论文阅读非易失内存系统中的写优化和持久化技术研究
Posted Anyanyamy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文阅读非易失内存系统中的写优化和持久化技术研究相关的知识,希望对你有一定的参考价值。
最近看了华科左鹏飞的博士毕业论文,深感写的好,便作此笔记。
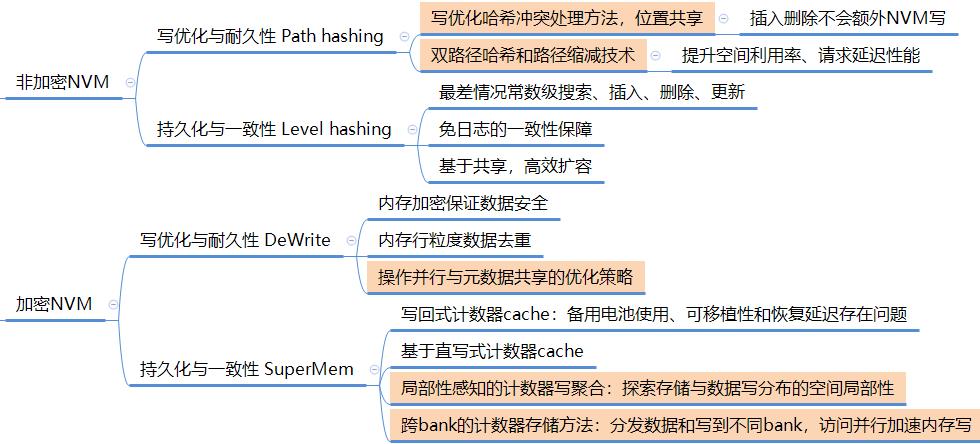
论文主要针对NVM做了4部分工作:针对非加密NVM的写优化、一致性优化工作,针对加密NVM的写优化、一致性优化工作。具体来说包括以下4个方案:Path hashing, Level hashing, DeWrite, SuperMem.
背景
计算机发展,对主存DRAM容量要求越来越高,但受工艺限制DRAM难以大容量。
NVM位于DRAM与SSD之间,低能耗、高密度,具有接近DRAM的访问速度与接近SSD的容量,具有可字节寻址、非易失性、访问速度快等优点。
但直接把针对DRAM设计的应用和数据结构用到NVM上,面临写优化、数据持久化、安全性的挑战。

写优化:进行磨损均衡、减少写次数存在挑战
持久化:保证故障一致性:使用clflush+mfence指令保证写的顺序,使用日志/CoW避免大于8B数据的部分更新。这些机制增加额外开销,如何保证一致性存在挑战
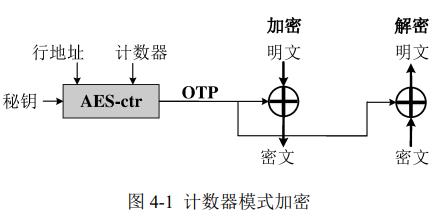
安全性:内存中存明文不可行,NVM中需要存密文,使用CME计数器模式加密NVM内存。但加密雪崩 =》NVM写增加,加密NVM2个写请求不能同时持久化 =》数据持久化不能保证故障一致性
