无奇不有! Matplotlib竟然也可画出“扭扭捏捏”的数据可视化图片!
Posted Python学习与数据挖掘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了无奇不有! Matplotlib竟然也可画出“扭扭捏捏”的数据可视化图片!相关的知识,希望对你有一定的参考价值。
今天我们直奔主题,分享一种使用 Matplotlib 进行有趣的数据可视化的案例!在我的印象中,Matplotlib 属于那种中规中矩的可视化库,能画出“扭扭捏捏”的可视化图片,着实让你吃惊,欢迎收藏学习,喜欢点赞支持。
我们使用 Matplotlib 创建类似 xkcd 的绘图,并可以在这个项目中同 Matplotlib 可视化组合起来,让整个数据分析变得更有趣。
下面我们先来看看数据吧
数据集
我们可以在 Kaggle 上找到 Netflix 数据集,截至 2020 年,已经包含 7787 部 Netflix 上可用的电影和电视节目的数据
下面就先查看数据
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['figure.dpi'] = 200
df = pd.read_csv("../input/netflix-shows/netflix_titles.csv")
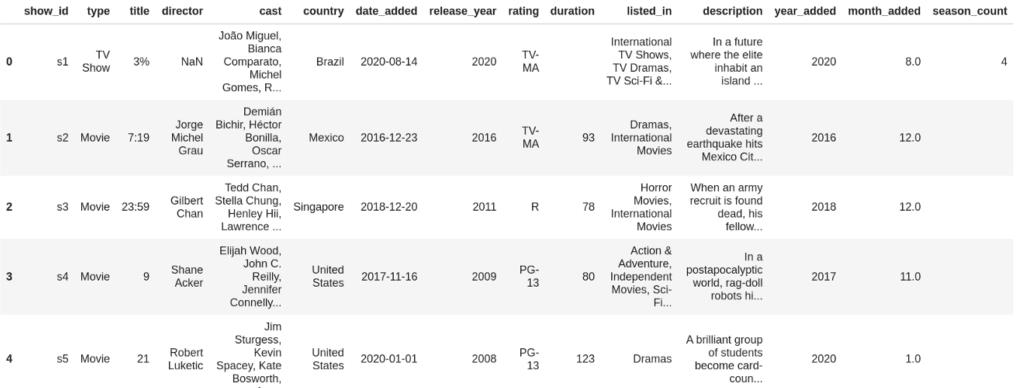
df.head()

接下来我们向数据集当中增加一些新功能,我们后面使用
df["date_added"] = pd.to_datetime(df['date_added'])
df['year_added'] = df['date_added'].dt.year.astype('Int64')
df['month_added'] = df['date_added'].dt.month
df['season_count'] = df.apply(lambda x : x['duration'].split(" ")[0] if "Season" in x['duration'] else "", axis = 1)
df['duration'] = df.apply(lambda x : x['duration'].split(" ")[0] if "Season" not in x['duration'] else "", axis = 1)
df.head()
下面我们就可以进入有趣的数据分析了
当然,如果要在 Matplotlib 中使用 XKCDify 可视化,还需要添加如下代码
with plt.xkcd():

1.Netflix 时间轴
我们先查看一个描述 Netflix 多年来演变的时间表
from datetime import datetime
# these go on the numbers below
tl_dates = [
"1997\\nFounded",
"1998\\nMail Service",
"2003\\nGoes Public",
"2007\\nStreaming service",
"2016\\nGoes Global",
"2021\\nNetflix & Chill"
]
tl_x = [1, 2, 4, 5.3, 8,9]
# the numbers go on these
tl_sub_x = [1.5,3,5,6.5,7]
tl_sub_times = [
"1998","2000","2006","2010","2012"
]
tl_text = [
"Netflix.com launched",
"Starts\\nPersonal\\nRecommendations","Billionth DVD Delivery","Canadian\\nLaunch","UK Launch"]
with plt.xkcd():
# Set figure & Axes
fig, ax = plt.subplots(figsize=(15, 4), constrained_layout=True)
ax.set_ylim(-2, 1.75)
ax.set_xlim(0, 10)
# Timeline : line
ax.axhline(0, xmin=0.1, xmax=0.9, c='deeppink', zorder=1)
# Timeline : Date Points
ax.scatter(tl_x, np.zeros(len(tl_x)), s=120, c='palevioletred', zorder=2)
ax.scatter(tl_x, np.zeros(len(tl_x)), s=30, c='darkmagenta', zorder=3)
