快速入门Python爬虫|requests请求库|pyquery定位库
Posted 向阳-Y.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了快速入门Python爬虫|requests请求库|pyquery定位库相关的知识,希望对你有一定的参考价值。
目录
1.分析爬虫
| 阶段 | 类型 | 问题 | 需要做到 |
|---|---|---|---|
| 1 | 请求 | 网页数据在哪里? | 发现网址url规律 |
| 2 | 请求 | 如何获取网页数据 | 先尝试使用requests成功访问一个url,拿到一个页面数据 |
| 3 | 解析 | 从html中定义需要的数据 | 使用pyquery对这一个页面的网页数据进行解析 |
| 3 | 解析 | 从json中定位需要的数据 | 使用json或resp.json()进行json网页数据解析 |
| 4 | 存储 | 如何存储数据 | 使用csv库将数据存储到csv文件中 |
| 5 | 大功告成 | 重复2-4 | for循环对所有的url进行访问解析存储 |
以大众点评为例:
http://www.dianping.com/shanghai/hotel
发现网址规律
1.根据规律构造
2.批量生成网址对常规的html网页数据,一般多点击翻页即可发现url规律.
template='http://www.dianping.com/shanghai/hotel/p{P}'
for page in range(1,51):
url=template.format(P=page)
print(url)
2.库
requests网络请求库
一、安装
pip install requests //Win命令行
pip3 install requests //Mac命令行
二、访问方法
requests两种访问方法,两者都返回Response对象:
| 常用参数 | 参数解读 | 使用频率 |
|---|---|---|
| requests.get(url,headers,cookies,params,proxies) | 发起get访问,返回Response对象 | 95% |
| requests.post(url,headers,cookies,data,proxies) | 发起post访问,返回Response对象 | 5% |
import requests
url='http://www.dianping.com/shanghai/hotel/p1'
resp=requests.get(url)
resp
三、返回Response
Response后面带有的状态码:
· 2开头表示访问正常
· 4开头,比如403表示爬虫被网站封锁
· 5开头表示服务器出问题

若出现403(如上图),解决办法如下:伪装
爬虫反爬[转链接]
import requests
url='http://www.dianping.com/shanghai/hotel/p1'
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36'} //在开发者工具中寻找headers参数,并整理成字典格式
resp=requests.get(url,headers=headers)
resp
Response常用方法:
| Response对象的方法 | 作用 | 使用评率 |
|---|---|---|
| Response.json() | 获得json网页数据 | 35% |
| Response.text | 获得html网页数据 | 60% |
| Response.content | 获取二进制数据(如文件、图片、音视频) | 5% |
| Response.encoding | 根据charset设置网页数据编码 | 很少用到 |
例如:
pyquery网页解析定位库
安装
pip install pyquery
假设我们访问得到了一个网页的html字符串数据:
>html = open('example.html', encoding='utf-8').read()
>html
html字符串转化为PyQuery
> from pyquery import PyQuery
> doc=PyQuery(html)
> doc
如下图,html字符串变成了下图内容,下图表示doc目前是可被循环的

从下图可看出,html字符串被转换成了pyquery类型
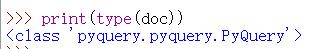
选择器表达式
在人类关系中,可以通过父母,子女,亲戚,外貌,邻居进行定位一个人
同理,在html世界也有很多不同的表达式来定位标签
| Selector_Expression | 例子 | 解释 |
|---|---|---|
| class | .Intro | 选出class="Intro"的标签,返回PyQuery |
| id | #intro | 选出id="intro"的标签,返回PyQuery |
| tag | li | 选出所有li标签的标签,返回PyQuery |
| 多层tag | ul li | 选出所有li标签(且这些li辈分都比ul低),返回PyQuery |
| tag & attr | li[class] | 选出带有class属性所有li标签,返回PyQuery |
| tag & attr & attr_value | li[class=cando] | 选出所有li标签,其中li都带有class="cando"属性值 |
class
>doc('.Intro') #利用class进行定位
id
>doc('#Intro') #利用ID进行定位
tag
##PyQuery(Selector_Expression)
>doc('ul') #利用标签进行定位(不常用,精确度不高)
多层tag
>doc('html body .Intro') #多层tag
>doc('html body #intro') #多层tag
>doc('html ul li') #多层tag
>doc('.intro ul li') #多层tag
>doc('#intro ul li') #多层tag
tag & attr
>doc('li[class]')定位含有class的li标签
>doc('div[title]')定位含有title的div标签
>doc('li[name]')定位含有name的li标签
tag & attr & attr_value
>doc('li[class=cando]')
>doc('div[title]=')
>doc('li[name=web]')
PyQuery常用方法
| PyQuery对象方法 | 功能 |
|---|---|
| PyQuery(Selector_Expression) | 查找符合Selector_Expression条件的标签,返回PyQuery |
| PyQuery.items(Selector_Expression) | 查找符合Selector_Expression条件的标签,返回PyQuery列表 |
| PyQuery.eq(index) | 获得第index+1个标签 |
| PyQuery.text() | 获得标签内的文本 |
| PyQuery.attr(attribute) | 获得标签的属性值 |
PyQuery(Selector_Expression)
>doc('li')
PyQuery.items(Selector_Expression)
>doc.items('li') #将li的数据打包为可遍历的值

这样的返回值表示是可遍历的:

PyQuery.eq(index)
eq表示第几行,从0开始
print(doc("li").eq(0))
PyQuery.text()
拿标签内的文本,只要是PyQuery类型的数据都可以拿
print(doc("li").eq(0).text())
print(doc.text[:100]) #表示只拿前100个字符
PyQuery.attr(attribute)
拿到属性值
doc("li").eq(0).attr("name")
doc("li").eq(0).attr("class")
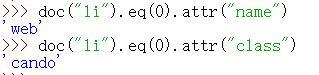
不定位使用text会输出所有text内容(不精确)、不定位使用attr只会给出第一个属性值(其余被忽略)。总结:建议全部定位到具体位置再使用attr和text。
以上是关于快速入门Python爬虫|requests请求库|pyquery定位库的主要内容,如果未能解决你的问题,请参考以下文章