本文设计的4个方案总结如下图所示,总结了每个方案的核心思想
一. Path hashing
背景
现有的hash直接使用在NVM上会带来额外写,降低性能。因此设计path hashing。
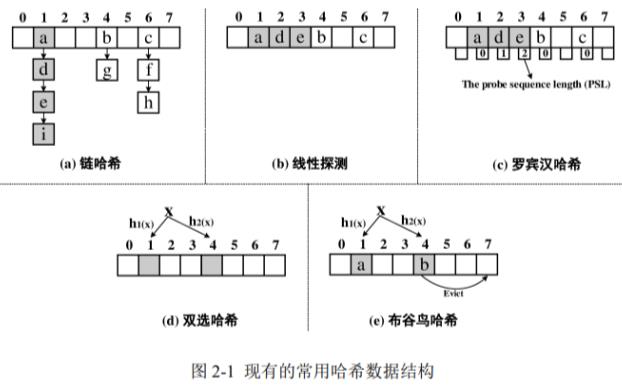
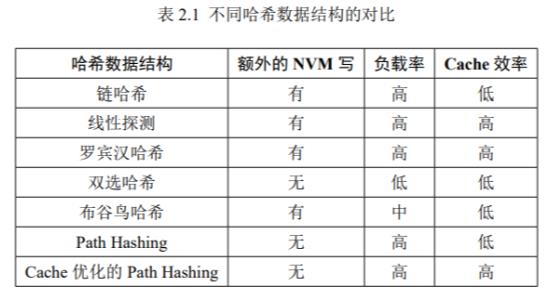
链哈希:插删时需要额外NVM写,因为要修改指针
线性探测:删除元素时要移动元素回原来的位置,造成额外NVM写
罗宾汉哈希:插入导致替换,删除需要移动,造成额外NVM写
双选哈希:插删只探测2个位子,无额外NVM写
布谷鸟哈希:插入踢出操作可能造成大量NVM写
设计
1. 位置共享
倒二叉树,顶层为可寻址单元,下层为共享的备用单元。用备用元素解决冲突,提升空间利用率
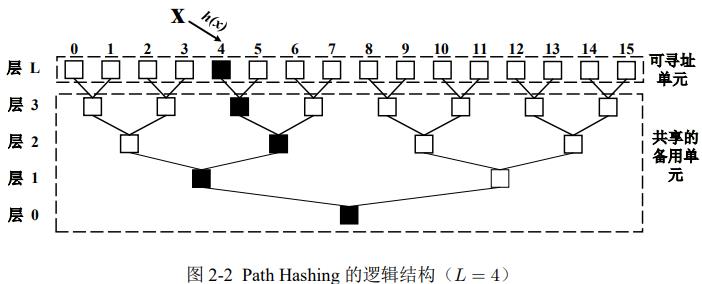
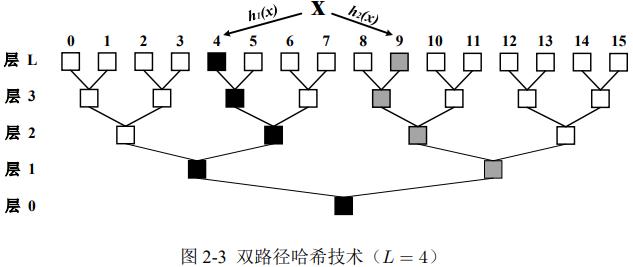
2. 双路径哈希
两条备选路径,进一步减少冲突
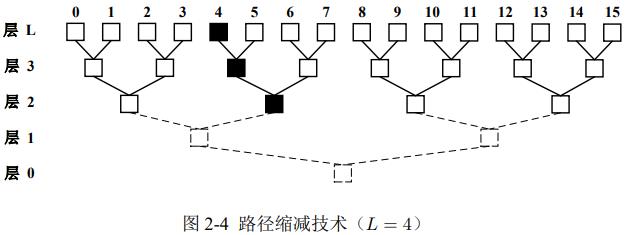
3. 路径缩减
把底层无用的位置删掉,缩短查找路径
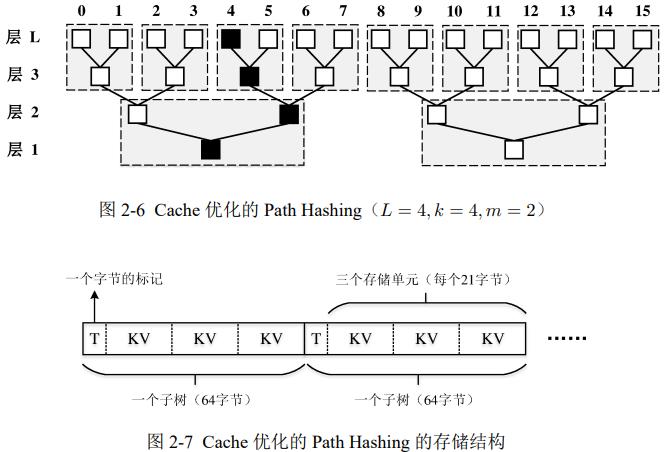
4. cache优化
cache缩小CPU与主存间的速度差距,cache行是主存与最后一级cache的基本数据传输单元,一般大小64B。如果不在cache中称为未命中,需要从主存加载到cache
属于相同路径的多个存储单元打包存储在1个cache行。划分子树,小方块内预取同1路径的下一级存储单元,如果访问4,找不到,找层3时产生1次cache命中
