量化推理引擎 Paddle Lite,以及在浏览器、小程序等环境下使用的前端推理引擎 Paddle.js。同时,透过与不同场景下的主流硬件高度适配优化及异构计算的支持, 飞桨的推理性能也领先绝大部分的主流实现。
安装飞桨
飞桨可以被认为是一个 Python 的依赖库,官方提供了 pip,conda,源码编译等多种安装方法。以 pip 安装方法为例,飞桨提供了 CPU 和 GPU 两个版本安装方法:
- CPU 版本安装方法:
pip install paddlepaddle
- GPU 版本安装方法:
pip install paddlepaddle-gpu
实践:手写数字识别任务
MNIST 是非常有名的手写体数字识别数据集,在无论是 Tensorflow 的官方网站还是 PaddlePaddle 的新手入门,都是通过它做实战讲解,它由手写体数字的图片和相对应的标签组成,如:

MNIST 数据集分为训练图像和测试图像。训练图像 60000 张,测试图像 10000 张,每一个图片代表 0-9 中的一个数字,且图片大小均为 28*28 的矩阵。这一小节将会以 PaddlePaddle 官方提供的 MNIST 手写数字识别任务为例,进行 PaddlePaddle 框架的基本学习。与其他深度学习任务一样,飞桨同样要通过以下四个步骤完成一个相对完整的深度学习任务:
- 数据集的准备和加载;
- 模型构建;
- 模型训练;
- 模型评估。
加载内置数据集
飞桨框架内置了一些常见的数据集,在这个示例中,开发者可以加载飞桨框架的内置数据集,例如本案例所涉及到的手写数字体数据集。这里加载两个数据集,一个用来训练模型,一个用来评估模型。
import paddle.vision.transforms as Ttransform = T.Normalize(mean=[127.5], std=[127.5], data_format='CHW')
#下载数据集
train_dataset = paddle.vision.datasets.MNIST(mode='train', transform=transform)val_dataset = paddle.vision.datasets.MNIST(mode='test', transform=transform)
模型搭建
通过 Sequential 将一层一层的网络结构组建起来。注意,需要先对数据进行 Flatten 操作,将 [1, 28, 28] 形状的图片数据改变形状为 [1, 784]。
mnist = paddle.nn.Sequential(
paddle.nn.Flatten(),
paddle.nn.Linear(784, 512),
paddle.nn.ReLU(),
paddle.nn.Dropout(0.2),
paddle.nn.Linear(512, 10))
模型训练
在训练模型前,需要配置训练模型时损失的计算方法与优化方法,开发者可以使用飞桨框架提供的 prepare 完成,之后使用 fit 接口来开始训练模型。
# 预计模型结构生成模型对象,便于进行后续的配置、训练和验证
model = paddle.Model(mnist)
# 模型训练相关配置,准备损失计算方法,优化器和精度计算方法model.prepare(paddle.optimizer.Adam(parameters=model.parameters()), paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy())
# 开始模型训练
model.fit(train_dataset,
epochs=5,
batch_size=64,
verbose=1)
训练结果:
