python爬虫实战一|大众点评网
Posted 向阳-Y.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫实战一|大众点评网相关的知识,希望对你有一定的参考价值。
PS:如果不懂的可以看我的上一篇文章快速入门Python爬虫
| 阶段 | 类型 | 问题 | 需要做到 |
|---|---|---|---|
| 1 | 请求 | 网页数据在哪里? | 发现网址url规律 |
| 2 | 请求 | 如何获取网页数据 | 先尝试使用requests成功访问一个url,拿到一个页面数据 |
| 3 | 解析 | 从html中定义需要的数据 | 使用pyquery对这一个页面的网页数据进行解析 |
| 3 | 解析 | 从json中定位需要的数据 | 使用json或resp.json()进行json网页数据解析 |
| 4 | 存储 | 如何存储数据 | 使用csv库将数据存储到csv文件中 |
| 5 | 大功告成 | 重复2-4 | for循环对所有的url进行访问解析存储 |
以大众点评为例:
http://www.dianping.com/shanghai/hotel
1.发现网址url规律
大众点评网址规律,每一页对应p1,p2…
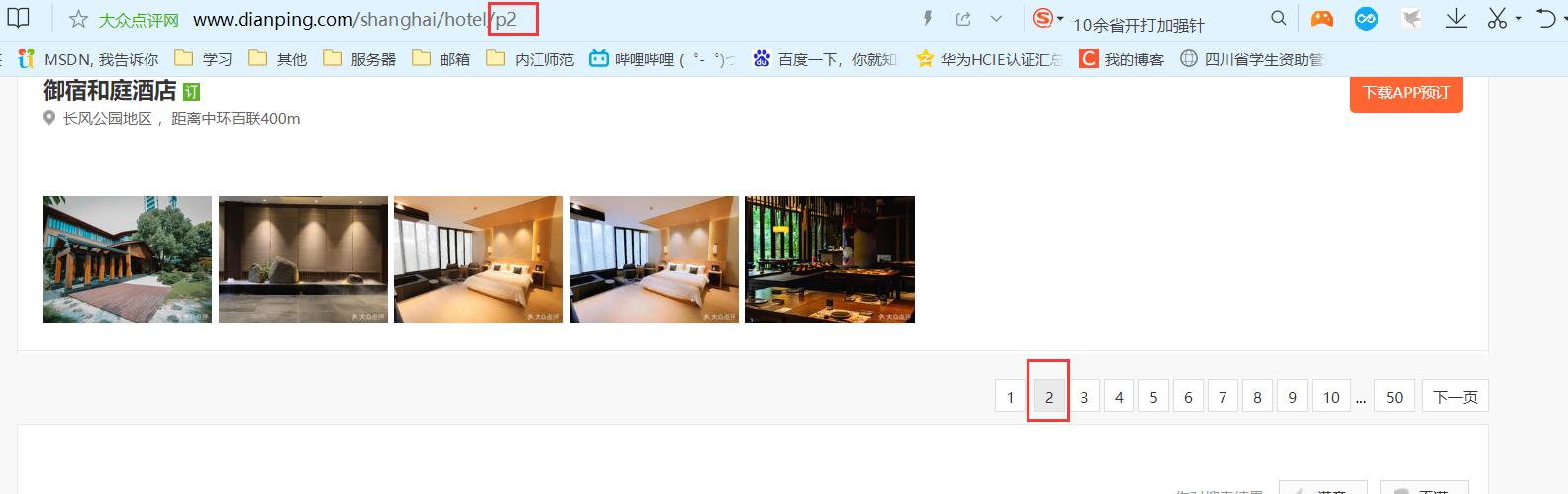
针对规律写出如下代码
>template='http://www.dianping.com/shanghai/hotel/p{page}'
>for p in range(1,51):
url=template.format(page=p)
print(url)
2.拿到一个页面数据