二. Level hashing
背景
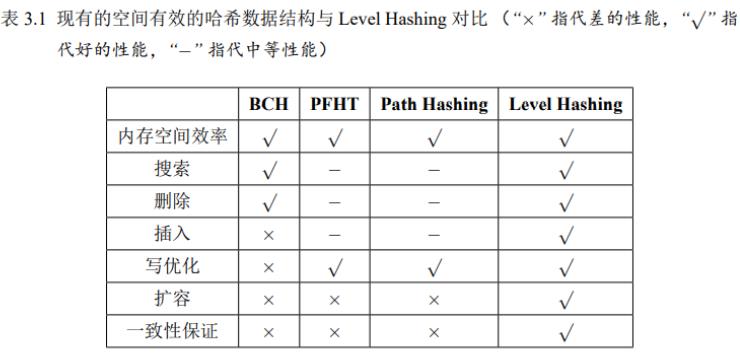
path hashing减少NVM写,但没有保证故障一致性+扩容低效
设计
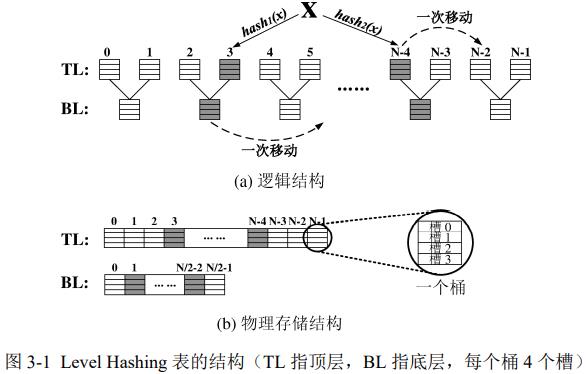
1. 结构设计
结合BCH思想(桶中多个slots)、2-choice哈希(用2个hash选2个备选桶)、cuckoo哈希(至多移动一次元素)、2层设计(提升负载因子,搜索最多探测4个bucket)
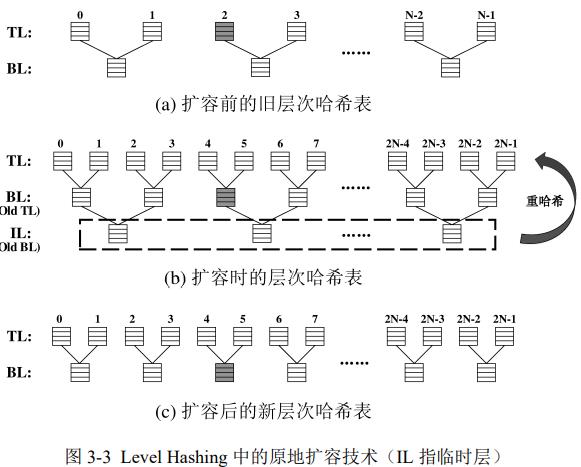
2. 高效扩容
创建top 2倍大的level,把bottom中的所有元素重哈希到新top中。
提升load factor:b2t策略:把底层满的移动到其他候选顶层,使得顶层与底层可以重分布,提升load factor
提升搜索性能:比较两层,哪个元素多,从哪层开始搜索
3. 故障一致性保证
桶之前有token标记状态,可以实现免日志的操作。
插入:没有元素移动 =》先写元素,再token置1;需要移动元素=》先复制到新位子,新token置1,旧token置0
删除:token置0
扩容:复制到新位子,新token置1,旧token置0
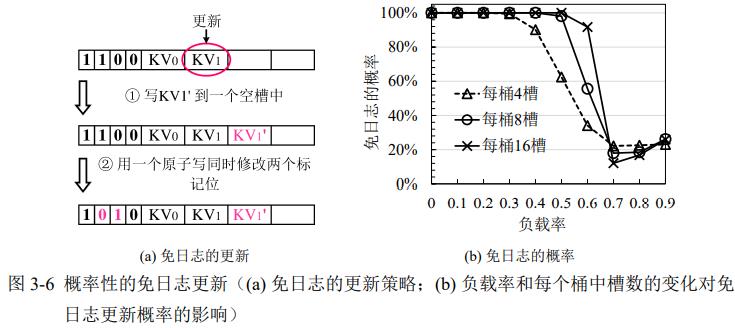
概率性免日志更新:如果存在空位,写新KV,修改新旧token
4. 并发性
对每个slot加细粒度锁
三. DeWrite
背景
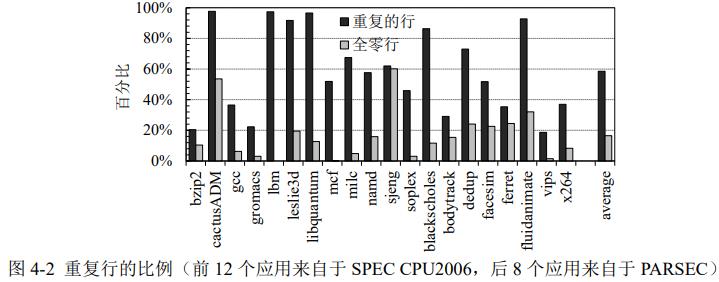