# Timeline : Time Points
ax.scatter(tl_sub_x, np.zeros(len(tl_sub_x)), s=50, c='darkmagenta',zorder=4)
# Date Text
for x, date in zip(tl_x, tl_dates):
ax.text(x, -0.55, date, ha='center',
fontfamily='serif', fontweight='bold',
color='royalblue',fontsize=12)
# Stemplot : vertical line
levels = np.zeros(len(tl_sub_x))
levels[::2] = 0.3
levels[1::2] = -0.3
markerline, stemline, baseline = ax.stem(tl_sub_x, levels, use_line_collection=True)
plt.setp(baseline, zorder=0)
plt.setp(markerline, marker=',', color='darkmagenta')
plt.setp(stemline, color='darkmagenta')
# Text
for idx, x, time, txt in zip(range(1, len(tl_sub_x)+1), tl_sub_x, tl_sub_times, tl_text):
ax.text(x, 1.3*(idx%2)-0.5, time, ha='center',
fontfamily='serif', fontweight='bold',
color='royalblue', fontsize=11)
ax.text(x, 1.3*(idx%2)-0.6, txt, va='top', ha='center',
fontfamily='serif',color='royalblue')
# Spine
for spine in ["left", "top", "right", "bottom"]:
ax.spines[spine].set_visible(False)
# Ticks
ax.set_xticks([])
ax.set_yticks([])
# Title
ax.set_title("Netflix through the years", fontweight="bold", fontfamily='serif', fontsize=16, color='royalblue')
ax.text(2.4,1.57,"From DVD rentals to a global audience of over 150m people - is it time for Netflix to Chill?", fontfamily='serif', fontsize=12, color='mediumblue')
plt.show()

上图展示了 Netflix 旅程当中一幅相当不错的画面, 此外,由于 plt.xkcd() 函数,这幅图看起来是手绘的,看起来确实很棒!
2.电影和电视节目
接下来我们看一下电影与电视节目的比例
col = "type"
grouped = df[col].value_counts().reset_index()
grouped = grouped.rename(columns = {col : "count", "index" : col})
with plt.xkcd():
explode = (0, 0.1) # only "explode" the 2nd slice (i.e. 'TV Show')
fig1, ax1 = plt.subplots(figsize=(5, 5), dpi=100)
ax1.pie(grouped["count"], explode=explode, labels=grouped["type"], autopct='%1.1f%%',
shadow=True, startangle=90)
ax1.axis('equal') # Equal aspect ratio ensures that pie is drawn as a circle.
plt.show()
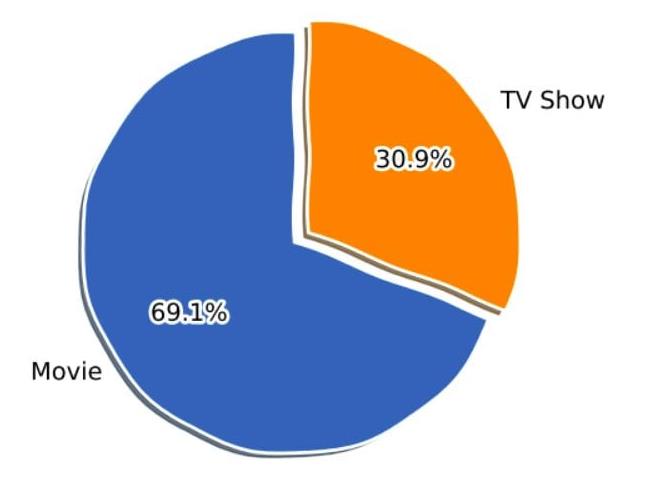
平台上的电视节目数量不到总内容的三分之一, 所以,与 Netflix 上的电视节目相比,我们可能更有机会找到一部相对较好的电影。
3.内容最多的国家
这一次我们制作一个水平条形图,代表内容最多的前 25 个国家/地区。DataFrame 中的 country 列有几行包含 1 个以上的国家。

from collections import Counter
col = "country"
categories = ", ".join(df[col].fillna("")).split(", ")