先尝试使用requests成功访问一个url,拿到一个页面数据:以p1为例
>import requests
>url='http://www.dianping.com/shanghai/hotel/p1'
>headers={"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) >AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36"}
>resp=requests.get(url,headers=headers)
>resp.text[:1000] #表示获取前1000个字符内容
通过headers伪装成功拿到:
3.数据解析
使用pyquery对这一个页面的网页数据进行解析,首先使用select工具定位到hotel-block块
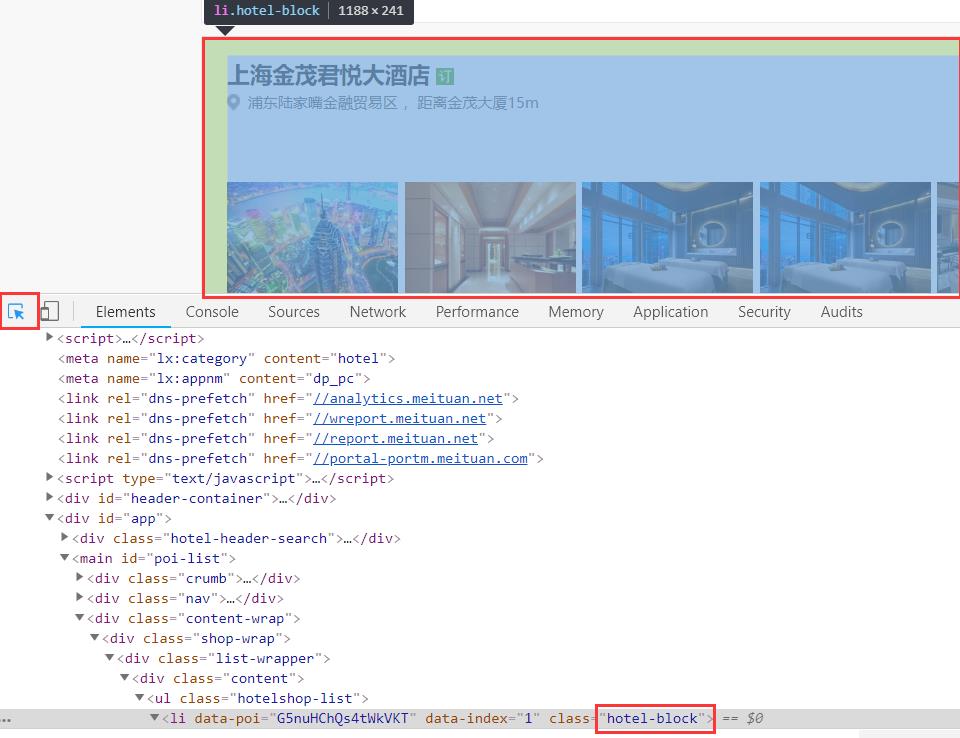
通过tag多级进行精确定位
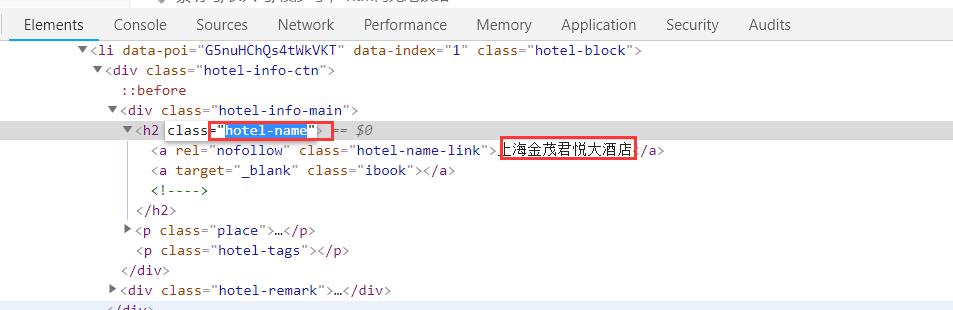
依次类推,改进代码:最终
doc=PyQuery(resp.text)
for hotel in doc.items('.hotel-block'):
hotel_name=hotel('.hotel-name-link').text()
addr1=hotel('.place a').text()
addr2=hotel('.walk-dist').text()[1:]
print(hotel_name,addr1,addr2)
4.存储数据
使用csv库将数据存储到csv文件中,–>不会的请点我<–
以上是关于python爬虫实战一|大众点评网的主要内容,如果未能解决你的问题,请参考以下文章