NVM内存加密一般采用CME模式,需要尽量减少写入NVM的数据量,从而降低加密负担。cache中有大量重复行,看看内存是否也有重复行,统计后发现写入NVM的内存行很多重复,因此可以执行去重,减少NVM写。
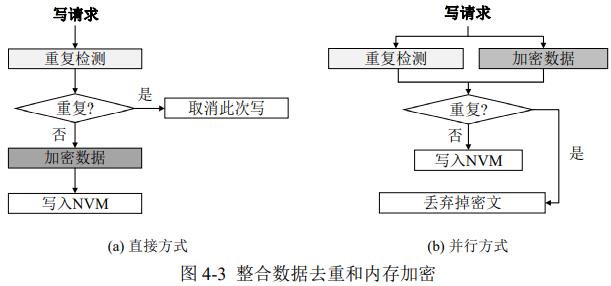
设计
1. NVM上进行加密去重不可行

2. 基于预测的并行策略
数据去重与加密可以直接串行处理(适合重复数据)或者并行处理(适合非重复数据),可以增加1个片上历史窗口,保持最近3个内存行是否重复,用于预测下一个是否重复。
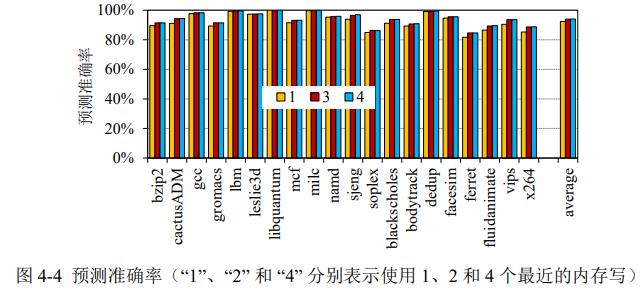
3. 轻量级在线去重
使用CRC-32哈希算法,更轻量。NVM读代价比写低,去重可以用读来消除写。
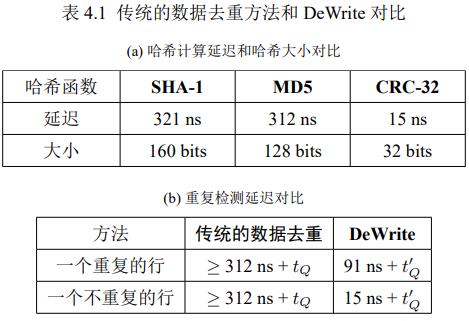
硬件架构:在LLC中预测下一个内存行数据是否重复,在iMC中执行去重和加密,然后写入到加密NVM中。

数据结构:地址映射表、重复检测hash表、清理旧hash的反向hash表、空闲空间管理表

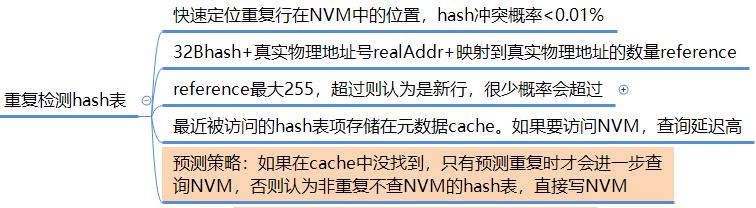

4. 元数据共享策略
计数器模式加密需要存储行计数器来加解密数据,每行的计数器是 28 B
把counter嵌入到元数据中,减少存储代价


5. 加密NVM读写操作
写:
1. 预测机制推测是否重复
2. 计算cache line哈希
3-5. 查hash表。如果有,读NVM比对cache line。如果重复,取消写,更新metadata;如果不重复,写NVM,更新metadata
6-7. 如果hash表中无,写NVM,更新metadata