The loss value printed in the log is the current step, and the metric is the average value of previous steps.Epoch 1/5step 938/938 [==============================] - loss: 0.1801 - acc: 0.9032 - 8ms/stepEpoch 2/5step 938/938 [==============================] - loss: 0.0544 - acc: 0.9502 - 8ms/stepEpoch 3/5step 938/938 [==============================] - loss: 0.0069 - acc: 0.9595 - 7ms/stepEpoch 4/5step 938/938 [==============================] - loss: 0.0094 - acc: 0.9638 - 7ms/stepEpoch 5/5step 938/938 [==============================] - loss: 0.1414 - acc: 0.9670 - 8ms/step
模型评估
开发者可以使用预先定义的验证数据集来评估前一步训练得到的模型的精度。
model.evaluate(val_dataset, verbose=0)
结果如下:
{'loss': [2.145765e-06], 'acc': 0.9751}
可以看出,初步训练得到的模型效果在 97.5% 附近,在逐渐了解飞桨后,开发者可以通过调整其中的训练参数来提升模型的精度。
与 Serverless 架构结合
PaddlePaddle 团队首次开源文字识别模型套件 PaddleOCR,目标是打造丰富、领先、实用的文本识别模型/工具库。该模型套件是一个实用的超轻量 OCR 系统。主要由DB文本检测、检测框矫正和 CRNN 文本识别三部分组成。该系统从骨干网络选择和调整、预测头部的设计、数据增强、学习率变换策略、正则化参数选择、预训练模型使用以及模型自动裁剪量化 8 个方面,采用 19 个有效策略,对各个模块的模型进行效果调优和瘦身,最终得到整体大小为 3.5M 的超轻量中英文 OCR 和 2.8M 的英文数字 OCR。
本地开发
# index.py
import base64
import bottle
import random
from paddleocr import PaddleOCR
ocr = PaddleOCR(use_gpu=False)
@bottle.route('/ocr', method='POST')
def login():
filePath = './temp/' + (''.join(random.sample('zyxwvutsrqponmlkjihgfedcba', 5)))
with open(filePath, 'wb') as f:
f.write(base64.b64decode(bottle.request.body.read().decode("utf-8").split(',')[1]))
ocrResult = ocr.ocr(filePath, cls=False)
return {'result': [[line[1][0], float(line[1][1])] for line in ocrResult]}
bottle.run(host='0.0.0.0', port=8080)
开发完成之后,运行该项目:
python index.py
可以看到服务已经启动:
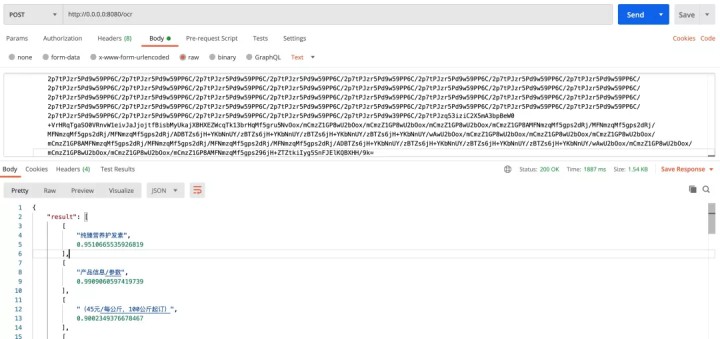
然后通过 Postman 工具进行测试,首先准备一张图片(此处以 PaddleOCR 项目内置的测试图片为例):

通过将图片转换为 Base64 编码,并以 POST 方法请求刚刚启动的 Web 服务,可以看到 PaddleOCR 的执行结果:
部署到 Serverless 架构
目前各大云厂商的 FaaS 平台均已经逐渐支持容器镜像部署。所以,可以将项目打包成镜像,并通过 Serverless Devs 部署到阿里云函数计算。
部署前准备
首先需要完成 Dockerfile 文件:
FROM python:3.7-slim
RUN apt update && apt install gcc libglib2.0-dev libgl1-mesa-glx libsm6 libxrender1 -y && pip install paddlepaddle bottle scikit-build paddleocrle scikit-build paddleocr
# Create app directory
WORKDIR /usr/src/app
# Bundle app source
COPY . .