counter_list = Counter(categories).most_common(25)
counter_list = [_ for _ in counter_list if _[0] != ""]
labels = [_[0] for _ in counter_list]
values = [_[1] for _ in counter_list]
with plt.xkcd():
fig, ax = plt.subplots(figsize=(10, 10), dpi=100)
y_pos = np.arange(len(labels))
ax.barh(y_pos, values, align='center')
ax.set_yticks(y_pos)
ax.set_yticklabels(labels)
ax.invert_yaxis() # labels read top-to-bottom
ax.set_xlabel('Content')
ax.set_title('Countries with most content')
plt.show()

看完上图后的一些总体看法:
-
Netflix 上的绝大多数内容都来自美国
-
尽管 Netflix 在印度起步较晚(2016 年),但它已经排在美国之后的第二位。因此,印度是 Netflix 的一个大市场。
4.受欢迎的导演和演员
为了看看受欢迎的导演和演员,我们决定绘制一个图形,其中包含来自内容最多的前六个国家的六个子情节,并为每个子情节制作水平条形图。我们来看看下面的图
a.最受欢迎的导演
from collections import Counter
from matplotlib.pyplot import figure
import math
colours = ["orangered", "mediumseagreen", "darkturquoise", "mediumpurple", "deeppink", "indianred"]
countries_list = ["United States", "India", "United Kingdom", "Japan", "France", "Canada"]
col = "director"
with plt.xkcd():
figure(num=None, figsize=(20, 8))
x=1
for country in countries_list:
country_df = df[df["country"]==country]
categories = ", ".join(country_df[col].fillna("")).split(", ")
counter_list = Counter(categories).most_common(6)
counter_list = [_ for _ in counter_list if _[0] != ""]
labels = [_[0] for _ in counter_list][::-1]
values = [_[1] for _ in counter_list][::-1]
if max(values)<10:
values_int = range(0, math.ceil(max(values))+1)
else:
values_int = range(0, math.ceil(max(values))+1, 2)
plt.subplot(2, 3, x)
plt.barh(labels,values, color = colours[x-1])
plt.xticks(values_int)
plt.title(country)
x+=1
plt.suptitle('Popular Directors with the most content')
plt.tight_layout()
plt.show()
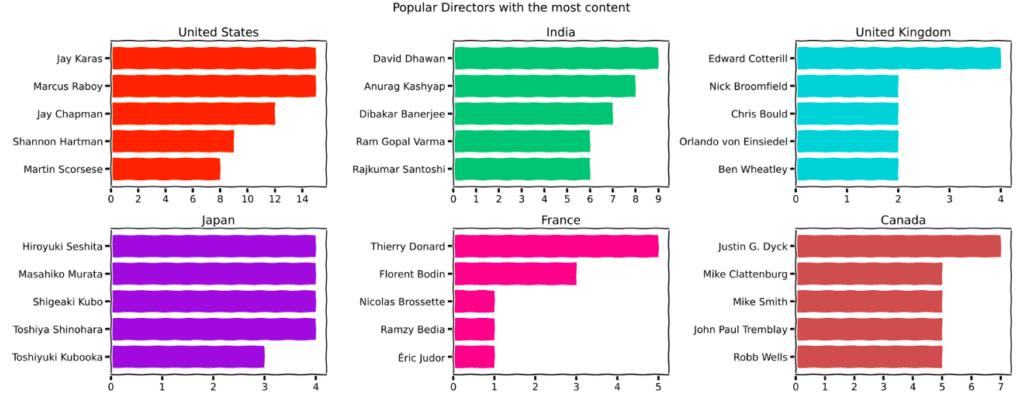
b.最受欢迎的演员
col = "cast"
with plt.xkcd():
figure(num=None, figsize=(20, 8))
x=1
for country in countries_list:
df["from_country"] = df['country'].fillna("").apply(lambda x : 1 if country.lower() in x.lower() else 0)
small = df[df["from_country"] == 1]
cast = ", ".join(small['cast'].fillna("")).split(", ")
tags = Counter(cast).most_common(11)