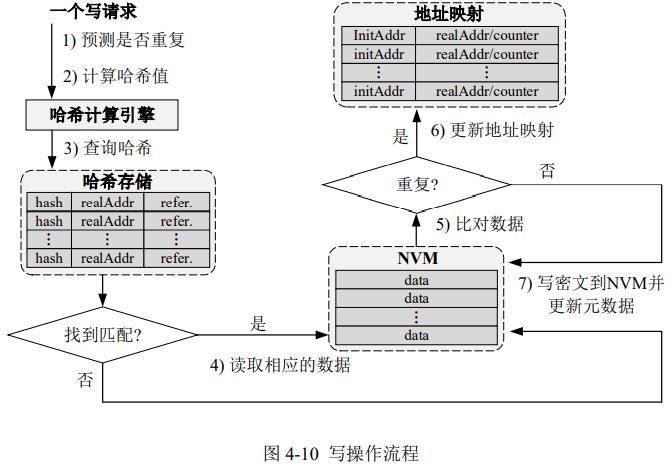
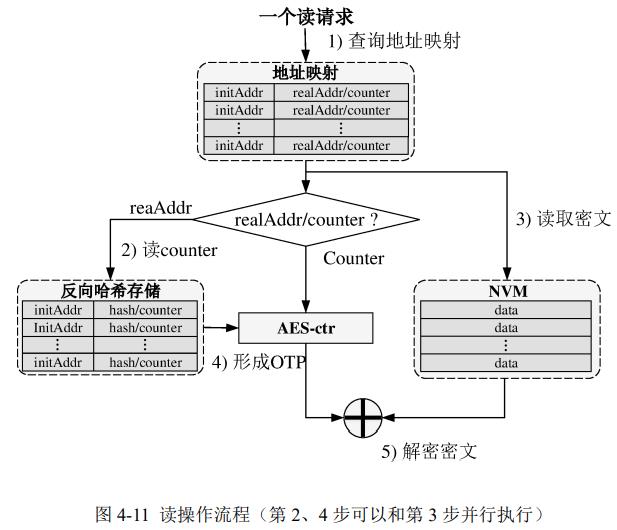
读:
1. 请求地址作为initAddr地址号查表,如果值是counter值,则计算OTP
2. 如果值是realAddr真实存储地址,则查询反向hash表获取counter,计算OTP
3. 读密文,OTP异或解密
四. SuperMem
背景
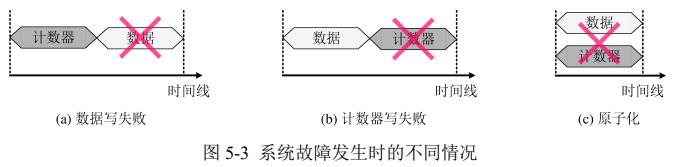
现在保证加密NVM中故障一致性可以使用写回式counter cache,需要大电池或软件层修改;电池贵,修改难移植。持久化与安全性存在矛盾:写入NVM产生的数据写与counter写请求不能同时持久化,可能导致故障时不一致。
目前使用CME进行NVM加密,使用全局key+行地址+counter来形成OTP,加密数据行
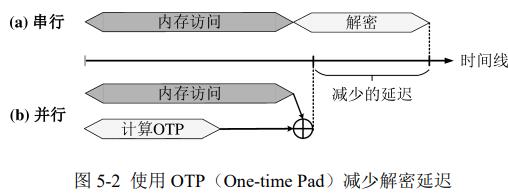
现在的计算机系统不能原子地同时持久化两个写请求到 NVM 中
设计
1. 直写式counter cache
直写cache:当data写入NVM,counter也写入NVM,不需要手动刷cache。但每次2个写降低性能
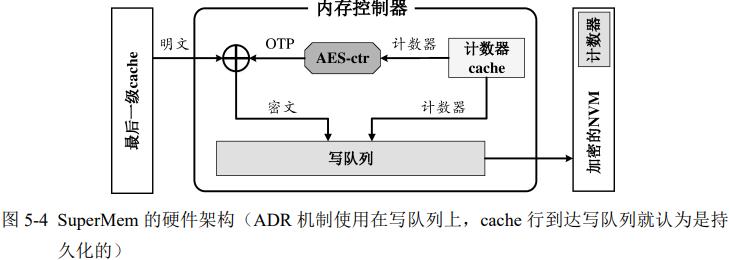
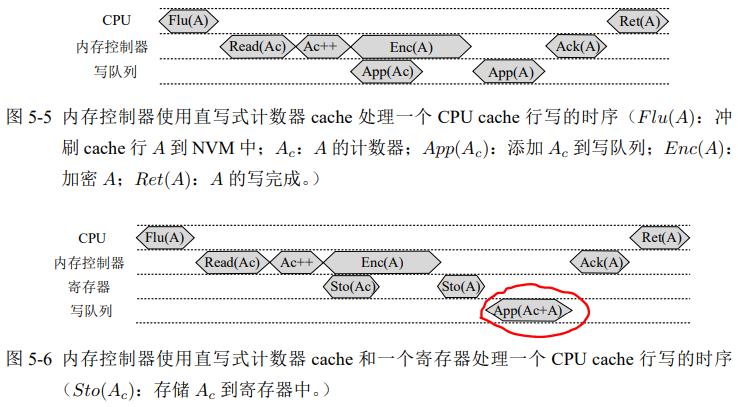

通过把counter与数据写的请求同时添加到写队列,可以保证故障一致性
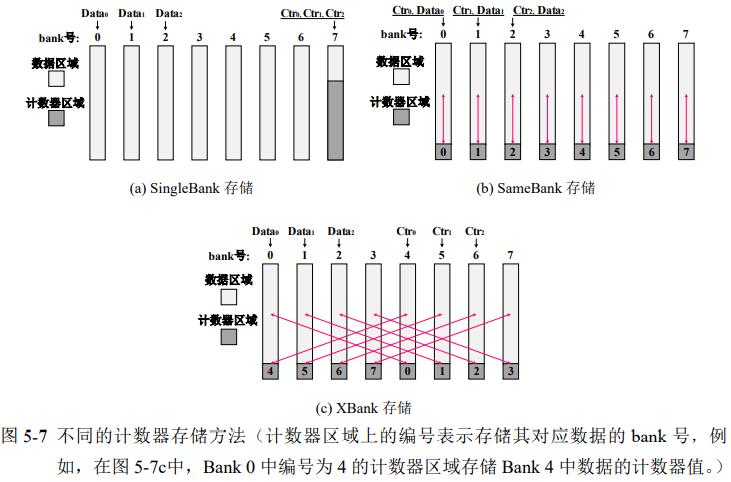
2. 跨bank的counter存储 - XBank