编写符合 Serverless Devs 规范的 Yaml 文档:
# s.yaml
edition: 1.0.0
name: paddle-ocr
access: default
services:
paddle-ocr:
component: fc
props:
region: cn-shanghai
service:
name: paddle-ocr
description: paddle-ocr service
function:
name: paddle-ocr-function
runtime: custom-container
caPort: 8080
codeUri: ./
timeout: 60
customContainerConfig:
image: 'registry.cn-shanghai.aliyuncs.com/custom-container/paddle-ocr:0.0.1'
command: '["python"]'
args: '["index.py"]'
triggers:
- name: httpTrigger
type: http
config:
authType: anonymous
methods:
- GET
- POST
customDomains:
- domainName: auto
protocol: HTTP
routeConfigs:
- path: /*
项目部署
首先构建镜像,此处可以通过 Serverless Devs 进行构建:
s build --use-docker
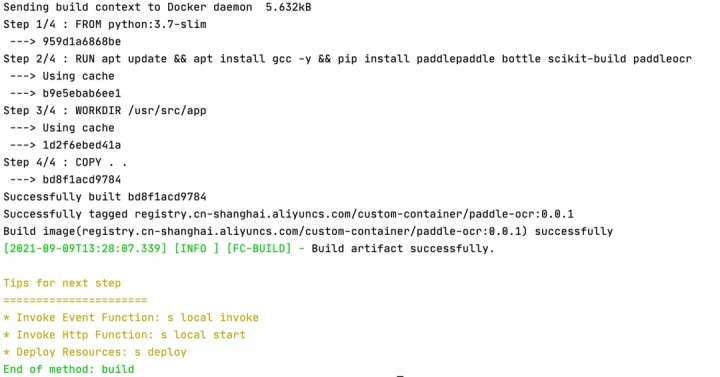
构建完成之后,可以通过工具直接进行部署:
s deploy --push-registry acr-internet --use-local -y
部署完成,可以看到系统返回的测试地址:

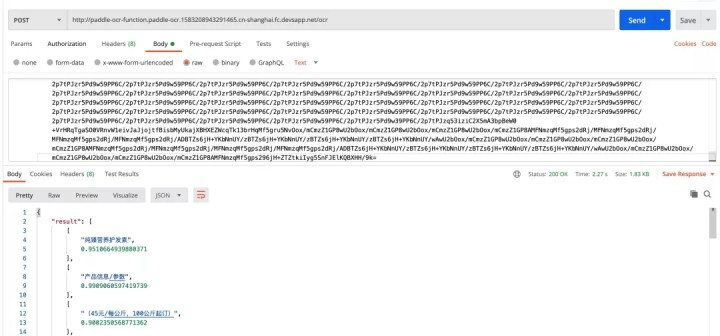
项目测试
此时,可以通过该测试地址进行测试,同样得到了预期效果:
项目优化
通过对部署在 Serverless 架构上的项目进行请求,可以看到冷启动和热启动的时间消耗:
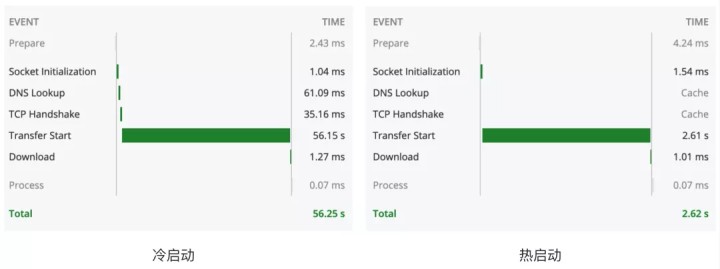
通过冷启动与热启动的对比,我们可以发现,在热启动时,整个系统的性能是相对优秀的。但是遇到冷启动整个项目的响应时常是不可控的,此时可以考虑一下途径进行优化:
- 缩减容器镜像的体积,减少不必要的依赖、文件等,清理掉安装依赖时留下的缓存等;因为函数计算的冷启动包括镜像拉取时间;
- 部分流程进行优化,例如在 PaddleOCR 项目中有明确说明:“paddleocr 会自动下载 ppocr 轻量级模型作为默认模型”,所以这就意味着该项目在 Serverless 架构的冷启动过程中,相对比热启动还增加了一个模型下载和解压的流程,所以这一部分在必要时是可以打入到容器镜像中,进而减少冷启动带来的影响;
- 开启镜像加速,可以有效降低容器镜像的冷启动,在阿里云函数计算官方文档中有相关镜像加速的性能测试描述:“开启函数计算的镜像加速后,可提速 2~5 倍,将分钟级的镜像拉取缩短至秒级”;
- 实例预留,最大程度上降低冷启动率。通过实例预留,可以通过多种算法/策略进行实例的预热和预启动,可以最大程度上降低 Serverless 架构冷启动带来的影响;
原文链接
本文为阿里云原创内容,未经允许不得转载。
以上是关于PaddlePaddle:在 Serverless 架构上十几行代码实现 OCR 能力的主要内容,如果未能解决你的问题,请参考以下文章
周一见|容器正流行,Serverless 未成熟RedHat 推出 OpenStack 第 13 版
全开源深度学习平台PaddlePaddle入手之路----利用Docker在Windows10专业版环境下配置PaddlePaddle