tags = [_ for _ in tags if "" != _[0]]
labels, values = [_[0]+" " for _ in tags][::-1], [_[1] for _ in tags][::-1]
if max(values)<10:
values_int = range(0, math.ceil(max(values))+1)
elif max(values)>=10 and max(values)<=20:
values_int = range(0, math.ceil(max(values))+1, 2)
else:
values_int = range(0, math.ceil(max(values))+1, 5)
plt.subplot(2, 3, x)
plt.barh(labels,values, color = colours[x-1])
plt.xticks(values_int)
plt.title(country)
x+=1
plt.suptitle('Popular Actors with the most content')
plt.tight_layout()
plt.show()
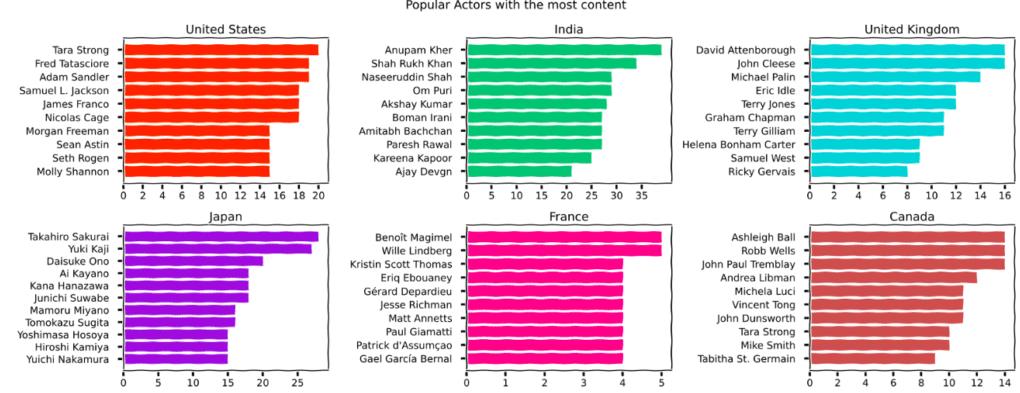
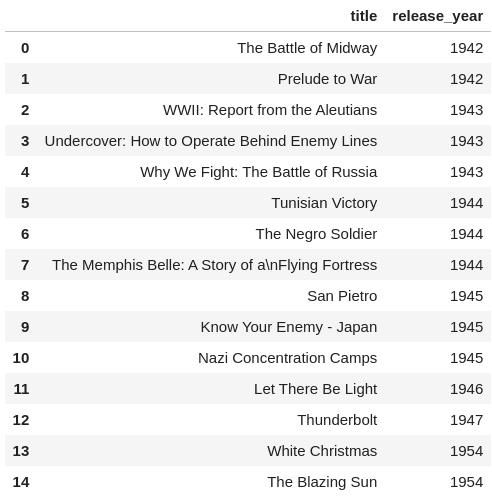
5.一些最古老的电影和电视节目
先来查看最古老的电影
a.古老的电影
small = df.sort_values("release_year", ascending = True)
small = small[small['duration'] != ""].reset_index()
small[['title', "release_year"]][:15]
b.古老的电视节目
small = df.sort_values("release_year", ascending = True)
small = small[small['season_count'] != ""].reset_index()
small = small[['title', "release_year"]][:15]
small
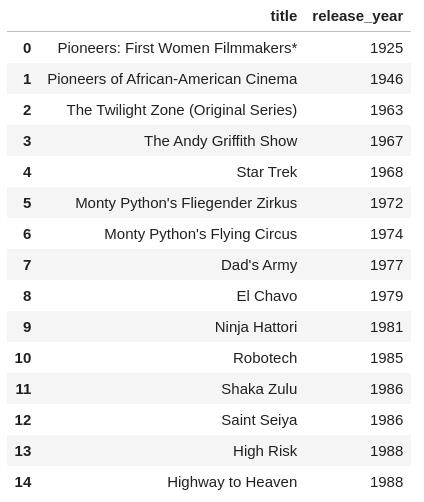
哇,Netflix 有一些非常老的电影和电视节目——有些甚至在 80 多年前就已经发行了, 你看过这些吗?
6.Netflix 有最新的内容吗?
是的,Netflix 确实很酷,而且拥有一个世纪前的内容,但它是否也有最新的电影和电视节目呢, 为了找到这一点,我们首先计算一下内容添加到 Netflix 的日期与该内容的发布年份之间的差异
df["year_diff"] = df["year_added"]-df["release_year"]
然后,我们创建了一个散点图,x 轴作为年份差异,y 轴作为电影/电视节目的数量:
col = "year_diff"
only_movies = df[df["duration"]!=""]
only_shows = df[df["season_count"]!=""]
grouped1 = only_movies[col].value_counts().reset_index()
grouped1 = grouped1.rename(columns = {col : "count", "index" : col})
grouped1 = grouped1.dropna()
grouped1 = grouped1.head(20)
grouped2 = only_shows[col].value_counts().reset_index()
grouped2 = grouped2.rename(columns = {col : "count", "index" : col})
grouped2 = grouped2.dropna()
grouped2 = grouped2.head(20)
with plt.xkcd():
figure(num=None, figsize=(8, 5))
plt.scatter(grouped1[col], grouped1["count"], color = "hotpink")
plt.scatter(grouped2[col], grouped2["count"], color = '#88c999')
values_int = range(0, math.ceil(max(grouped1[col]))+1, 2)
plt.xticks(values_int)
plt.xlabel("Difference between the year when the conten以上是关于无奇不有! Matplotlib竟然也可画出“扭扭捏捏”的数据可视化图片!的主要内容,如果未能解决你的问题,请参考以下文章