counter存储在NVM连续区域SingleBank中
写回counter cache: 大部分counter写缓存在cache
直写counter cache: 每个data产生1个counter写,不同bank的data,产生的counter写都在一个bank,只能串行降低性能
OS给应用分配连续的内存,很可能在附近bank,所以发到远的bank,能够并行
3. counter写聚合 - CWC

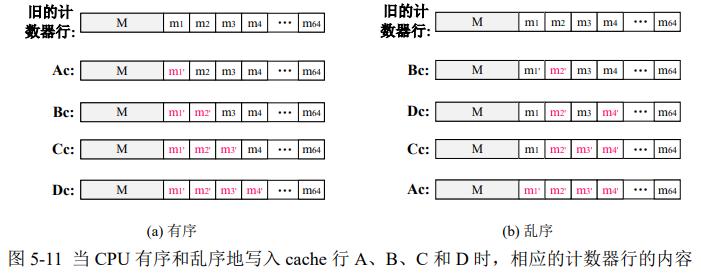
分裂计数器模式:1个页共享大counter M,页内64个行分别有64个7bit的小counter m
内存行重写,更新小counter,如果溢出,更新M,M不会溢出,大于NVM寿命
应用通常给事务分配连续空间,事务中多个cacheline具有连续物理地址,也具有空间局部性
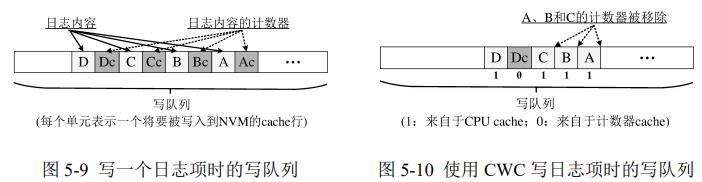
日志条目:同1页中多个内存行,counter写入相同内存行
后写入的counter cacheline 包括之前写入的counter
直接删掉旧的counter cacheline,最新的计数器行包括了之前的修改
给队列中cacheline增加1位标志是否是cpu cache/counter cache
内存页重加密处理counter溢出:
数据不一致:重加密状态寄存器RSR追踪每行加密状态,如果丢失,可能页一部分加密
RSR:32bit物理页号,64bit旧M,64bit done每行是否重加密
用ADR保护RSR不丢失
以上是关于论文阅读非易失内存系统中的写优化和持久化技术研究的主要内容,如果未能解决你的问题,请参考以下文章